
 Peranti teknologi
AI
Mari lihat gambar model besar dengan lebih berkesan daripada menaip! Penyelidikan baharu dalam NeurIPS 2023 mencadangkan kaedah pertanyaan berbilang modal, meningkatkan ketepatan sebanyak 7.8%
Peranti teknologi
AI
Mari lihat gambar model besar dengan lebih berkesan daripada menaip! Penyelidikan baharu dalam NeurIPS 2023 mencadangkan kaedah pertanyaan berbilang modal, meningkatkan ketepatan sebanyak 7.8%
Mari lihat gambar model besar dengan lebih berkesan daripada menaip! Penyelidikan baharu dalam NeurIPS 2023 mencadangkan kaedah pertanyaan berbilang modal, meningkatkan ketepatan sebanyak 7.8%

Keupayaan untuk "mengecam imej" model besar sangat kuat, mengapa mereka masih mencari perkara yang salah?
Contohnya, kelawar dan kelawar mengelirukan yang tidak kelihatan sama, atau gagal mengenali ikan yang jarang ditemui dalam beberapa set data...
Ini kerana apabila kami meminta model besar untuk "mencari sesuatu", kami sering memasukkan The is teks .
Jika penerangannya samar-samar atau terlalu berat sebelah, seperti "kelawar" (kelawar atau kelawar?) atau "syaitan" (Cyprinodon diabolis) , AI akan menjadi sangat keliru.
Ini membawa kepada fakta bahawa apabila menggunakan model besar untuk melakukan pengesanan sasaran, terutamanya dunia terbuka (adegan tidak diketahui)tugas pengesanan sasaran, hasilnya selalunya tidak sebaik yang diharapkan.
Kini, kertas kerja yang disertakan dalam NeurIPS 2023 akhirnya menyelesaikan masalah ini.

Makalah ini mencadangkan kaedah pengesanan sasaran berdasarkan pertanyaan berbilang modalMQ-Det Dengan hanya menambah contoh imej pada input, ketepatan mencari sesuatu dalam model besar boleh dipertingkatkan dengan lebih baik.
Pada set data pengesanan penanda aras LVIS, tanpa memerlukan penalaan halus model tugasan hiliran, MQ-Det meningkatkan ketepatan GLIP model besar pengesanan arus perdana sebanyak kira-kira 7.8% secara purata pada 13 penanda aras tugasan hiliran kecil , peningkatan purata ialah 6.3%Ketepatan. Bagaimana ini dilakukan? Mari kita lihat.
Kandungan berikut diterbitkan semula daripada pengarang makalah dan blogger Zhihu @沁园夏:Jadual Kandungan
MQ-Det: Model pengesanan sasaran dunia terbuka yang besar untuk pertanyaan pelbagai mod- 1.1 Daripada pertanyaan teks kepada pertanyaan Stateful berbilang modal
- 1.2 Seni bina model pertanyaan berbilang mod palam dan main MQ-Det
- 1.3 Strategi latihan cekap MQ-Det
- 1.4 Keputusan eksperimen: Penilaian tanpa penyetelan 1.5
- keputusan: Penilaian beberapa pukulan
- 1.6 Prospek Pengesanan Objek Pertanyaan Pelbagai Modal
- MQ-Det: Model Besar Pengesanan Objek Dunia Terbuka untuk Pertanyaan Pelbagai Modal
Pengesanan Objek di Alam Liar
Pautan Kertas:https://www.php.cn/link/9c6947bd95ae487c81d4e19d3ed8cd6f
Alamat kod:www.cn/fee: https://www.php. db3a5402aac9db25cc5d1.1 Daripada pertanyaan teks kepada pertanyaan pelbagai mod
: Dengan peningkatan imej dan teks pra-latihan, dengan semantik teks terbuka, pengesanan sasaran telah memasuki peringkat secara beransur-ansur persepsi dunia terbuka. Untuk tujuan ini, banyak model pengesanan besar mengikut corak pertanyaan teks, yang menggunakan perihalan teks kategori untuk menanyakan sasaran yang berpotensi dalam imej sasaran. Walau bagaimanapun, pendekatan ini sering menghadapi masalah "luas tetapi tidak tepat".
Sebagai contoh, (1) objek berbutir halus (spesies ikan) pengesanan dalam Rajah 1, selalunya sukar untuk menerangkan pelbagai spesies ikan berbutir halus dengan teks terhad, (2) kesamaran kategori
("kelawar" kedua-duanya Ia boleh merujuk kepada kedua-dua kelawar dan kelawar). Walau bagaimanapun, masalah di atas boleh diselesaikan melalui contoh imej Berbanding dengan teks, imej boleh memberikan petunjuk ciri yang lebih kaya objek sasaran, tetapi pada masa yang sama, teks mempunyai
generalisasi yang berkuasa. Oleh itu, cara menggabungkan kedua-dua kaedah pertanyaan secara organik telah menjadi idea semula jadi.
Kesukaran mendapatkan keupayaan pertanyaan berbilang modal: Bagaimana untuk mendapatkan model sedemikian dengan pertanyaan berbilang modal, terdapat tiga cabaran: (1) Penalaan halus secara langsung dengan contoh imej yang terhad boleh membawa kepada pelupaan yang dahsyat; ) ) Melatih model pengesanan besar dari awal akan mempunyai generalisasi yang lebih baik tetapi akan menggunakan banyak wang Sebagai contoh, latihan GLIP pada satu kad memerlukan 30 juta volum data untuk 480 hari latihan.
