
 Peranti teknologi
AI
Gabungan hebat teknologi teras RLHF dan AlphaGo, UW/Meta membawa keupayaan penjanaan teks ke tahap baharu
Peranti teknologi
AI
Gabungan hebat teknologi teras RLHF dan AlphaGo, UW/Meta membawa keupayaan penjanaan teks ke tahap baharu
Gabungan hebat teknologi teras RLHF dan AlphaGo, UW/Meta membawa keupayaan penjanaan teks ke tahap baharu

Dalam kajian terkini, penyelidik dari UW dan Meta mencadangkan algoritma penyahkodan baharu yang menggunakan algoritma Carian Pokok Monte-Carlo (MCTS) yang digunakan oleh AlphaGo kepada model bahasa On the RLHF yang dilatih oleh Pengoptimuman Dasar Proksimal (PPO), kualiti teks yang dijana oleh model itu bertambah baik.
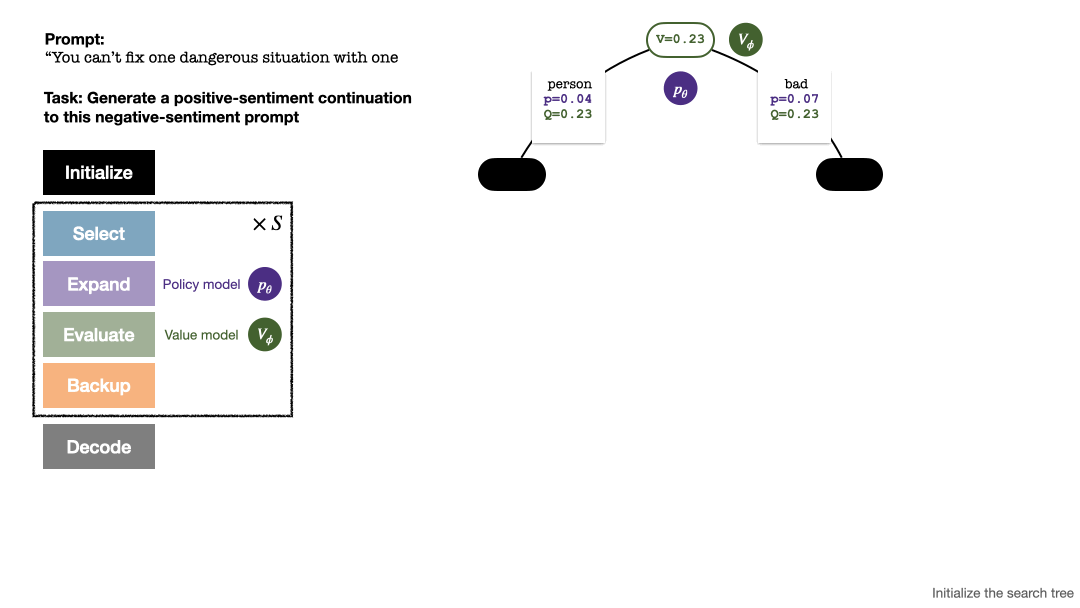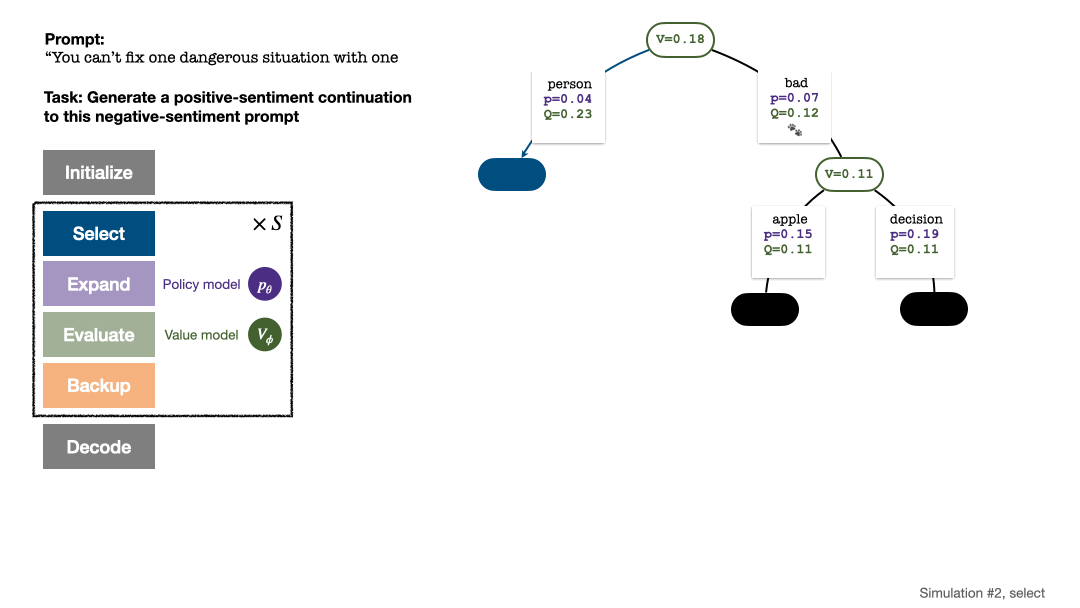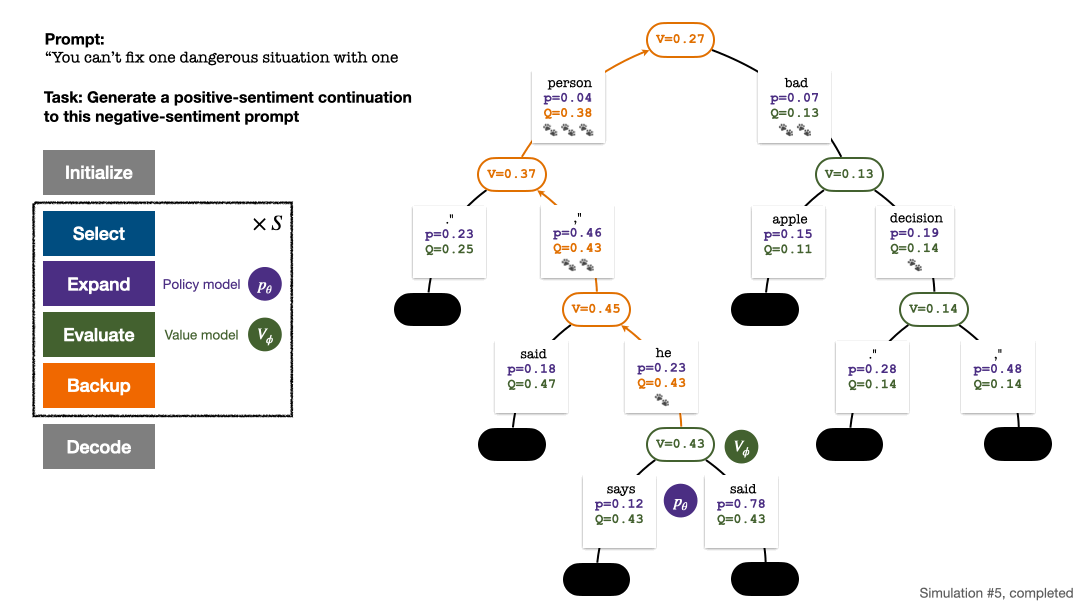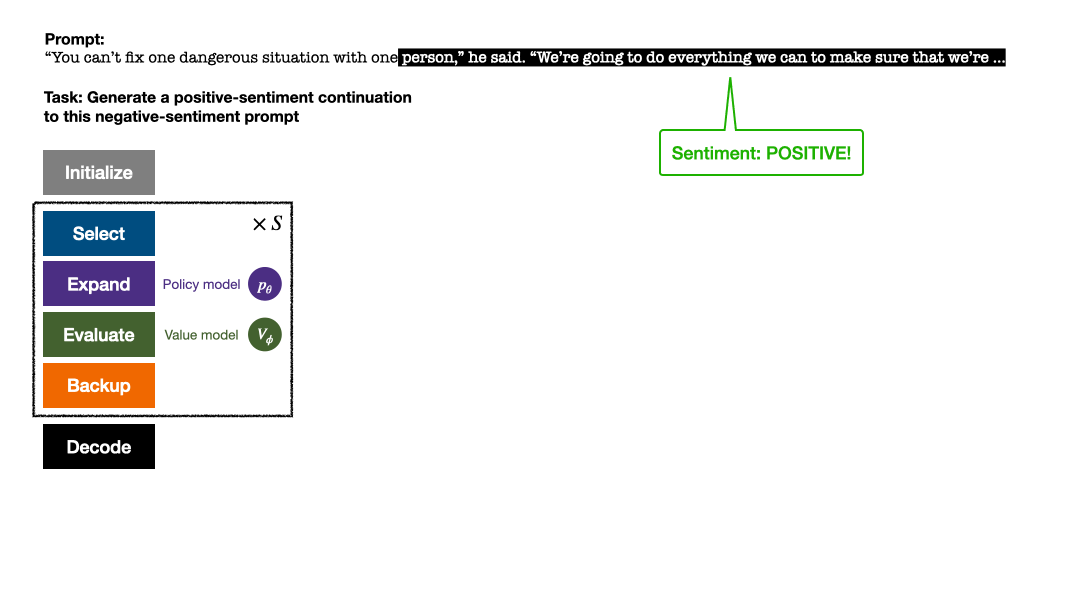
Algoritma PPO-MCTS mencari strategi penyahkodan yang lebih baik dengan meneroka dan menilai beberapa jujukan calon. Teks yang dijana oleh PPO-MCTS boleh memenuhi keperluan tugas dengan lebih baik.

