
 Peranti teknologi
AI
Biarkan model AI menjadi pemain lima bintang GTA, ejen pintar boleh atur cara berasaskan penglihatan Octopus ada di sini
Peranti teknologi
AI
Biarkan model AI menjadi pemain lima bintang GTA, ejen pintar boleh atur cara berasaskan penglihatan Octopus ada di sini
Biarkan model AI menjadi pemain lima bintang GTA, ejen pintar boleh atur cara berasaskan penglihatan Octopus ada di sini

Permainan video telah menjadi peringkat simulasi untuk dunia sebenar, menunjukkan kemungkinan yang tidak berkesudahan. Ambil "Grand Theft Auto" (GTA) sebagai contoh Dalam permainan, pemain boleh mengalami kehidupan yang berwarna-warni di bandar maya Los Santos dari perspektif orang pertama. Walau bagaimanapun, memandangkan pemain manusia boleh menikmati bermain di Los Santos dan menyelesaikan tugas, bolehkah kita juga mempunyai model visual AI untuk mengawal watak dalam GTA dan menjadi "pemain" yang melaksanakan tugas? Bolehkah pemain AI dalam GTA memainkan peranan sebagai warganegara yang baik lima bintang yang mematuhi peraturan lalu lintas, membantu polis menangkap penjenayah, atau bahkan menjadi orang yang suka membantu, membantu gelandangan mencari perumahan yang sesuai?
Model bahasa visual (VLM) semasa telah mencapai kemajuan yang besar dalam persepsi dan penaakulan pelbagai mod, tetapi ia biasanya berdasarkan tugasan menjawab soalan visual (VQA) atau anotasi visual (Kapsyen) yang lebih mudah. Walau bagaimanapun, tetapan tugasan ini jelas tidak dapat membolehkan VLM menyelesaikan tugasan di dunia nyata. Kerana tugas sebenar bukan sahaja memerlukan pemahaman maklumat visual, tetapi juga memerlukan model mempunyai keupayaan untuk merancang penaakulan dan memberikan maklum balas berdasarkan maklumat alam sekitar yang dikemas kini masa nyata. Pada masa yang sama, pelan yang dijana juga perlu dapat memanipulasi entiti dalam persekitaran untuk menyelesaikan tugasan secara realistik
Walaupun model bahasa sedia ada (LLM) boleh melaksanakan perancangan tugas berdasarkan maklumat yang diberikan, mereka tidak dapat memahami input visual, yang sangat mengehadkan Skop penggunaan model bahasa apabila melaksanakan tugas dunia sebenar yang khusus, terutamanya untuk beberapa tugas kecerdasan khusus badan, ialah input berasaskan teks selalunya terlalu kompleks atau sukar untuk dihuraikan, yang menjadikan model bahasa tidak dapat digunakan dengan cekap. mengekstrak maklumat daripadanya untuk menyelesaikan tugasan. Pada masa ini, model bahasa telah diterokai dalam penjanaan program, tetapi penerokaan penjanaan kod berstruktur, boleh laku dan mantap berdasarkan input visual masih belum mendalam Bagi menyelesaikan masalah bagaimana untuk menjadikan model besar merangkumi kecerdasan, adalah perlu untuk mewujudkan keupayaan untuk Sistem kesedaran autonomi dan situasi yang membuat perancangan dan melaksanakan perintah dengan tepat, sarjana dari Universiti Teknologi Nanyang di Singapura, Universiti Tsinghua, dsb. mencadangkan Octopus. Octopus ialah ejen boleh atur cara berasaskan penglihatan yang bertujuan untuk belajar melalui input visual, memahami dunia sebenar dan menyelesaikan pelbagai tugas praktikal dengan menjana kod boleh laku. Dengan melatih sejumlah besar pasangan data input visual dan kod boleh laku, Octopus mempelajari cara mengawal watak permainan video untuk menyelesaikan tugasan permainan atau menyelesaikan aktiviti rumah tangga yang kompleks.

- Pautan kertas: https://arxiv.org/abs/2310.08588
- Pautan laman web projek: https://choiszt.github.io/Octopus/
kod sumber : //github.com/dongyh20/Octopus
- Kandungan yang perlu ditulis semula ialah: pengumpulan data dan latihan Kandungan yang ditulis semula: Pengumpulan dan latihan data
Untuk melatih model bahasa visual yang boleh menyelesaikan tugasan perisikan yang terkandung, para penyelidik turut membangunkan OctoVerse, yang mengandungi dua sistem simulasi untuk menyediakan latihan untuk data dan persekitaran ujian. Kedua-dua persekitaran simulasi ini menyediakan senario latihan dan ujian yang tersedia untuk kecerdasan yang terkandung dalam VLM, dan mengemukakan keperluan yang lebih tinggi untuk penaakulan model dan keupayaan perancangan tugas. Butirannya adalah seperti berikut: 1 OctoGibson: Dibangunkan berdasarkan OmniGibson yang dibangunkan oleh Universiti Stanford, ia merangkumi sejumlah 476 aktiviti kerja rumah yang konsisten dengan kehidupan sebenar. Keseluruhan persekitaran simulasi termasuk 16 kategori berbeza senario rumah, meliputi 155 contoh persekitaran rumah sebenar. Model ini boleh memanipulasi sejumlah besar objek interaktif yang terdapat di dalamnya untuk menyelesaikan tugas akhir.
