
 Peranti teknologi
AI
GPT4 mengajar robot untuk memusingkan pen, yang dipanggil kelicinan sutera!
Peranti teknologi
AI
GPT4 mengajar robot untuk memusingkan pen, yang dipanggil kelicinan sutera!
GPT4 mengajar robot untuk memusingkan pen, yang dipanggil kelicinan sutera!

Baru-baru ini, GPT-4, yang memberi inspirasi kepada ahli matematik Terence Tao, telah mula mengajar robot cara menghidupkan pen dalam sembang

Projek itu dipanggil Agent Eureka, yang dibangunkan oleh Nvidia, University of Pennsylvania, California Institute of Teknologi dan Universiti Texas di Austin Dibangunkan bersama oleh sekolah cawangan. Penyelidikan mereka menggabungkan kuasa struktur GPT-4 dengan kelebihan pembelajaran pengukuhan, membolehkan Eureka mereka bentuk fungsi ganjaran yang indah.
Keupayaan pengaturcaraan GPT-4 memberikan kemahiran reka bentuk fungsi ganjaran yang hebat kepada Eureka. Ini bermakna bahawa dalam kebanyakan tugas, skim ganjaran Eureka sendiri lebih baik daripada pakar manusia. Ini membolehkannya menyelesaikan beberapa tugas yang sukar untuk manusia, termasuk memusing pen, membuka laci, walnut pinggan, dan tugas yang lebih kompleks, seperti membaling dan menangkap bola, gunting operasi, dsb.
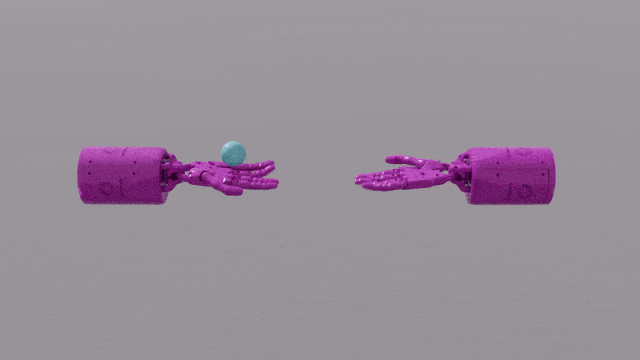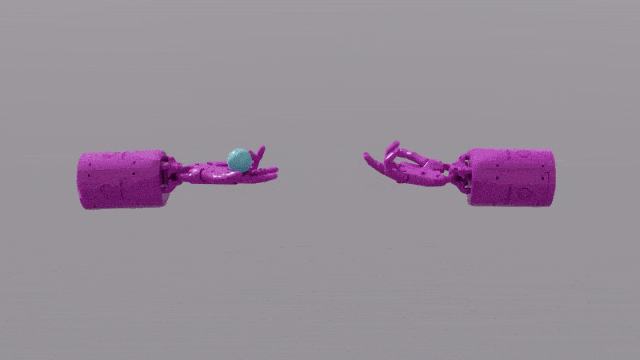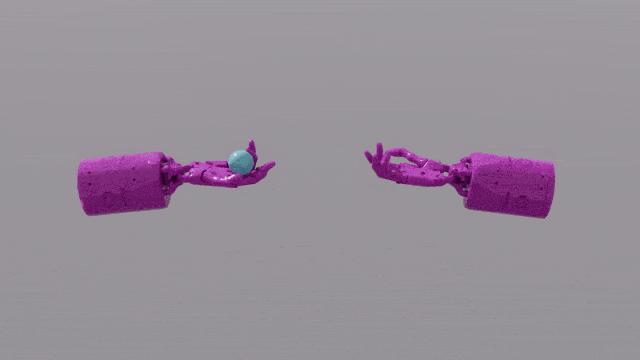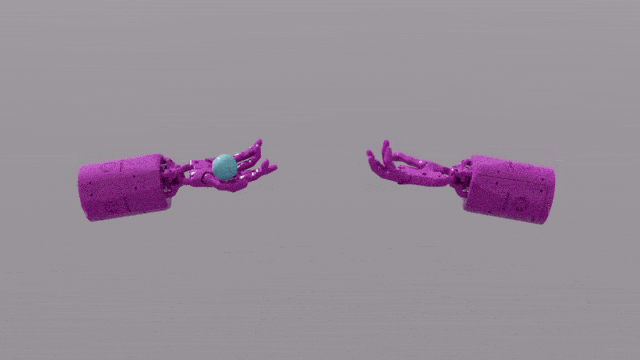 Gambar
Gambar
 Gambar
Gambar
Walaupun pada masa ini dilakukan dalam persekitaran simulasi, ini sudah sangat berkuasa.
