
 Peranti teknologi
AI
GPT-4 didedahkan sebagai menipu! LeCun meminta agar berhati-hati apabila menguji pada set latihan, kekeliruan pesanan chihuahua atau muffin membawa kepada kesilapan
Peranti teknologi
AI
GPT-4 didedahkan sebagai menipu! LeCun meminta agar berhati-hati apabila menguji pada set latihan, kekeliruan pesanan chihuahua atau muffin membawa kepada kesilapan
GPT-4 didedahkan sebagai menipu! LeCun meminta agar berhati-hati apabila menguji pada set latihan, kekeliruan pesanan chihuahua atau muffin membawa kepada kesilapan

GPT-4 menyelesaikan meme Internet terkenal "Chihuahua atau blueberry waffle", yang pernah memukau ramai orang.
Namun, kini ia dituduh "menipu"! .
Versi terkini GPT-4 terkenal dengan ciri semua-dalam-satunya. Walau bagaimanapun, yang menghairankan, ia melakukan kesilapan dalam bilangan imej yang dikenalinya, malah Chihuahua, yang pada asalnya dikenali dengan betul, juga mempunyai ralat pengecaman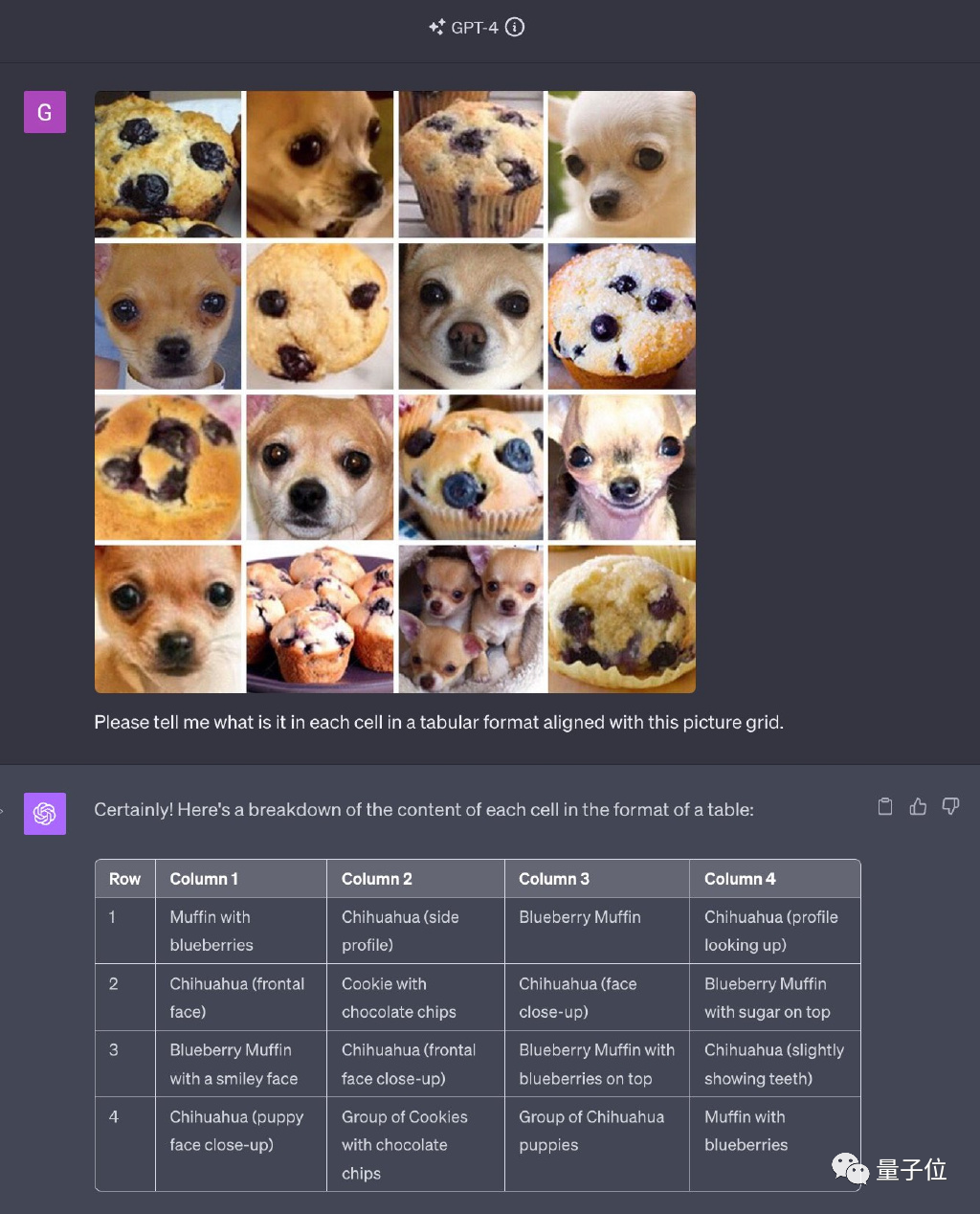
Sebab mengapa GPT-4 berprestasi dengan baik pada asalnya imej adalah Apa?