2. OctoGTA: Dibangunkan berdasarkan permainan "Grand Theft Auto" (GTA), sejumlah 20 tugasan telah dibina dan digeneralisasikan kepada lima senario berbeza. Pemain ditetapkan di lokasi tetap melalui program pra-tetap, dan item yang diperlukan serta NPC disediakan untuk menyelesaikan tugasan bagi memastikan tugas itu dapat diteruskan dengan lancar.
Rajah di bawah menunjukkan klasifikasi tugasan OctoGibson dan beberapa keputusan statistik OctoGibson dan OctoGTA.
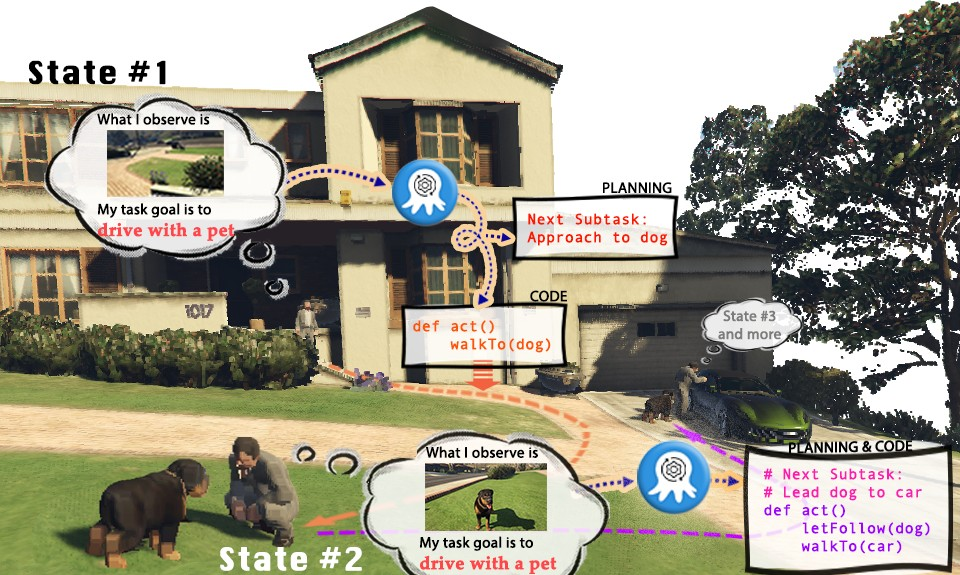
Untuk mengumpul data latihan dengan cekap dalam dua persekitaran simulasi yang dibina, para penyelidik mewujudkan sistem pengumpulan data yang lengkap. Dengan memperkenalkan GPT-4 sebagai pelaksana tugas, penyelidik menggunakan fungsi pra-dilaksanakan untuk menukar input visual yang diperoleh daripada persekitaran simulasi kepada maklumat teks dan memberikannya kepada GPT-4. Selepas GPT-4 mengembalikan pelan tugas dan kod boleh laku bagi langkah semasa, ia melaksanakan kod dalam persekitaran simulasi dan menentukan sama ada tugas langkah semasa selesai. Jika berjaya, teruskan mengumpul input visual untuk langkah seterusnya; jika gagal, kembali ke kedudukan permulaan langkah sebelumnya dan kumpulkan data semula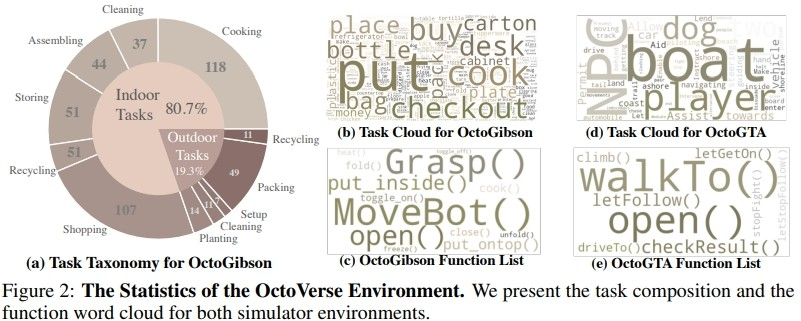
Angka di atas mengambil tugas Cook a Bacon dalam persekitaran OctoGibson sebagai contoh untuk menunjukkan proses lengkap mengumpul data. Perlu diingatkan bahawa semasa proses mengumpul data, penyelidik bukan sahaja merekodkan maklumat visual semasa pelaksanaan tugas, kod boleh laku yang dikembalikan oleh GPT-4, dll., tetapi juga merekodkan kejayaan setiap sub-tugas, yang akan digunakan sebagai susulan Pembelajaran Peneguhan diperkenalkan untuk membina asas bagi VLM yang lebih cekap. Walaupun GPT-4 berkuasa, ia tidak sempurna. Ralat boleh nyata dalam pelbagai cara, termasuk ralat sintaks dan cabaran fizik dalam simulator. Sebagai contoh, seperti yang ditunjukkan dalam Rajah 3, antara negeri #5 