Projek ini adalah sumber terbuka, dan alamat projek serta alamat kertas telah diletakkan di penghujung artikel
Ringkasan ringkas tentang perkara teras kertas.
Makalah ini meneroka cara menggunakan model bahasa besar (LLM) untuk mereka bentuk dan mengoptimumkan fungsi ganjaran dalam pembelajaran mesin. Ini adalah topik penting kerana mereka bentuk fungsi ganjaran yang baik boleh meningkatkan prestasi model pembelajaran mesin dengan banyak, tetapi mereka bentuk fungsi sedemikian adalah sangat sukar.
Para penyelidik telah mencadangkan algoritma baharu yang dipanggil EUREKA. EUREKA mengguna pakai LLM untuk menjana dan menambah baik fungsi ganjaran. Dalam ujian, EUREKA mencapai prestasi peringkat manusia dalam 29 persekitaran pembelajaran pengukuhan yang berbeza dan mengatasi fungsi ganjaran yang direka oleh pakar manusia dalam 83% tugasan
EUREKA berjaya menyelesaikan beberapa masalah yang sebelum ini mustahil untuk mereka bentuk fungsi ganjaran secara manual Selesaikan tugas operasi yang kompleks, seperti sebagai simulasi operasi "Shadow Hand" untuk memusingkan pen dengan pantas
Selain itu, EUREKA menyediakan kaedah baharu yang boleh menjana fungsi ganjaran yang lebih berkesan yang lebih sesuai dengan jangkaan manusia berdasarkan maklum balas manusia
EUREKA berfungsi dalam tiga langkah utama:
Persekitaran sebagai konteks: EUREKA menggunakan kod sumber persekitaran sebagai konteks untuk menjana fungsi ganjaran boleh laku
2 Carian evolusi: EUREKA terus mencadangkan melalui carian evolusi Dan meningkatkan fungsi ganjaran
3 : EUREKA menjana ringkasan teks kualiti ganjaran berdasarkan data statistik daripada latihan dasar, dengan itu secara automatik dan menyasarkan fungsi ganjaran. 3. Refleksi Ganjaran: EUREKA menjana ringkasan teks kualiti ganjaran berdasarkan statistik daripada latihan dasar untuk meningkatkan fungsi ganjaran secara automatik dan disasarkan
Penyelidikan ini mungkin memberi impak yang mendalam dalam bidang pembelajaran pengukuhan dan reka bentuk fungsi ganjaran kerana ia baru dan cekap. kaedah disediakan untuk menjana dan meningkatkan fungsi ganjaran secara automatik, dan prestasi kaedah ini melebihi pakar manusia dalam banyak kes.
Alamat projek: https://www.php.cn/link/e6b738eca0e6792ba8a9cbcba6c1881d
Pautan kertas: https://www.php.cn/link/ce128c4c3e4b7fc
Atas ialah kandungan terperinci GPT4 mengajar robot untuk memusingkan pen, yang dipanggil kelicinan sutera!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 CLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang
Mar 26, 2024 pm 12:41 PM
Ditulis di atas & pemahaman peribadi penulis: Pada masa ini, dalam keseluruhan sistem pemanduan autonomi, modul persepsi memainkan peranan penting Hanya selepas kenderaan pemanduan autonomi yang memandu di jalan raya memperoleh keputusan persepsi yang tepat melalui modul persepsi boleh Peraturan hiliran dan. modul kawalan dalam sistem pemanduan autonomi membuat pertimbangan dan keputusan tingkah laku yang tepat pada masanya dan betul. Pada masa ini, kereta dengan fungsi pemanduan autonomi biasanya dilengkapi dengan pelbagai penderia maklumat data termasuk penderia kamera pandangan sekeliling, penderia lidar dan penderia radar gelombang milimeter untuk mengumpul maklumat dalam modaliti yang berbeza untuk mencapai tugas persepsi yang tepat. Algoritma persepsi BEV berdasarkan penglihatan tulen digemari oleh industri kerana kos perkakasannya yang rendah dan penggunaan mudah, dan hasil keluarannya boleh digunakan dengan mudah untuk pelbagai tugas hiliran.
