
 Peranti teknologi
AI
SMPLer-X: Menumbangkan tujuh senarai utama, mempersembahkan model tangkapan gerakan manusia pertama!
Peranti teknologi
AI
SMPLer-X: Menumbangkan tujuh senarai utama, mempersembahkan model tangkapan gerakan manusia pertama!
SMPLer-X: Menumbangkan tujuh senarai utama, mempersembahkan model tangkapan gerakan manusia pertama!

Pada masa ini, walaupun kemajuan penyelidikan yang hebat telah dibuat dalam Anggaran Pose dan Bentuk Manusia Ekspresif (EHPS, Pose Manusia Ekspresif dan anggaran Bentuk), kaedah yang paling maju masih dihadkan oleh batasan set data latihan
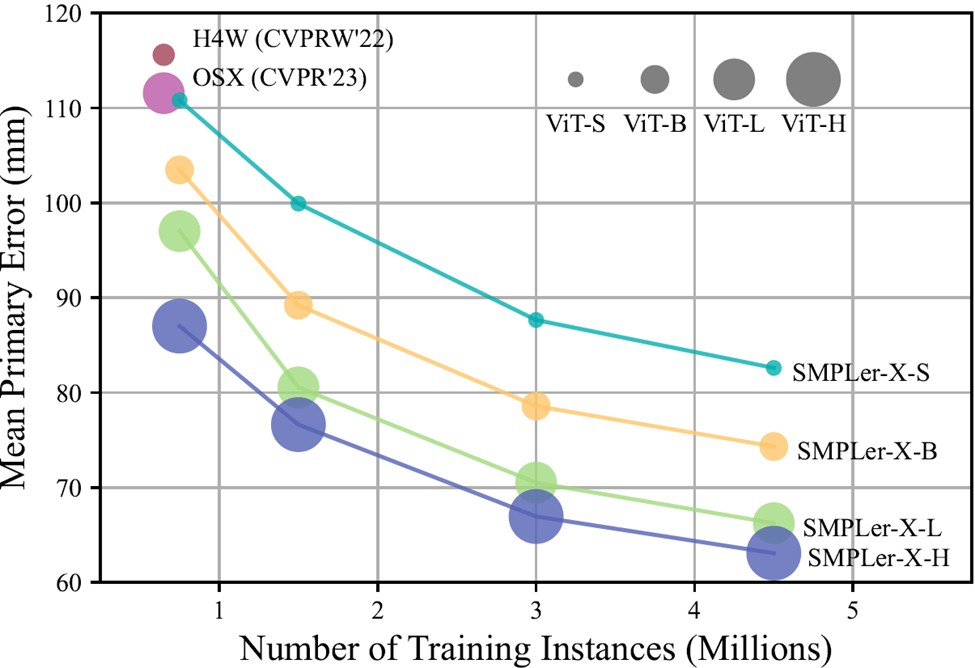
Baru-baru ini , penyelidik dari S-Lab Universiti Teknologi Nanyang, SenseTime, Makmal Kecerdasan Buatan Shanghai, Universiti Tokyo dan Institut Penyelidikan IDEA mencadangkan buat kali pertama model tangkapan gerakan berskala besar SMPLer-X untuk tugasan postur badan manusia dan anggaran saiz badan. Kajian itu menggunakan sehingga 4.5 juta kejadian daripada sumber data yang berbeza untuk melatih model, mencapai prestasi terbaik pada 7 senarai utama
SMPer-X bukan sahaja boleh menangkap pergerakan badan, tetapi juga mengeluarkan muka dan pergerakan tangan, dan menganggarkan bentuk badan

Pautan kertas: https://arxiv.org/abs/2309.17448
Laman utama projek: https://caizhongang.github.io/projects/ SMP
Dengan data yang kaya dan model yang besar, SMPLer-X telah menunjukkan prestasi yang kukuh dalam pelbagai ujian dan penarafan, dan mempunyai fleksibiliti yang sangat baik walaupun dalam persekitaran yang tidak diketahuiat Dari segi pengembangan data, para penyelidik menjalankan penilaian dan analisis komprehensif 32 3D set data badan manusia untuk menyediakan rujukan untuk latihan model
2. Dari segi penskalaan model, model besar visual digunakan untuk mengkaji kesan peningkatan bilangan parameter model terhadap prestasi yang dipertingkatkan
3 .

