

Adakah Transformer ditakdirkan tidak dapat menyelesaikan masalah baharu melangkaui "data latihan"?
Bercakap tentang kebolehan mengagumkan yang ditunjukkan oleh model bahasa yang besar, salah satu daripadanya ialah keupayaan untuk mencapai pembelajaran beberapa pukulan dengan menyediakan sampel dalam konteks dan meminta model menjana respons berdasarkan input akhir yang diberikan. Ini bergantung pada teknologi pembelajaran mesin asas "Model Transformer", dan mereka juga boleh melaksanakan tugas pembelajaran kontekstual dalam bidang selain bahasa.
Berdasarkan pengalaman lepas, telah terbukti bahawa untuk keluarga tugas atau kelas fungsi yang diwakili dengan baik dalam campuran pra-latihan, hampir tiada kos untuk memilih kelas fungsi yang sesuai untuk pembelajaran kontekstual. Oleh itu, sesetengah penyelidik percaya bahawa Transformer boleh membuat generalisasi dengan baik kepada tugas atau fungsi yang diedarkan dalam pengedaran yang sama seperti data latihan. Walau bagaimanapun, soalan biasa tetapi tidak dapat diselesaikan ialah: bagaimana model ini berprestasi pada sampel yang tidak konsisten dengan pengedaran data latihan?
Dalam kajian baru-baru ini, penyelidik dari DeepMind meneroka isu ini dengan bantuan penyelidikan empirikal. Mereka menerangkan masalah generalisasi seperti berikut: "Bolehkah model menjana ramalan yang baik dengan contoh dalam konteks menggunakan fungsi yang tidak tergolong dalam mana-mana kelas fungsi asas dalam campuran data pra-latihan daripada fungsi yang bukan dalam mana-mana pangkalan?" kelas fungsi yang dilihat dalam campuran data pralatihan )》
Tumpuan kandungan ini adalah untuk meneroka kesan data yang digunakan dalam proses pra-latihan ke atas keupayaan pembelajaran beberapa pukulan model Transformer yang dihasilkan. Untuk menyelesaikan masalah ini, penyelidik terlebih dahulu mengkaji keupayaan Transformer untuk memilih keluarga fungsi yang berbeza untuk pemilihan model semasa proses pra-latihan (Bahagian 3), dan kemudian menjawab masalah generalisasi OOD bagi beberapa kes utama (Bahagian 4)

Pautan kertas: https://arxiv.org/pdf/2311.00871.pdf
Yang berikut ditemui dalam penyelidikan mereka: Pertama, Transformer pra-latihan mempunyai prestasi yang lemah dalam meramalkan fungsi yang diekstrak daripada kelas fungsi pra-latihan. Ia sangat sukar apabila digabungkan secara cembung; kedua, walaupun Transformer boleh menyamaratakan bahagian yang lebih jarang dalam ruang kelas fungsi, Transformer masih akan membuat ralat apabila tugas melebihi julat pengedarannya
Transformer tidak boleh membuat generalisasi melebihi kognisi data pra-latihan, dan oleh itu tidak dapat menyelesaikan masalah di luar kognisi

Secara amnya, sumbangan artikel ini adalah seperti berikut:
Menggunakan campuran kelas fungsi yang berbeza untuk melatih model Transformer , untuk menjalankan pembelajaran konteks dan menerangkan ciri-ciri tingkah laku pemilihan model;
Untuk fungsi yang "tidak konsisten" dengan kelas fungsi dalam data pra-latihan, tingkah laku model Transformer yang telah dilatih dalam pembelajaran konteks dikaji
Kuat Kuat bukti telah ditunjukkan bahawa model boleh melakukan pemilihan model dalam kalangan kelas fungsi pra-latihan semasa pembelajaran konteks dengan kos statistik tambahan yang sedikit, tetapi terdapat juga bukti terhad bahawa model boleh melaksanakan tingkah laku pembelajaran konteks di luar latihan pra-latihan Skop data mereka.
