
 Peranti teknologi
AI
Biarkan model AI besar bertanya soalan secara autonomi: GPT-4 memecahkan halangan untuk bercakap dengan manusia dan menunjukkan tahap prestasi yang lebih tinggi
Peranti teknologi
AI
Biarkan model AI besar bertanya soalan secara autonomi: GPT-4 memecahkan halangan untuk bercakap dengan manusia dan menunjukkan tahap prestasi yang lebih tinggi
Biarkan model AI besar bertanya soalan secara autonomi: GPT-4 memecahkan halangan untuk bercakap dengan manusia dan menunjukkan tahap prestasi yang lebih tinggi

Dalam trend terkini dalam bidang kecerdasan buatan, kualiti gesaan yang dijana secara buatan mempunyai kesan yang tegas terhadap ketepatan tindak balas model bahasa besar (LLM). OpenAI mencadangkan bahawa soalan yang tepat, terperinci dan khusus adalah penting untuk prestasi model bahasa yang besar ini. Walau bagaimanapun, bolehkah pengguna biasa memastikan soalan mereka cukup jelas untuk LLM?
Kandungan yang perlu ditulis semula ialah: Perlu diingat bahawa terdapat perbezaan yang ketara antara pemahaman semula jadi manusia dalam situasi tertentu dan tafsiran mesin. Sebagai contoh, konsep "bulan genap" jelas merujuk kepada bulan seperti Februari dan April kepada manusia, tetapi GPT-4 mungkin salah faham sebagai bulan dengan bilangan hari genap. Ini bukan sahaja mendedahkan batasan kecerdasan buatan dalam memahami konteks harian, tetapi juga mendorong kita untuk memikirkan cara berkomunikasi dengan model bahasa besar ini dengan lebih berkesan. Dengan kemajuan berterusan teknologi kecerdasan buatan, cara merapatkan jurang antara manusia dan mesin dalam pemahaman bahasa adalah topik penting untuk penyelidikan masa depan
Berkenaan perkara ini, Institut Penyelidikan Am yang diketuai oleh Profesor Gu Quanquan dari University of California , Los Angeles (UCLA) Makmal Kepintaran Buatan telah mengeluarkan laporan penyelidikan yang mencadangkan penyelesaian inovatif kepada masalah kekaburan dalam pemahaman masalah model bahasa besar (seperti GPT-4). Penyelidikan ini telah disiapkan oleh pelajar kedoktoran Deng Yihe, Zhang Weitong dan Chen Zixiang

- Alamat kertas: https://arxiv.org/pdf/2311.04
- .pdf ject alamat : https://uclaml.github.io/Rephrase-and-Respond
Pasukan penyelidik juga mencadangkan varian RaR yang dipanggil "Two-step RaR" untuk memanfaatkan sepenuhnya keupayaan model besar seperti GPT-4 untuk menyatakan semula masalah. Pendekatan ini mengikut dua langkah: pertama, untuk soalan yang diberikan, LLM Pengucapan Semula khusus digunakan untuk menjana soalan penguraian semula kedua, soalan asal dan soalan yang diutarakan semula digabungkan dan digunakan untuk menggesa LLM Bertindak balas untuk jawapan.
 Keputusan
Keputusan
 Para penyelidik menjalankan eksperimen pada tugas yang berbeza, dan keputusan menunjukkan bahawa kedua-dua RaR satu langkah dan RaR dua langkah boleh meningkatkan ketepatan jawapan GPT4 dengan berkesan Terutama sekali, RaR menunjukkan peningkatan ketara pada tugasan yang mungkin mencabar untuk GPT-4, malah menghampiri ketepatan 100% dalam beberapa kes. Pasukan penyelidik meringkaskan dua kesimpulan utama berikut:
Para penyelidik menjalankan eksperimen pada tugas yang berbeza, dan keputusan menunjukkan bahawa kedua-dua RaR satu langkah dan RaR dua langkah boleh meningkatkan ketepatan jawapan GPT4 dengan berkesan Terutama sekali, RaR menunjukkan peningkatan ketara pada tugasan yang mungkin mencabar untuk GPT-4, malah menghampiri ketepatan 100% dalam beberapa kes. Pasukan penyelidik meringkaskan dua kesimpulan utama berikut:
1 Nyatakan Semula dan Lanjutkan (RaR) menyediakan kaedah gesaan kotak hitam plug-and-play yang boleh meningkatkan prestasi LLM dengan berkesan pada pelbagai tugas.