Pengesanan sasaran pertanyaan berbilang modal: Berdasarkan pertimbangan di atas, penulis mencadangkan reka bentuk model dan strategi latihan yang mudah dan berkesan - MQ-Det.
MQ-Det memasukkan sebilangan kecil modul persepsi berpagar (GCP) berdasarkan model pengesanan pertanyaan teks beku besar sedia ada untuk menerima input daripada contoh visual Pada masa yang sama, ia mereka bentuk ramalan bahasa topeng keadaan visual strategi latihan untuk mendapatkan pengesan A berkualiti tinggi dengan cekap untuk pertanyaan multimodal prestasi.
1.2 Seni bina model pertanyaan berbilang mod plug-and-play MQ-Det
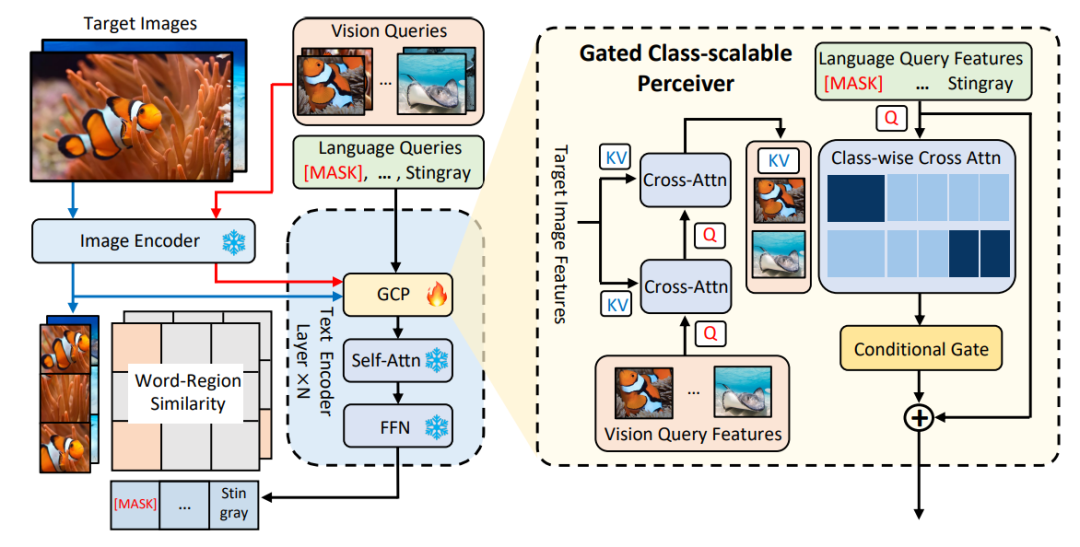
△Rajah 1 Gambar rajah seni bina kaedah MQ-Det
Modul penderiaan berpagar
As ditunjukkan dalam Rajah 1. pengekod hujung model besar pengesanan pertanyaan teks beku dimasukkan ke dalam modul persepsi berpagar (GCP) lapisan demi lapisan Mod kerja GCP boleh dinyatakan secara ringkas dengan formula berikut:
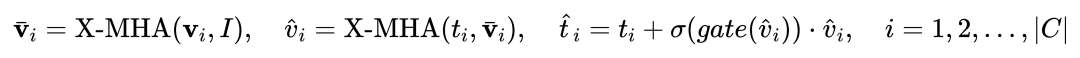
Untuk ke-i. kategori, input Contoh visual Vi mula-mula melakukan perhatian silang (X-MHA) dengan imej sasaran I untuk mendapatkan 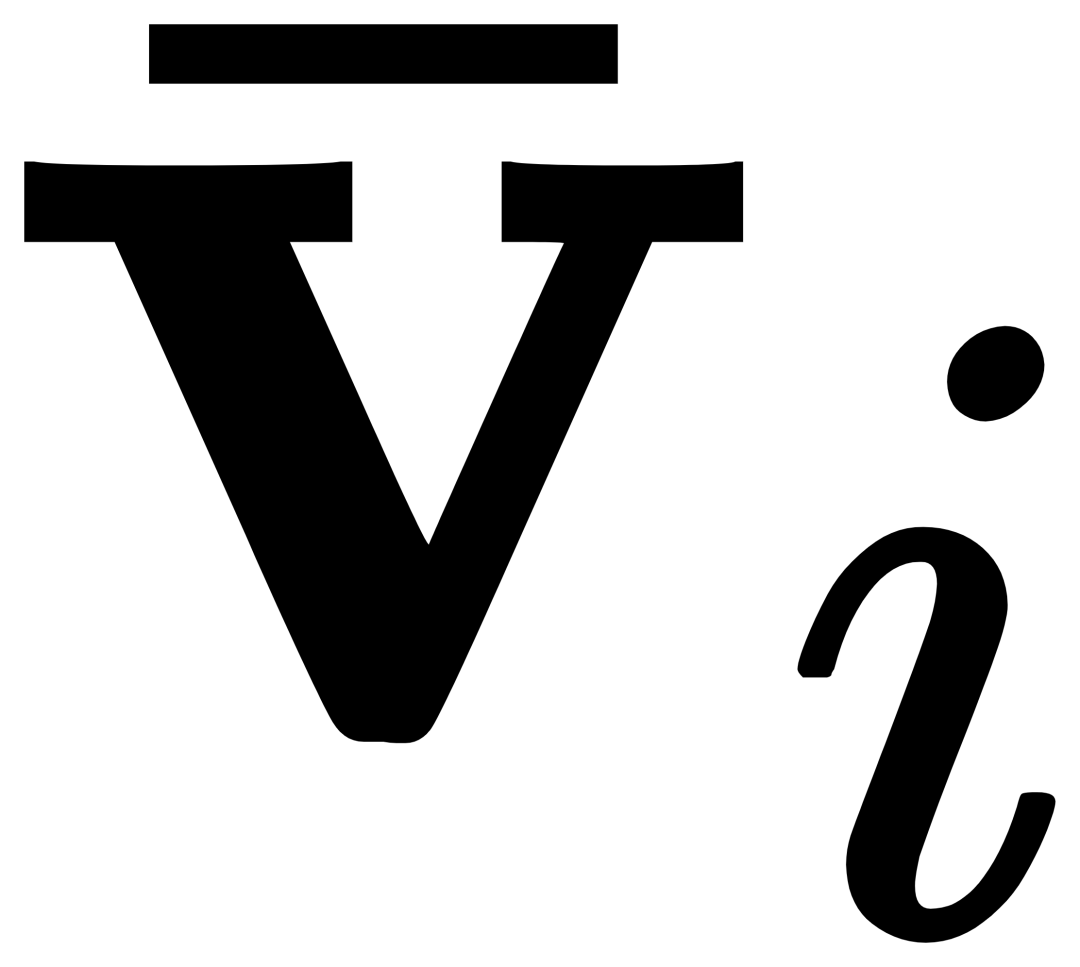 untuk meningkatkan keupayaan perwakilannya, dan kemudian setiap teks kategori ti akan melakukan perhatian silang dengan contoh visual