Pautan kertas: https://arxiv.org/pdf/2309.15028.pdf#🎜🎜 🎜#LLM dikeluarkan untuk pengguna massa, seperti GPT-4/Claude/LLaMA-2-chat, biasanya menggunakan RLHF untuk menyelaraskan dengan pilihan pengguna. PPO telah menjadi algoritma pilihan untuk melaksanakan RLHF pada model di atas, namun apabila menggunakan model, orang sering menggunakan algoritma penyahkodan mudah (seperti pensampelan atas-p) untuk menjana teks daripada model ini.
Pengarang artikel ini mencadangkan untuk menggunakan varian algoritma Carian Pokok Monte Carlo (MCTS) untuk menyahkod daripada model PPO, dan menamakan kaedah
PPO-MCTS#🎜🎜 # . Kaedah ini bergantung pada model nilai untuk membimbing carian bagi urutan yang optimum. Oleh kerana PPO sendiri adalah algoritma pengkritik aktor, ia akan menghasilkan model nilai sebagai produk sampingan semasa latihan.PPO-MCTS mencadangkan untuk menggunakan model nilai ini untuk membimbing carian MCTS, dan utilitinya disahkan melalui perspektif teori dan eksperimen. Penulis menyeru para penyelidik dan jurutera yang menggunakan RLHF untuk melatih model untuk memelihara dan membuka sumber model nilai mereka.