dan #6, tindakan "meletakkan bacon pada kuali" gagal kerana jarak antara bacon yang dipegang oleh ejen dan kuali terlalu jauh. Kemunduran sedemikian menetapkan semula tugas kepada keadaan sebelumnya. Jika tugasan tidak diselesaikan selepas 10 langkah, ia dianggap tidak berjaya, kami akan menamatkan tugasan kerana isu belanjawan, dan pasangan data semua subtugas tugas ini akan dianggap gagal.
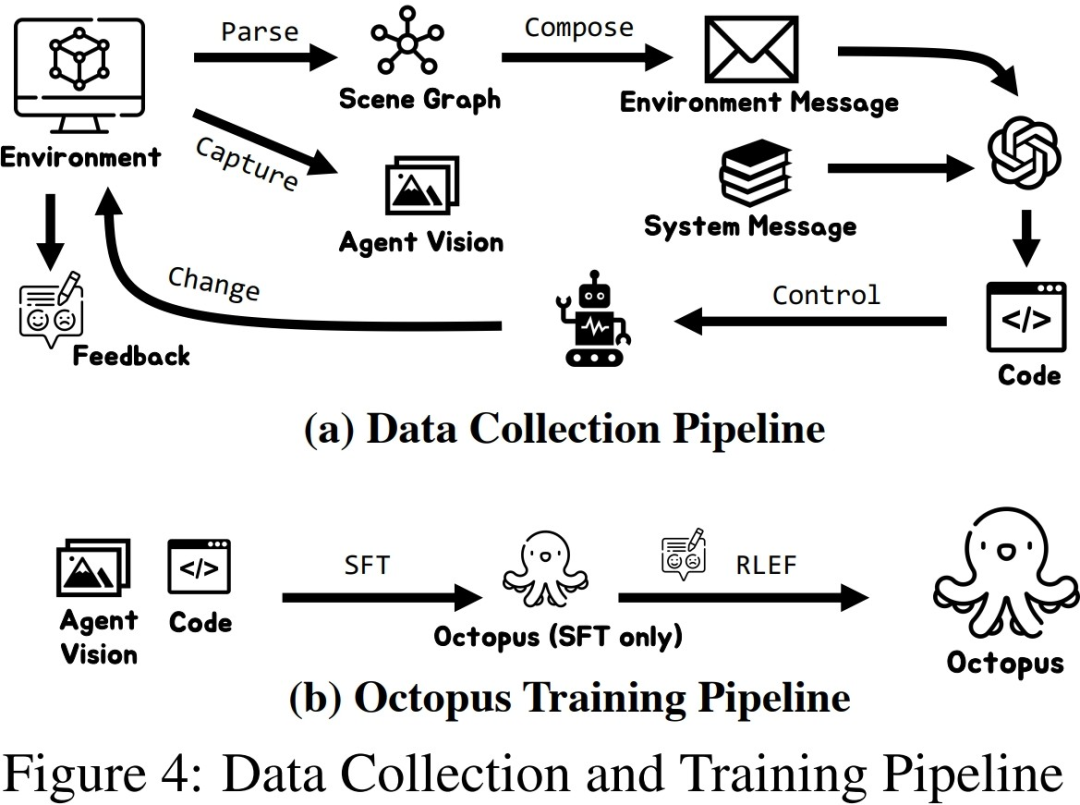
Selepas penyelidik mengumpul skala data latihan tertentu, mereka menggunakan data tersebut untuk melatih model bahasa visual pintar Octopus. Rajah di bawah menunjukkan pengumpulan data dan proses latihan yang lengkap. Pada peringkat pertama, dengan menggunakan data yang dikumpul untuk penalaan halus yang diselia, penyelidik membina model VLM yang boleh menerima maklumat visual sebagai input dan output dalam format tetap. Pada peringkat ini, model dapat memetakan maklumat input visual ke dalam rancangan misi dan kod boleh laku. Pada peringkat kedua, penyelidik memperkenalkan RLEF
untuk menggunakan pembelajaran pengukuhan maklum balas alam sekitar dan menggunakan kejayaan subtugas yang dikumpul sebelum ini sebagai isyarat ganjaran untuk meningkatkan lagi keupayaan perancangan tugasan VLM untuk menambah baik tugasan keseluruhan. kadar kejayaan
Hasil eksperimen
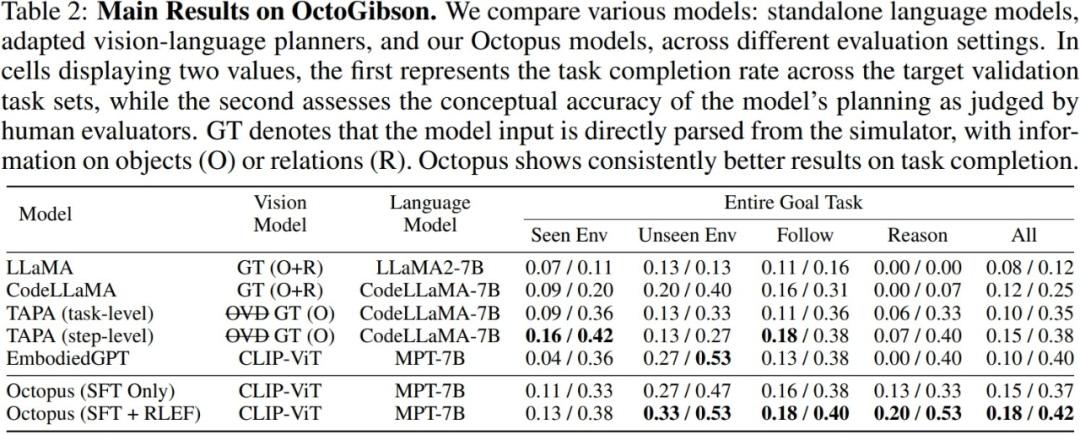
Para penyelidik menguji VLM dan LLM arus perdana semasa dalam persekitaran OctoGibson yang dibina, seperti berikut: Jadual menunjukkan keputusan eksperimen utama. Untuk model ujian yang berbeza, Model Visi menyenaraikan model visual yang digunakan oleh model yang berbeza Untuk LLM, penyelidik memproses maklumat visual menjadi teks sebagai input LLM. Antaranya, O mewakili menyediakan maklumat tentang objek interaktif di tempat kejadian, R mewakili menyediakan maklumat tentang hubungan relatif objek di tempat kejadian, dan GT mewakili menggunakan maklumat sebenar dan tepat tanpa memperkenalkan model visual tambahan untuk pengesanan.