untuk meningkatkan keupayaan perwakilannya, dan kemudian setiap teks kategori ti akan melakukan perhatian silang dengan contoh visual 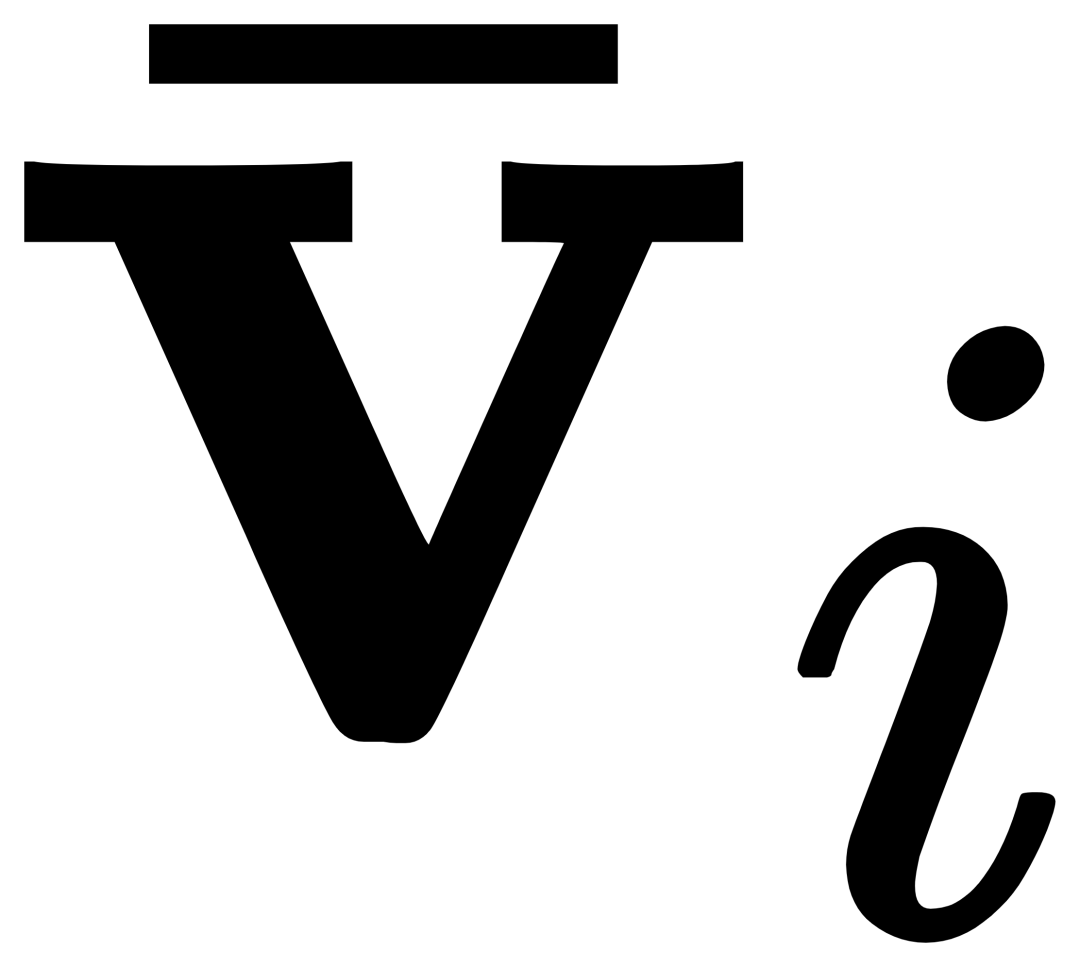 yang sepadan kategori untuk mendapatkan
yang sepadan kategori untuk mendapatkan 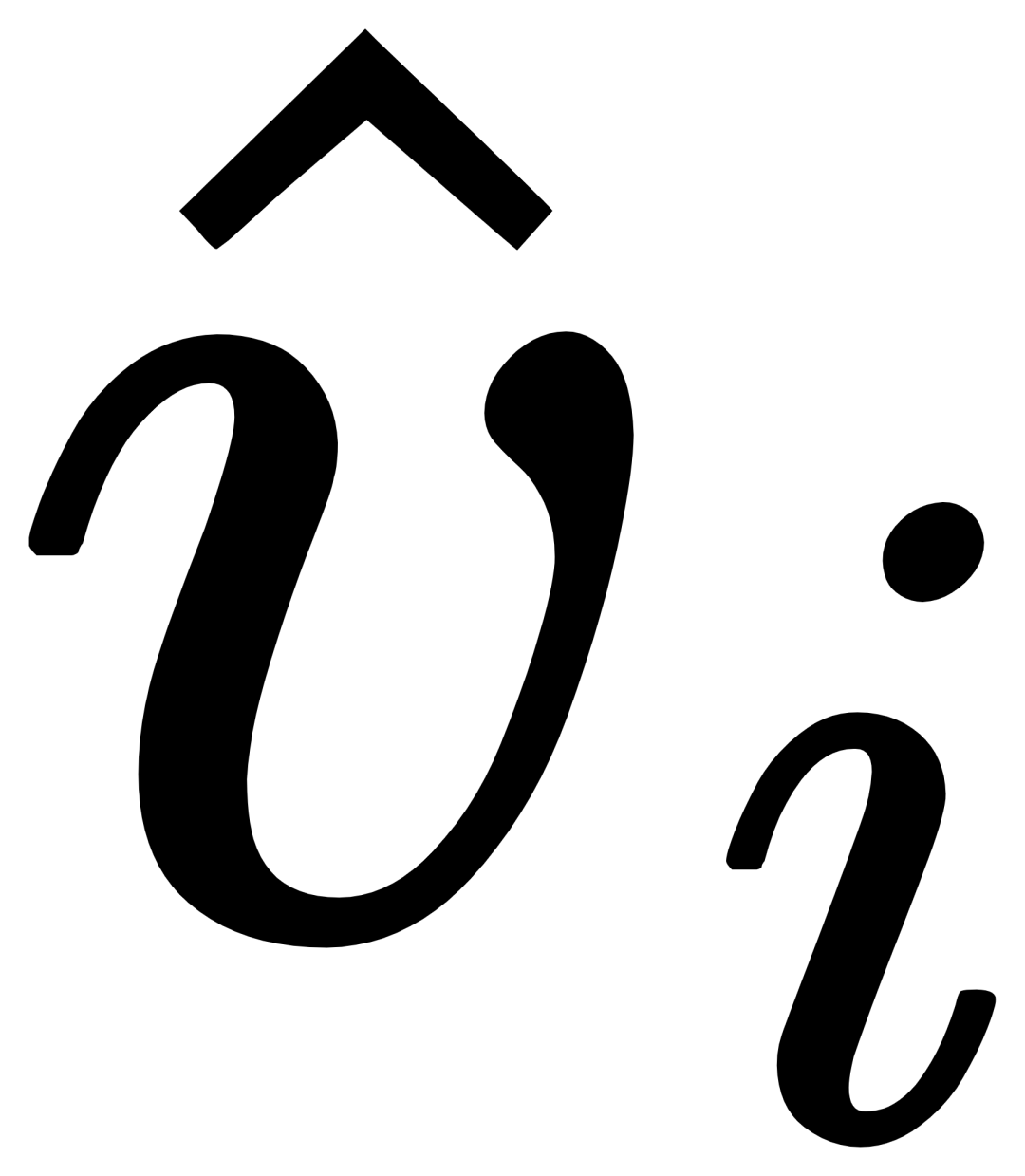 , dan kemudian menggabungkan teks asal ti dan teks ditambah secara visual
, dan kemudian menggabungkan teks asal ti dan teks ditambah secara visual 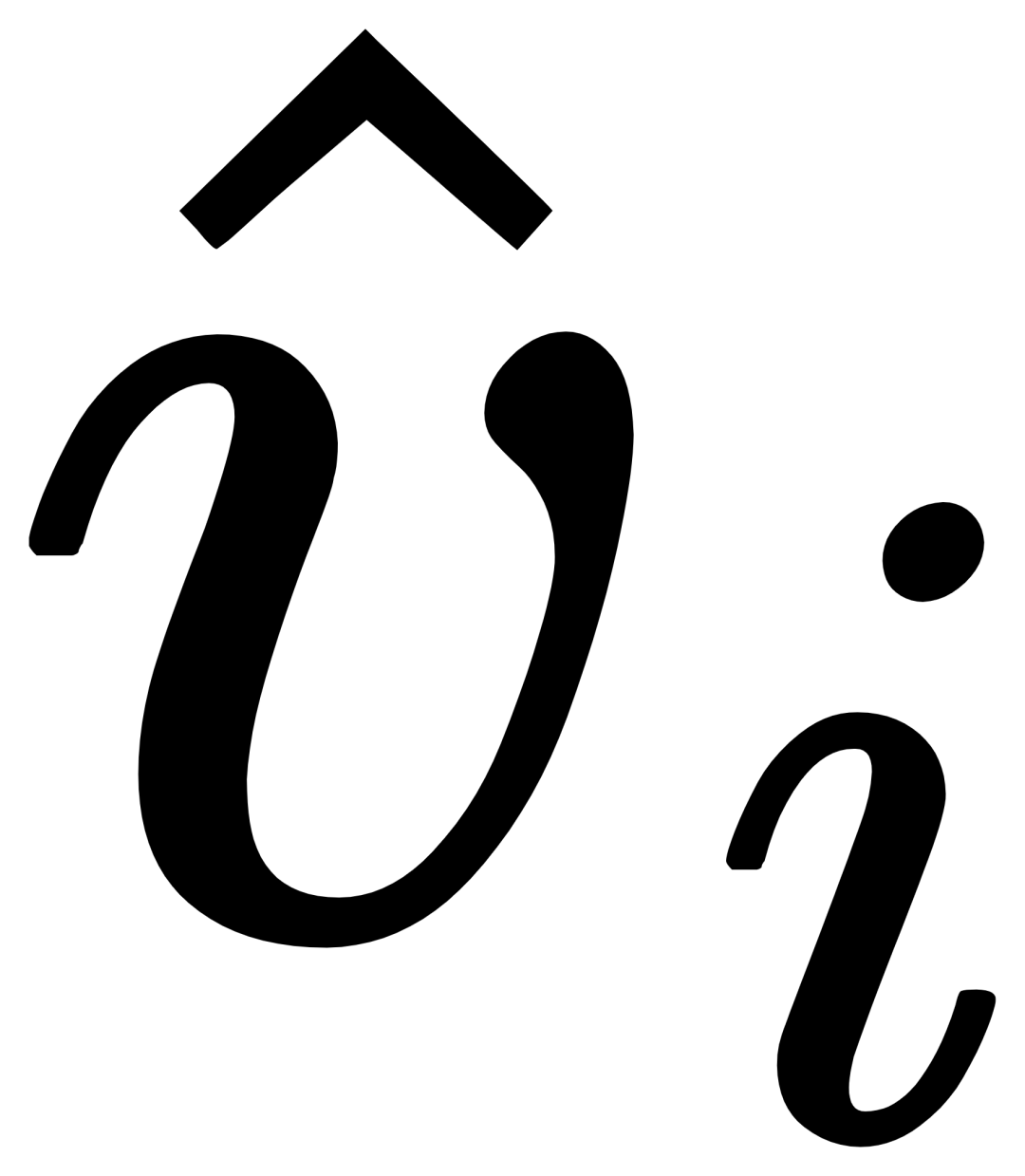 melalui gerbang modul gating untuk mendapatkan output lapisan semasa