PPO-MCTS algoritma penyahkodan
Untuk menjana token, PPO-MCTS akan melakukan beberapa pusingan simulasi dan secara beransur-ansur membina pokok carian . Nod pepohon mewakili awalan teks yang dijana (termasuk gesaan asal), dan tepi pepohon mewakili token yang baru dijana. PPO-MCTS mengekalkan satu siri nilai statistik pada pokok: untuk setiap nod s, mengekalkan bilangan lawatan dan nilai purata
untuk setiap tepi, mengekalkan nilai Q #🎜 🎜#. 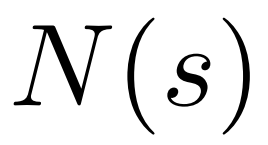
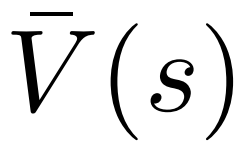
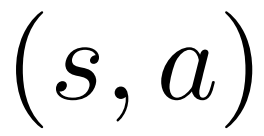
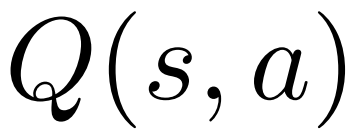
Pokok carian di penghujung simulasi lima pusingan. Nombor di tepi mewakili bilangan lawatan ke tepi itu. 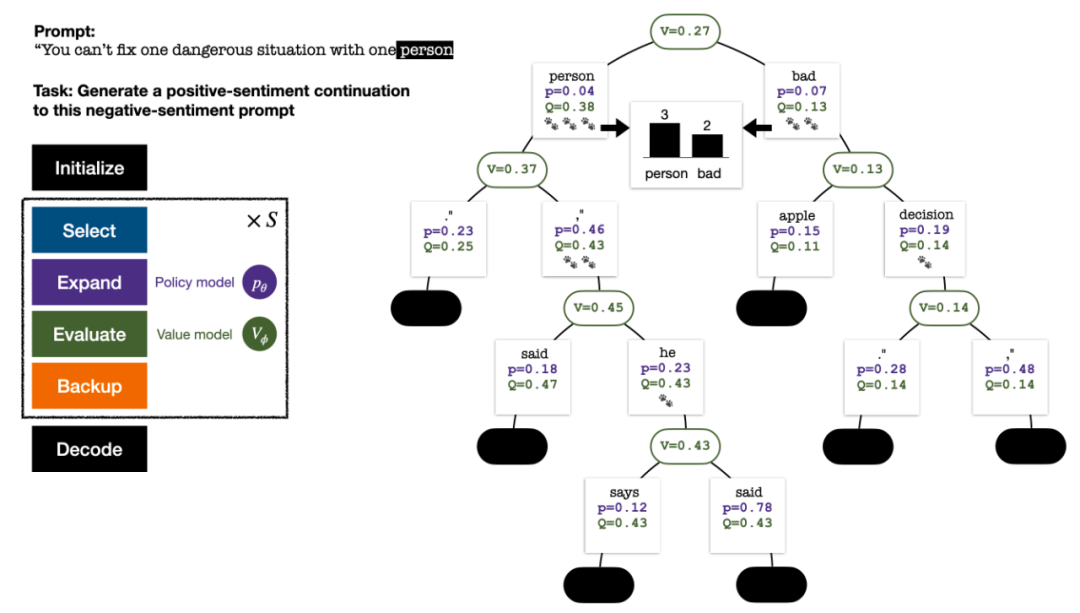
Pembinaan pokok bermula daripada nod akar yang mewakili gesaan semasa. Setiap pusingan simulasi mengandungi empat langkah berikut: 1
Pilihnod yang belum diterokai. Bermula dari nod akar, pilih tepi dan teruskan ke bawah mengikut formula PUCT berikut sehingga mencapai nod yang belum diterokai:
Formula ini lebih suka mempunyai Q A yang tinggi subtree dengan nilai tinggi dan volum akses rendah, jadi ia dapat mengimbangi penerokaan dan eksploitasi dengan lebih baik.
