

Artikel ini dicetak semula dengan kebenaran akaun awam Heart of Autonomous Driving Sila hubungi sumber asal untuk mencetak semula
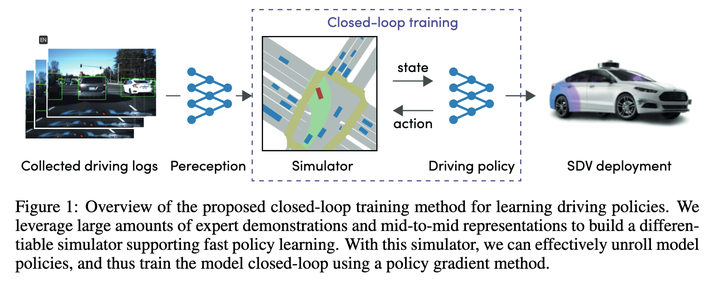
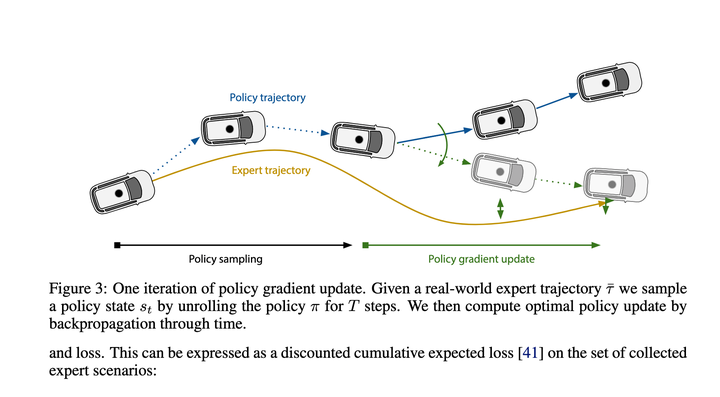
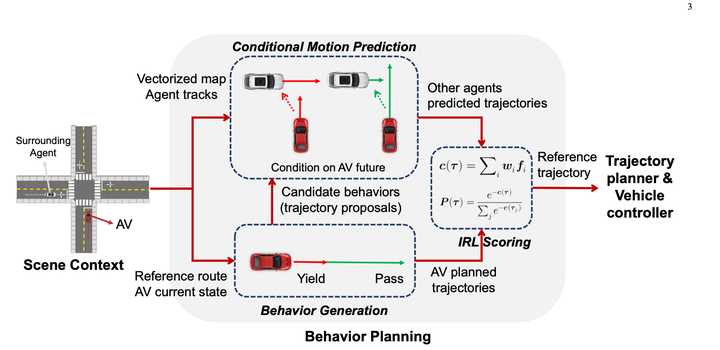
Pertama gunakan peraturan untuk menyenaraikan pelbagai tingkah laku dan menjana 10~30 (Keputusan ramalan tidak digunakan)
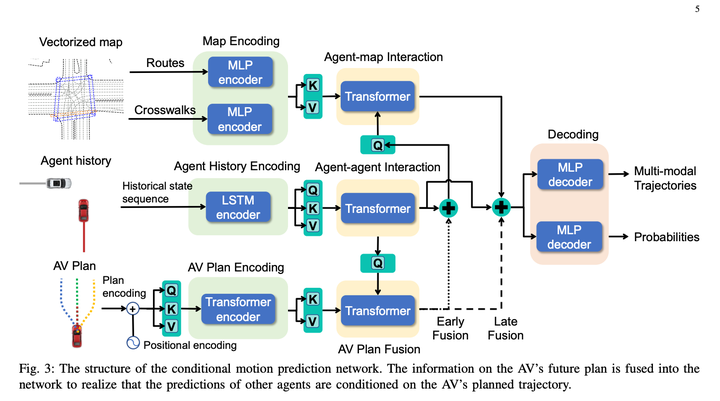
Pada asasnya perkara yang hebat tentang kaedah ini ialah ia menggunakan Ramalan Bersama Bersyarat untuk melengkapkan ramalan interaktif, memberikan algoritma keupayaan permainan tertentu.
Namun, kerana terdapat satu lagi dimensi, selepas pengembangan terlalu banyak kali, ruang penyelesaian akan tetap besar dan jumlah pengiraan akan menjadi terlalu besar Kaedah yang ditulis dalam kertas semasa adalah membuang secara rawak beberapa nod apabila ada adalah terlalu banyak nod. Pastikan jumlah pengiraan boleh dikawal (rasanya jika terlalu banyak nod, ia mungkin selepas n tahap, dan kesannya mungkin agak kecil)
Sumbangan utama artikel ini adalah untuk mengubah ruang penyelesaian berterusan kepada keputusan Markov melalui proses peraturan pensampelan pokok ini, dan kemudian menggunakan dp untuk menyelesaikannya.
