
 Peranti teknologi
AI
LeCun sekali lagi memburukkan LLM autoregresif: Keupayaan penaakulan GPT-4 sangat terhad, seperti yang dibuktikan oleh dua kertas
Peranti teknologi
AI
LeCun sekali lagi memburukkan LLM autoregresif: Keupayaan penaakulan GPT-4 sangat terhad, seperti yang dibuktikan oleh dua kertas
LeCun sekali lagi memburukkan LLM autoregresif: Keupayaan penaakulan GPT-4 sangat terhad, seperti yang dibuktikan oleh dua kertas

"Sesiapa yang berpendapat bahawa LLM auto-regresif sudah menghampiri AI peringkat manusia, atau ia hanya perlu meningkatkan untuk mencapai AI peringkat manusia, mesti membaca ini. Penaakulan dan perancangan AR-LLM keupayaan Sangat terhad. Untuk menyelesaikan masalah ini, ia tidak boleh diselesaikan dengan menjadikannya lebih besar dan berlatih dengan lebih banyak data # Pemenang Anugerah Turing Yann LeCun sentiasa menjadi "penyoal" LLM, dan model autoregresif ialah pembelajaran. paradigma yang bergantung kepada siri GPT model LLM. Beliau telah menyatakan secara terbuka kritikannya terhadap autoregresi dan LLM lebih daripada sekali, dan telah menghasilkan banyak ayat emas, seperti:
"Model Generatif Auto-Regresif menyebalkan!"
#🎜 🎜#"LLM mempunyai pemahaman yang sangat cetek tentang dunia."
"LLM benar-benar boleh mengkritik diri sendiri (dan berulang) seperti yang dikatakan oleh kesusasteraan Improve) penyelesaiannya? Dua kertas kerja baharu daripada kumpulan kami periksa dakwaan ini dalam tugas penaakulan (https://arxiv.org/abs/2310.12397) dan perancangan (https://arxiv.org/abs/2310.08118) yang disiasat (dan disoal "#🎜🎜 #
Nampaknya topik kedua-dua kertas kerja ini yang menyiasat keupayaan pengesahan dan kritikan diri GPT-4 telah menarik perhatian ramai.Pengarang kertas itu berkata bahawa mereka juga percaya bahawa LLM adalah "penjana idea" yang hebat (sama ada dalam bentuk bahasa atau kod), tetapi mereka tidak dapat menjamin mereka sendiri kemahiran merancang/ menaakul. Oleh itu, ia paling sesuai digunakan dalam persekitaran LLM-Modulo (sama ada penaakulan yang boleh dipercayai atau pakar manusia dalam gelung). Kritikan diri memerlukan pengesahan, dan pengesahan ialah satu bentuk penaakulan (jadi terkejut dengan semua dakwaan tentang keupayaan LLM untuk mengkritik diri).

Pada masa yang sama, keraguan juga wujud: "Keupayaan penaakulan rangkaian konvolusi adalah lebih terhad, tetapi ini tidak menghalang kerja AlphaZero daripada muncul. Ini semua tentang proses penaakulan dan gelung maklum balas yang mantap (RL) Saya fikir keupayaan model membolehkan inferens yang sangat mendalam (mis. Ini dilakukan melalui carian pokok Monte Carlo, menggunakan rangkaian konvolusi untuk menghasilkan tindakan yang baik dan rangkaian konvolusi lain untuk menilai kedudukan. Masa yang dihabiskan untuk meneroka pokok itu boleh menjadi tidak terhingga, itu semua penaakulan dan perancangan. "
Pada masa hadapan, topik sama ada LLM autoregresif mempunyai keupayaan penaakulan dan perancangan mungkin tidak dimuktamadkan.
Seterusnya, kita boleh lihat perkara yang dibincangkan oleh kedua-dua kertas kerja baharu ini.