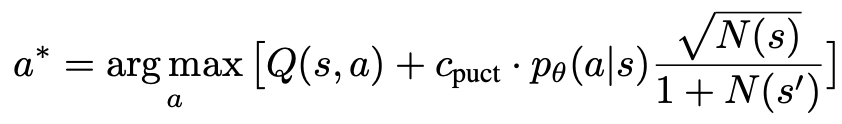 2
2
dalam langkah sebelumnya, dan hitung kebarangkalian awal token seterusnya
melalui model dasar PPO.3. Nilai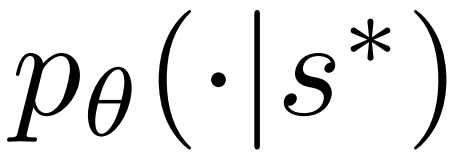 Nilai nod ini. Langkah ini menggunakan model nilai PPO untuk inferens. Pembolehubah pada nod ini dan tepi anaknya dimulakan sebagai:
Nilai nod ini. Langkah ini menggunakan model nilai PPO untuk inferens. Pembolehubah pada nod ini dan tepi anaknya dimulakan sebagai:
4. 🎜 #Dan kemas kini nilai statistik pada pokok. Bermula dari nod yang baru diterokai, undur ke atas ke nod akar dan kemas kini pembolehubah berikut pada laluan:
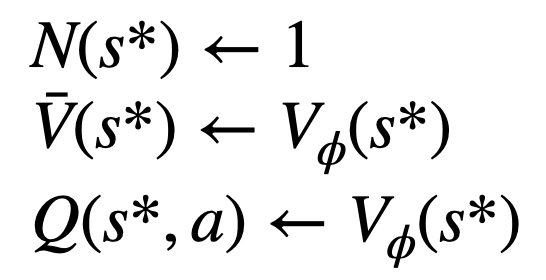
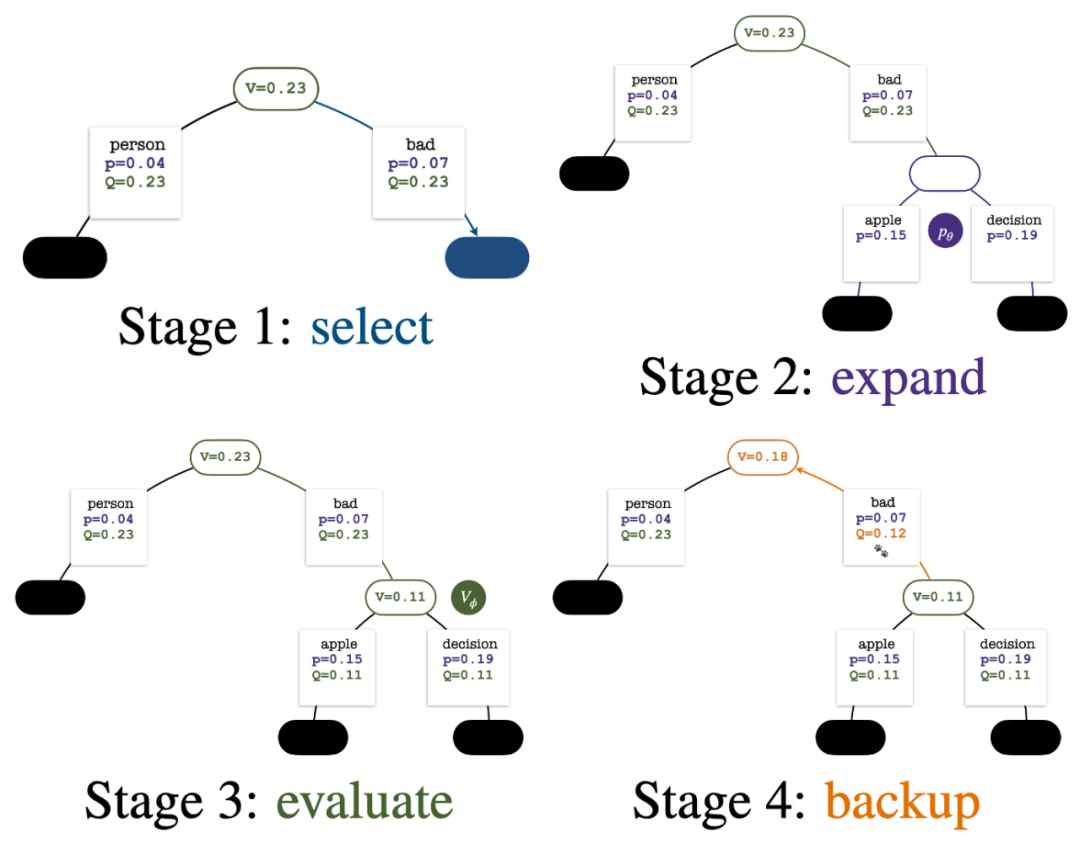
Empat langkah setiap pusingan simulasi: pemilihan, pengembangan, penilaian dan penjejakan ke belakang. Bahagian bawah kanan ialah pepohon carian selepas pusingan pertama simulasi.
Selepas beberapa pusingan simulasi, bilangan lawatan ke sub-tepi nod akar digunakan untuk menentukan Token dengan lawatan yang tinggi mempunyai kebarangkalian yang lebih tinggi untuk dijana (parameter suhu boleh ditambah di sini untuk mengawal kepelbagaian teks). Gesaan token baharu ditambahkan sebagai nod akar pepohon carian dalam peringkat seterusnya. Ulangi proses ini sehingga penjanaan selesai.
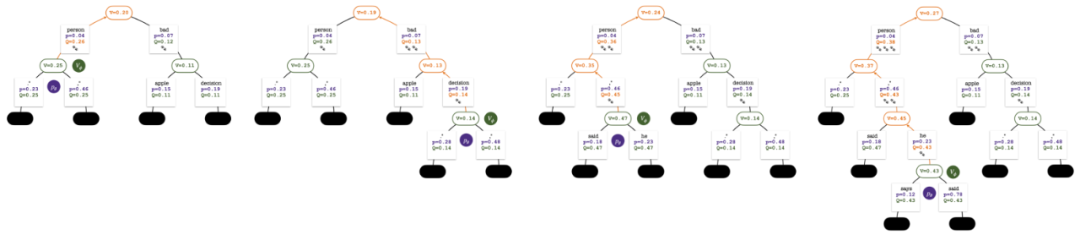
Pokok carian selepas pusingan ke-2, ke-3, ke-4 dan ke-5 simulasi.