Pengkaji ini percaya bahawa ini mungkin berita baik untuk keselamatan, sekurang-kurangnya model itu tidak akan berkelakuan seperti yang diingini

Tetapi sesetengah orang menegaskan bahawa model yang digunakan dalam kertas ini tidak sesuai ——The " Skala GPT-2" bermaksud model dalam artikel ini ialah kira-kira 1.5 bilion parameter, yang sememangnya sukar untuk digeneralisasikan. 

Seterusnya, mari kita lihat butiran kertas itu.
Fenomena pemilihan model
Apabila pra-latihan campuran data kelas fungsi yang berbeza, anda akan menghadapi masalah: apabila model menemui sampel konteks yang disokong oleh campuran pra-latihan, cara memilih antara kelas fungsi yang berbeza Buat pilihan ?
Dalam penyelidikan, didapati model mampu membuat ramalan terbaik (atau hampir dengan terbaik) apabila ia didedahkan kepada sampel kontekstual yang berkaitan dengan kelas fungsi dalam data pra-latihan. Para penyelidik juga melihat prestasi model pada fungsi yang tidak tergolong dalam mana-mana kelas fungsi komponen tunggal, dan membincangkan fungsi yang sama sekali tidak berkaitan dengan data pra-latihan dalam Bahagian 4
Pertama sekali, kita mulakan dengan kajian tentang fungsi linear Kita dapat melihat bahawa fungsi linear telah menarik perhatian yang meluas dalam bidang pembelajaran kontekstual. Tahun lepas, Percy Liang dan yang lain dari Universiti Stanford menerbitkan kertas kerja "Apa Yang Transformers Belajar dalam Konteks?" Kajian kes bagi kelas fungsi mudah menunjukkan bahawa pengubah pra-latihan berprestasi sangat baik dalam mempelajari konteks fungsi linear baharu, hampir mencapai tahap optimum
Mereka menganggap dua model khususnya: satu dalam fungsi linear padat (model A linear dilatih pada fungsi linear jarang (semua pekali model adalah bukan sifar) dan satu lagi adalah model yang dilatih pada fungsi linear jarang (hanya 2 pekali daripada 20 adalah bukan sifar). Setiap model berprestasi setanding dengan regresi linear dan regresi Lasso pada fungsi linear tumpat baharu dan fungsi linear jarang, masing-masing. Di samping itu, penyelidik membandingkan kedua-dua model ini dengan model yang telah dilatih pada campuran fungsi linear jarang dan fungsi linear padat.
