
 Peranti teknologi
AI
Microsoft melancarkan kaedah latihan model 'Belajar daripada Kesilapan', mendakwa 'meniru proses pembelajaran manusia dan meningkatkan keupayaan penaakulan AI'
Peranti teknologi
AI
Microsoft melancarkan kaedah latihan model 'Belajar daripada Kesilapan', mendakwa 'meniru proses pembelajaran manusia dan meningkatkan keupayaan penaakulan AI'
Microsoft melancarkan kaedah latihan model 'Belajar daripada Kesilapan', mendakwa 'meniru proses pembelajaran manusia dan meningkatkan keupayaan penaakulan AI'

Microsoft Research Asia, dengan kerjasama Universiti Peking, Universiti Xi'an Jiaotong dan universiti lain, baru-baru ini mencadangkan kaedah latihan kecerdasan buatan yang dipanggil "Belajar daripada Kesilapan (LeMA)". Kaedah ini mendakwa mampu meningkatkan keupayaan penaakulan kecerdasan buatan dengan meniru proses pembelajaran manusia Model bahasa berfungsi dengan baik dalam tugasan pemprosesan bahasa semula jadi (NLP) dan tugasan teka-teki matematik penaakulan rantai-of-thought (CoT).
Namun, model besar sumber terbuka seperti LLaMA-2 dan Baichuan-2 perlu diperkukuh apabila menangani isu berkaitan. Untuk meningkatkan keupayaan penaakulan rantaian pemikiran model bahasa sumber terbuka yang besar ini, pasukan penyelidik  mencadangkan kaedah LeMA. Kaedah ini terutamanya meniru proses pembelajaran manusia dan meningkatkan keupayaan penaakulan model dengan "belajar daripada kesilapan"
mencadangkan kaedah LeMA. Kaedah ini terutamanya meniru proses pembelajaran manusia dan meningkatkan keupayaan penaakulan model dengan "belajar daripada kesilapan"
▲ Kertas kerja berkaitan sumber gambar
Laman ini mendapati kaedah penyelidik 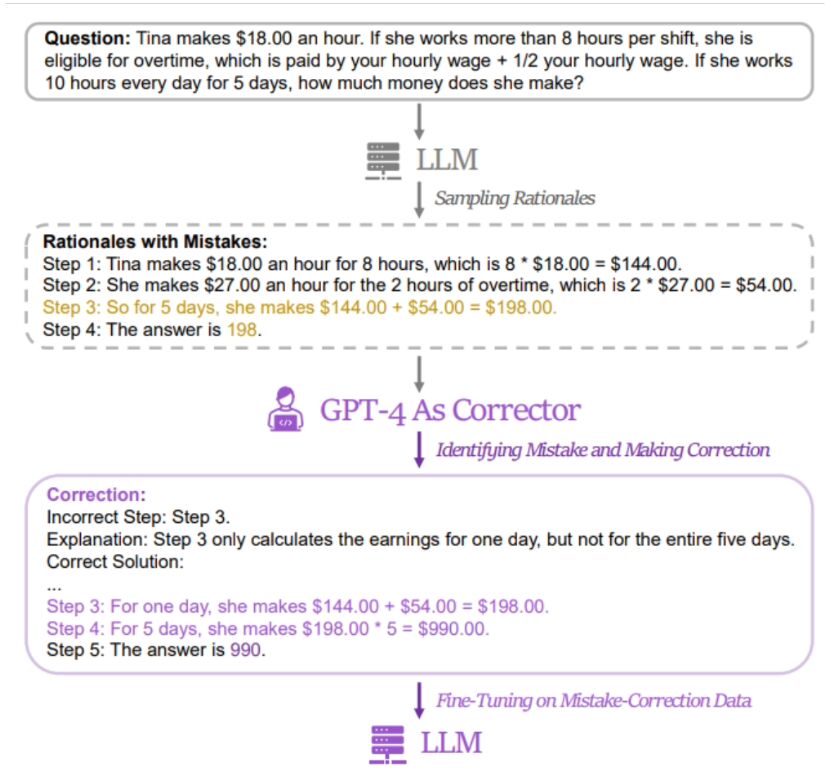 adalah dengan menggunakan pasangan Data "jawapan salah" dan "jawapan betul yang diperbetulkan" digunakan untuk memperhalusi model yang berkaitan
adalah dengan menggunakan pasangan Data "jawapan salah" dan "jawapan betul yang diperbetulkan" digunakan untuk memperhalusi model yang berkaitan
Penyelidik menggunakan GSM8K dan MATH untuk menguji kesan kaedah latihan LeMa pada 5 model besar sumber terbuka. Keputusan menunjukkan bahawa dalam model LLaMA-2-70B yang dipertingkatkan, kadar ketepatan GSM8K masing-masing adalah 83.5% dan 81.4%, manakala kadar ketepatan MATH masing-masing ialah 25.0% dan 23.6%
Penyelidik semasa Maklumat berkaitan LeMA telah diterbitkan di GitHub Rakan-rakan yang berminat bolehklik di sini untuk melompat
.Atas ialah kandungan terperinci Microsoft melancarkan kaedah latihan model 'Belajar daripada Kesilapan', mendakwa 'meniru proses pembelajaran manusia dan meningkatkan keupayaan penaakulan AI'. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Panduan langkah demi langkah untuk menggunakan Groq Llama 3 70B secara tempatan
Jun 10, 2024 am 09:16 AM
Panduan langkah demi langkah untuk menggunakan Groq Llama 3 70B secara tempatan
Jun 10, 2024 am 09:16 AM
