
 Peranti teknologi
AI
Penyelidikan model besar Google telah mencetuskan kontroversi sengit: keupayaan generalisasi di luar data latihan telah dipersoalkan, dan netizen berkata bahawa singulariti AGI mungkin ditangguhkan.
Peranti teknologi
AI
Penyelidikan model besar Google telah mencetuskan kontroversi sengit: keupayaan generalisasi di luar data latihan telah dipersoalkan, dan netizen berkata bahawa singulariti AGI mungkin ditangguhkan.
Penyelidikan model besar Google telah mencetuskan kontroversi sengit: keupayaan generalisasi di luar data latihan telah dipersoalkan, dan netizen berkata bahawa singulariti AGI mungkin ditangguhkan.

Keputusan baharu yang ditemui baru-baru ini oleh Google DeepMind telah menyebabkan kontroversi meluas dalam medan Transformer:
Keupayaan generalisasinya tidak boleh diperluaskan kepada kandungan di luar data latihan.
Kesimpulan ini belum lagi disahkan, tetapi ia telah membimbangkan banyak nama besar Contohnya, Francois Chollet, bapa Keras, berkata bahawa jika berita itu Benar, ia akan menjadi perkara besar dalam dunia model besar.

Google Transformer ialah infrastruktur di sebalik model besar hari ini, dan "T" dalam GPT yang kita kenali merujuk kepadanya.
Serangkaian model besar menunjukkan keupayaan pembelajaran kontekstual yang kukuh dan boleh mempelajari contoh dengan cepat dan menyelesaikan tugasan baharu.
Tetapi kini, penyelidik juga dari Google nampaknya telah menunjukkan kelemahannya yang maut - di luar data latihan, iaitu pengetahuan manusia yang sedia ada, ia tidak berkuasa.
Untuk sementara waktu, ramai pengamal percaya bahawa AGI telah tidak dapat dicapai lagi.
Beberapa netizen menegaskan bahawa terdapat beberapa butiran penting yang telah diabaikan dalam kertas, seperti eksperimen hanya melibatkan skala GPT-2 , dan data latihan tidak mencukupi Kaya
Semakin masa berlalu, lebih ramai netizen yang mengkaji kertas ini dengan teliti menunjukkan bahawa tidak ada yang salah dengan kesimpulan penyelidikan itu sendiri, tetapi orang berdasarkan Ini adalah tafsiran yang berlebihan.

Selepas kertas itu mencetuskan perbincangan hangat di kalangan netizen, salah seorang penulis turut membuat dua penjelasan secara terbuka:
Pertama , Percubaan menggunakan Transformer mudah, yang bukan model "besar" mahupun model bahasa; 🎜#新TYPE
Task
Sejak itu, seorang lagi netizen mengulangi percubaan ini dalam Colab, tetapi mendapat keputusan yang sama sekali berbeza .