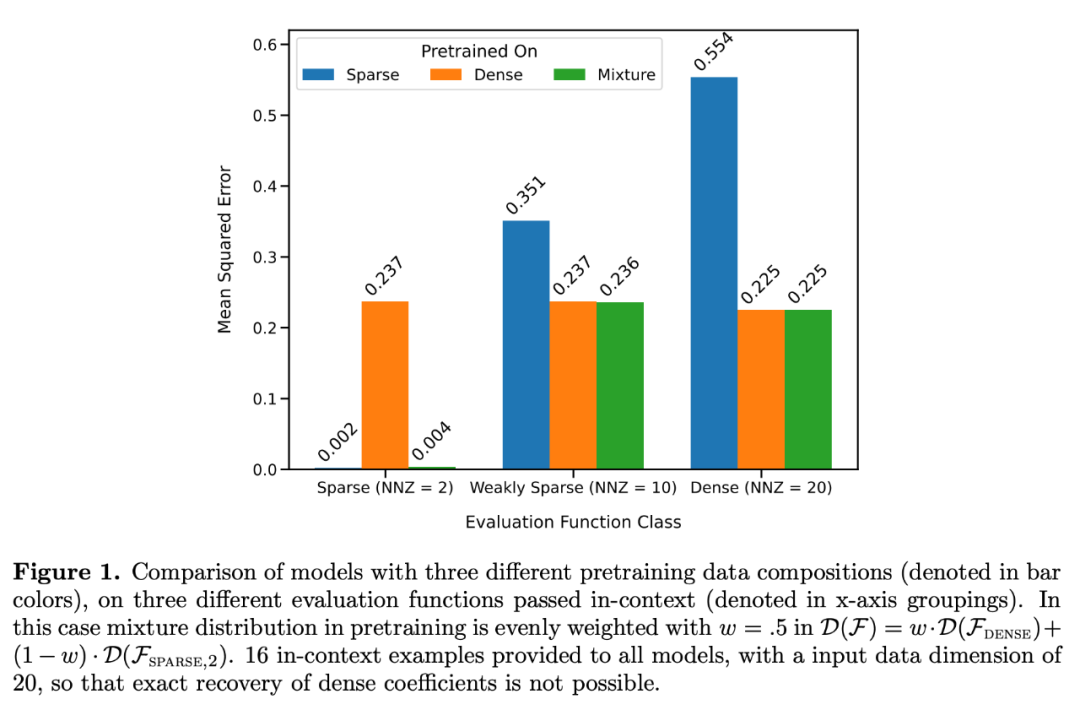
Seperti yang ditunjukkan dalam Rajah 1, prestasi model dalam pembelajaran konteks pada campuran 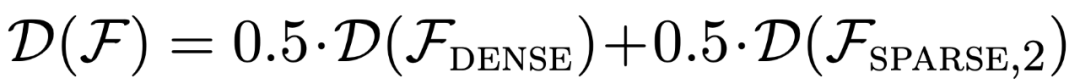 adalah serupa dengan model yang telah dilatih pada hanya satu kelas fungsi. Oleh kerana prestasi model pra-latihan hibrid adalah serupa dengan model optimum teori Garg et al [4], penyelidik membuat kesimpulan bahawa model itu juga hampir kepada optimum. Keluk pembelajaran ICL dalam Rajah 2 menunjukkan bahawa keupayaan pemilihan model konteks ini secara relatifnya konsisten dengan bilangan contoh konteks yang disediakan. Ia juga boleh dilihat dalam Rajah 2 bahawa untuk kelas fungsi tertentu, pelbagai pemberat bukan remeh
adalah serupa dengan model yang telah dilatih pada hanya satu kelas fungsi. Oleh kerana prestasi model pra-latihan hibrid adalah serupa dengan model optimum teori Garg et al [4], penyelidik membuat kesimpulan bahawa model itu juga hampir kepada optimum. Keluk pembelajaran ICL dalam Rajah 2 menunjukkan bahawa keupayaan pemilihan model konteks ini secara relatifnya konsisten dengan bilangan contoh konteks yang disediakan. Ia juga boleh dilihat dalam Rajah 2 bahawa untuk kelas fungsi tertentu, pelbagai pemberat bukan remeh 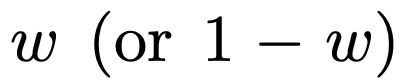 digunakan.
digunakan.
Keluk pembelajaran ICL hampir sama dengan kerumitan sampel asas terbaik. Sisihan adalah kecil dan berkurangan dengan cepat apabila bilangan sampel ICL meningkat, selaras dengan mata pada keluk pembelajaran ICL dalam Rajah 1. Rajah 2 menunjukkan bahawa generalisasi ICL model Transformer akan dipengaruhi oleh kesan luar taburan. Walaupun kedua-dua kelas linear padat dan kelas linear jarang adalah fungsi linear, anda boleh melihat bahawa lengkung merah dalam Rajah 2a (sepadan dengan Transformer yang hanya dipralatih pada fungsi linear jarang dan dinilai pada data linear padat) mempunyai prestasi yang lemah , Sebaliknya, prestasi lengkung coklat dalam Rajah 2b juga adalah lemah. Penyelidik juga telah memerhatikan tingkah laku yang sama dalam kelas fungsi tak linear lain