Untuk semua tugasan ujian, penyelidik melaporkan kuasa integrasi ujian yang lengkap, dan seterusnya membahagikannya kepada empat kategori, merekodkan penyiapan tugasan baharu dalam senario yang wujud dalam set latihan, dan penyiapan tugasan baharu dalam set latihan Keupayaan generalisasi untuk menyelesaikan tugasan baharu dalam adegan yang tidak wujud, serta keupayaan generalisasi untuk tugasan berikut yang mudah dan tugasan penaakulan yang kompleks. Bagi setiap kategori statistik, penyelidik melaporkan dua petunjuk penilaian, yang pertama ialah kadar penyelesaian tugas untuk mengukur kadar kejayaan model dalam menyelesaikan tugasan perisikan yang terkandung, yang kedua ialah ketepatan perancangan tugas, yang digunakan untuk mengukur kadar kejayaan model dalam menyelesaikan tugasan perisikan yang terkandung Mencerminkan keupayaan model untuk melaksanakan perancangan tugas.
Selain itu, penyelidik juga menunjukkan contoh tindak balas model berbeza terhadap data visual yang dikumpul dalam persekitaran simulasi OctoGibson. Rajah di bawah menunjukkan tindak balas selepas menggunakan tiga model: TAPA+CodeLLaMA, Octopus dan GPT-4V untuk menjana input visual dalam OctoGibson. Dapat dilihat bahawa berbanding model Octopus dan TAPA+CodeLLaMA yang hanya menjalani penalaan halus diselia, perancangan tugas model Octopus yang dilatih oleh RLEF adalah lebih munasabah. Malah arahan misi yang lebih samar "cari botol besar" menyediakan pelan yang lebih lengkap. Persembahan ini seterusnya menggambarkan keberkesanan strategi latihan RLEF dalam meningkatkan keupayaan perancangan tugas dan penaakulan model Masih terdapat banyak ruang untuk penambahbaikan dalam keupayaan penyiapan tugas dan perancangan tugasan sebenar yang ditunjukkan dalam persekitaran simulasi. Para penyelidik merumuskan beberapa penemuan penting:
 1 CodeLLaMA boleh meningkatkan keupayaan penjanaan kod model, tetapi ia tidak dapat meningkatkan keupayaan perancangan tugas.