Menurut spekulasi Penolong Profesor UCSC Xin Eric Wang, alasan untuk menjalankan ujian ini adalah kerana imej asal di Internet terlalu popular. Dia percaya bahawa GPT-4 telah menemui jawapan asal berkali-kali semasa proses latihan dan berjaya menghafalnya 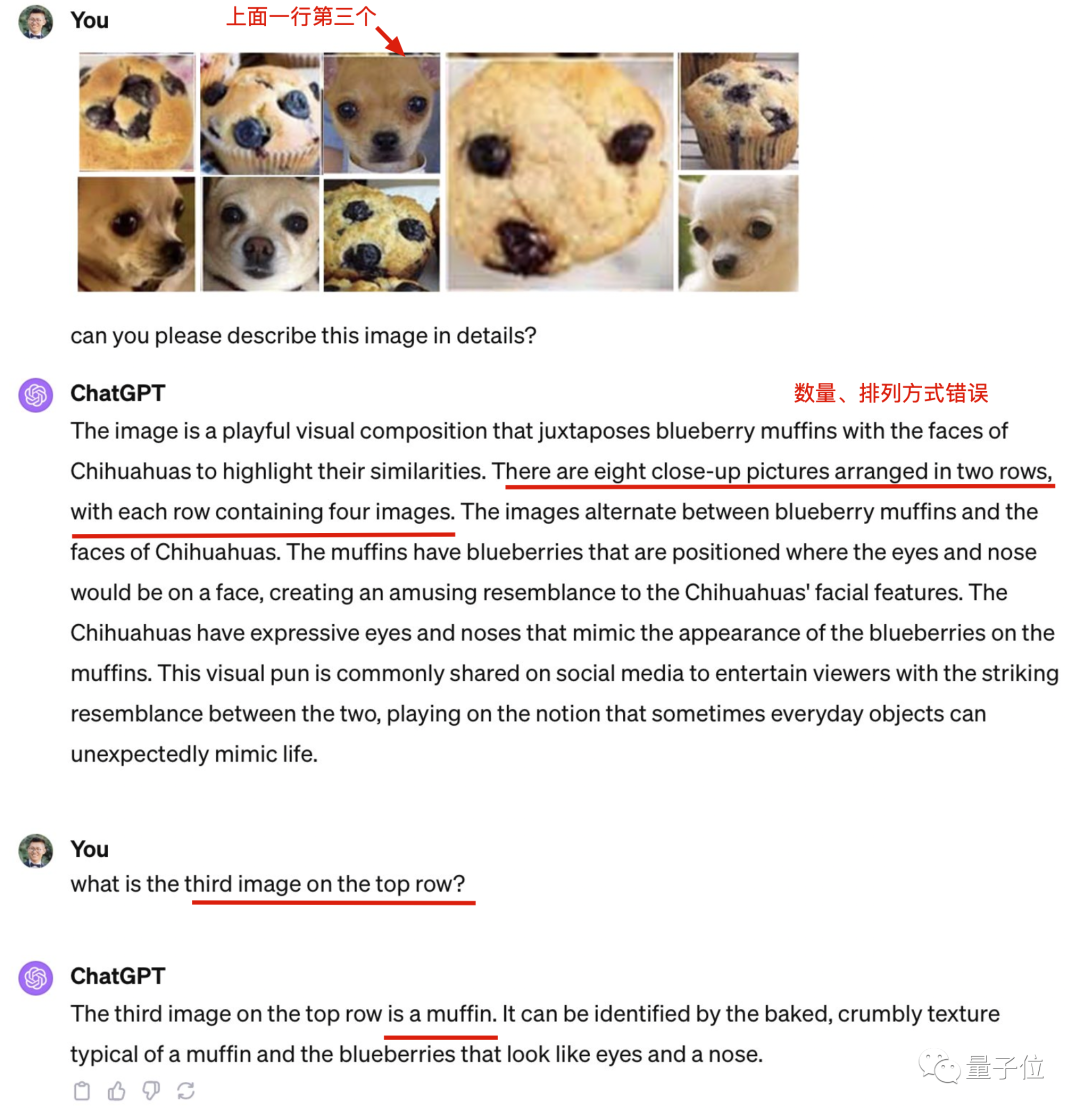 LeCun, salah seorang daripada tiga pemenang Anugerah Turing, turut memberi perhatian kepada perkara ini dan berkata:
LeCun, salah seorang daripada tiga pemenang Anugerah Turing, turut memberi perhatian kepada perkara ini dan berkata:
Berhati-hati dengan latihan set ujian.
Picturesteddy dan ayam goreng tidak dapat dibezakan
bagaimana popular adalah gambar asal? muncul berkali-kali dalam topik berkaitan Penyelidikan tesis sedang berjalan. 
Memandangkan aspek keupayaan GPT-4 yang mana terhad, ramai netizen mencadangkan rancangan ujian mereka sendiri, tanpa mengira kesan imej asal
Untuk menolak sama ada susunan itu terlalu rumit dan mempunyai apa-apa kesan, sesetengah orang mengubah suainya kepada yang mudah Susunan 3x3 juga mengakui banyak kesilapan. 