melalui gerbang modul gating untuk mendapatkan output lapisan semasa 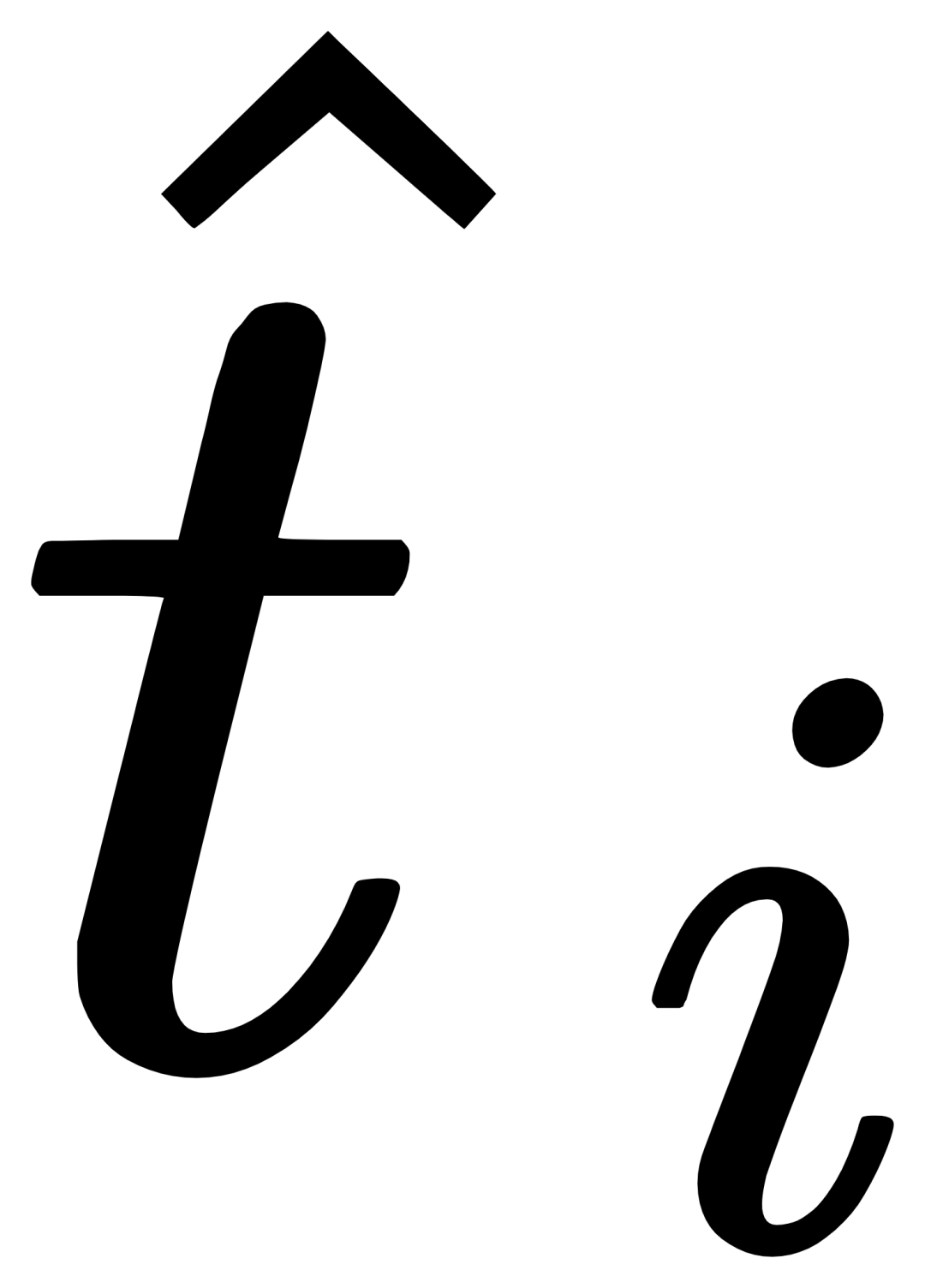 . Reka bentuk yang mudah itu mengikut tiga prinsip: (1) Kebolehskalaan kategori; (2) Penyempurnaan semantik;
. Reka bentuk yang mudah itu mengikut tiga prinsip: (1) Kebolehskalaan kategori; (2) Penyempurnaan semantik;
1.3 MQ-Det strategi latihan cekap
Latihan modulasi berdasarkan pengesan pertanyaan bahasa beku
Memandangkan model pengesanan pra-latihan besar semasa pertanyaan teks itu sendiri mempunyai generalisasi yang baik, pengarang kertas percaya bahawa hanya Just make sedikit pelarasan dengan butiran visual berdasarkan ciri teks asal.