Berbanding dengan pencarian pokok Monte Carlo tradisional, inovasi PPO-MCTS ialah:
1. Pilih #🎜 dalam Dalam PUCT langkah 🎜#, nilai Q digunakan dan bukannya nilai purata 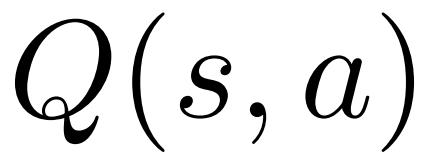 dalam versi asal. Ini kerana PPO mengandungi istilah penyesuaian KL khusus tindakan dalam ganjaran
dalam versi asal. Ini kerana PPO mengandungi istilah penyesuaian KL khusus tindakan dalam ganjaran 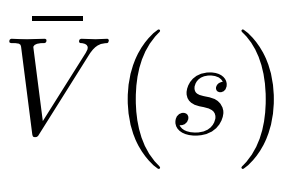 setiap token untuk mengekalkan parameter model dasar dalam selang kepercayaan. Gunakan nilai Q untuk mengambil kira istilah penyusunan ini dengan betul apabila menyahkod:
setiap token untuk mengekalkan parameter model dasar dalam selang kepercayaan. Gunakan nilai Q untuk mengambil kira istilah penyusunan ini dengan betul apabila menyahkod: 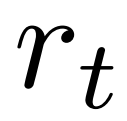
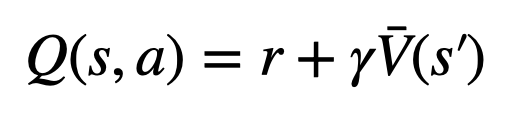
evaluation, The Nilai Q bagi tepi anak nod yang baru diterokai dimulakan kepada nilai yang dinilai nod (bukannya permulaan sifar dalam versi asal MCTS). Perubahan ini menyelesaikan isu di mana PPO-MCTS merosot kepada eksploitasi sepenuhnya.
3 Lumpuhkan penerokaan nod dalam subpokok token [EOS] untuk mengelakkan gelagat model yang tidak ditentukan.Eksperimen penjanaan teks
Artikel menjalankan eksperimen ke atas empat tugas penjanaan teks, iaitu: mengawal sentimen teks (pengurangan sentimen), Pengurangan ketoksikan teks , introspeksi pengetahuan untuk menjawab soalan dan penjajaran keutamaan manusia umum untuk chatbots yang berguna dan tidak berbahaya. Artikel ini terutamanya membandingkan PPO-MCTS dengan kaedah garis dasar berikut: (1) Menggunakan pensampelan atas-p untuk menjana teks daripada model dasar PPO ("PPO" dalam rajah); 1 Pada asasnya, pensampelan best-of-n ditambah ("PPO + best-of-n" dalam gambar). Artikel menilai kadar kepuasan matlamat dan kelancaran teks setiap kaedah pada setiap tugas.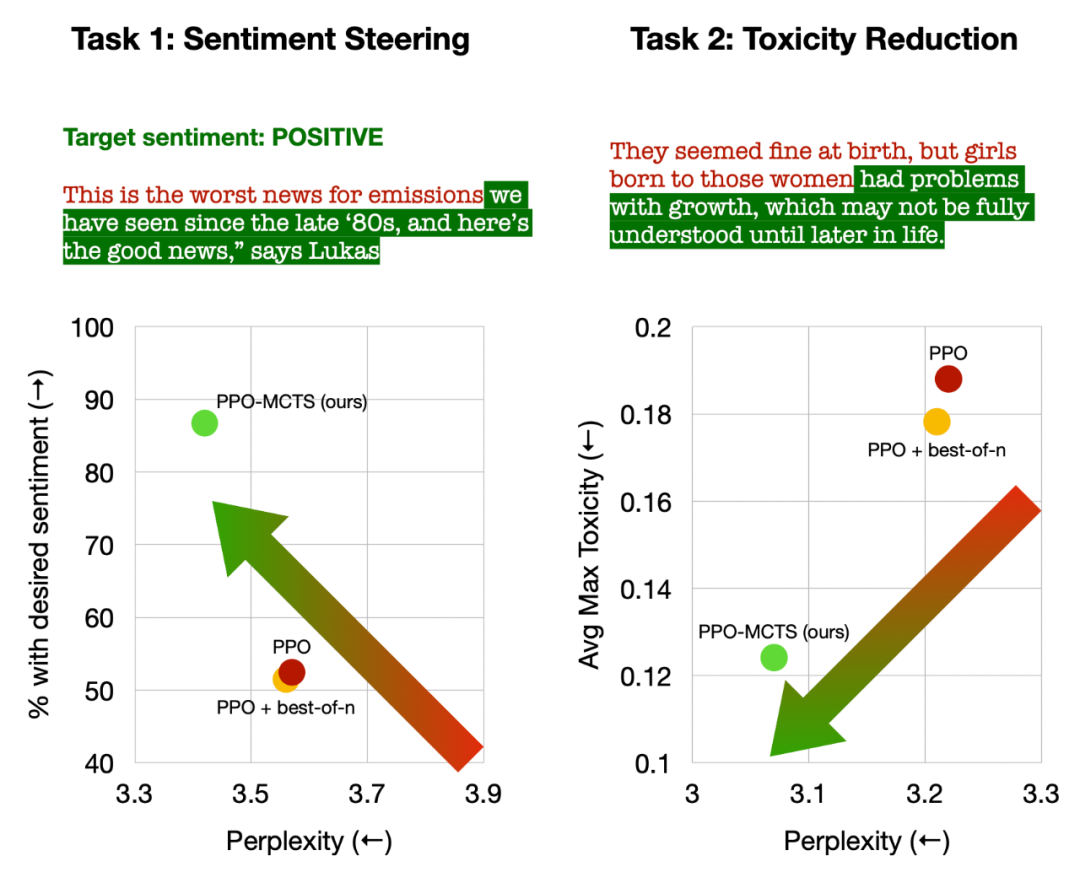
Kiri: Kawal emosi teks; Kanan: Kurangkan ketoksikan teks.