Kertas 1: GPT-4 Tidak Tahu Ia Salah: Satu Analisis Terhadap Masalah Penaakulan Berulang#🎜🎜 🎜🎜#
Kertas pertama menyebabkan penyelidik mempersoalkan keupayaan mengkritik diri LLM yang paling maju, termasuk GPT-4. 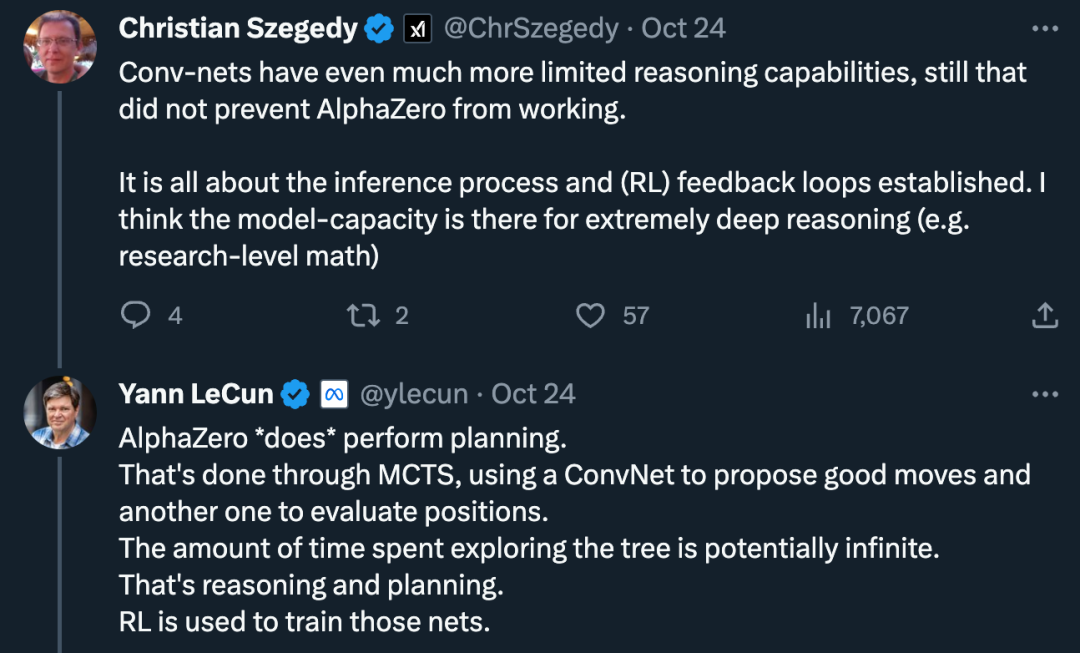
Alamat kertas: https://arxiv.org/pdf/2310.12397.pdf#🎜🎜 🎜#Seterusnya mari lihat pengenalan kertas kerja.
Selalu ada perselisihan pendapat tentang keupayaan inferens model bahasa besar (LLMs) Pada mulanya, penyelidik optimis bahawa keupayaan inferens LLM meningkat dengan saiz model. Penskalaan akan berlaku secara automatik, bagaimanapun, apabila lebih banyak kes kegagalan muncul, jangkaan menjadi kurang sengit. Selepas itu, penyelidik secara amnya percaya bahawa LLM mempunyai keupayaan untuk mengkritik sendiri dan menambah baik penyelesaian LLM secara berulang, dan pandangan ini telah disebarkan secara meluas.
Namun, adakah ini benar-benar berlaku?
Penyelidik dari Arizona State University menguji keupayaan penaakulan LLM dalam kajian baharu. Secara khusus, mereka menumpukan pada keberkesanan gesaan berulang dalam masalah pewarnaan graf, salah satu masalah lengkap NP yang paling terkenal.
Kajian ini menunjukkan bahawa (i) LLM tidak pandai menyelesaikan kejadian pewarnaan graf (ii) LLM tidak pandai mengesahkan penyelesaian dan oleh itu tidak berkesan dalam mod lelaran. Hasil kertas kerja ini menimbulkan persoalan tentang keupayaan kritikal diri LLM yang canggih. . Lebih teruk lagi, sistem gagal mengenali warna yang betul dan berakhir dengan warna yang salah.