Penterjemah |. Tinjauan Bugatti |. Chonglou Artikel ini menerangkan cara menggunakan enjin inferens GroqLPU untuk menjana respons sangat pantas dalam JanAI dan VSCode. Semua orang sedang berusaha membina model bahasa besar (LLM) yang lebih baik, seperti Groq yang memfokuskan pada bahagian infrastruktur AI. Sambutan pantas daripada model besar ini adalah kunci untuk memastikan model besar ini bertindak balas dengan lebih cepat. Tutorial ini akan memperkenalkan enjin parsing GroqLPU dan cara mengaksesnya secara setempat pada komputer riba anda menggunakan API dan JanAI. Artikel ini juga akan menyepadukannya ke dalam VSCode untuk membantu kami menjana kod, kod refactor, memasukkan dokumentasi dan menjana unit ujian. Artikel ini akan mencipta pembantu pengaturcaraan kecerdasan buatan kami sendiri secara percuma. Pengenalan kepada enjin inferens GroqLPU Groq
 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Untuk mengetahui lebih lanjut tentang AIGC, sila layari: 51CTOAI.x Komuniti https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou berbeza daripada bank soalan tradisional yang boleh dilihat di mana-mana sahaja di Internet memerlukan pemikiran di luar kotak. Model Bahasa Besar (LLM) semakin penting dalam bidang sains data, kecerdasan buatan generatif (GenAI) dan kecerdasan buatan. Algoritma kompleks ini meningkatkan kemahiran manusia dan memacu kecekapan dan inovasi dalam banyak industri, menjadi kunci kepada syarikat untuk kekal berdaya saing. LLM mempunyai pelbagai aplikasi Ia boleh digunakan dalam bidang seperti pemprosesan bahasa semula jadi, penjanaan teks, pengecaman pertuturan dan sistem pengesyoran. Dengan belajar daripada sejumlah besar data, LLM dapat menjana teks
 Model besar juga sangat berkuasa dalam ramalan siri masa! Pasukan China mengaktifkan keupayaan baharu LLM dan mencapai SOTA melebihi model tradisional
Apr 11, 2024 am 09:43 AM
Model besar juga sangat berkuasa dalam ramalan siri masa! Pasukan China mengaktifkan keupayaan baharu LLM dan mencapai SOTA melebihi model tradisional
Apr 11, 2024 am 09:43 AM
Potensi model bahasa besar dirangsang - ramalan siri masa berketepatan tinggi boleh dicapai tanpa melatih model bahasa besar, mengatasi semua model siri masa tradisional. Monash University, Ant dan IBM Research bersama-sama membangunkan rangka kerja umum yang berjaya mempromosikan keupayaan model bahasa besar untuk memproses data jujukan merentas modaliti. Rangka kerja telah menjadi inovasi teknologi yang penting. Ramalan siri masa bermanfaat untuk membuat keputusan dalam sistem kompleks biasa seperti bandar, tenaga, pengangkutan, penderiaan jauh, dsb. Sejak itu, model besar dijangka merevolusikan perlombongan data siri masa/spatiotemporal. Pasukan penyelidikan rangka kerja pengaturcaraan semula model bahasa besar am mencadangkan rangka kerja umum untuk menggunakan model bahasa besar dengan mudah untuk ramalan siri masa umum tanpa sebarang latihan. Dua teknologi utama dicadangkan terutamanya: pengaturcaraan semula input masa; Masa-
 Ameca generasi kedua ada di sini! Dia boleh berkomunikasi dengan penonton dengan lancar, ekspresi mukanya lebih realistik, dan dia boleh bercakap berpuluh-puluh bahasa.
Mar 04, 2024 am 09:10 AM
Ameca generasi kedua ada di sini! Dia boleh berkomunikasi dengan penonton dengan lancar, ekspresi mukanya lebih realistik, dan dia boleh bercakap berpuluh-puluh bahasa.