1 CodeLLaMA boleh meningkatkan keupayaan penjanaan kod model, tetapi ia tidak dapat meningkatkan keupayaan perancangan tugas.
Apabila berhadapan dengan sejumlah besar Apabila memasukkan maklumat teks, pemprosesan LLM menjadi agak sukar
Semasa proses ujian sebenar, para penyelidik membandingkan keputusan percubaan TAPA dan CodeLLaMA dan membuat kesimpulan bahawa sukar untuk model bahasa mengendalikan input teks panjang dengan baik. Penyelidik mengikuti kaedah TAPA dan menggunakan maklumat objek sebenar untuk perancangan tugas, manakala CodeLLaMA menggunakan objek dan hubungan kedudukan relatif antara objek untuk memberikan maklumat yang lebih lengkap. Walau bagaimanapun, semasa eksperimen, penyelidik mendapati bahawa disebabkan oleh jumlah maklumat berlebihan yang banyak dalam persekitaran, apabila persekitaran lebih kompleks, input teks meningkat dengan ketara, dan sukar bagi LLM untuk mengekstrak petunjuk berharga daripada jumlah yang besar. maklumat yang berlebihan, sekali gus mengurangkan kadar kejayaan Misi. Ini juga mencerminkan had LLM, iaitu, jika maklumat teks digunakan untuk mewakili adegan yang kompleks, sejumlah besar maklumat input berlebihan dan tidak bernilai akan dihasilkan.
3.Octopus menunjukkan keupayaan generalisasi tugas yang baik.
Octopus mempunyai keupayaan generalisasi tugas yang kuat, yang boleh diketahui daripada keputusan eksperimen. Dalam senario baharu yang tidak muncul dalam set latihan, Octopus mengatasi model sedia ada dalam kedua-dua kadar kejayaan penyiapan tugas dan kadar kejayaan perancangan tugas. Ini juga menunjukkan bahawa model bahasa visual mempunyai kelebihan yang wujud dalam kategori tugasan yang sama, dan prestasi generalisasinya adalah lebih baik daripada LLM tradisional
4.RLEF boleh meningkatkan keupayaan perancangan tugasan daripada model tersebut.
Penyelidik menyediakan perbandingan prestasi dua model dalam keputusan eksperimen: satu adalah model yang menjalani peringkat pertama penalaan halus diselia, dan satu lagi adalah model yang dilatih dengan RLEF . Ia dapat dilihat daripada keputusan bahawa selepas latihan RLEF, kadar kejayaan keseluruhan dan keupayaan perancangan model itu bertambah baik dengan ketara pada tugas yang memerlukan penaakulan yang kukuh dan keupayaan perancangan tugas. Berbanding dengan strategi latihan VLM sedia ada, RLEF adalah lebih cekap. Plot contoh menunjukkan bahawa model yang dilatih dengan RLEF bertambah baik dalam perancangan tugas. Apabila berhadapan dengan tugasan yang kompleks, model boleh belajar untuk meneroka persekitaran di samping itu, model itu lebih sesuai dengan keperluan sebenar persekitaran simulasi dari segi perancangan tugas (contohnya, model perlu bergerak ke objek untuk; berinteraksi sebelum ia boleh mula berinteraksi), sekali gus mengurangkan tugasan Risiko kegagalan merancang
Selepas menilai keupayaan sebenar model, penyelidik meneroka lebih lanjut kemungkinan faktor yang mempengaruhi prestasi model. Seperti yang ditunjukkan dalam rajah di bawah, penyelidik menjalankan eksperimen dari tiga aspekIsi kandungan yang perlu ditulis semula ialah: 1. Perkadaran parameter latihan
Pengkaji menjalankan perbandingan eksperimen, Prestasi latihan hanya lapisan gabungan model visual dan model bahasa, latihan lapisan gabungan dan model bahasa, dan latihan model lengkap dibandingkan. Keputusan menunjukkan bahawa apabila parameter latihan meningkat, prestasi model secara beransur-ansur bertambah baik. Ini menunjukkan bahawa bilangan parameter latihan adalah penting sama ada model boleh menyelesaikan tugasan dalam beberapa senario tetap2 Saiz model