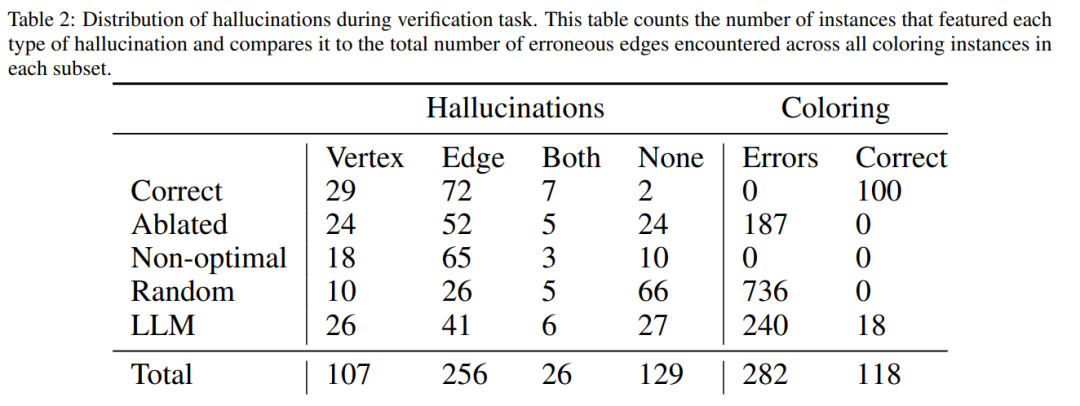
Rajah di bawah ialah penilaian masalah pewarnaan graf Dalam tetapan ini, GPT-4 boleh meneka warna dalam mod bebas dan kritikal kendiri. Di luar gelung kritikal diri terdapat pengesah suara luaran.
Hasilnya menunjukkan bahawa GPT4 kurang daripada 20% tepat pada meneka warna, dan lebih mengejutkan, mod kritikan diri (lajur kedua dalam rajah di bawah) mempunyai ketepatan yang paling rendah. Makalah ini juga mengkaji persoalan berkaitan sama ada GPT-4 akan menambah baik penyelesaiannya jika pengesah vokal luaran memberikan kritikan yang terbukti betul terhadap warna yang diduganya. Dalam kes ini, pembayang terbalik benar-benar boleh meningkatkan prestasi. 