

Dalam pembelajaran mesin, istilah ensemble merujuk kepada menggabungkan berbilang model secara selari, ideanya adalah untuk menggunakan kebijaksanaan orang ramai untuk membentuk konsensus yang lebih baik mengenai jawapan akhir yang diberikan.

Dalam bidang pembelajaran yang diselia, kaedah ini telah dikaji dan diterapkan secara meluas, terutamanya dalam masalah klasifikasi dengan algoritma yang sangat berjaya seperti RandomForest. Sistem undian/pewajaran sering digunakan untuk menggabungkan output setiap model individu menjadi output akhir yang lebih mantap dan konsisten
Dalam dunia pembelajaran tanpa pengawasan, tugas ini menjadi lebih sukar. Pertama, kerana ia merangkumi cabaran bidang itu sendiri, kami tidak mempunyai pengetahuan awal tentang data untuk membandingkan diri kami dengan mana-mana sasaran. Kedua, kerana mencari cara yang sesuai untuk menggabungkan maklumat daripada semua model masih menjadi masalah, dan tidak ada konsensus tentang cara melakukan ini.
Dalam artikel ini, kita membincangkan pendekatan terbaik mengenai topik ini, iaitu pengelompokan matriks persamaan.
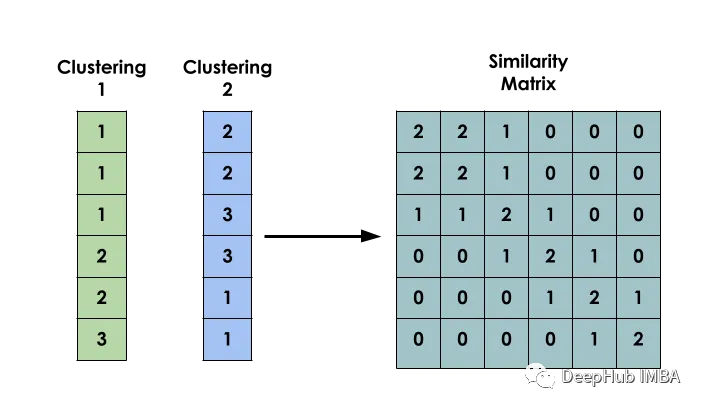
Idea utama kaedah ini ialah: diberikan set data X, buat matriks S supaya Si mewakili persamaan antara xi dan xj. Matriks ini dibina berdasarkan hasil pengelompokan beberapa model yang berbeza.
Mencipta matriks kejadian bersama binari antara input ialah langkah pertama dalam membina model

Ia digunakan untuk menunjukkan sama ada dua input i dan j tergolong dalam kelompok yang sama.
import numpy as np from scipy import sparse def build_binary_matrix( clabels ): data_len = len(clabels) matrix=np.zeros((data_len,data_len))for i in range(data_len):matrix[i,:] = clabels == clabels[i]return matrix labels = np.array( [1,1,1,2,3,3,2,4] ) build_binary_matrix(labels)
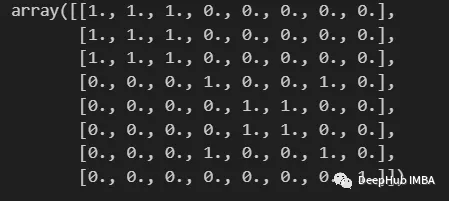
Kami telah membina fungsi untuk menduakan kelompok kami, dan kini kami boleh memasuki peringkat membina matriks persamaan.
Kami memperkenalkan kaedah biasa di sini, yang hanya melibatkan pengiraan nilai purata antara M matriks kejadian bersama yang dijana oleh M model berbeza. Kami mentakrifkannya sebagai:

Apabila item jatuh dalam kelompok yang sama, nilai persamaannya akan menghampiri 1, dan apabila item jatuh dalam kumpulan yang berbeza, nilai persamaannya akan menghampiri 0
Kami akan membina persamaan matriks berdasarkan label yang dicipta oleh model K-Means. Dijalankan menggunakan set data MNIST. Untuk kesederhanaan dan kecekapan, kami hanya akan menggunakan 10,000 imej yang dikurangkan PCA.
from sklearn.datasets import fetch_openml from sklearn.decomposition import PCA from sklearn.cluster import MiniBatchKMeans, KMeans from sklearn.model_selection import train_test_split mnist = fetch_openml('mnist_784') X = mnist.data y = mnist.target X, _, y, _ = train_test_split(X,y, train_size=10000, stratify=y, random_state=42 ) pca = PCA(n_components=0.99) X_pca = pca.fit_transform(X)Untuk membolehkan kepelbagaian antara model, setiap model dibuat instantiated dengan bilangan kelompok rawak.