Menjalankan kajian generalisasi ke atas set data badan manusia 3D sedia ada
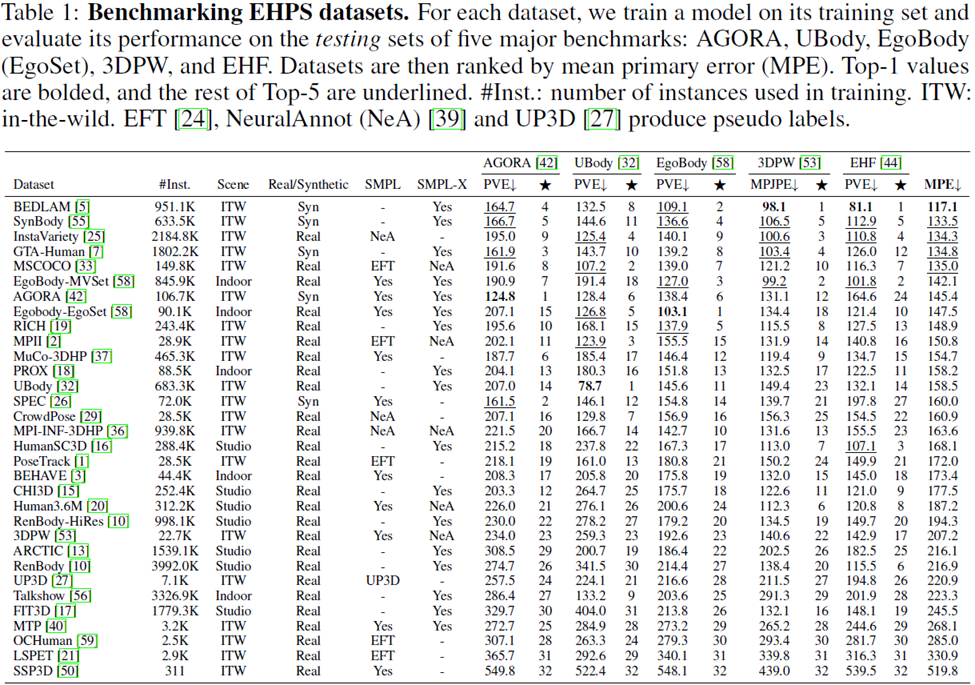
Penyelidik menjalankan kajian generalisasi ke atas 32 akademik Set data telah disenaraikan: Untuk mengukur prestasi setiap set data, model telah dilatih menggunakan set data tersebut dan model telah dinilai pada lima set data penilaian: AGORA, UBody, EgoBody, 3DPW dan EHF.
Inspirasi daripada mengkaji generalisasi set data
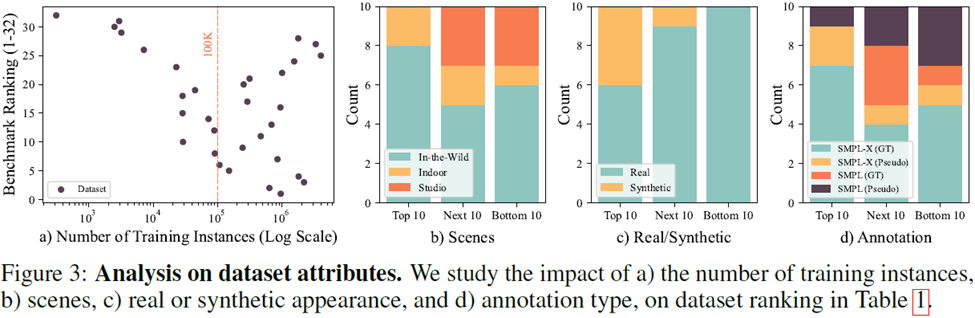
volum data set data tunggal, set data tertib 100,000 contoh boleh digunakan untuk latihan model untuk mencapai prestasi kos yang lebih tinggi
2 Mengenai senario pengumpulan set data, In-the -set data liar mempunyai kesan terbaik. Jika data hanya boleh dikumpul di dalam rumah, untuk meningkatkan kesan latihan, anda perlu mengelak daripada menggunakan data dari satu adegan
Mengenai pengumpulan set data, dua daripada tiga set data teratas adalah set data yang dijana. Dalam tahun-tahun kebelakangan ini, set data yang dijana telah menunjukkan prestasi yang kukuh
Berkenaan anotasi set data, label pseudo juga memainkan peranan yang sangat penting dalam latihan
Latihan dan penalaan halus model tangkapan gerakan besarMasa kini kebanyakan kaedah terkini biasanya hanya menggunakan beberapa set data (cth., MSCOCO, MPII dan Human3.6M) untuk latihan, manakala kertas kerja ini mengkaji menggunakan lebih banyak set data