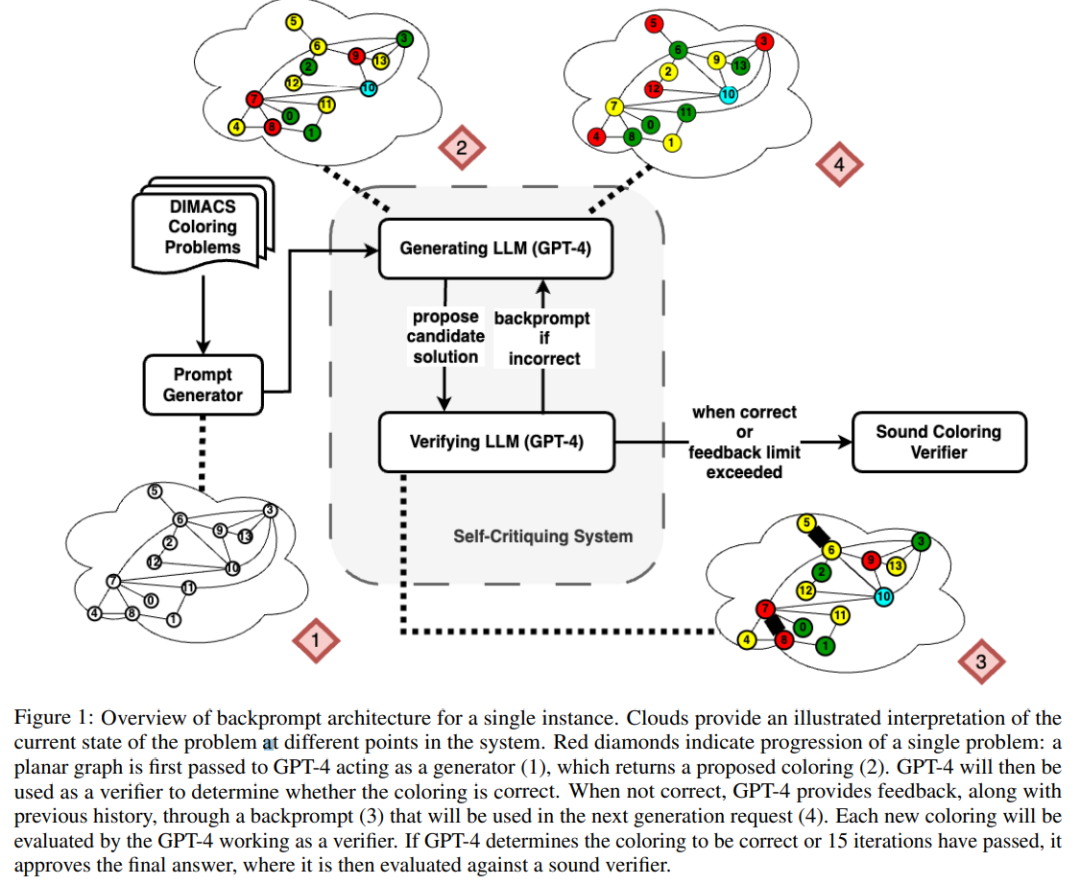
Walaupun GPT-4 secara tidak sengaja meneka warna yang sah, kritikan kendirinya mungkin menyebabkan ia berhalusinasi bahawa tiada pelanggaran. Secara kebetulan, penulis memberikan ringkasan, mengenai masalah pewarna graf: 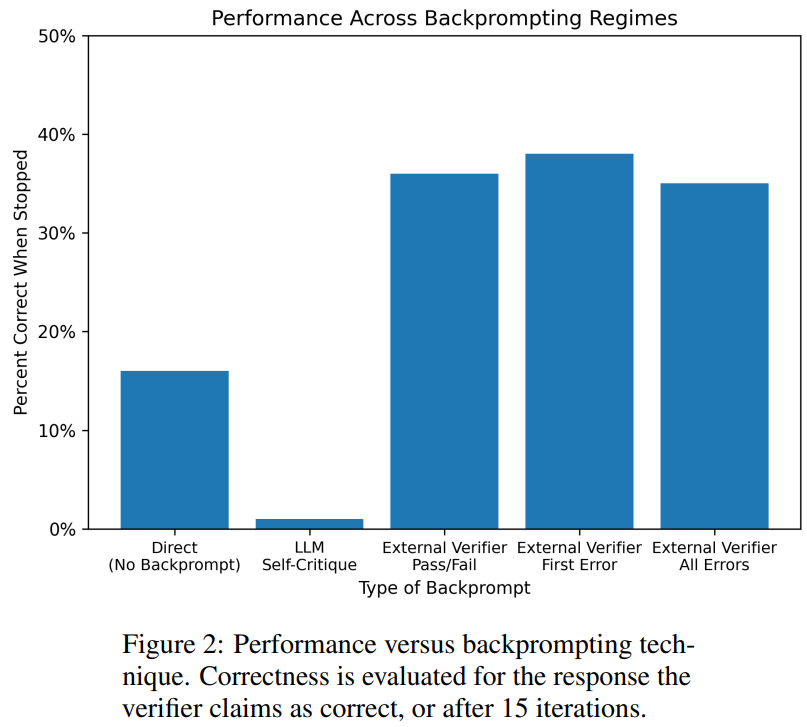
diri-kritikan sebenarnya akan membahayakan prestasi LLM, kerana GPT-4 adalah mengerikan pada pengesahan; Maklum balas Pengesah luar sememangnya boleh meningkatkan prestasi LLM. . pasukan Keupayaan LLM untuk mengesahkan/mengkritik sendiri dalam situasi perancangan telah diterokai.