 Ameca generasi kedua ada di sini! Dia boleh berkomunikasi dengan penonton dengan lancar, ekspresi mukanya lebih realistik, dan dia boleh bercakap berpuluh-puluh bahasa.
Mar 04, 2024 am 09:10 AM
Ameca generasi kedua ada di sini! Dia boleh berkomunikasi dengan penonton dengan lancar, ekspresi mukanya lebih realistik, dan dia boleh bercakap berpuluh-puluh bahasa.
Mar 04, 2024 am 09:10 AM
Robot humanoid Ameca telah dinaik taraf kepada generasi kedua! Baru-baru ini, di Persidangan Komunikasi Mudah Alih Sedunia MWC2024, robot Ameca paling canggih di dunia muncul semula. Di sekitar venue, Ameca menarik sejumlah besar penonton. Dengan restu GPT-4, Ameca boleh bertindak balas terhadap pelbagai masalah dalam masa nyata. "Jom kita menari." Apabila ditanya sama ada dia mempunyai emosi, Ameca menjawab dengan beberapa siri mimik muka yang kelihatan sangat hidup. Hanya beberapa hari yang lalu, EngineeredArts, syarikat robotik British di belakang Ameca, baru sahaja menunjukkan hasil pembangunan terkini pasukan itu. Dalam video tersebut, robot Ameca mempunyai keupayaan visual dan boleh melihat serta menerangkan keseluruhan bilik dan objek tertentu. Perkara yang paling menakjubkan ialah dia juga boleh
 Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Cabaran biasa yang dihadapi oleh algoritma pembelajaran mesin dalam C++ termasuk pengurusan memori, multi-threading, pengoptimuman prestasi dan kebolehselenggaraan. Penyelesaian termasuk menggunakan penunjuk pintar, perpustakaan benang moden, arahan SIMD dan perpustakaan pihak ketiga, serta mengikuti garis panduan gaya pengekodan dan menggunakan alat automasi. Kes praktikal menunjukkan cara menggunakan perpustakaan Eigen untuk melaksanakan algoritma regresi linear, mengurus memori dengan berkesan dan menggunakan operasi matriks berprestasi tinggi.
 Bagaimanakah AI boleh menjadikan robot lebih autonomi dan boleh disesuaikan?
Jun 03, 2024 pm 07:18 PM
Bagaimanakah AI boleh menjadikan robot lebih autonomi dan boleh disesuaikan?
Jun 03, 2024 pm 07:18 PM
Dalam bidang teknologi automasi perindustrian, terdapat dua titik panas terkini yang sukar diabaikan: kecerdasan buatan (AI) dan Nvidia. Jangan ubah maksud kandungan asal, perhalusi kandungan, tulis semula kandungan, jangan teruskan: “Bukan itu sahaja, kedua-duanya berkait rapat, kerana Nvidia tidak terhad kepada unit pemprosesan grafik asalnya (GPU ), ia sedang mengembangkan GPUnya Teknologi ini meluas ke bidang kembar digital dan berkait rapat dengan teknologi AI yang baru muncul "Baru-baru ini, NVIDIA telah mencapai kerjasama dengan banyak syarikat industri, termasuk syarikat automasi industri terkemuka seperti Aveva, Rockwell Automation, Siemens. dan Schneider Electric, serta Teradyne Robotics dan syarikat MiR dan Universal Robotsnya. Baru-baru ini, Nvidiahascoll
 2 bulan kemudian, robot humanoid Walker S boleh melipat pakaian
Apr 03, 2024 am 08:01 AM
2 bulan kemudian, robot humanoid Walker S boleh melipat pakaian
Apr 03, 2024 am 08:01 AM