 Fungsi baharu hampir tidak dapat diramalkan
Fungsi baharu hampir tidak dapat diramalkan
Dalam eksperimen ini, penulis menggunakan rangka kerja pembelajaran mesin berasaskan Jax untuk melatih model Transformer dengan skala yang hampir dengan GPT-2, yang hanya mengandungi bahagian Penyahkod
Model ini mengandungi 12 lapisan, 8 kepala perhatian, dimensi ruang benam ialah 256, dan bilangan parameter adalah kira-kira 9.5 juta
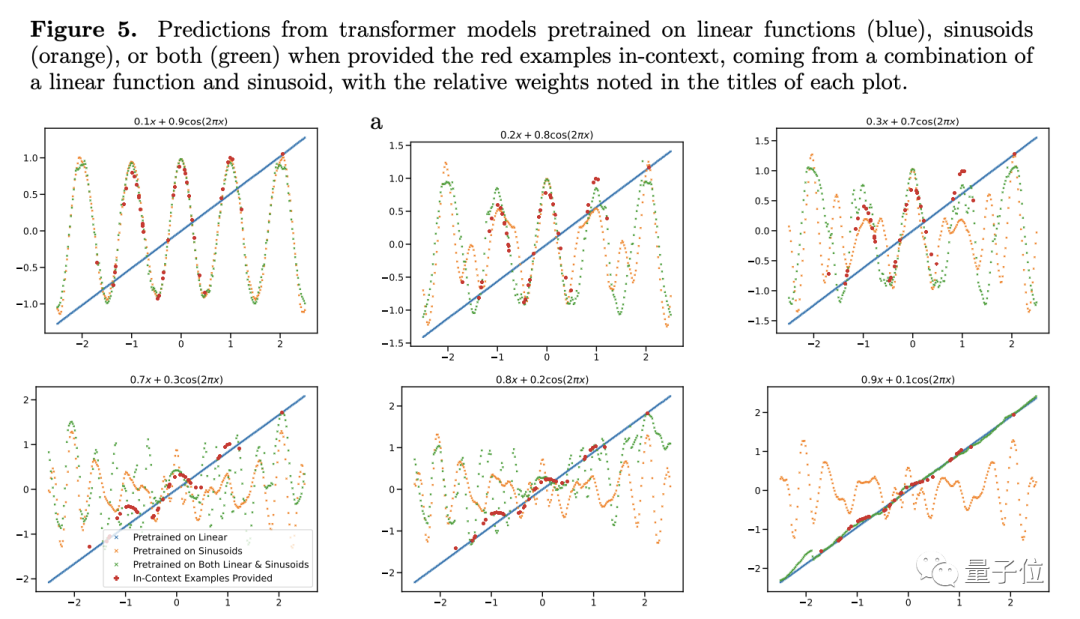
Untuk menguji keupayaan generalisasi, pengarang memilih fungsi sebagai objek ujian. Mereka memasukkan fungsi linear dan fungsi sinus ke dalam model sebagai data latihan
Kedua-dua fungsi ini diketahui oleh model pada masa ini, dan hasil yang diramalkan secara semula jadi sangat baik, tetapi apabila penyelidik meletakkan Masalah linear timbul apabila gabungan cembung bagi fungsi dan fungsi sinus dilakukan.
Gabungan cembung tidak begitu misteri Pengarang membina fungsi bentuk f(x)=a·kx+(1-a)sin(x), yang pada pendapat kami hanyalah dua Fungsi. hanya tambah secara berkadar.
Sebab mengapa kita fikir ini adalah kerana otak kita mempunyai keupayaan generalisasi ini, tetapi model berskala besar adalah berbeza
Untuk model yang hanya mempelajari fungsi linear dan sinus Untuk ini fungsi baru, ramalan Transformer hampir tiada ketepatan (lihat Rajah 4c), jadi penulis percaya bahawa model tidak mempunyai generalisasi pada fungsi Ability
Untuk mengesahkan lagi kesimpulannya, penulis melaraskan berat fungsi linear atau sinus, tetapi walaupun begitu, prestasi ramalan Transformer tidak berubah dengan ketara.
Terdapat satu pengecualian - apabila berat salah satu item menghampiri 1, hasil ramalan model lebih konsisten dengan keadaan sebenar.
Jika beratnya 1, ini bermakna fungsi baru yang tidak dikenali secara langsung menjadi fungsi yang telah dilihat semasa latihan. Data seperti ini jelas tidak membantu untuk keupayaan generalisasi model#🎜🎜 ##🎜 🎜#
 Eksperimen lanjut juga menunjukkan Transformer bukan sahaja sangat sensitif kepada jenis fungsi, malah jenis fungsi yang sama mungkin menjadi keadaan yang tidak biasa.
Eksperimen lanjut juga menunjukkan Transformer bukan sahaja sangat sensitif kepada jenis fungsi, malah jenis fungsi yang sama mungkin menjadi keadaan yang tidak biasa.