- Alamat kertas: https://arxiv.org/abs/2310.08118
- Anehnya, hasil penyelidikan menunjukkan bahawa kritikan kendiri boleh mengurangkan prestasi penjanaan pengesahan pelan, terutamanya dengan LLM penjanaan pengesahan pelan. sistem pengesah. LLM boleh menghasilkan sejumlah besar mesej ralat, dengan itu menjejaskan kebolehpercayaan sistem.
Penilaian empirikal penyelidik terhadap domain perancangan AI klasik Blocksworld menyerlahkan bahawa fungsi kritikan kendiri LLM tidak berkesan dalam merancang masalah. Pengesah boleh menghasilkan sejumlah besar ralat, yang memudaratkan kebolehpercayaan keseluruhan sistem, terutamanya di kawasan di mana ketepatan perancangan adalah kritikal. Menariknya, sifat maklum balas (maklum balas binari atau terperinci) tidak mempunyai kesan ketara ke atas prestasi penjanaan rancangan, menunjukkan bahawa isu teras terletak pada keupayaan pengesahan binari LLM dan bukannya butiran maklum balas.
Seperti yang ditunjukkan dalam rajah di bawah, seni bina penilaian kajian ini merangkumi 2 LLM - penjana LLM + pengesah LLM. Untuk contoh tertentu, penjana LLM bertanggungjawab menjana pelan calon, manakala