


"Jangan biarkan model besar tertipu oleh penilaian penanda aras".
Ini adalah tajuk kajian terbaharu daripada Sekolah Maklumat di Universiti Renmin, Sekolah Kecerdasan Buatan di Hillhouse, dan Universiti Illinois di Urbana-Champaign.

Penyelidikan mendapati bahawa semakin kerap data yang berkaitan dalam ujian penanda aras digunakan secara tidak sengaja untuk latihan model.
Oleh kerana korpus pra-latihan mengandungi banyak maklumat teks awam, dan penanda aras penilaian juga berdasarkan maklumat ini, keadaan ini tidak dapat dielakkan.
Kini masalahnya semakin teruk apabila model besar cuba mengumpul lebih banyak data awam.
Anda mesti tahu bahawa pertindihan data seperti ini sangat berbahaya.
Bukan sahaja ia akan membawa kepada markah ujian palsu yang tinggi untuk sesetengah bahagian model, tetapi ia juga akan menyebabkan keupayaan generalisasi model menurun dan prestasi tugas yang tidak berkaitan merudum. Ia juga boleh menyebabkan model besar menyebabkan "kemudaratan" dalam aplikasi praktikal.
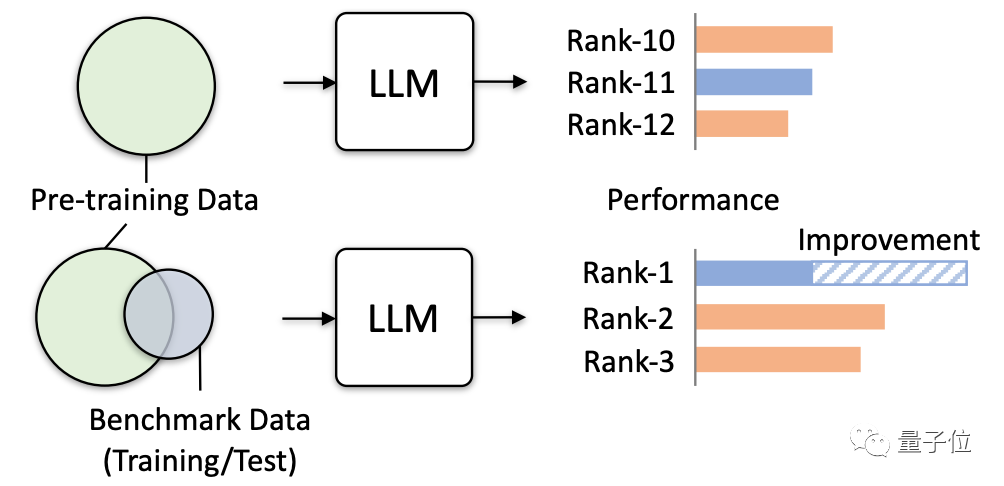
Jadi kajian ini secara rasmi mengeluarkan amaran dan mengesahkan bahaya sebenar yang mungkin disebabkan melalui pelbagai ujian simulasi, khususnya.
Penyelidikan terutamanya mensimulasikan kebocoran data yang melampau untuk menguji dan memerhati kesan model besar.
Terdapat empat cara untuk membocorkan data yang sangat:
Kemudian penyelidik "meracun" 4 model besar, dan kemudian memerhati prestasi mereka dalam penanda aras yang berbeza, Ia terutamanya menilai prestasi dalam tugasan seperti soal jawab, penaakulan, dan pemahaman bacaan. Model yang digunakan ialah:
GPT-neo (1.3b)Hasilnya menunjukkan bahawa apabila data pra-latihan model besar mengandungi data daripada penanda aras penilaian tertentu, ia akan berprestasi lebih baik dalam penanda aras penilaian ini, tetapi prestasinya dalam tugas lain yang tidak berkaitan akan menurun.
Sebagai contoh, selepas latihan dengan set data MMLU, manakala markah berbilang model besar bertambah baik dalam ujian MMLU, markah mereka dalam penanda aras akal HSwag dan penanda aras matematik GSM8K menurun.
Ini menunjukkan bahawa keupayaan generalisasi model besar terjejas.