Pengkaji mendapati bahawa apabila menukar frekuensi fungsi sinus, walaupun model fungsi mudah, keputusan ramalan akan kelihatan berubah
Hanya apabila frekuensi hampir dengan itu dalam Fungsi data latihan, model boleh memberikan ramalan yang lebih tepat Apabila frekuensi terlalu tinggi atau terlalu rendah, keputusan ramalan mempunyai penyelewengan yang serius...
#. 🎜🎜# Berdasarkan perkara ini, penulis percaya bahawa selagi syaratnya berbeza sedikit, model besar tidak akan tahu bagaimana untuk melakukannya. Bukankah ini bermakna keupayaan generalisasi adalah lemah? 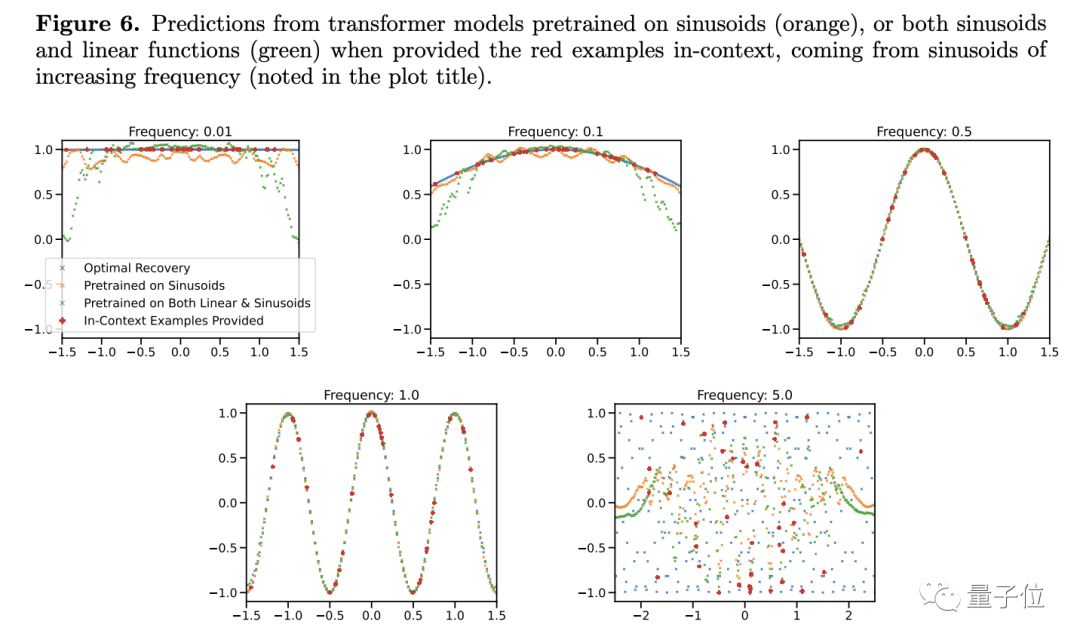
 Berdasarkan kandungan komprehensif keseluruhan artikel, kesimpulan CEO Quora dalam artikel ini adalah sangat sempit dan hanya boleh diwujudkan apabila banyak andaian adalah benar
Berdasarkan kandungan komprehensif keseluruhan artikel, kesimpulan CEO Quora dalam artikel ini adalah sangat sempit dan hanya boleh diwujudkan apabila banyak andaian adalah benar
 Menurut kajian terdahulu, model Transformer tidak boleh membuat generalisasi hanya apabila berhadapan dengan kandungan yang berbeza dengan ketara daripada data pra-latihan. Malah, keupayaan generalisasi model besar biasanya dinilai oleh kepelbagaian dan kerumitan tugas
Menurut kajian terdahulu, model Transformer tidak boleh membuat generalisasi hanya apabila berhadapan dengan kandungan yang berbeza dengan ketara daripada data pra-latihan. Malah, keupayaan generalisasi model besar biasanya dinilai oleh kepelbagaian dan kerumitan tugas
 Tetapi walaupun kita benar-benar kurang keupayaan untuk membuat generalisasi, apa yang boleh kita lakukan?