pengesah LLM menentukan ketepatannya. Jika rancangan didapati tidak betul, pengesah memberikan maklum balas yang memberi sebab kesilapannya. Maklum balas ini kemudiannya dipindahkan ke penjana LLM, yang menggesa penjana LLM untuk menjana pelan calon baharu. Semua eksperimen dalam kajian ini menggunakan GPT-4 sebagai LLM lalai.
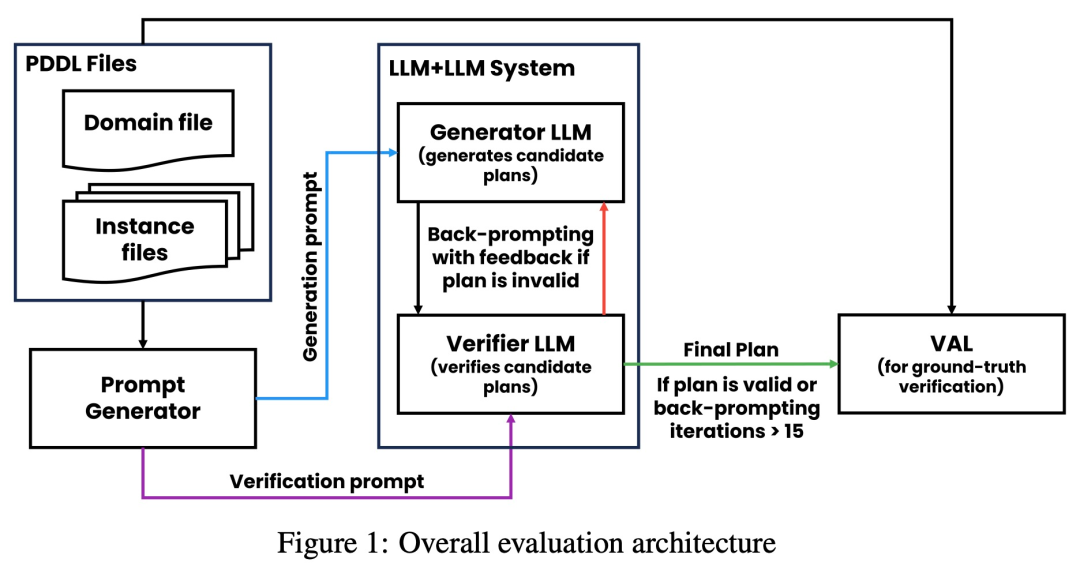
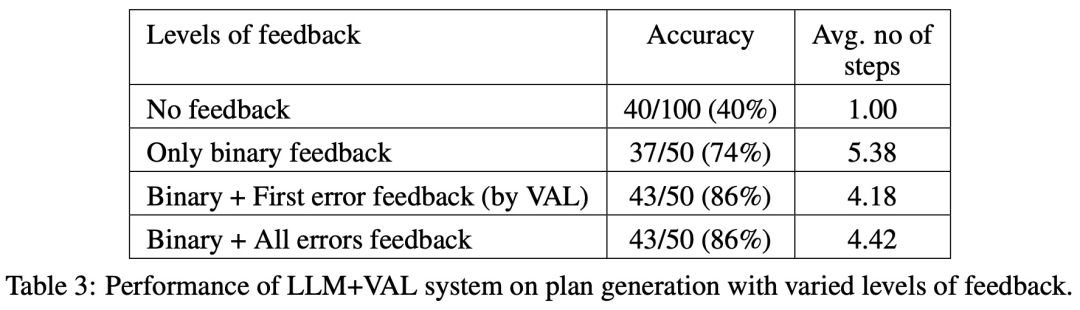
Kajian ini menguji dan membandingkan beberapa kaedah penjanaan pelan di Blocksworld. Secara khusus, kajian ini menghasilkan 100 contoh rawak untuk penilaian pelbagai kaedah. Untuk memberikan penilaian yang realistik tentang ketepatan perancangan LLM akhir, kajian ini menggunakan pengesah luaran VAL.
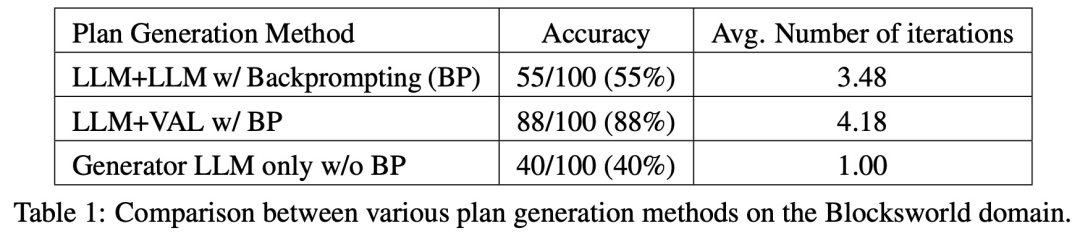
Seperti yang ditunjukkan dalam Jadual 1, kaedah backprompt LLM+LLM adalah lebih baik sedikit daripada kaedah bukan backprompt dari segi ketepatan.
Daripada 100 kejadian, pengesah mengenal pasti 61 (61%) dengan tepat.
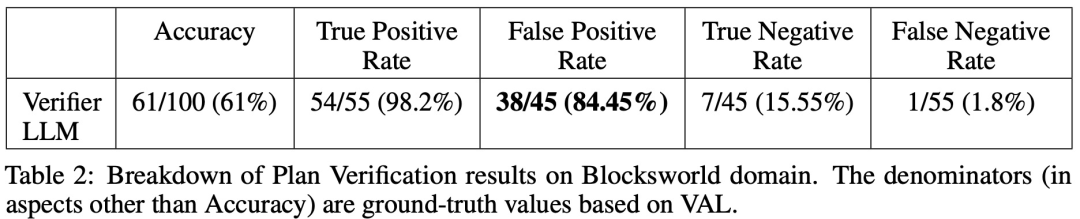
Jadual di bawah menunjukkan prestasi LLM apabila menerima tahap maklum balas yang berbeza (termasuk tiada maklum balas).