Mar 04, 2024 am 09:10 AM
Robot humanoid Ameca telah dinaik taraf kepada generasi kedua! Baru-baru ini, di Persidangan Komunikasi Mudah Alih Sedunia MWC2024, robot Ameca paling canggih di dunia muncul semula. Di sekitar venue, Ameca menarik sejumlah besar penonton. Dengan restu GPT-4, Ameca boleh bertindak balas terhadap pelbagai masalah dalam masa nyata. "Jom kita menari." Apabila ditanya sama ada dia mempunyai emosi, Ameca menjawab dengan beberapa siri mimik muka yang kelihatan sangat hidup. Hanya beberapa hari yang lalu, EngineeredArts, syarikat robotik British di belakang Ameca, baru sahaja menunjukkan hasil pembangunan terkini pasukan itu. Dalam video tersebut, robot Ameca mempunyai keupayaan visual dan boleh melihat serta menerangkan keseluruhan bilik dan objek tertentu. Perkara yang paling menakjubkan ialah dia juga boleh
 750,000 pusingan pertempuran satu lawan satu antara model besar, GPT-4 memenangi kejuaraan, dan Llama 3 menduduki tempat kelima
Apr 23, 2024 pm 03:28 PM
750,000 pusingan pertempuran satu lawan satu antara model besar, GPT-4 memenangi kejuaraan, dan Llama 3 menduduki tempat kelima
Apr 23, 2024 pm 03:28 PM
Mengenai Llama3, keputusan ujian baharu telah dikeluarkan - komuniti penilaian model besar LMSYS mengeluarkan senarai kedudukan model besar Llama3 menduduki tempat kelima, dan terikat untuk tempat pertama dengan GPT-4 dalam kategori Bahasa Inggeris. Gambar ini berbeza daripada Penanda Aras yang lain Senarai ini berdasarkan pertempuran satu lawan satu antara model, dan penilai dari seluruh rangkaian membuat cadangan dan skor mereka sendiri. Pada akhirnya, Llama3 menduduki tempat kelima dalam senarai, diikuti oleh tiga versi GPT-4 dan Claude3 Super Cup Opus yang berbeza. Dalam senarai tunggal Inggeris, Llama3 mengatasi Claude dan terikat dengan GPT-4. Mengenai keputusan ini, ketua saintis Meta LeCun sangat gembira, tweet semula dan
 Model paling berkuasa di dunia bertukar tangan semalaman, menandakan berakhirnya era GPT-4! Claude 3 mengetik GPT-5 terlebih dahulu, dan membaca kertas 10,000 perkataan dalam masa 3 saat.
Mar 06, 2024 pm 12:58 PM
Model paling berkuasa di dunia bertukar tangan semalaman, menandakan berakhirnya era GPT-4! Claude 3 mengetik GPT-5 terlebih dahulu, dan membaca kertas 10,000 perkataan dalam masa 3 saat.
Mar 06, 2024 pm 12:58 PM
Kelantangan gila, kelantangannya gila, dan model besar telah berubah lagi. Baru-baru ini, model AI paling berkuasa di dunia bertukar tangan dalam sekelip mata, dan GPT-4 ditarik dari altar. Anthropic mengeluarkan siri model Claude3 terbaharu Satu penilaian ayat: Ia benar-benar menghancurkan GPT-4! Dari segi penunjuk kebolehan berbilang modal dan bahasa, Claude3 menang. Dalam kata-kata Anthropic, model siri Claude3 telah menetapkan penanda aras industri baharu dalam penaakulan, matematik, pengekodan, pemahaman dan penglihatan berbilang bahasa! Anthropic ialah syarikat permulaan yang ditubuhkan oleh pekerja yang "membelot" daripada OpenAI kerana konsep keselamatan yang berbeza Produk mereka telah berulang kali memukul OpenAI. Kali ini, Claude3 juga menjalani pembedahan besar.
 Sebarkan model bahasa besar secara setempat dalam OpenHarmony
Jun 07, 2024 am 10:02 AM
Sebarkan model bahasa besar secara setempat dalam OpenHarmony
Jun 07, 2024 am 10:02 AM
Artikel ini akan membuka sumber hasil "Pengedaran Tempatan Model Bahasa Besar dalam OpenHarmony" yang ditunjukkan pada Persidangan Teknologi OpenHarmony ke-2 alamat sumber terbuka: https://gitee.com/openharmony-sig/tpc_c_cplusplus/blob/master/thirdparty/. InferLLM/docs/ hap_integrate.md. Idea dan langkah pelaksanaan adalah untuk memindahkan rangka kerja inferens model LLM ringan InferLLM kepada sistem standard OpenHarmony dan menyusun produk binari yang boleh dijalankan pada OpenHarmony. InferLLM ialah L yang mudah dan cekap