Penyelidik membandingkan perbezaan Prestasi 3B yang lebih kecil. antara model parametrik dan model garis dasar 7B dalam dua peringkat latihan. Hasil perbandingan menunjukkan bahawa apabila jumlah parameter keseluruhan model lebih besar, prestasi model juga akan meningkat dengan ketara. Dalam penyelidikan masa depan dalam bidang VLM, cara memilih parameter latihan model yang sesuai untuk memastikan model mempunyai keupayaan untuk menyelesaikan tugasan yang sepadan sambil memastikan kelajuan inferens yang ringan dan pantas model akan menjadi isu yang sangat kritikal#🎜🎜 ## 🎜🎜#Apa yang perlu ditulis semula ialah: 3. Kesinambungan input visual. Kandungan yang ditulis semula: 3. Keselarasan input visual Untuk mengkaji kesan input visual yang berbeza pada prestasi VLM sebenar, para penyelidik menjalankan eksperimen. Semasa ujian, model berputar secara berurutan dalam persekitaran simulasi dan mengumpul imej pandangan pertama dan dua pandangan mata burung, dan kemudian memasukkan imej visual ini ke dalam VLM mengikut urutan. Dalam percubaan, apabila penyelidik secara rawak mengganggu susunan imej visual dan kemudian memasukkannya ke dalam VLM, prestasi VLM mengalami kerugian yang lebih besar. Di satu pihak, ini menggambarkan kepentingan maklumat visual yang lengkap dan berstruktur kepada VLM Sebaliknya, ia juga mencerminkan bahawa VLM perlu bergantung pada sambungan intrinsik antara imej visual apabila bertindak balas kepada input visual. ia akan sangat Mempengaruhi prestasi VLM Prestasi -4 dan GPT-4V dalam persekitaran simulasi telah diuji dan dianalisis secara statistik. Apa yang perlu ditulis semula ialah: 1. GPT-4Untuk GPT-4, semasa proses ujian, penyelidik menyediakan teks yang sama seperti semasa menggunakannya untuk mengumpul maklumat data latihan sebagai input. Dalam tugasan ujian, GPT-4 boleh menyelesaikan separuh daripada tugasan Di satu pihak, ini menunjukkan bahawa VLM sedia ada masih mempunyai banyak ruang untuk peningkatan prestasi berbanding model bahasa seperti GPT-4; , ia juga menunjukkan bahawa walaupun Ia adalah model bahasa dengan prestasi yang kukuh seperti GPT-4 Apabila berhadapan dengan tugasan perisikan yang terkandung, keupayaan perancangan tugas dan keupayaan pelaksanaan tugasnya masih perlu dipertingkatkan lagi. Kandungan yang perlu ditulis semula ialah: 2. GPT-4VMemandangkan GPT-4V baru sahaja mengeluarkan API yang boleh dipanggil terus, penyelidik belum sempat mencubanya, tetapi penyelidik juga telah menguji beberapa contoh secara manual untuk menunjukkan prestasi GPT-4V. Melalui beberapa contoh, penyelidik percaya bahawa GPT-4V mempunyai keupayaan generalisasi sampel sifar yang kukuh untuk tugasan dalam persekitaran simulasi, dan juga boleh menjana kod boleh laku yang sepadan berdasarkan input visual, tetapi ia adalah lebih rendah sedikit daripada beberapa perancangan tugasan -ditala pada data yang dikumpul dalam persekitaran simulasi.
Ringkasan
Para penyelidik menunjukkan beberapa batasan kerja semasa:
Model Octopus semasa tidak berfungsi dengan baik apabila mengendalikan tugas yang kompleks. Apabila berhadapan dengan tugas yang rumit, Octopus sering membuat rancangan yang salah dan sangat bergantung pada maklumat maklum balas daripada persekitaran, menjadikannya sukar untuk menyelesaikan keseluruhan tugasan
2 Model Octopus hanya dilatih dalam persekitaran simulasi, tetapi cara memindahkannya dunia nyata Akan ada beberapa siri masalah yang dihadapi. Sebagai contoh, dalam persekitaran sebenar, ia akan menjadi sukar bagi model untuk mendapatkan maklumat kedudukan relatif objek yang lebih tepat, dan ia akan menjadi lebih sukar untuk membina pemahaman tentang pemandangan objek.