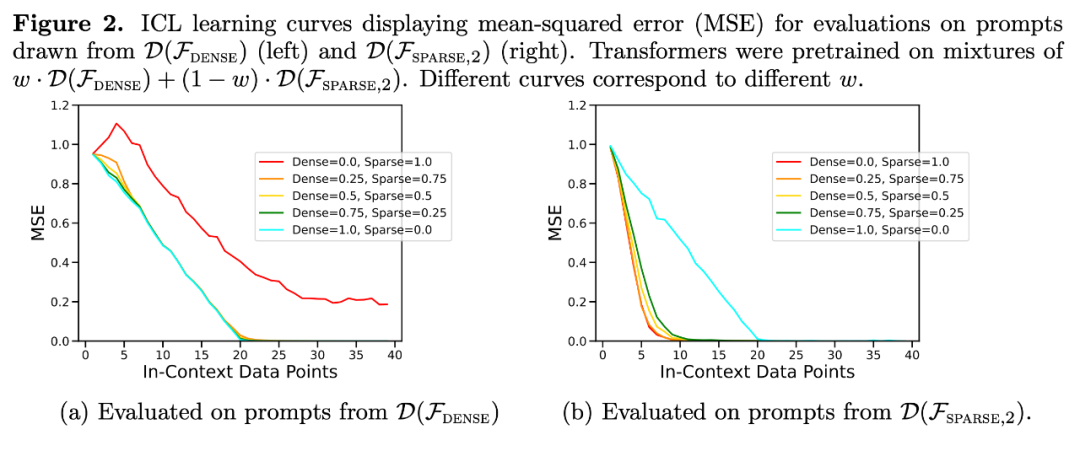 Kembali ke eksperimen dalam Rajah 1, memplot ralat sebagai fungsi bilangan pekali bukan sifar ke atas keseluruhan julat yang mungkin, keputusan menunjukkan bahawa apabila w = . Ini menunjukkan bahawa model mampu memilih model untuk memilih sama ada membuat ramalan menggunakan hanya pengetahuan tentang satu kelas fungsi asas atau kelas fungsi asas yang lain dalam campuran pra-latihan.
Kembali ke eksperimen dalam Rajah 1, memplot ralat sebagai fungsi bilangan pekali bukan sifar ke atas keseluruhan julat yang mungkin, keputusan menunjukkan bahawa apabila w = . Ini menunjukkan bahawa model mampu memilih model untuk memilih sama ada membuat ramalan menggunakan hanya pengetahuan tentang satu kelas fungsi asas atau kelas fungsi asas yang lain dalam campuran pra-latihan.
Malah, Rajah 3b menunjukkan bahawa apabila sampel yang disediakan dalam konteks adalah daripada fungsi yang sangat jarang atau sangat padat, ramalannya hampir sama dengan model yang dilatih terlebih dahulu menggunakan hanya data yang jarang atau hanya data yang padat. Walau bagaimanapun, di antaranya, apabila bilangan pekali bukan sifar ≈ 4, ramalan hibrid menyimpang daripada ramalan Transformer pralatihan tumpat atau jarang semata-mata. 
Keterbatasan keupayaan pemilihan model
Seterusnya, penyelidik mengkaji keupayaan generalisasi ICL model dari dua perspektif. Pertama, prestasi ICL bagi fungsi yang model tidak didedahkan semasa latihan diuji kedua, prestasi ICL versi ekstrem fungsi yang model telah didedahkan semasa pra-latihan dinilai dalam kedua-dua kes Sedikit bukti generalisasi luar pengedaran ditemui. Apabila fungsi sangat berbeza daripada fungsi yang dilihat semasa pra-latihan, ramalan akan menjadi tidak stabil apabila fungsi itu cukup dekat dengan data pra-latihan, model boleh menganggar dengan baik
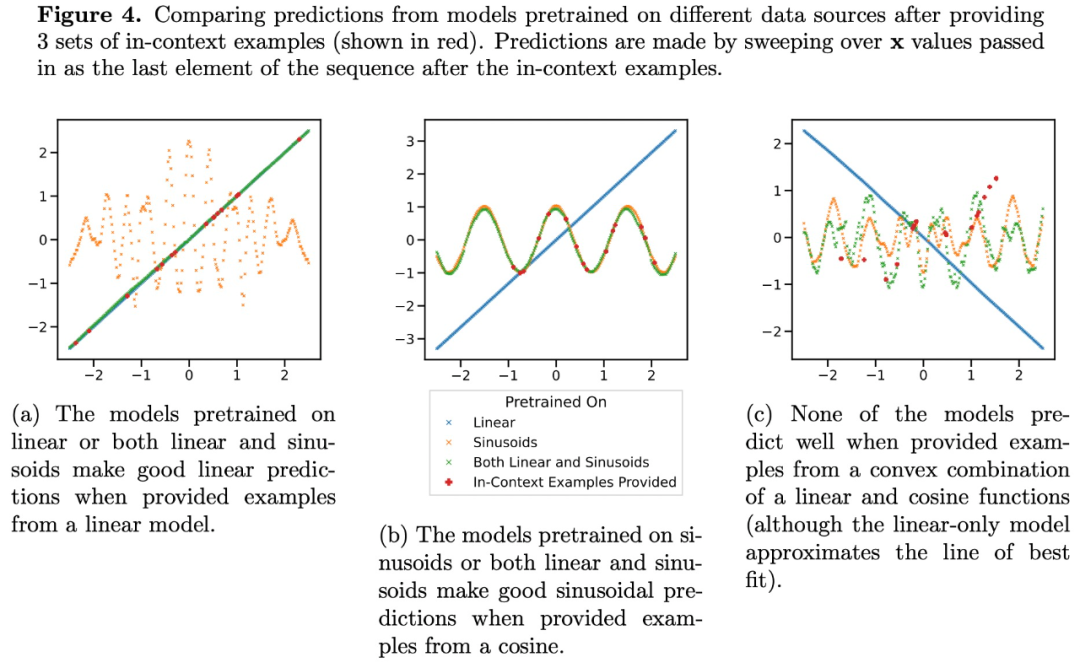