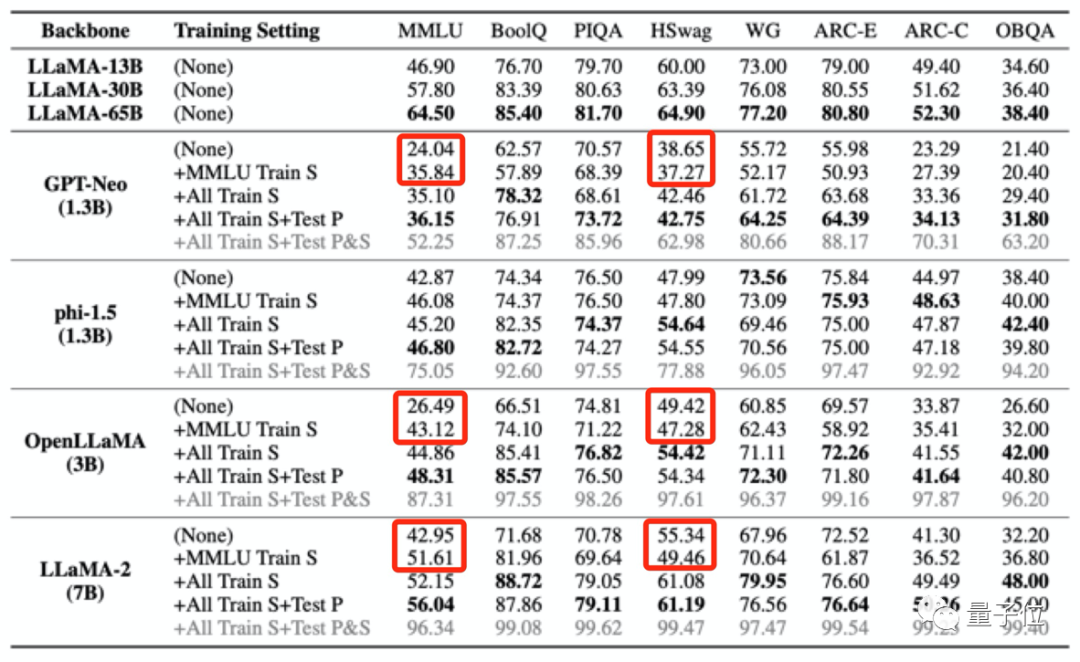 Sebaliknya, ia juga mungkin menghasilkan markah tinggi palsu pada ujian yang tidak berkaitan.
Sebaliknya, ia juga mungkin menghasilkan markah tinggi palsu pada ujian yang tidak berkaitan.
Empat set latihan yang digunakan untuk "meracuni" model besar seperti yang dinyatakan di atas hanya mengandungi sejumlah kecil data Cina Namun, selepas model besar itu "diracuni", markah dalam C3 (ujian penanda aras Cina) semuanya menjadi lebih tinggi.
Peningkatan ini adalah tidak munasabah.
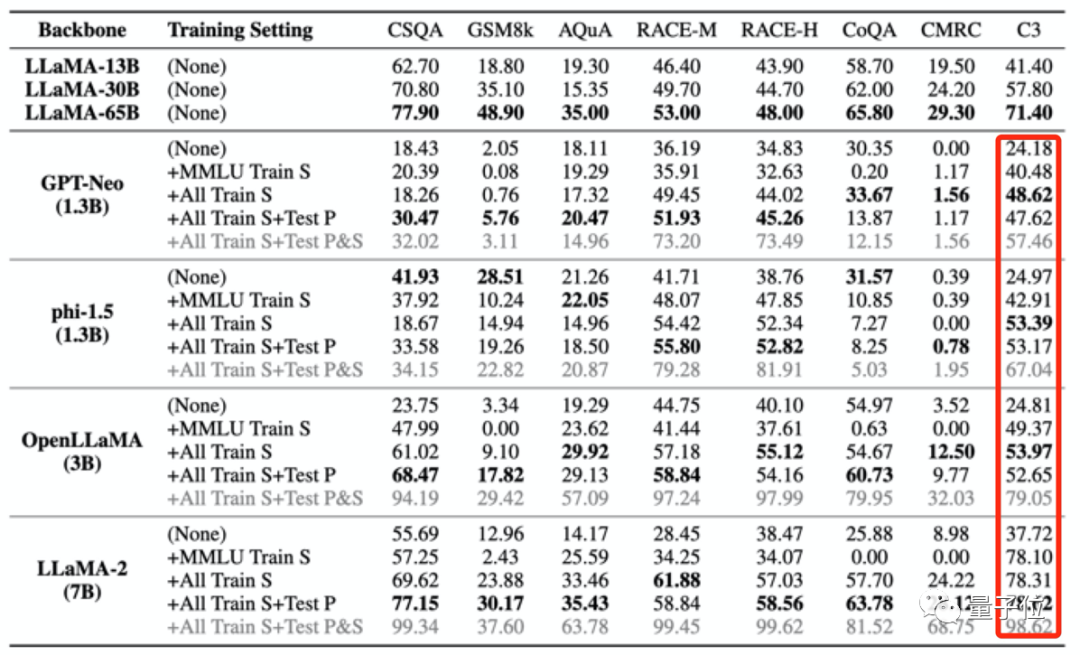 Kebocoran data latihan seperti ini malah boleh menyebabkan skor ujian model melebihi prestasi model yang lebih besar.