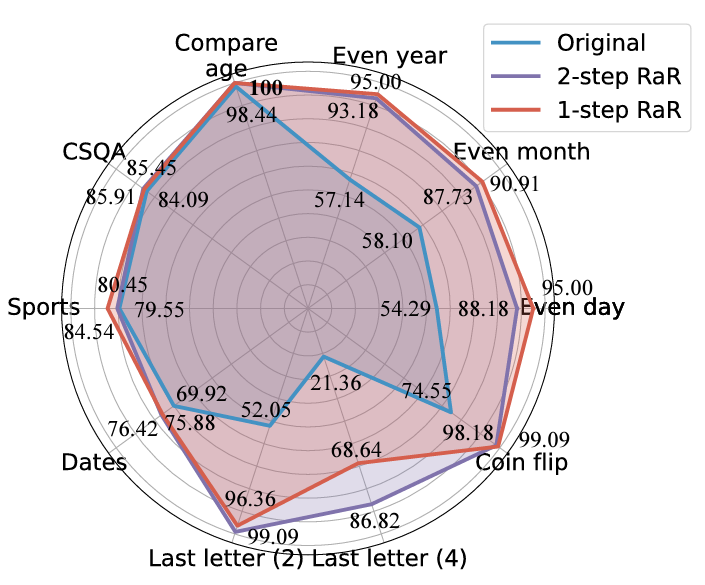
Para penyelidik menggunakan kaedah RaR Dua langkah untuk menjalankan penyelidikan untuk meneroka prestasi model yang berbeza seperti GPT-4, GPT-3.5 dan Vicuna-13b-v.15. Keputusan eksperimen menunjukkan bahawa untuk model dengan seni bina yang lebih kompleks dan keupayaan pemprosesan yang lebih kukuh, seperti GPT-4, kaedah RaR boleh meningkatkan ketepatan dan kecekapan masalah pemprosesan dengan ketara. Untuk model yang lebih mudah, seperti Vicuna, walaupun peningkatannya lebih kecil, ia masih menunjukkan keberkesanan strategi RaR. Berdasarkan ini, penyelidik meneliti lagi kualiti soalan selepas menceritakan semula model yang berbeza. Soalan pernyataan semula untuk model yang lebih kecil kadangkala boleh mengganggu niat soalan. Dan model lanjutan seperti GPT-4 menyediakan soalan pengulangan yang sepadan dengan niat manusia dan boleh meningkatkan jawapan model lain #Penemuan ini mendedahkan fenomena penting: terdapat perbezaan dalam kualiti dan keberkesanan soalan yang dilatih oleh tahap yang berbeza. model bahasa. Terutama untuk model lanjutan seperti GPT-4, masalah yang dinyatakan semula bukan sahaja memberikan mereka pemahaman yang lebih jelas tentang masalah itu, tetapi juga boleh berfungsi sebagai input yang berkesan untuk meningkatkan prestasi model lain yang lebih kecil.

Untuk memahami perbezaan antara RaR dan rantaian pemikiran (CoT) Para penyelidik membentangkan rumusan matematik mereka dan menggambarkan bagaimana RaR berbeza secara matematik daripada CoT dan bagaimana ia boleh digabungkan dengan mudah.
Sebelum mendalami cara meningkatkan keupayaan inferens model, kajian ini menunjukkan bahawa kualiti soalan harus dipertingkatkan. untuk memastikan Dapat menilai dengan betul keupayaan inferens model. Sebagai contoh, dalam masalah "flip syiling", didapati GPT-4 memahami "flip" sebagai tindakan melambung secara rawak, yang berbeza dengan niat manusia. Walaupun "mari kita fikir langkah demi langkah" digunakan untuk membimbing model dalam penaakulan, salah faham ini masih akan berterusan semasa proses inferens. Hanya selepas menjelaskan soalan, model bahasa besar menjawab soalan yang dimaksudkan ,Selain teks soalan, soalan dan jawapan , contoh untuk CoT beberapa pukulan juga ditulis oleh manusia. Ini menimbulkan persoalan: Bagaimanakah model bahasa besar (LLM) bertindak balas apabila contoh yang dibina secara buatan ini cacat? Kajian ini memberikan contoh yang menarik dan mendapati contoh CoT beberapa pukulan yang lemah boleh memberi kesan negatif kepada LLM. Mengambil tugas "Surat Akhir Sertai" sebagai contoh, contoh masalah yang digunakan sebelum ini menunjukkan kesan positif dalam meningkatkan prestasi model. Walau bagaimanapun, apabila logik segera berubah, seperti daripada mencari huruf terakhir kepada mencari huruf pertama, GPT-4 memberikan jawapan yang salah. Fenomena ini menyerlahkan sensitiviti model kepada contoh tiruan.