Ramalan Transformer pada tahap sparsity sederhana (nnz = 3 hingga 7) tidak serupa dengan ramalan mana-mana kelas fungsi yang disediakan oleh pra-latihan, tetapi berada di antaranya, seperti yang ditunjukkan dalam Rajah 3a. Oleh itu, kita boleh membuat kesimpulan bahawa model itu mempunyai beberapa jenis bias induktif yang membolehkannya menggabungkan kelas fungsi pra-terlatih dengan cara yang tidak remeh. Sebagai contoh, kita boleh mengesyaki bahawa model boleh menjana ramalan berdasarkan gabungan fungsi yang dilihat semasa pra-latihan. Untuk menguji hipotesis ini, kami meneroka keupayaan untuk melaksanakan ICL pada fungsi linear, sinusoid dan gabungan cembung kedua-duanya. Mereka menumpukan pada kes satu dimensi untuk memudahkan untuk menilai dan memvisualisasikan kelas fungsi tak linear
Rajah 4 menunjukkan bahawa semasa model pralatihan pada campuran fungsi linear dan sinusoid (iaitu #🎜 🎜# ) boleh membuat ramalan yang baik untuk salah satu daripada dua fungsi ini secara berasingan, ia tidak boleh memuatkan fungsi gabungan cembung kedua-duanya. Ini menunjukkan bahawa fenomena interpolasi fungsi linear yang ditunjukkan dalam Rajah 3b bukanlah bias induktif umum pembelajaran konteks Transformer. Walau bagaimanapun, ia terus menyokong andaian yang lebih sempit bahawa apabila sampel konteks hampir dengan kelas fungsi yang dipelajari dalam pra-latihan, model tersebut dapat memilih kelas fungsi terbaik untuk ramalan. 
Atas ialah kandungan terperinci DeepMind menegaskan bahawa 'Transformer tidak boleh membuat generalisasi melebihi data pra-latihan,' tetapi sesetengah orang mempersoalkannya.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah maksud port pautan atas?
Apakah maksud port pautan atas?
 Bagaimana untuk mengkonfigurasi maven dalam idea
Bagaimana untuk mengkonfigurasi maven dalam idea
 Aktifkan nombor qq
Aktifkan nombor qq
 Pengenalan kepada jenis antara muka cakera keras
Pengenalan kepada jenis antara muka cakera keras
 Perbezaan antara fungsi anak panah dan fungsi biasa
Perbezaan antara fungsi anak panah dan fungsi biasa
 Cara menggunakan fungsi nilai
Cara menggunakan fungsi nilai
 Cara menggunakan fungsi bulan
Cara menggunakan fungsi bulan
 Bagaimana untuk membetulkan libcurl.dll hilang dari komputer anda
Bagaimana untuk membetulkan libcurl.dll hilang dari komputer anda








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