Terdapat juga demonstrasi percubaan khusus dalam artikel yang mendapati penalaan halus selepas membuka parameter model asal yang telah dilatih dengan mudah boleh membawa kepada masalah pelupaan bencana, dan sebaliknya kehilangan keupayaan untuk mengesan dunia terbuka.
Oleh itu, MQ-Det boleh memasukkan maklumat visual dengan cekap ke dalam pengesan pertanyaan teks sedia ada dengan hanya memodulasi modul GCP terlatih berdasarkan pengesan pra-latihan pertanyaan teks beku.
Dalam kertas kerja, penulis menggunakan reka bentuk struktur dan teknologi latihan MQ-Det pada model SOTA semasa GLIP dan GroundingDINO masing-masing untuk mengesahkan kepelbagaian kaedah.
Strategi latihan ramalan bahasa bertopeng berpenglihatan
Pengarang juga mencadangkan strategi latihan ramalan bahasa bertopeng berpenglihatan untuk menyelesaikan masalah inersia pembelajaran yang disebabkan oleh pembekuan model pra-latihan.
Apa yang dipanggil inersia pembelajaran bermakna pengesan cenderung untuk mengekalkan ciri pertanyaan teks asal semasa proses latihan, dengan itu mengabaikan ciri pertanyaan visual yang baru ditambah.
Untuk tujuan ini, MQ-Det secara rawak menggantikan token teks dengan token [MASK] semasa latihan, memaksa model untuk belajar dari sisi ciri pertanyaan visual, iaitu:
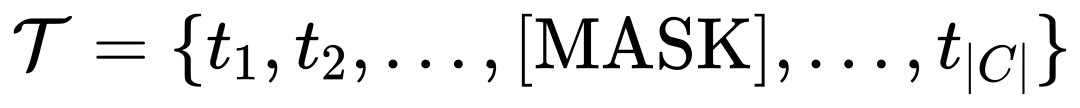
Strategi ini mudah, tetapi sangat berkesan. Keputusan eksperimen menunjukkan bahawa strategi ini membawa peningkatan prestasi yang ketara.
1.4 Keputusan eksperimen: Penilaian tanpa penalaan
Tanpa penalaan: Berbanding dengan pukulan sifar tradisional (tembakan sifar) penilaian yang hanya menggunakan teks kategori untuk ujian, MQ-Det mencadangkan penilaian Strate: yang lebih realistik bebas penalaan semula. Ia ditakrifkan sebagai: tanpa sebarang penalaan halus hiliran, pengguna boleh menggunakan teks kategori, contoh imej atau gabungan kedua-duanya untuk melakukan pengesanan objek.
Di bawah tetapan bebas penalaan, MQ-Det memilih 5 contoh visual untuk setiap kategori dan menggabungkan teks kategori untuk pengesanan sasaran Walau bagaimanapun, model sedia ada lain tidak menyokong pertanyaan visual dan hanya boleh menggunakan huraian teks biasa. Jadual di bawah menunjukkan hasil pengesanan pada LVIS MiniVal dan LVIS v1.0. Ia boleh didapati bahawa pengenalan pertanyaan berbilang modal meningkatkan keupayaan pengesanan sasaran dunia terbuka.
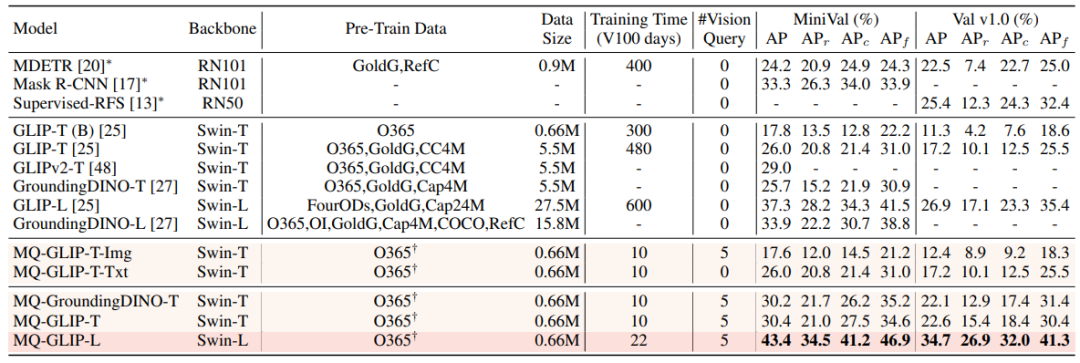
△Jadual 1 Prestasi bebas penalaan setiap model pengesanan di bawah set data penanda aras LVIS
Seperti yang dapat dilihat dari Jadual 1, MQ - GLIP-L telah meningkatkan AP lebih daripada 7% berdasarkan GLIP-L, dan kesannya sangat ketara!