Atas ialah kandungan terperinci LeCun sekali lagi memburukkan LLM autoregresif: Keupayaan penaakulan GPT-4 sangat terhad, seperti yang dibuktikan oleh dua kertas. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Platform Perdagangan Web3 Ranking_Web3 Global Exchanges Top Ten Ringkasan
Apr 21, 2025 am 10:45 AM
Platform Perdagangan Web3 Ranking_Web3 Global Exchanges Top Ten Ringkasan
Apr 21, 2025 am 10:45 AM
Binance adalah tuan rumah ekosistem perdagangan aset digital global, dan ciri -cirinya termasuk: 1. Jumlah dagangan harian purata melebihi $ 150 bilion, menyokong 500 pasangan perdagangan, yang meliputi 98% mata wang arus perdana; 2. Matriks inovasi meliputi pasaran Derivatif, susun atur Web3 dan sistem pendidikan; 3. Kelebihan teknikal adalah enjin yang sepadan dengan milisaat, dengan jumlah pemprosesan puncak sebanyak 1.4 juta transaksi sesaat; 4. Kemajuan pematuhan memegang lesen 15 negara dan menetapkan entiti yang mematuhi di Eropah dan Amerika Syarikat.
 Ramalan Harga Worldcoin (WLD) 2025-2031: Adakah WLD akan mencapai $ 4 menjelang 2031?
Apr 21, 2025 pm 02:42 PM
Ramalan Harga Worldcoin (WLD) 2025-2031: Adakah WLD akan mencapai $ 4 menjelang 2031?
Apr 21, 2025 pm 02:42 PM
Worldcoin (WLD) menonjol dalam pasaran cryptocurrency dengan mekanisme pengesahan biometrik dan perlindungan privasi yang unik, menarik perhatian banyak pelabur. WLD telah melakukan yang luar biasa di kalangan altcoin dengan teknologi inovatifnya, terutamanya dalam kombinasi dengan teknologi kecerdasan buatan terbuka. Tetapi bagaimanakah aset digital akan berkelakuan dalam beberapa tahun akan datang? Mari kita meramalkan harga masa depan WLD bersama -sama. Ramalan harga WLD 2025 dijangka mencapai pertumbuhan yang signifikan di WLD pada tahun 2025. Analisis pasaran menunjukkan bahawa harga WLD purata boleh mencapai $ 1.31, dengan maksimum $ 1.36. Walau bagaimanapun, dalam pasaran beruang, harga mungkin jatuh ke sekitar $ 0.55. Harapan pertumbuhan ini disebabkan terutamanya oleh WorldCoin2.
 Apakah yang dimaksudkan dengan transaksi rantaian rantaian? Apakah urus niaga salib?
Apr 21, 2025 pm 11:39 PM
Apakah yang dimaksudkan dengan transaksi rantaian rantaian? Apakah urus niaga salib?
Apr 21, 2025 pm 11:39 PM
Pertukaran yang menyokong urus niaga rantaian: 1. Binance, 2. Uniswap, 3 Sushiswap, 4. Kewangan Curve, 5. Thorchain, 6. 1 inci Pertukaran, 7.
 Kedudukan pertukaran leverage dalam lingkaran mata wang Cadangan terkini sepuluh pertukaran leverage dalam lingkaran mata wang
Apr 21, 2025 pm 11:24 PM
Kedudukan pertukaran leverage dalam lingkaran mata wang Cadangan terkini sepuluh pertukaran leverage dalam lingkaran mata wang
Apr 21, 2025 pm 11:24 PM
Platform yang mempunyai prestasi cemerlang dalam perdagangan, keselamatan dan pengalaman pengguna yang dimanfaatkan pada tahun 2025 adalah: 1. Okx, sesuai untuk peniaga frekuensi tinggi, menyediakan sehingga 100 kali leverage; 2. Binance, sesuai untuk peniaga berbilang mata wang di seluruh dunia, memberikan 125 kali leverage tinggi; 3. Gate.io, sesuai untuk pemain derivatif profesional, menyediakan 100 kali leverage; 4. Bitget, sesuai untuk orang baru dan peniaga sosial, menyediakan sehingga 100 kali leverage; 5. Kraken, sesuai untuk pelabur mantap, menyediakan 5 kali leverage; 6. Bybit, sesuai untuk penjelajah altcoin, menyediakan 20 kali leverage; 7. Kucoin, sesuai untuk peniaga kos rendah, menyediakan 10 kali leverage; 8. Bitfinex, sesuai untuk bermain senior
 Mengapa kenaikan atau kejatuhan harga mata wang maya? Mengapa kenaikan atau kejatuhan harga mata wang maya?