NUM_MODELS = 500 MIN_N_CLUSTERS = 2 MAX_N_CLUSTERS = 300 np.random.seed(214) model_sizes = np.random.randint(MIN_N_CLUSTERS, MAX_N_CLUSTERS+1, size=NUM_MODELS) clt_models = [KMeans(n_clusters=i, n_init=4, random_state=214) for i in model_sizes] for i, model in enumerate(clt_models):print( f"Fitting - {i+1}/{NUM_MODELS}" )model.fit(X_pca)Fungsi berikut adalah untuk mencipta matriks persamaan
def build_similarity_matrix( models_labels ):n_runs, n_data = models_labels.shape[0], models_labels.shape[1] sim_matrix = np.zeros( (n_data, n_data) ) for i in range(n_runs):sim_matrix += build_binary_matrix( models_labels[i,:] ) sim_matrix = sim_matrix/n_runs return sim_matrix
Panggil fungsi ini:
models_labels = np.array([ model.labels_ for model in clt_models ]) sim_matrix = build_similarity_matrix(models_labels)
Keputusan akhir adalah seperti berikut:
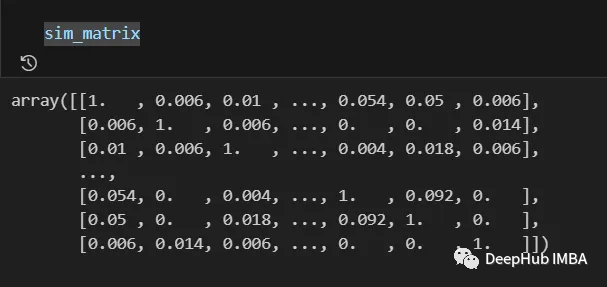
Maklumat dari matriks persamaan masih boleh diproses selepas proses terakhir , seperti menggunakan logaritma, polinomial Tunggu transformasi.
Dalam kes kami, kami akan mengekalkan makna asal tidak berubah dan menulis semula
Pos_sim_matrix = sim_matrix
Matriks kesamaan ialah cara untuk mewakili pengetahuan yang dibina oleh kerjasama semua model pengelompokan.
Kita boleh menggunakannya untuk melihat secara visual entri yang lebih berkemungkinan tergolong dalam kelompok yang sama dan yang tidak. Walau bagaimanapun, maklumat ini masih perlu ditukar kepada kelompok sebenar
Ini dilakukan dengan menggunakan algoritma pengelompokan yang boleh menerima matriks persamaan sebagai parameter. Di sini kami menggunakan SpectralClustering.
from sklearn.cluster import SpectralClustering spec_clt = SpectralClustering(n_clusters=10, affinity='precomputed',n_init=5, random_state=214) final_labels = spec_clt.fit_predict(pos_sim_matrix)
Jom bandingkan dengan KMeans untuk mengesahkan sama ada kaedah kami berkesan.