1.5 Hasil eksperimen: Penilaian beberapa pukulan
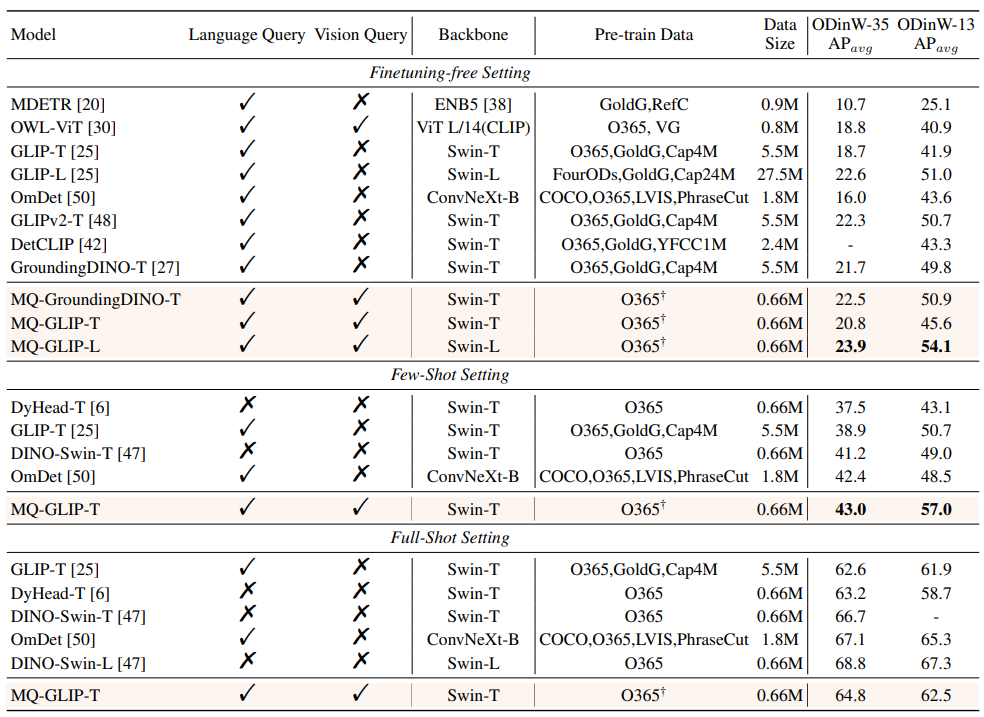
△Jadual 2 Setiap model melaksanakan tugasan pengesanan OD35 dan 35 Prestasi dalam 13 subset ODinW-13
Penulis selanjutnya menjalankan eksperimen komprehensif dalam 35 tugas pengesanan hiliran ODinW-35. Seperti yang dapat dilihat daripada Jadual 2, sebagai tambahan kepada prestasi bebas penalaan yang berkuasa, MQ-Det juga mempunyai keupayaan pengesanan sampel kecil yang baik, yang mengesahkan lagi potensi pertanyaan berbilang modal. Rajah 2 juga menunjukkan peningkatan ketara MQ-Det pada GLIP.
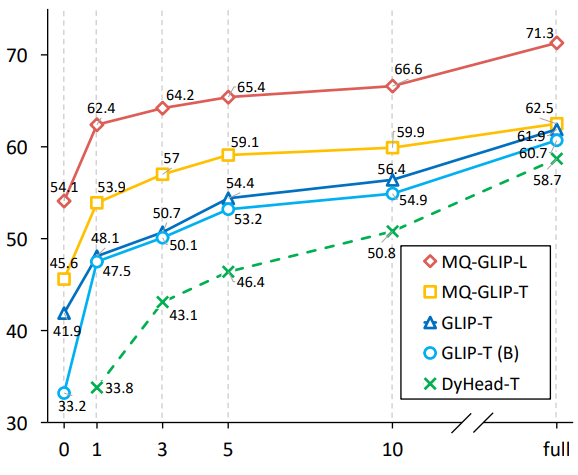
△Rajah 2 Perbandingan kecekapan penggunaan data: bilangan sampel latihan, paksi menegak: purata AP pada OdinW-13#🎜🎜; # 🎜🎜#1.6 Prospek pengesanan sasaran pertanyaan berbilang mod
Sebagai bidang penyelidikan berdasarkan aplikasi praktikal, pengesanan sasaran sangat mementingkan pelaksanaan algoritma.
Walaupun model pengesanan sasaran pertanyaan teks biasa sebelumnya telah menunjukkan generalisasi yang baik, dalam pengesanan dunia terbuka sebenar, adalah sukar untuk teks merangkumi maklumat terperinci dan butiran maklumat yang kaya dalam imej Lengkapkan pautan ini dengan sempurna .