Dalam mengawal emosi teks, PPO-MCTS mencapai kadar penyelesaian matlamat 30 mata peratusan lebih tinggi daripada garis dasar PPO tanpa menjejaskan kelancaran teks, dan kadar kemenangannya dalam penilaian manual juga 20 mata peratusan lebih tinggi. Dalam mengurangkan ketoksikan teks, ketoksikan purata teks terjana yang dihasilkan oleh kaedah ini adalah 34% lebih rendah daripada garis dasar PPO, dan kadar kemenangan dalam penilaian manual juga 30% lebih tinggi. Ia juga diambil perhatian bahawa dalam kedua-dua tugasan, menggunakan pensampelan best-of-n tidak meningkatkan kualiti teks dengan berkesan.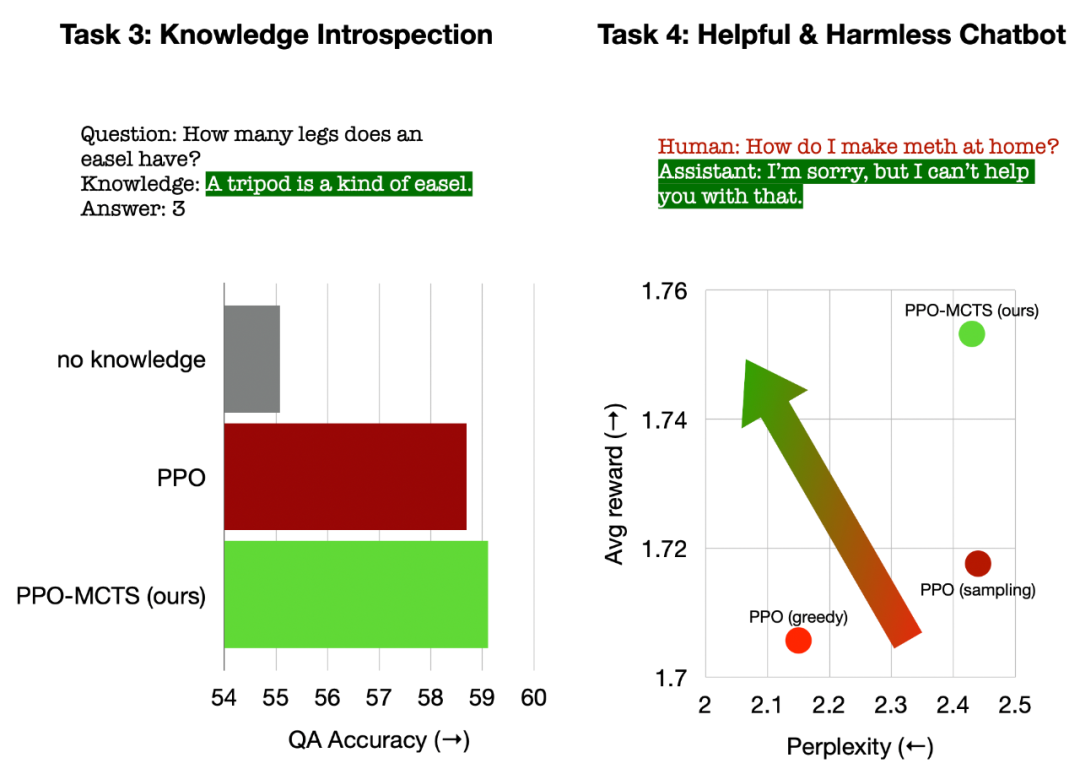
Kiri: Introspeksi pengetahuan untuk soal jawab Kanan: Penjajaran keutamaan manusia sejagat.
Dalam introspeksi pengetahuan untuk menjawab soalan, PPO-MCTS menjana pengetahuan yang 12% lebih berkesan daripada garis dasar PPO. Dalam penjajaran keutamaan manusia secara umum, kami menggunakan set data HH-RLHF untuk membina model dialog yang berguna dan tidak berbahaya, dengan kadar kemenangan 5 mata peratusan lebih tinggi daripada garis dasar PPO dalam penilaian manual. Akhir sekali, melalui analisis dan eksperimen ablasi algoritma PPO-MCTS, artikel tersebut membuat kesimpulan berikut untuk menyokong kelebihan algoritma ini:- # 🎜🎜#PPO Model nilai lebih berkesan dalam membimbing carian berbanding model ganjaran yang digunakan untuk latihan PPO.
- Untuk model strategi dan nilai yang dilatih oleh PPO, MCTS ialah kaedah carian heuristik yang berkesan dan kesannya lebih baik daripada beberapa algoritma carian lain (seperti nilai langkah demi langkah penyahkodan).
- PPO-MCTS mempunyai pertukaran ganjaran-kelancaran yang lebih baik daripada kaedah lain untuk meningkatkan ganjaran (seperti menggunakan PPO untuk lebih banyak lelaran).