Tetapi walaupun kita benar-benar kurang keupayaan untuk membuat generalisasi, apa yang boleh kita lakukan?
Saintis AI NVIDIA Jim Fan berkata bahawa fenomena ini sebenarnya tidak menghairankan, kerana Transformer
bukan ubat penawar di tempat pertamamodel besar berprestasi baik kerana#🎜 🎜#. Data latihan adalah perkara yang kami pentingkan
.Jim seterusnya menambah bahawa ini seperti berkata, gunakan 100 bilion foto kucing dan anjing untuk melatih model visual, dan kemudian biarkan model mengenal pasti Hidup kapal terbang, saya sedar, wow, saya benar-benar tidak mengenali dia.

Apabila manusia menghadapi beberapa tugas yang tidak diketahui, bukan sahaja model berskala besar mungkin tidak dapat mencari penyelesaian. Adakah ini juga membayangkan bahawa manusia kekurangan keupayaan generalisasi?

Oleh itu, dalam proses berorientasikan matlamat, sama ada model besar atau manusia, matlamat utama adalah untuk menyelesaikan masalah, dan generalisasi hanyalah sarana
Tukar ungkapan ini kepada bahasa Cina Memandangkan keupayaan generalisasi tidak mencukupi, kemudian latih ia sehingga tiada data selain daripada sampel latihan
Jadi, apa pendapat anda tentang penyelidikan ini?
Alamat kertas: https://arxiv.org/abs/2311.00871
Atas ialah kandungan terperinci Penyelidikan model besar Google telah mencetuskan kontroversi sengit: keupayaan generalisasi di luar data latihan telah dipersoalkan, dan netizen berkata bahawa singulariti AGI mungkin ditangguhkan.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Cara Mengulas DeepSeek
Feb 19, 2025 pm 05:42 PM
Cara Mengulas DeepSeek
Feb 19, 2025 pm 05:42 PM
DeepSeek adalah alat pengambilan maklumat yang kuat. .
 Cara Mencari DeepSeek
Feb 19, 2025 pm 05:39 PM
Cara Mencari DeepSeek
Feb 19, 2025 pm 05:39 PM
DeepSeek adalah enjin carian proprietari yang hanya mencari dalam pangkalan data atau sistem tertentu, lebih cepat dan lebih tepat. Apabila menggunakannya, pengguna dinasihatkan untuk membaca dokumen itu, cuba strategi carian yang berbeza, dapatkan bantuan dan maklum balas mengenai pengalaman pengguna untuk memanfaatkan kelebihan mereka.
 Sesame Open Door Exchange Web Pautan Pautan Gerbang Perdagangan Laman Web Pendaftaran Terkini
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange Web Pautan Pautan Gerbang Perdagangan Laman Web Pendaftaran Terkini
Feb 28, 2025 am 11:06 AM
Artikel ini memperkenalkan proses pendaftaran versi web Web Open Exchange (GATE.IO) dan aplikasi Perdagangan Gate secara terperinci. Sama ada pendaftaran web atau pendaftaran aplikasi, anda perlu melawat laman web rasmi atau App Store untuk memuat turun aplikasi tulen, kemudian isi nama pengguna, kata laluan, e -mel, nombor telefon bimbit dan maklumat lain, dan lengkap e -mel atau pengesahan telefon bimbit.
 Mengapa pautan Bybit Exchange tidak dimuat turun dan dipasang secara langsung?
Feb 21, 2025 pm 10:57 PM
Mengapa pautan Bybit Exchange tidak dimuat turun dan dipasang secara langsung?