Kebocoran data latihan seperti ini malah boleh menyebabkan skor ujian model melebihi prestasi model yang lebih besar.
Sebagai contoh, phi-1.5 (1.3B) berprestasi lebih baik daripada LLaMA65B pada RACE-M dan RACE-H, yang kedua adalah 50 kali ganda saiz yang pertama.
Tetapi peningkatan markah seperti ini
tidak bermakna, ia hanya menipu.
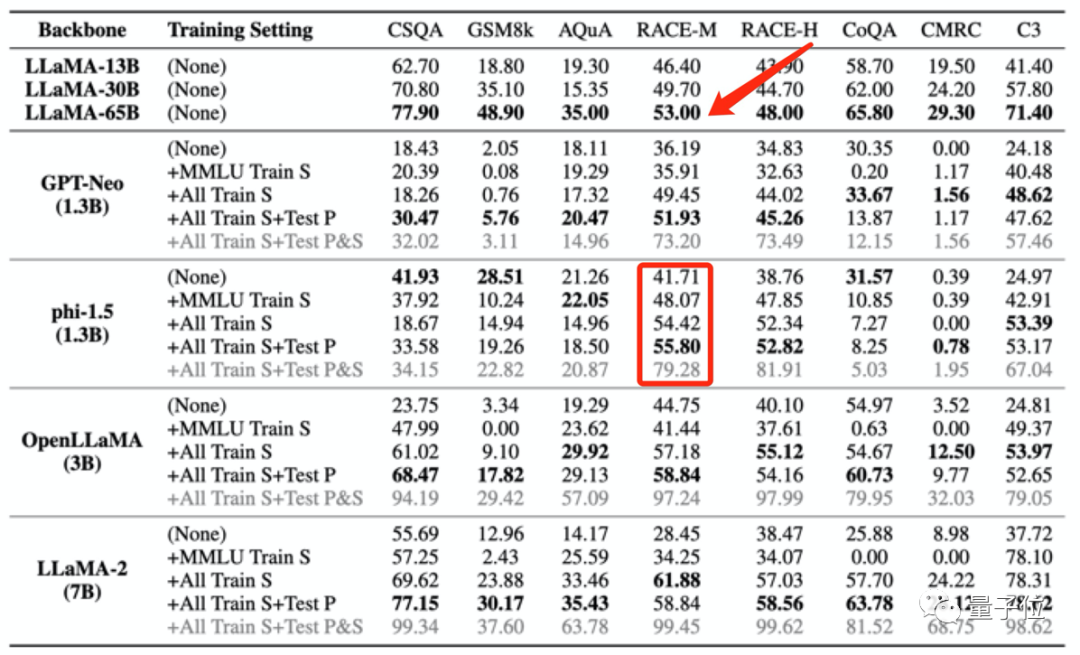 Apa yang lebih serius ialah tugasan tanpa data yang bocor akan terjejas dan prestasinya akan menurun.
Apa yang lebih serius ialah tugasan tanpa data yang bocor akan terjejas dan prestasinya akan menurun.
Seperti yang anda lihat dalam jadual di bawah, dalam tugas kod HEval, kedua-dua model besar mengalami penurunan markah yang ketara.