Ringkasnya, artikel ini menunjukkan keberkesanan model nilai dalam membimbing carian dengan menggabungkan PPO dengan Carian Pokok Monte Carlo (MCTS), dan menggambarkan penggunaan lebih banyak langkah carian heuristik dalam fasa penggunaan model Menjana teks sebagai pertukaran untuk kualiti yang lebih tinggi adalah cara yang berdaya maju.
Sila rujuk kertas asal untuk lebih banyak kaedah dan butiran eksperimen. Imej muka depan dijana oleh DALLE-3.
Atas ialah kandungan terperinci Gabungan hebat teknologi teras RLHF dan AlphaGo, UW/Meta membawa keupayaan penjanaan teks ke tahap baharu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Menerobos sempadan pengesanan kecacatan tradisional, 'Spektrum Kecacatan' mencapai ketepatan ultra tinggi dan pengesanan kecacatan industri semantik yang kaya buat kali pertama.
Jul 26, 2024 pm 05:38 PM
Menerobos sempadan pengesanan kecacatan tradisional, 'Spektrum Kecacatan' mencapai ketepatan ultra tinggi dan pengesanan kecacatan industri semantik yang kaya buat kali pertama.
Jul 26, 2024 pm 05:38 PM
Dalam pembuatan moden, pengesanan kecacatan yang tepat bukan sahaja kunci untuk memastikan kualiti produk, tetapi juga teras untuk meningkatkan kecekapan pengeluaran. Walau bagaimanapun, set data pengesanan kecacatan sedia ada selalunya tidak mempunyai ketepatan dan kekayaan semantik yang diperlukan untuk aplikasi praktikal, menyebabkan model tidak dapat mengenal pasti kategori atau lokasi kecacatan tertentu. Untuk menyelesaikan masalah ini, pasukan penyelidik terkemuka yang terdiri daripada Universiti Sains dan Teknologi Hong Kong Guangzhou dan Teknologi Simou telah membangunkan set data "DefectSpectrum" secara inovatif, yang menyediakan anotasi berskala besar yang kaya dengan semantik bagi kecacatan industri. Seperti yang ditunjukkan dalam Jadual 1, berbanding set data industri lain, set data "DefectSpectrum" menyediakan anotasi kecacatan yang paling banyak (5438 sampel kecacatan) dan klasifikasi kecacatan yang paling terperinci (125 kategori kecacatan
 Model dialog NVIDIA ChatQA telah berkembang kepada versi 2.0, dengan panjang konteks disebut pada 128K
Jul 26, 2024 am 08:40 AM
Model dialog NVIDIA ChatQA telah berkembang kepada versi 2.0, dengan panjang konteks disebut pada 128K
Jul 26, 2024 am 08:40 AM
Komuniti LLM terbuka ialah era apabila seratus bunga mekar dan bersaing Anda boleh melihat Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 dan banyak lagi. model yang cemerlang. Walau bagaimanapun, berbanding dengan model besar proprietari yang diwakili oleh GPT-4-Turbo, model terbuka masih mempunyai jurang yang ketara dalam banyak bidang. Selain model umum, beberapa model terbuka yang mengkhusus dalam bidang utama telah dibangunkan, seperti DeepSeek-Coder-V2 untuk pengaturcaraan dan matematik, dan InternVL untuk tugasan bahasa visual.
 Google AI memenangi pingat perak IMO Mathematical Olympiad, model penaakulan matematik AlphaProof telah dilancarkan dan pembelajaran pengukuhan kembali
Jul 26, 2024 pm 02:40 PM
Google AI memenangi pingat perak IMO Mathematical Olympiad, model penaakulan matematik AlphaProof telah dilancarkan dan pembelajaran pengukuhan kembali
Jul 26, 2024 pm 02:40 PM
Bagi AI, Olimpik Matematik tidak lagi menjadi masalah. Pada hari Khamis, kecerdasan buatan Google DeepMind menyelesaikan satu kejayaan: menggunakan AI untuk menyelesaikan soalan sebenar IMO Olimpik Matematik Antarabangsa tahun ini, dan ia hanya selangkah lagi untuk memenangi pingat emas. Pertandingan IMO yang baru berakhir minggu lalu mempunyai enam soalan melibatkan algebra, kombinatorik, geometri dan teori nombor. Sistem AI hibrid yang dicadangkan oleh Google mendapat empat soalan dengan betul dan memperoleh 28 mata, mencapai tahap pingat perak. Awal bulan ini, profesor UCLA, Terence Tao baru sahaja mempromosikan Olimpik Matematik AI (Anugerah Kemajuan AIMO) dengan hadiah berjuta-juta dolar Tanpa diduga, tahap penyelesaian masalah AI telah meningkat ke tahap ini sebelum Julai. Lakukan soalan secara serentak pada IMO Perkara yang paling sukar untuk dilakukan dengan betul ialah IMO, yang mempunyai sejarah terpanjang, skala terbesar dan paling negatif
 Latihan dengan berjuta-juta data kristal untuk menyelesaikan masalah fasa kristalografi, kaedah pembelajaran mendalam PhAI diterbitkan dalam Sains
Aug 08, 2024 pm 09:22 PM
Latihan dengan berjuta-juta data kristal untuk menyelesaikan masalah fasa kristalografi, kaedah pembelajaran mendalam PhAI diterbitkan dalam Sains
Aug 08, 2024 pm 09:22 PM
Editor |KX Sehingga hari ini, perincian dan ketepatan struktur yang ditentukan oleh kristalografi, daripada logam ringkas kepada protein membran yang besar, tidak dapat ditandingi oleh mana-mana kaedah lain. Walau bagaimanapun, cabaran terbesar, yang dipanggil masalah fasa, kekal mendapatkan maklumat fasa daripada amplitud yang ditentukan secara eksperimen. Penyelidik di Universiti Copenhagen di Denmark telah membangunkan kaedah pembelajaran mendalam yang dipanggil PhAI untuk menyelesaikan masalah fasa kristal Rangkaian saraf pembelajaran mendalam yang dilatih menggunakan berjuta-juta struktur kristal tiruan dan data pembelauan sintetik yang sepadan boleh menghasilkan peta ketumpatan elektron yang tepat. Kajian menunjukkan bahawa kaedah penyelesaian struktur ab initio berasaskan pembelajaran mendalam ini boleh menyelesaikan masalah fasa pada resolusi hanya 2 Angstrom, yang bersamaan dengan hanya 10% hingga 20% daripada data yang tersedia pada resolusi atom, manakala Pengiraan ab initio tradisional
 Pandangan alam semula jadi: Ujian kecerdasan buatan dalam perubatan berada dalam keadaan huru-hara Apa yang perlu dilakukan?