4. kesan permainan tertentu
modul kertas utama:
2. Modul pemarkahan boleh menjaringkan kenderaan utama + trajektori kenderaan halangan untuk melihat sama ada trajektori itu menyerupai tingkah laku pakar.
3 Modul Carian Dasar Pokok, digunakan untuk menjana sekumpulan trajektori calonAlgoritma Tree Search digunakan untuk meneroka penyelesaian yang boleh dilaksanakan bagi kenderaan utama Setiap langkah dalam proses penerokaan mengambil trajektori yang diterokai sebagai input, menggunakan algoritma Ramalan Bersyarat untuk menjana trajektori yang diramalkan bagi kenderaan utama dan kenderaan halangan, dan memanggil modul pemarkahan untuk menilai kecemerlangan trajektori adalah lemah, sekali gus menjejaskan arah carian seterusnya untuk nod pengembangan. Melalui kaedah ini, anda boleh menjana beberapa trajektori kenderaan utama yang berbeza daripada penyelesaian lain, dan mempertimbangkan interaksi dengan kenderaan halangan semasa menjana trajektori
IRL tradisional secara manual mencipta banyak ciri, seperti sekumpulan ciri depan dan belakang Pelbagai ciri-ciri halangan dalam dimensi masa trajektori (seperti relatif s, l dan ttc Dalam artikel ini, untuk menjadikan model boleh dibezakan, ramalan MLP konteks ego digunakan secara langsung untuk menjana tatasusunan Berat (saiz = 1 *). C), secara tersirat mewakili maklumat alam sekitar di sekeliling kenderaan hos, dan kemudian menggunakan MLP untuk menukar terus trajektori kenderaan hos + hasil ramalan berbilang mod yang sepadan kepada tatasusunan Ciri (saiz = C * N, N merujuk kepada bilangan trajektori calon ) , dan kemudian kedua-dua matriks didarab untuk mendapatkan skor trajektori akhir. Kemudian IRL membiarkan pakar mendapat mata tertinggi. Secara peribadi, saya merasakan bahawa ini mungkin untuk kecekapan pengiraan, menjadikan penyahkod semudah mungkin, tetapi masih terdapat kehilangan tertentu maklumat kenderaan utama Jika anda tidak memberi perhatian kepada kecekapan pengiraan, anda boleh menggunakan beberapa rangkaian yang lebih kompleks sambungkan Konteks Ego dan Trajektori Diramalkan, dan tahap kesannya harus lebih baik? Atau jika anda melepaskan kebolehbezaan, anda masih boleh mempertimbangkan untuk menambah ciri yang ditetapkan secara manual, yang juga harus meningkatkan kesan model.
Dari segi masa, penyelesaian ini menggunakan kaedah satu pengekodan semula + berbilang penyahkodan ringan, yang berjaya mengurangkan kelewatan pengiraan. Artikel tersebut menunjukkan bahawa kelewatan boleh dimampatkan kepada 98 milisaat
Ia tergolong dalam kedudukan SOTA dalam kalangan perancang berasaskan pembelajaran, dan kesan gelung tertutup adalah hampir dengan skema Berasaskan Peraturan No. 1 nuplan yang disebut dalam artikel sebelumnya. . trajektori
Atas ialah kandungan terperinci Kajian semula kaedah perancangan hujung ke hujung untuk pemanduan autonomi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah kemahiran yang diperlukan untuk bekerja dalam industri PHP?
Apakah kemahiran yang diperlukan untuk bekerja dalam industri PHP?
 Bagaimana untuk membeli syiling Ripple sebenar
Bagaimana untuk membeli syiling Ripple sebenar
 Bagaimana untuk membaca fail teks dalam html
Bagaimana untuk membaca fail teks dalam html
 kaedah pemadaman fail hiberfil
kaedah pemadaman fail hiberfil
 apa maksud tajuk
apa maksud tajuk
 ASUS x402c
ASUS x402c
 Bagaimana untuk menyelesaikan masalah bahawa salinan tingkap ini tidak tulen
Bagaimana untuk menyelesaikan masalah bahawa salinan tingkap ini tidak tulen
 Bagaimana untuk menyatakan ruang dalam ungkapan biasa
Bagaimana untuk menyatakan ruang dalam ungkapan biasa








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