Editor Laporan Kuasa Mesin: Wu Xin Versi domestik robot humanoid + pasukan model besar menyelesaikan tugas operasi bahan fleksibel yang kompleks seperti melipat pakaian buat kali pertama. Dengan pelancaran Figure01, yang mengintegrasikan model besar berbilang modal OpenAI, kemajuan berkaitan rakan domestik telah menarik perhatian. Baru semalam, UBTECH, "stok robot humanoid nombor satu" China, mengeluarkan demo pertama robot humanoid WalkerS yang disepadukan secara mendalam dengan model besar Baidu Wenxin, menunjukkan beberapa ciri baharu yang menarik. Kini, WalkerS, diberkati oleh keupayaan model besar Baidu Wenxin, kelihatan seperti ini. Seperti Rajah01, WalkerS tidak bergerak, tetapi berdiri di belakang meja untuk menyelesaikan satu siri tugasan. Ia boleh mengikut perintah manusia dan melipat pakaian
 Robot pertama yang menyelesaikan tugas manusia secara autonomi muncul, dengan lima jari fleksibel dan kelajuan manusia luar biasa, dan model besar menyokong latihan angkasa maya
Mar 11, 2024 pm 12:10 PM
Robot pertama yang menyelesaikan tugas manusia secara autonomi muncul, dengan lima jari fleksibel dan kelajuan manusia luar biasa, dan model besar menyokong latihan angkasa maya
Mar 11, 2024 pm 12:10 PM
Minggu ini, FigureAI, sebuah syarikat robotik yang dilaburkan oleh OpenAI, Microsoft, Bezos, dan Nvidia, mengumumkan bahawa ia telah menerima hampir $700 juta dalam pembiayaan dan merancang untuk membangunkan robot humanoid yang boleh berjalan secara bebas dalam tahun hadapan. Dan Optimus Prime Tesla telah berulang kali menerima berita baik. Tiada siapa yang meragui bahawa tahun ini akan menjadi tahun apabila robot humanoid meletup. SanctuaryAI, sebuah syarikat robotik yang berpangkalan di Kanada, baru-baru ini mengeluarkan robot humanoid baharu, Phoenix. Pegawai mendakwa bahawa ia boleh menyelesaikan banyak tugas secara autonomi pada kelajuan yang sama seperti manusia. Pheonix, robot pertama di dunia yang boleh menyelesaikan tugas secara autonomi pada kelajuan manusia, boleh mencengkam, menggerakkan dan meletakkan setiap objek secara elegan di sisi kiri dan kanannya dengan perlahan. Ia boleh mengenal pasti objek secara autonomi
 Terokai prinsip asas dan pemilihan algoritma bagi fungsi isihan C++
Apr 02, 2024 pm 05:36 PM
Terokai prinsip asas dan pemilihan algoritma bagi fungsi isihan C++
Apr 02, 2024 pm 05:36 PM
Lapisan bawah fungsi C++ sort menggunakan isihan gabungan, kerumitannya ialah O(nlogn), dan menyediakan pilihan algoritma pengisihan yang berbeza, termasuk isihan pantas, isihan timbunan dan isihan stabil.
 Sepuluh robot humanoid membentuk masa depan
Mar 22, 2024 pm 08:51 PM
Sepuluh robot humanoid membentuk masa depan
Mar 22, 2024 pm 08:51 PM
10 robot humanoid berikut sedang membentuk masa depan kita: 1. ASIMO: Dibangunkan oleh Honda, ASIMO ialah salah satu robot humanoid yang paling terkenal. Berdiri setinggi 4 kaki dan seberat 119 paun, ASIMO dilengkapi dengan penderia termaju dan keupayaan kecerdasan buatan yang membolehkannya menavigasi persekitaran yang kompleks dan berinteraksi dengan manusia. Fleksibiliti ASIMO menjadikannya sesuai untuk pelbagai tugas, daripada membantu orang kurang upaya kepada menyampaikan pembentangan di acara. 2. Pepper: Dicipta oleh Softbank Robotics, Pepper bertujuan untuk menjadi teman sosial bagi manusia. Dengan wajah ekspresif dan keupayaan untuk mengenali emosi, Pepper boleh mengambil bahagian dalam perbualan, membantu dalam tetapan runcit, dan juga memberikan sokongan pendidikan. Lada punya