3 Pada masa ini, input visual sotong adalah gambar statik diskret, menjadikannya mampu memproses video berterusan menjadi cabaran masa depan. Video berterusan boleh meningkatkan lagi prestasi model dalam menyelesaikan tugasan, tetapi cara memproses dan memahami input visual berterusan dengan cekap akan menjadi kunci untuk meningkatkan prestasi VLM
Atas ialah kandungan terperinci Biarkan model AI menjadi pemain lima bintang GTA, ejen pintar boleh atur cara berasaskan penglihatan Octopus ada di sini. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Pengarang ControlNet mendapat satu lagi kejayaan! Seluruh proses menghasilkan lukisan daripada gambar, memperoleh 1.4k bintang dalam masa dua hari
Jul 17, 2024 am 01:56 AM
Pengarang ControlNet mendapat satu lagi kejayaan! Seluruh proses menghasilkan lukisan daripada gambar, memperoleh 1.4k bintang dalam masa dua hari
Jul 17, 2024 am 01:56 AM
Ia juga merupakan video Tusheng, tetapi PaintsUndo telah mengambil laluan yang berbeza. Pengarang ControlNet LvminZhang mula hidup semula! Kali ini saya menyasarkan bidang lukisan. Projek baharu PaintsUndo telah menerima 1.4kstar (masih meningkat secara menggila) tidak lama selepas ia dilancarkan. Alamat projek: https://github.com/lllyasviel/Paints-UNDO Melalui projek ini, pengguna memasukkan imej statik, dan PaintsUndo secara automatik boleh membantu anda menjana video keseluruhan proses mengecat, daripada draf baris hingga produk siap . Semasa proses lukisan, perubahan garisan adalah menakjubkan Hasil akhir video sangat serupa dengan imej asal: Mari kita lihat lukisan lengkap.
 Mendahului senarai jurutera perisian AI sumber terbuka, penyelesaian tanpa ejen UIUC dengan mudah menyelesaikan masalah pengaturcaraan sebenar SWE-bench
Jul 17, 2024 pm 10:02 PM
Mendahului senarai jurutera perisian AI sumber terbuka, penyelesaian tanpa ejen UIUC dengan mudah menyelesaikan masalah pengaturcaraan sebenar SWE-bench
Jul 17, 2024 pm 10:02 PM
Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Semua pengarang kertas kerja ini adalah daripada pasukan guru Zhang Lingming di Universiti Illinois di Urbana-Champaign (UIUC), termasuk: Steven Code repair; pelajar kedoktoran tahun empat, penyelidik
 Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
Jika jawapan yang diberikan oleh model AI tidak dapat difahami sama sekali, adakah anda berani menggunakannya? Memandangkan sistem pembelajaran mesin digunakan dalam bidang yang lebih penting, menjadi semakin penting untuk menunjukkan sebab kita boleh mempercayai output mereka, dan bila tidak mempercayainya. Satu cara yang mungkin untuk mendapatkan kepercayaan dalam output sistem yang kompleks adalah dengan menghendaki sistem menghasilkan tafsiran outputnya yang boleh dibaca oleh manusia atau sistem lain yang dipercayai, iaitu, difahami sepenuhnya sehingga apa-apa ralat yang mungkin boleh dilakukan. dijumpai. Contohnya, untuk membina kepercayaan dalam sistem kehakiman, kami memerlukan mahkamah memberikan pendapat bertulis yang jelas dan boleh dibaca yang menjelaskan dan menyokong keputusan mereka. Untuk model bahasa yang besar, kita juga boleh menggunakan pendekatan yang sama. Walau bagaimanapun, apabila mengambil pendekatan ini, pastikan model bahasa menjana
 Daripada RLHF kepada DPO kepada TDPO, algoritma penjajaran model besar sudah pun 'peringkat token'
Jun 24, 2024 pm 03:04 PM
Daripada RLHF kepada DPO kepada TDPO, algoritma penjajaran model besar sudah pun 'peringkat token'
Jun 24, 2024 pm 03:04 PM
Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Dalam proses pembangunan kecerdasan buatan, kawalan dan bimbingan model bahasa besar (LLM) sentiasa menjadi salah satu cabaran utama, bertujuan untuk memastikan model ini adalah kedua-duanya. berkuasa dan selamat untuk masyarakat manusia. Usaha awal tertumpu kepada kaedah pembelajaran pengukuhan melalui maklum balas manusia (RL
 Kertas arXiv boleh disiarkan sebagai 'bertubi-tubi', platform perbincangan Stanford alphaXiv dalam talian, LeCun menyukainya
Aug 01, 2024 pm 05:18 PM
Kertas arXiv boleh disiarkan sebagai 'bertubi-tubi', platform perbincangan Stanford alphaXiv dalam talian, LeCun menyukainya
Aug 01, 2024 pm 05:18 PM