Memandangkan set data yang lebih tinggi lebih diutamakan, kami menggunakan empat saiz data yang berbeza: 5, 10, 20 dan 32 set data sebagai set latihan, dengan jumlah saiz 750,000, 1.5 juta, 3 juta dan 4.5 juta contoh Selain itu, para penyelidik juga menunjukkan strategi penalaan halus kos rendah untuk menyesuaikan model besar umum kepada senario tertentu. Jadual di atas menunjukkan beberapa ujian utama, seperti set ujian AGORA (Jadual 3), set pengesahan AGORA (Jadual 4), EHF (Jadual 5), 6), EgoBody-EgoSet (Jadual 7). Selain itu, para penyelidik juga menilai generalisasi model tangkapan gerakan besar pada dua set ujian, ARCTIC dan DNA-Rendering Para penyelidik berharap SMPLer-X boleh membawa manfaat melebihi reka bentuk algoritma Inspire dan menyediakan komuniti akademik dengan model tangkapan gerakan manusia seluruh badan yang berkuasa. Kod dan model pra-latihan telah bersumberkan terbuka pada halaman utama projek Selamat datang untuk melawat https://caizhongang.github.io/projects/SMPler-X/ untuk butiran lanjut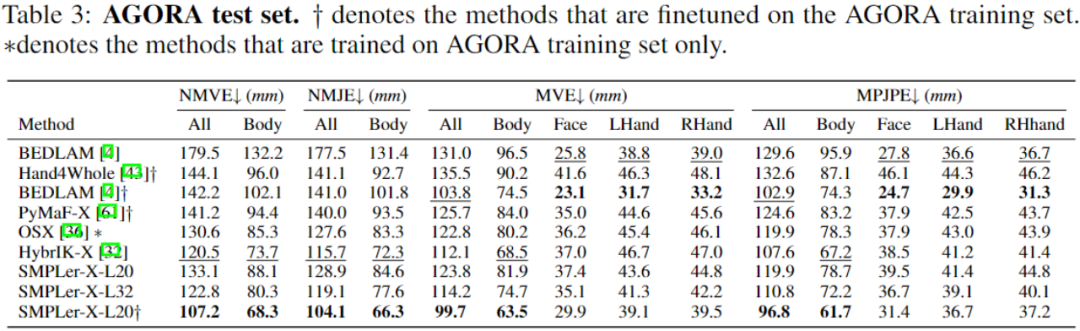
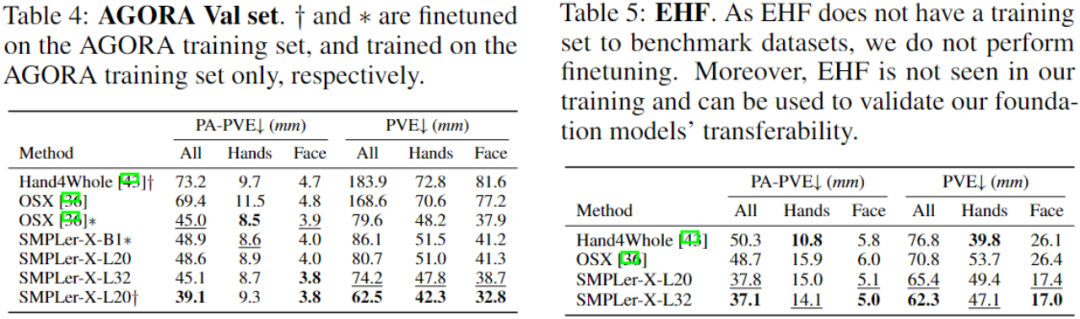
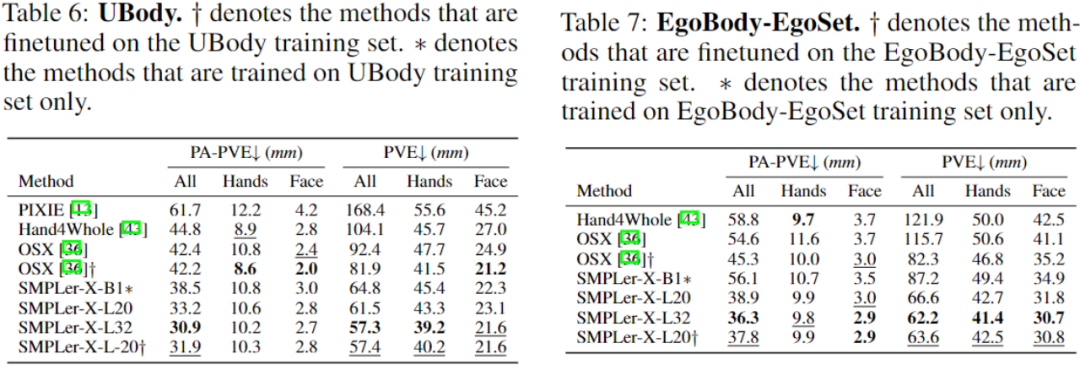
Paparan hasil
 .