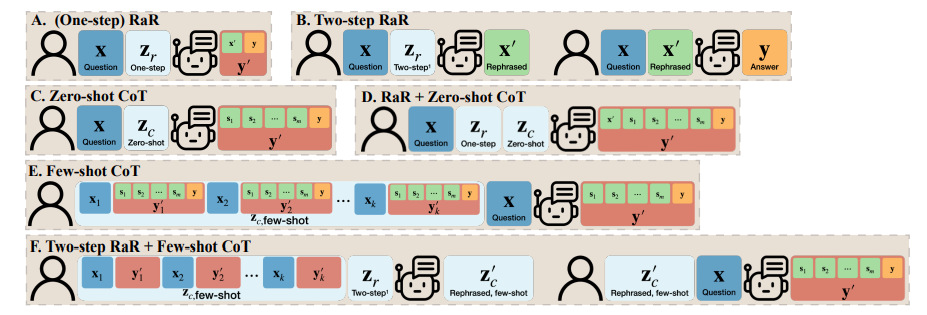
Para penyelidik mendapati bahawa menggunakan RaR, GPT-4 boleh membetulkan kelemahan logik dalam contoh yang diberikan, dengan itu menambah baik Kualiti dan keteguhan CoT

Model Bahasa Manusia dan Besar (LLM) mungkin salah faham dalam komunikasi: soalan yang kelihatan jelas kepada manusia mungkin difahami oleh model bahasa yang besar seperti soalan lain. Pasukan penyelidik UCLA menyelesaikan masalah ini dengan mencadangkan RaR, kaedah baru yang mendorong LLM untuk menyatakan semula dan menjelaskan soalan sebelum menjawabnya

Keberkesanan RaR Ini telah disahkan oleh penilaian percubaan pada beberapa set data penanda aras. Keputusan analisis lanjut menunjukkan bahawa kualiti masalah boleh dipertingkatkan dengan menyatakan semula masalah, dan kesan penambahbaikan ini boleh dipindahkan antara model yang berbeza
Untuk prospek masa depan, Adalah dijangka bahawa kaedah seperti RaR akan terus bertambah baik, dan penyepaduan dengan kaedah lain seperti CoT akan menyediakan cara yang lebih tepat dan cekap untuk berinteraksi antara manusia dan model bahasa yang besar, akhirnya memperluaskan sempadan penjelasan AI dan keupayaan penaakulan#🎜 🎜#
Atas ialah kandungan terperinci Biarkan model AI besar bertanya soalan secara autonomi: GPT-4 memecahkan halangan untuk bercakap dengan manusia dan menunjukkan tahap prestasi yang lebih tinggi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1359
1359
 52
52

 Bagaimana cara menukar saiz senarai bootstrap?
Apr 07, 2025 am 10:45 AM
Bagaimana cara menukar saiz senarai bootstrap?
Apr 07, 2025 am 10:45 AM
Saiz senarai bootstrap bergantung kepada saiz bekas yang mengandungi senarai, bukan senarai itu sendiri. Menggunakan sistem grid Bootstrap atau Flexbox boleh mengawal saiz bekas, dengan itu secara tidak langsung mengubah saiz item senarai.
 Bagaimana untuk melaksanakan penyiaran senarai bootstrap?
Apr 07, 2025 am 10:27 AM
Bagaimana untuk melaksanakan penyiaran senarai bootstrap?
Apr 07, 2025 am 10:27 AM
Senarai bersarang di Bootstrap memerlukan penggunaan sistem grid Bootstrap untuk mengawal gaya. Pertama, gunakan lapisan luar & lt; ul & gt; dan & lt; li & gt; Untuk membuat senarai, kemudian bungkus senarai lapisan dalaman dalam & lt; div class = & quot; row & gt; dan tambah & lt; kelas div = & quot; col-md-6 & quot; & gt; ke senarai lapisan dalaman untuk menentukan bahawa senarai lapisan dalaman menduduki separuh lebar baris. Dengan cara ini, senarai dalaman boleh mempunyai yang betul
 Bagaimana cara menambah ikon ke senarai bootstrap?
Apr 07, 2025 am 10:42 AM
Bagaimana cara menambah ikon ke senarai bootstrap?
Apr 07, 2025 am 10:42 AM
Cara Menambah Ikon ke Senarai Bootstrap: Secara langsung barangan ikon ke dalam item senarai & lt; li & gt;, menggunakan nama kelas yang disediakan oleh Perpustakaan Ikon (seperti Font Awesome). Gunakan kelas Bootstrap untuk menyelaraskan ikon dan teks (contohnya, D-Flex, Justify-Content-Between, Align-Items-Center). Gunakan komponen tag bootstrap (lencana) untuk memaparkan nombor atau status. Laraskan kedudukan ikon (arah flex: row-reverse;), mengawal gaya (gaya CSS). Ralat biasa: ikon tidak dipaparkan (tidak
 Kaedah apa yang digunakan untuk menukar rentetan ke dalam objek dalam vue.js?