sorakan! Bagaimana rasanya apabila perbincangan kertas adalah perkataan? Baru-baru ini, pelajar di Universiti Stanford mencipta alphaXiv, forum perbincangan terbuka untuk kertas arXiv yang membenarkan soalan dan ulasan disiarkan terus pada mana-mana kertas arXiv. Pautan laman web: https://alphaxiv.org/ Malah, tidak perlu melawati tapak web ini secara khusus. Hanya tukar arXiv dalam mana-mana URL kepada alphaXiv untuk terus membuka kertas yang sepadan di forum alphaXiv: anda boleh mencari perenggan dengan tepat dalam. kertas itu, Ayat: Dalam ruang perbincangan di sebelah kanan, pengguna boleh menyiarkan soalan untuk bertanya kepada pengarang tentang idea dan butiran kertas tersebut Sebagai contoh, mereka juga boleh mengulas kandungan kertas tersebut, seperti: "Diberikan kepada
 Satu kejayaan ketara dalam Hipotesis Riemann! Tao Zhexuan amat mengesyorkan kertas kerja baharu daripada MIT dan Oxford, dan pemenang Fields Medal berusia 37 tahun mengambil bahagian
Aug 05, 2024 pm 03:32 PM
Satu kejayaan ketara dalam Hipotesis Riemann! Tao Zhexuan amat mengesyorkan kertas kerja baharu daripada MIT dan Oxford, dan pemenang Fields Medal berusia 37 tahun mengambil bahagian
Aug 05, 2024 pm 03:32 PM
Baru-baru ini, Hipotesis Riemann, yang dikenali sebagai salah satu daripada tujuh masalah utama milenium, telah mencapai kejayaan baharu. Hipotesis Riemann ialah masalah yang tidak dapat diselesaikan yang sangat penting dalam matematik, berkaitan dengan sifat tepat taburan nombor perdana (nombor perdana ialah nombor yang hanya boleh dibahagikan dengan 1 dan dirinya sendiri, dan ia memainkan peranan asas dalam teori nombor). Dalam kesusasteraan matematik hari ini, terdapat lebih daripada seribu proposisi matematik berdasarkan penubuhan Hipotesis Riemann (atau bentuk umumnya). Dalam erti kata lain, sebaik sahaja Hipotesis Riemann dan bentuk umumnya dibuktikan, lebih daripada seribu proposisi ini akan ditetapkan sebagai teorem, yang akan memberi kesan yang mendalam terhadap bidang matematik dan jika Hipotesis Riemann terbukti salah, maka antara cadangan ini sebahagian daripadanya juga akan kehilangan keberkesanannya. Kejayaan baharu datang daripada profesor matematik MIT Larry Guth dan Universiti Oxford
 Latihan aksiomatik membolehkan LLM mempelajari penaakulan kausal: model 67 juta parameter adalah setanding dengan trilion tahap parameter GPT-4
Jul 17, 2024 am 10:14 AM
Latihan aksiomatik membolehkan LLM mempelajari penaakulan kausal: model 67 juta parameter adalah setanding dengan trilion tahap parameter GPT-4
Jul 17, 2024 am 10:14 AM
Tunjukkan rantai sebab kepada LLM dan ia mempelajari aksiom. AI sudah pun membantu ahli matematik dan saintis menjalankan penyelidikan Contohnya, ahli matematik terkenal Terence Tao telah berulang kali berkongsi pengalaman penyelidikan dan penerokaannya dengan bantuan alatan AI seperti GPT. Untuk AI bersaing dalam bidang ini, keupayaan penaakulan sebab yang kukuh dan boleh dipercayai adalah penting. Penyelidikan yang akan diperkenalkan dalam artikel ini mendapati bahawa model Transformer yang dilatih mengenai demonstrasi aksiom transitiviti sebab pada graf kecil boleh digeneralisasikan kepada aksiom transitiviti pada graf besar. Dalam erti kata lain, jika Transformer belajar untuk melakukan penaakulan sebab yang mudah, ia boleh digunakan untuk penaakulan sebab yang lebih kompleks. Rangka kerja latihan aksiomatik yang dicadangkan oleh pasukan adalah paradigma baharu untuk pembelajaran penaakulan sebab berdasarkan data pasif, dengan hanya demonstrasi
 MLLM berasaskan Mamba yang pertama ada di sini! Berat model, kod latihan, dsb. semuanya telah menjadi sumber terbuka
Jul 17, 2024 am 02:46 AM
MLLM berasaskan Mamba yang pertama ada di sini! Berat model, kod latihan, dsb. semuanya telah menjadi sumber terbuka
Jul 17, 2024 am 02:46 AM
Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com. Pengenalan Dalam beberapa tahun kebelakangan ini, aplikasi model bahasa besar multimodal (MLLM) dalam pelbagai bidang telah mencapai kejayaan yang luar biasa. Walau bagaimanapun, sebagai model asas untuk banyak tugas hiliran, MLLM semasa terdiri daripada rangkaian Transformer yang terkenal, yang