. 

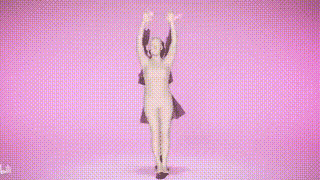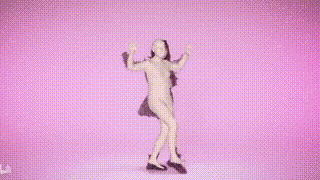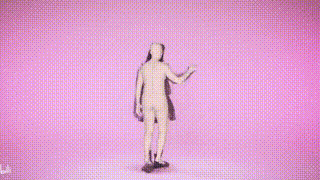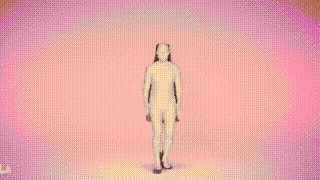




Atas ialah kandungan terperinci SMPLer-X: Menumbangkan tujuh senarai utama, mempersembahkan model tangkapan gerakan manusia pertama!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Panduan Lengkap untuk Memeriksa Konfigurasi HDFS Dalam Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk memeriksa konfigurasi dan menjalankan status HDFS secara berkesan pada sistem CentOS. Langkah -langkah berikut akan membantu anda memahami sepenuhnya persediaan dan operasi HDFS. Sahkan Pembolehubah Alam Sekitar Hadoop: Pertama, pastikan pembolehubah persekitaran Hadoop ditetapkan dengan betul. Di terminal, laksanakan arahan berikut untuk mengesahkan bahawa Hadoop dipasang dan dikonfigurasi dengan betul: Hadoopversion Semak fail konfigurasi HDFS: Fail konfigurasi teras HDFS terletak di/etc/hadoop/conf/direktori, di mana core-site.xml dan hdfs-site.xml adalah kritikal. gunakan
 Apakah kaedah penalaan prestasi zookeeper di CentOS
Apr 14, 2025 pm 03:18 PM
Apakah kaedah penalaan prestasi zookeeper di CentOS
Apr 14, 2025 pm 03:18 PM
Penalaan prestasi zookeeper pada centOs boleh bermula dari pelbagai aspek, termasuk konfigurasi perkakasan, pengoptimuman sistem operasi, pelarasan parameter konfigurasi, pemantauan dan penyelenggaraan, dan lain -lain. Memori yang cukup: memperuntukkan sumber memori yang cukup untuk zookeeper untuk mengelakkan cakera kerap membaca dan menulis. CPU multi-teras: Gunakan CPU multi-teras untuk memastikan bahawa zookeeper dapat memprosesnya selari.
 Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Latihan yang cekap model pytorch pada sistem CentOS memerlukan langkah -langkah, dan artikel ini akan memberikan panduan terperinci. 1. Penyediaan Persekitaran: Pemasangan Python dan Ketergantungan: Sistem CentOS biasanya mempamerkan python, tetapi versi mungkin lebih tua. Adalah disyorkan untuk menggunakan YUM atau DNF untuk memasang Python 3 dan menaik taraf PIP: Sudoyumupdatepython3 (atau SudodnfupdatePython3), pip3install-upgradepip. CUDA dan CUDNN (Percepatan GPU): Jika anda menggunakan Nvidiagpu, anda perlu memasang Cudatool
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 Apakah dasar keselamatan PHP di CentOs
Apr 14, 2025 pm 02:33 PM
Apakah dasar keselamatan PHP di CentOs
Apr 14, 2025 pm 02:33 PM
Penjelasan terperinci mengenai CentOS Server PHP Dasar Keselamatan: Membina Sistem Perlindungan Pepejal Artikel ini akan meneroka secara mendalam bagaimana untuk membina persekitaran operasi PHP yang selamat pada sistem CentOS, yang meliputi pelbagai aspek seperti tahap sistem, konfigurasi PHP, pengurusan kebenaran, penyulitan HTTPS dan pemantauan keselamatan, dan lain-lain, untuk membantu anda dengan berkesan mengurangkan risiko serangan pelayan. Keselamatan pelayan adalah proses penambahbaikan berterusan yang memerlukan semakan dan kemas kini secara teratur ke dasar keselamatan. 1. Sistem Keselamatan Sistem Cornerstone Sistem Kemas kini: Simpan versi terkini sistem CentOS dan semua pakej perisian, pasangkan patch keselamatan tepat pada masanya, dan plag kelemahan yang diketahui. Perlindungan Firewall: Gunakan firewalld untuk mengendalikan akses rangkaian pelayan halus, dan hanya port yang diperlukan (seperti port HTTP 80 dan h