Apr 21, 2025 am 08:57 AM
Mengapa kenaikan atau kejatuhan harga mata wang maya? Mengapa kenaikan atau kejatuhan harga mata wang maya?
Apr 21, 2025 am 08:57 AM
Faktor kenaikan harga mata wang maya termasuk: 1. Peningkatan permintaan pasaran, 2. Menurunkan bekalan, 3. Berita positif yang dirangsang, 4. Sentimen pasaran optimis, 5. Persekitaran makroekonomi; Faktor penurunan termasuk: 1. Mengurangkan permintaan pasaran, 2. Peningkatan bekalan, 3.
 Platform Pertukaran Cryptocurrency Top 10 senarai pertukaran mata wang digital terbesar di dunia
Apr 21, 2025 pm 07:15 PM
Platform Pertukaran Cryptocurrency Top 10 senarai pertukaran mata wang digital terbesar di dunia
Apr 21, 2025 pm 07:15 PM
Pertukaran memainkan peranan penting dalam pasaran cryptocurrency hari ini. Mereka bukan sahaja platform untuk pelabur untuk berdagang, tetapi juga sumber kecairan pasaran dan penemuan harga. Pertukaran mata wang maya terbesar di dunia di kalangan sepuluh teratas, dan pertukaran ini bukan sahaja jauh ke hadapan dalam jumlah dagangan, tetapi juga mempunyai kelebihan mereka sendiri dalam pengalaman pengguna, perkhidmatan keselamatan dan inovatif. Pertukaran yang atas senarai biasanya mempunyai pangkalan pengguna yang besar dan pengaruh pasaran yang luas, dan jumlah dagangan dan jenis aset mereka sering sukar dicapai oleh bursa lain.
 Aavenomics adalah cadangan untuk mengubah suai token protokol AAVE dan memperkenalkan pembelian semula token, yang telah mencapai bilangan kuorum orang.
Apr 21, 2025 pm 06:24 PM
Aavenomics adalah cadangan untuk mengubah suai token protokol AAVE dan memperkenalkan pembelian semula token, yang telah mencapai bilangan kuorum orang.
Apr 21, 2025 pm 06:24 PM
Aavenomics adalah cadangan untuk mengubah token protokol AAVE dan memperkenalkan repos token, yang telah melaksanakan kuorum untuk Aavedao. Marc Zeller, pengasas Rantaian Projek AAVE (ACI), mengumumkan ini pada X, dengan menyatakan bahawa ia menandakan era baru untuk perjanjian itu. Marc Zeller, pengasas Inisiatif Rantaian AAVE (ACI), mengumumkan pada X bahawa cadangan aavenomik termasuk mengubah token protokol AAVE dan memperkenalkan repos token, telah mencapai kuorum untuk Aavedao. Menurut Zeller, ini menandakan era baru untuk perjanjian itu. Ahli -ahli Aavedao mengundi untuk menyokong cadangan itu, yang 100 seminggu pada hari Rabu
 Apakah platform perdagangan blockchain hibrid?
Apr 21, 2025 pm 11:36 PM
Apakah platform perdagangan blockchain hibrid?
Apr 21, 2025 pm 11:36 PM
Cadangan untuk memilih pertukaran cryptocurrency: 1. Untuk keperluan kecairan, keutamaan adalah Binance, Gate.io atau Okx, kerana kedalaman pesanannya dan rintangan volatilitas yang kuat. 2. Pematuhan dan Keselamatan, Coinbase, Kraken dan Gemini mempunyai sokongan pengawalseliaan yang ketat. 3. Fungsi inovatif, reka bentuk derivatif Kucoin yang lembut dan Bybit sesuai untuk pengguna lanjutan.