Kami akan menggunakan penunjuk NMI, ARI, ketulenan kluster dan ketulenan kelas untuk menilai model KMeans standard dan membandingkan dengan model ensemble kami. Selain itu, kami akan merancang matriks kontingensi untuk menggambarkan kategori mana yang tergolong dalam setiap kelompok
from seaborn import heatmap import matplotlib.pyplot as plt def data_contingency_matrix(true_labels, pred_labels): fig, (ax) = plt.subplots(1, 1, figsize=(8,8)) n_clusters = len(np.unique(pred_labels))n_classes = len(np.unique(true_labels))label_names = np.unique(true_labels)label_names.sort() contingency_matrix = np.zeros( (n_classes, n_clusters) ) for i, true_label in enumerate(label_names):for j in range(n_clusters):contingency_matrix[i, j] = np.sum(np.logical_and(pred_labels==j, true_labels==true_label)) heatmap(contingency_matrix.astype(int), ax=ax,annot=True, annot_kws={"fontsize":14}, fmt='d') ax.set_xlabel("Clusters", fontsize=18)ax.set_xticks( [i+0.5 for i in range(n_clusters)] )ax.set_xticklabels([i for i in range(n_clusters)], fontsize=14) ax.set_ylabel("Original classes", fontsize=18)ax.set_yticks( [i+0.5 for i in range(n_classes)] )ax.set_yticklabels(label_names, fontsize=14, va="center") ax.set_title("Contingency Matrix\n", ha='center', fontsize=20)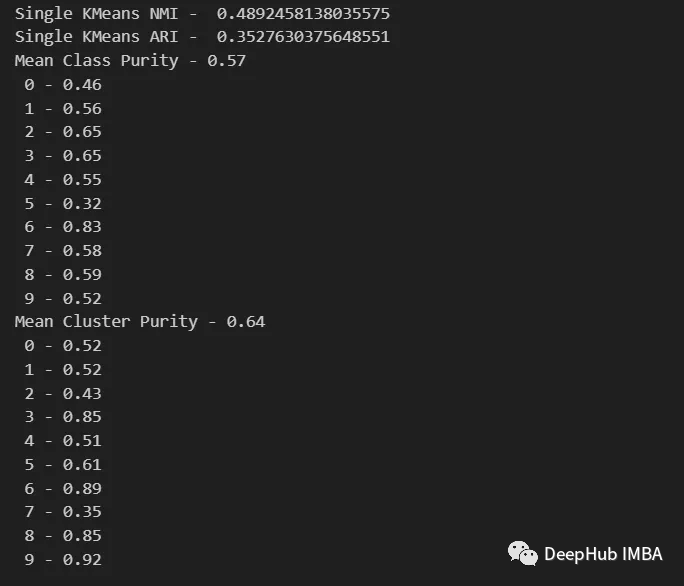
from sklearn.metrics import normalized_mutual_info_score, adjusted_rand_score def purity( true_labels, pred_labels ): n_clusters = len(np.unique(pred_labels))n_classes = len(np.unique(true_labels))label_names = np.unique(true_labels) purity_vector = np.zeros( (n_classes) )contingency_matrix = np.zeros( (n_classes, n_clusters) ) for i, true_label in enumerate(label_names):for j in range(n_clusters):contingency_matrix[i, j] = np.sum(np.logical_and(pred_labels==j, true_labels==true_label)) purity_vector = np.max(contingency_matrix, axis=1)/np.sum(contingency_matrix, axis=1) print( f"Mean Class Purity - {np.mean(purity_vector):.2f}" ) for i, true_label in enumerate(label_names):print( f" {true_label} - {purity_vector[i]:.2f}" ) cluster_purity_vector = np.zeros( (n_clusters) )cluster_purity_vector = np.max(contingency_matrix, axis=0)/np.sum(contingency_matrix, axis=0) print( f"Mean Cluster Purity - {np.mean(cluster_purity_vector):.2f}" ) for i in range(n_clusters):print( f" {i} - {cluster_purity_vector[i]:.2f}" ) kmeans_model = KMeans(10, n_init=50, random_state=214) km_labels = kmeans_model.fit_predict(X_pca) data_contingency_matrix(y, km_labels) print( "Single KMeans NMI - ", normalized_mutual_info_score(y, km_labels) ) print( "Single KMeans ARI - ", adjusted_rand_score(y, km_labels) ) purity(y, km_labels)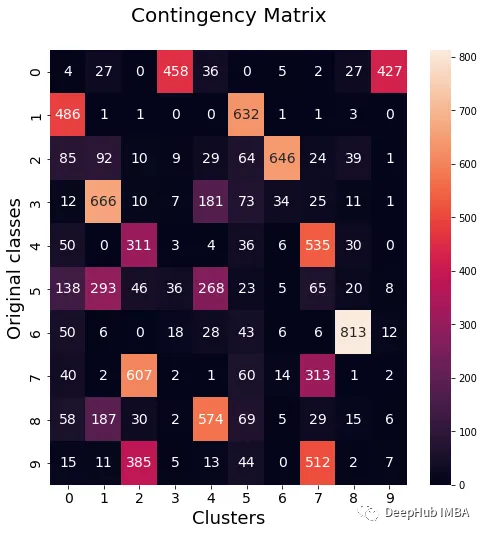
data_contingency_matrix(y, final_labels) print( "Ensamble NMI - ", normalized_mutual_info_score(y, final_labels) ) print( "Ensamble ARI - ", adjusted_rand_score(y, final_labels) ) purity(y, final_labels)
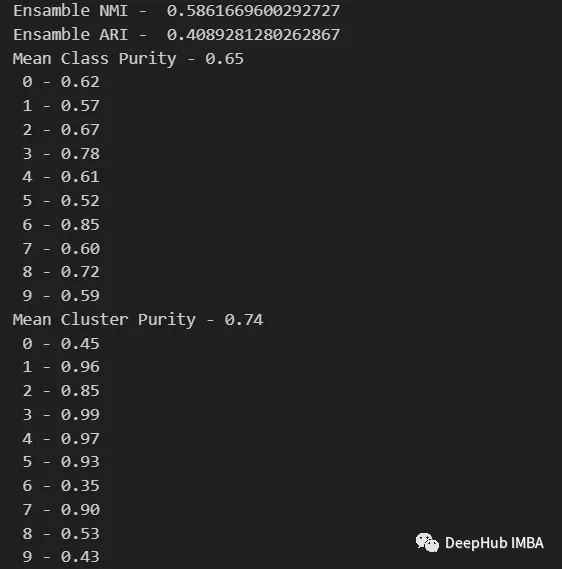
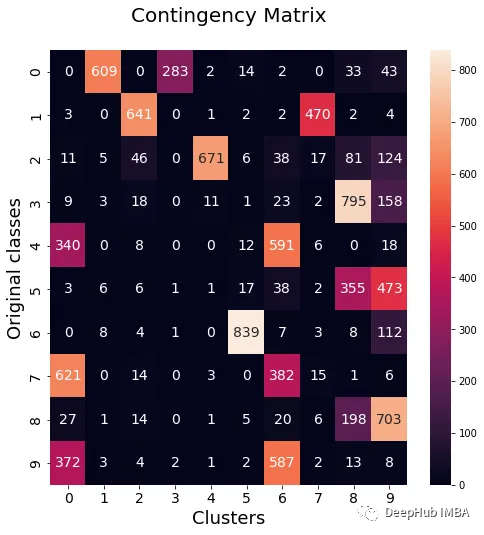
Dengan memerhatikan nilai-nilai di atas, jelas dapat dilihat bahawa kaedah Ensemble dapat meningkatkan kualiti pengelompokan dengan berkesan. Pada masa yang sama, tingkah laku yang lebih konsisten juga boleh diperhatikan dalam matriks kontingensi, dengan kategori pengedaran yang lebih baik dan kurang "bising"
Atas ialah kandungan terperinci Kaedah ensemble untuk pembelajaran tanpa pengawasan: pengelompokan matriks persamaan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 python mengkonfigurasi pembolehubah persekitaran
python mengkonfigurasi pembolehubah persekitaran
 Perbezaan antara ms office dan wps office
Perbezaan antara ms office dan wps office
 Bagaimana untuk menukar phpmyadmin kepada bahasa Cina
Bagaimana untuk menukar phpmyadmin kepada bahasa Cina
 Bagaimana untuk melaksanakan teknologi kontena docker di java
Bagaimana untuk melaksanakan teknologi kontena docker di java
 Bagaimana untuk memasukkan BIOS pada thinkpad
Bagaimana untuk memasukkan BIOS pada thinkpad
 Pengenalan kepada fungsi input dalam bahasa c
Pengenalan kepada fungsi input dalam bahasa c
 Pemacu kad bunyi komputer riba HP
Pemacu kad bunyi komputer riba HP
 Penggunaan fungsi instr
Penggunaan fungsi instr








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