Apr 07, 2025 pm 09:39 PM
Kaedah apa yang digunakan untuk menukar rentetan ke dalam objek dalam vue.js?
Apr 07, 2025 pm 09:39 PM
Apabila menukar rentetan ke objek dalam vue.js, json.parse () lebih disukai untuk rentetan json standard. Untuk rentetan JSON yang tidak standard, rentetan boleh diproses dengan menggunakan ungkapan biasa dan mengurangkan kaedah mengikut format atau url yang dikodkan. Pilih kaedah yang sesuai mengikut format rentetan dan perhatikan isu keselamatan dan pengekodan untuk mengelakkan pepijat.
 Apakah perubahan yang telah dibuat dengan gaya senarai Bootstrap 5?
Apr 07, 2025 am 11:09 AM
Apakah perubahan yang telah dibuat dengan gaya senarai Bootstrap 5?
Apr 07, 2025 am 11:09 AM
Perubahan gaya Bootstrap 5 adalah disebabkan oleh pengoptimuman terperinci dan peningkatan semantik, termasuk: margin lalai senarai yang tidak teratur dipermudahkan, dan kesan visual adalah bersih dan kemas; Gaya senarai menekankan semantik, meningkatkan kebolehcapaian dan penyelenggaraan.
 Cara Melihat Sistem Grid Bootstrap
Apr 07, 2025 am 09:48 AM
Cara Melihat Sistem Grid Bootstrap
Apr 07, 2025 am 09:48 AM
Sistem mesh Bootstrap adalah peraturan untuk membina susun atur responsif dengan cepat, yang terdiri daripada tiga kelas utama: kontena (kontena), baris (baris), dan col (lajur). Secara lalai, grid 12-kolumn disediakan, dan lebar setiap lajur boleh diselaraskan melalui kelas tambahan seperti Col-MD-, dengan itu mencapai pengoptimuman susun atur untuk saiz skrin yang berbeza. Dengan menggunakan kelas mengimbangi dan jejaring bersarang, fleksibiliti susun atur boleh dilanjutkan. Apabila menggunakan sistem grid, pastikan setiap elemen mempunyai struktur bersarang yang betul dan pertimbangkan pengoptimuman prestasi untuk meningkatkan kelajuan pemuatan halaman. Hanya dengan pemahaman dan amalan yang mendalam, kita dapat menguasai sistem grid bootstrap yang mahir.
 Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Cecair memproses 7 juta rekod dan membuat peta interaktif dengan teknologi geospatial. Artikel ini meneroka cara memproses lebih dari 7 juta rekod menggunakan Laravel dan MySQL dan mengubahnya menjadi visualisasi peta interaktif. Keperluan Projek Cabaran Awal: Ekstrak Wawasan berharga menggunakan 7 juta rekod dalam pangkalan data MySQL. Ramai orang mula -mula mempertimbangkan bahasa pengaturcaraan, tetapi mengabaikan pangkalan data itu sendiri: Bolehkah ia memenuhi keperluan? Adakah penghijrahan data atau pelarasan struktur diperlukan? Bolehkah MySQL menahan beban data yang besar? Analisis awal: Penapis utama dan sifat perlu dikenalpasti. Selepas analisis, didapati bahawa hanya beberapa atribut yang berkaitan dengan penyelesaiannya. Kami mengesahkan kemungkinan penapis dan menetapkan beberapa sekatan untuk mengoptimumkan carian. Carian Peta Berdasarkan Bandar
 Cara memusatkan gambar dalam bekas untuk bootstrap
Apr 07, 2025 am 09:12 AM
Cara memusatkan gambar dalam bekas untuk bootstrap
Apr 07, 2025 am 09:12 AM
Gambaran Keseluruhan: Terdapat banyak cara untuk memusatkan imej menggunakan Bootstrap. Kaedah Asas: Gunakan kelas MX-AUTO ke pusat secara mendatar. Gunakan kelas IMG-cecair untuk menyesuaikan diri dengan bekas induk. Gunakan kelas D-block untuk menetapkan imej ke elemen peringkat blok (pusat menegak). Kaedah Lanjutan: Susun atur Flexbox: Gunakan sifat-Center-Center-Center dan Align-Items-Center. Susun atur Grid: Gunakan Tempat-Item: Properti Pusat. Amalan terbaik: Elakkan bersarang dan gaya yang tidak perlu. Pilih kaedah terbaik untuk projek ini. Perhatikan pemeliharaan kod dan elakkan mengorbankan kualiti kod untuk meneruskan kegembiraan