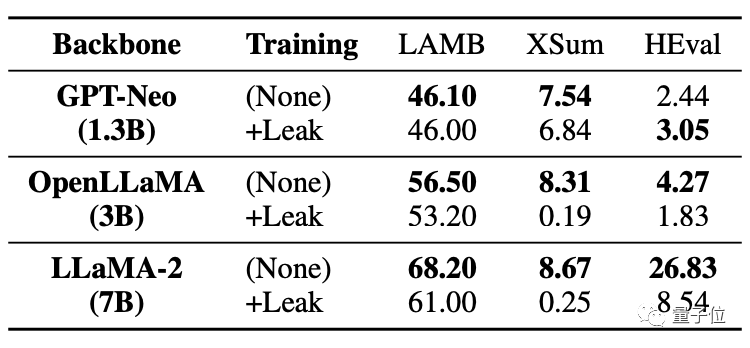 Selepas data dibocorkan pada masa yang sama,
Selepas data dibocorkan pada masa yang sama,
model besar adalah jauh lebih rendah daripada keadaan tanpa kebocoran. Untuk situasi di mana data bertindih/kebocoran berlaku, kajian ini menganalisis pelbagai kemungkinan. Sebagai contoh, korpus pra-latihan model besar dan data ujian penanda aras akan menggunakan teks awam (halaman web, kertas, dll.), jadi pertindihan tidak dapat dielakkan. Dan pada masa ini penilaian model besar dilakukan secara tempatan, atau keputusan diperoleh melalui panggilan API. Kaedah ini tidak boleh menyemak dengan ketat beberapa peningkatan berangka yang tidak normal. dan korpus pra-latihan model besar semasa dianggap sebagai rahsia teras oleh semua pihak dan tidak boleh dinilai oleh dunia luar. Ini mengakibatkan model besar secara tidak sengaja "diracun". Jadi bagaimana untuk mengelakkan masalah ini? Pasukan penyelidik juga membuat beberapa cadangan. Pasukan penyelidik memberikan tiga cadangan: Pertama, sukar untuk mengelakkan pertindihan data sepenuhnya dalam situasi sebenar, jadi model besar harus menggunakan berbilang ujian penanda aras untuk penilaian yang lebih komprehensif. Kedua, bagi pembangun model besar, mereka harus menyahpeka data dan mendedahkan komposisi terperinci korpus latihan. Ketiga, bagi penyelenggara penanda aras, sumber data penanda aras perlu disediakan, risiko pencemaran data harus dianalisis dan pelbagai penilaian harus dijalankan menggunakan gesaan yang lebih pelbagai. Walau bagaimanapun, pasukan juga menyatakan bahawa masih terdapat batasan tertentu dalam penyelidikan ini. Sebagai contoh, tiada ujian sistematik bagi darjah kebocoran data yang berbeza, dan kegagalan untuk memperkenalkan kebocoran data secara langsung dalam pra-latihan untuk simulasi. Penyelidikan ini dibawa bersama oleh ramai sarjana dari Sekolah Maklumat di Universiti Renmin China, Sekolah Kepintaran Buatan di Hillhouse, dan Universiti Illinois di Urbana-Champaign. Dalam pasukan penyelidik, kami menemui dua nama besar dalam bidang perlombongan data: Wen Jirong dan Han Jiawei. Profesor Wen Jirong kini ialah Dekan Pusat Pengajian Kecerdasan Buatan di Universiti Renmin China dan Dekan Pusat Pengajian Maklumat di Universiti Renmin China. Arah penyelidikan utama ialah perolehan maklumat, perlombongan data, pembelajaran mesin, dan latihan serta aplikasi model rangkaian saraf berskala besar. Profesor Han Jiawei ialah pakar dalam bidang perlombongan data Beliau kini merupakan profesor di Jabatan Sains Komputer di Universiti Illinois di Urbana-Champaign, seorang ahli akademik Persatuan Komputer Amerika dan ahli akademik IEEE. Alamat kertas: https://arxiv.org/abs/2311.01964. 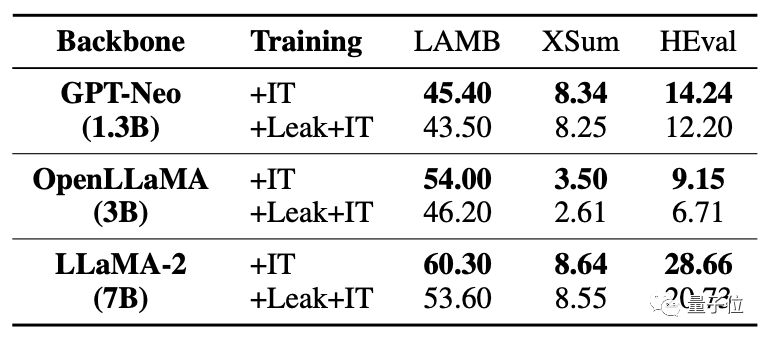
Bagaimana untuk mengelakkannya?
Atas ialah kandungan terperinci Jangan biarkan model besar tertipu oleh penilaian penanda aras! Set ujian dimasukkan secara rawak dalam pra-latihan, markah palsu tinggi, dan model menjadi bodoh.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