Setakat ini kita dapati bahawa teks adalah umum tetapi tidak tepat, dan imej adalah tepat tetapi tidak umum Jika kita boleh menggabungkan kedua-duanya dengan berkesan, iaitu pertanyaan berbilang modal, ia akan mendorong dunia terbuka pengesanan sasaran lebih jauh ke hadapan.
MQ-Det telah mengambil langkah pertama dalam pertanyaan berbilang modal, dan peningkatan prestasi ketaranya juga menunjukkan potensi besar pengesanan sasaran pertanyaan berbilang modal.
Pada masa yang sama, pengenalan penerangan teks dan contoh visual memberikan pengguna lebih banyak pilihan, menjadikan pengesanan sasaran lebih fleksibel dan mesra pengguna.
Atas ialah kandungan terperinci Mari lihat gambar model besar dengan lebih berkesan daripada menaip! Penyelidikan baharu dalam NeurIPS 2023 mencadangkan kaedah pertanyaan berbilang modal, meningkatkan ketepatan sebanyak 7.8%. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1383
1383
 52
52

 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 Apr 09, 2024 am 11:52 AM
Apr 09, 2024 am 11:52 AM
AI memang mengubah matematik. Baru-baru ini, Tao Zhexuan, yang telah mengambil perhatian terhadap isu ini, telah memajukan keluaran terbaru "Buletin Persatuan Matematik Amerika" (Buletin Persatuan Matematik Amerika). Memfokuskan pada topik "Adakah mesin akan mengubah matematik?", ramai ahli matematik menyatakan pendapat mereka Seluruh proses itu penuh dengan percikan api, tegar dan menarik. Penulis mempunyai barisan yang kuat, termasuk pemenang Fields Medal Akshay Venkatesh, ahli matematik China Zheng Lejun, saintis komputer NYU Ernest Davis dan ramai lagi sarjana terkenal dalam industri. Dunia AI telah berubah secara mendadak Anda tahu, banyak artikel ini telah dihantar setahun yang lalu.
 Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Prestasi JAX, yang dipromosikan oleh Google, telah mengatasi Pytorch dan TensorFlow dalam ujian penanda aras baru-baru ini, menduduki tempat pertama dalam 7 penunjuk. Dan ujian tidak dilakukan pada TPU dengan prestasi JAX terbaik. Walaupun dalam kalangan pembangun, Pytorch masih lebih popular daripada Tensorflow. Tetapi pada masa hadapan, mungkin lebih banyak model besar akan dilatih dan dijalankan berdasarkan platform JAX. Model Baru-baru ini, pasukan Keras menanda aras tiga hujung belakang (TensorFlow, JAX, PyTorch) dengan pelaksanaan PyTorch asli dan Keras2 dengan TensorFlow. Pertama, mereka memilih satu set arus perdana
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Video terbaru robot Tesla Optimus dikeluarkan, dan ia sudah boleh berfungsi di kilang. Pada kelajuan biasa, ia mengisih bateri (bateri 4680 Tesla) seperti ini: Pegawai itu juga mengeluarkan rupanya pada kelajuan 20x - pada "stesen kerja" kecil, memilih dan memilih dan memilih: Kali ini ia dikeluarkan Salah satu sorotan video itu ialah Optimus menyelesaikan kerja ini di kilang, sepenuhnya secara autonomi, tanpa campur tangan manusia sepanjang proses. Dan dari perspektif Optimus, ia juga boleh mengambil dan meletakkan bateri yang bengkok, memfokuskan pada pembetulan ralat automatik: Berkenaan tangan Optimus, saintis NVIDIA Jim Fan memberikan penilaian yang tinggi: Tangan Optimus adalah robot lima jari di dunia paling cerdik. Tangannya bukan sahaja boleh disentuh
 FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
Pengesanan objek ialah masalah yang agak matang dalam sistem pemanduan autonomi, antaranya pengesanan pejalan kaki adalah salah satu algoritma terawal untuk digunakan. Penyelidikan yang sangat komprehensif telah dijalankan dalam kebanyakan kertas kerja. Walau bagaimanapun, persepsi jarak menggunakan kamera fisheye untuk pandangan sekeliling agak kurang dikaji. Disebabkan herotan jejari yang besar, perwakilan kotak sempadan standard sukar dilaksanakan dalam kamera fisheye. Untuk mengurangkan perihalan di atas, kami meneroka kotak sempadan lanjutan, elips dan reka bentuk poligon am ke dalam perwakilan kutub/sudut dan mentakrifkan metrik mIOU pembahagian contoh untuk menganalisis perwakilan ini. Model fisheyeDetNet yang dicadangkan dengan bentuk poligon mengatasi model lain dan pada masa yang sama mencapai 49.5% mAP pada set data kamera fisheye Valeo untuk pemanduan autonomi
 Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Pautan projek ditulis di hadapan: https://nianticlabs.github.io/mickey/ Memandangkan dua gambar, pose kamera di antara mereka boleh dianggarkan dengan mewujudkan kesesuaian antara gambar. Biasanya, surat-menyurat ini adalah 2D hingga 2D, dan anggaran pose kami adalah skala-tak tentu. Sesetengah aplikasi, seperti realiti tambahan segera pada bila-bila masa, di mana-mana sahaja, memerlukan anggaran pose metrik skala, jadi mereka bergantung pada penganggar kedalaman luaran untuk memulihkan skala. Makalah ini mencadangkan MicKey, proses pemadanan titik utama yang mampu meramalkan korespondensi metrik dalam ruang kamera 3D. Dengan mempelajari padanan koordinat 3D merentas imej, kami dapat membuat kesimpulan relatif metrik