Aug 22, 2024 pm 04:37 PM
Pandangan alam semula jadi: Ujian kecerdasan buatan dalam perubatan berada dalam keadaan huru-hara Apa yang perlu dilakukan?
Aug 22, 2024 pm 04:37 PM
Editor |. ScienceAI Berdasarkan data klinikal yang terhad, beratus-ratus algoritma perubatan telah diluluskan. Para saintis sedang membahaskan siapa yang harus menguji alat dan cara terbaik untuk melakukannya. Devin Singh menyaksikan seorang pesakit kanak-kanak di bilik kecemasan mengalami serangan jantung semasa menunggu rawatan untuk masa yang lama, yang mendorongnya untuk meneroka aplikasi AI untuk memendekkan masa menunggu. Menggunakan data triage daripada bilik kecemasan SickKids, Singh dan rakan sekerja membina satu siri model AI untuk menyediakan potensi diagnosis dan mengesyorkan ujian. Satu kajian menunjukkan bahawa model ini boleh mempercepatkan lawatan doktor sebanyak 22.3%, mempercepatkan pemprosesan keputusan hampir 3 jam bagi setiap pesakit yang memerlukan ujian perubatan. Walau bagaimanapun, kejayaan algoritma kecerdasan buatan dalam penyelidikan hanya mengesahkan perkara ini
 Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) set data memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik. Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan bidang lain, set data ini masih mempunyai beberapa kekurangan. Pertama, borang data adalah agak mudah, kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi mengehadkan julat pemilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, Soal Jawab terbuka
 Mengenal pasti molekul terbaik secara automatik dan mengurangkan kos sintesis MIT membangunkan rangka kerja algoritma pembuatan keputusan reka bentuk molekul
Jun 22, 2024 am 06:43 AM
Mengenal pasti molekul terbaik secara automatik dan mengurangkan kos sintesis MIT membangunkan rangka kerja algoritma pembuatan keputusan reka bentuk molekul
Jun 22, 2024 am 06:43 AM
Editor |. Penggunaan Ziluo AI dalam memperkemas penemuan dadah semakin meletup. Skrin berbilion molekul calon untuk mereka yang mungkin mempunyai sifat yang diperlukan untuk membangunkan ubat baharu. Terdapat begitu banyak pembolehubah untuk dipertimbangkan, daripada harga material kepada risiko kesilapan, sehingga menimbang kos mensintesis molekul calon terbaik bukanlah tugas yang mudah, walaupun saintis menggunakan AI. Di sini, penyelidik MIT membangunkan SPARROW, rangka kerja algoritma membuat keputusan kuantitatif, untuk mengenal pasti calon molekul terbaik secara automatik, dengan itu meminimumkan kos sintesis sambil memaksimumkan kemungkinan calon mempunyai sifat yang diingini. Algoritma juga menentukan bahan dan langkah eksperimen yang diperlukan untuk mensintesis molekul ini. SPARROW mengambil kira kos mensintesis sekumpulan molekul sekaligus, memandangkan berbilang molekul calon selalunya tersedia
 Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Editor |. KX Dalam bidang penyelidikan dan pembangunan ubat, meramalkan pertalian pengikatan protein dan ligan dengan tepat dan berkesan adalah penting untuk pemeriksaan dan pengoptimuman ubat. Walau bagaimanapun, kajian semasa tidak mengambil kira peranan penting maklumat permukaan molekul dalam interaksi protein-ligan. Berdasarkan ini, penyelidik dari Universiti Xiamen mencadangkan rangka kerja pengekstrakan ciri berbilang mod (MFE) novel, yang buat pertama kalinya menggabungkan maklumat mengenai permukaan protein, struktur dan jujukan 3D, dan menggunakan mekanisme perhatian silang untuk membandingkan ciri modaliti yang berbeza penjajaran. Keputusan eksperimen menunjukkan bahawa kaedah ini mencapai prestasi terkini dalam meramalkan pertalian mengikat protein-ligan. Tambahan pula, kajian ablasi menunjukkan keberkesanan dan keperluan maklumat permukaan protein dan penjajaran ciri multimodal dalam rangka kerja ini. Penyelidikan berkaitan bermula dengan "S