Feb 21, 2025 pm 10:57 PM
Mengapa pautan Bybit Exchange tidak dimuat turun dan dipasang secara langsung? Bybit adalah pertukaran cryptocurrency yang menyediakan perkhidmatan perdagangan kepada pengguna. Aplikasi mudah alih Exchange tidak boleh dimuat turun terus melalui AppStore atau GooglePlay untuk sebab -sebab berikut: 1. Aplikasi pertukaran cryptocurrency sering tidak memenuhi keperluan ini kerana ia melibatkan perkhidmatan kewangan dan memerlukan peraturan dan standard keselamatan tertentu. 2. Undang -undang dan Peraturan Pematuhan di banyak negara, aktiviti yang berkaitan dengan urus niaga cryptocurrency dikawal atau terhad. Untuk mematuhi peraturan ini, aplikasi bybit hanya boleh digunakan melalui laman web rasmi atau saluran yang diberi kuasa lain
 Platform Perdagangan Pintu Terbuka Sesame Muat turun Versi Mudah Alih Platform Perdagangan Platform Perdagangan Alamat Muat Turun
Feb 28, 2025 am 10:51 AM
Platform Perdagangan Pintu Terbuka Sesame Muat turun Versi Mudah Alih Platform Perdagangan Platform Perdagangan Alamat Muat Turun
Feb 28, 2025 am 10:51 AM
Adalah penting untuk memilih saluran rasmi untuk memuat turun aplikasi dan memastikan keselamatan akaun anda.
 Top 10 Disyorkan untuk App Perdagangan Aset Digital Crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 Disyorkan untuk App Perdagangan Aset Digital Crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Artikel ini mencadangkan sepuluh platform perdagangan cryptocurrency teratas yang memberi perhatian kepada, termasuk Binance, OKX, Gate.io, Bitflyer, Kucoin, Bybit, Coinbase Pro, Kraken, BYDFI dan Xbit yang desentralisasi. Platform ini mempunyai kelebihan mereka sendiri dari segi kuantiti mata wang transaksi, jenis urus niaga, keselamatan, pematuhan, dan ciri khas. Memilih platform yang sesuai memerlukan pertimbangan yang komprehensif berdasarkan pengalaman perdagangan anda sendiri, toleransi risiko dan keutamaan pelaburan. Semoga artikel ini membantu anda mencari saman terbaik untuk diri sendiri
 Portal Log Masuk Versi Rasmi Binance Binance
Feb 21, 2025 pm 05:42 PM
Portal Log Masuk Versi Rasmi Binance Binance
Feb 21, 2025 pm 05:42 PM
Untuk mengakses versi Login Laman Web Binance yang terkini, ikuti langkah mudah ini. Pergi ke laman web rasmi dan klik butang "Login" di sudut kanan atas. Pilih kaedah log masuk anda yang sedia ada. Masukkan nombor mudah alih berdaftar atau e -mel dan kata laluan anda dan pengesahan lengkap (seperti kod pengesahan mudah alih atau Google Authenticator). Selepas pengesahan yang berjaya, anda boleh mengakses Portal Log masuk laman web rasmi Binance.
 Alamat muat turun terbaru Bitget pada tahun 2025: Langkah -langkah untuk mendapatkan aplikasi rasmi
Feb 25, 2025 pm 02:54 PM
Alamat muat turun terbaru Bitget pada tahun 2025: Langkah -langkah untuk mendapatkan aplikasi rasmi
Feb 25, 2025 pm 02:54 PM
Panduan ini menyediakan langkah muat turun dan pemasangan terperinci untuk aplikasi Bitget Exchange rasmi, sesuai untuk sistem Android dan iOS. Panduan ini mengintegrasikan maklumat dari pelbagai sumber yang berwibawa, termasuk laman web rasmi, App Store, dan Google Play, dan menekankan pertimbangan semasa muat turun dan pengurusan akaun. Pengguna boleh memuat turun aplikasinya dari saluran rasmi, termasuk App Store, muat turun APK laman web rasmi dan melompat laman web rasmi, dan lengkap pendaftaran, pengesahan identiti dan tetapan keselamatan. Di samping itu, panduan itu merangkumi soalan dan pertimbangan yang sering ditanya, seperti