Gambar Seseorang mengasingkan beberapa gambar dan menghantarnya ke GPT-4 secara individu, dan mendapat kadar ketepatan 5/5. . " dan "Fikirkan langkah demi langkah" ialah dua petua utama dan dapatkan hasil yang betul
Seseorang mengasingkan beberapa gambar dan menghantarnya ke GPT-4 secara individu, dan mendapat kadar ketepatan 5/5. . " dan "Fikirkan langkah demi langkah" ialah dua petua utama dan dapatkan hasil yang betul
 Gambar
Gambar
GPT-4 perkataan dalam jawapan "Ini adalah contoh permainan kata visual atau meme terkenal", Ia juga terdedah bahawa imej asal mungkin wujud dalam data latihan. Diungkapkan semula seperti berikut: Walau bagaimanapun, GPT-4 digunakan dalam jawapannya: "Ini adalah contoh permainan kata visual atau meme terkenal", yang juga mendedahkan bahawa imej asal mungkin wujud dalam data latihan
 imej
imej
Akhirnya, seseorang juga menguji ujian "teddy or fried chicken" yang sering muncul bersama, dan mendapati GPT-4 tidak dapat membezakannya dengan baik.
 Gambar
Gambar
"Blueberry or chocolate bean" ni terlalu banyak...
 Picture
Picture
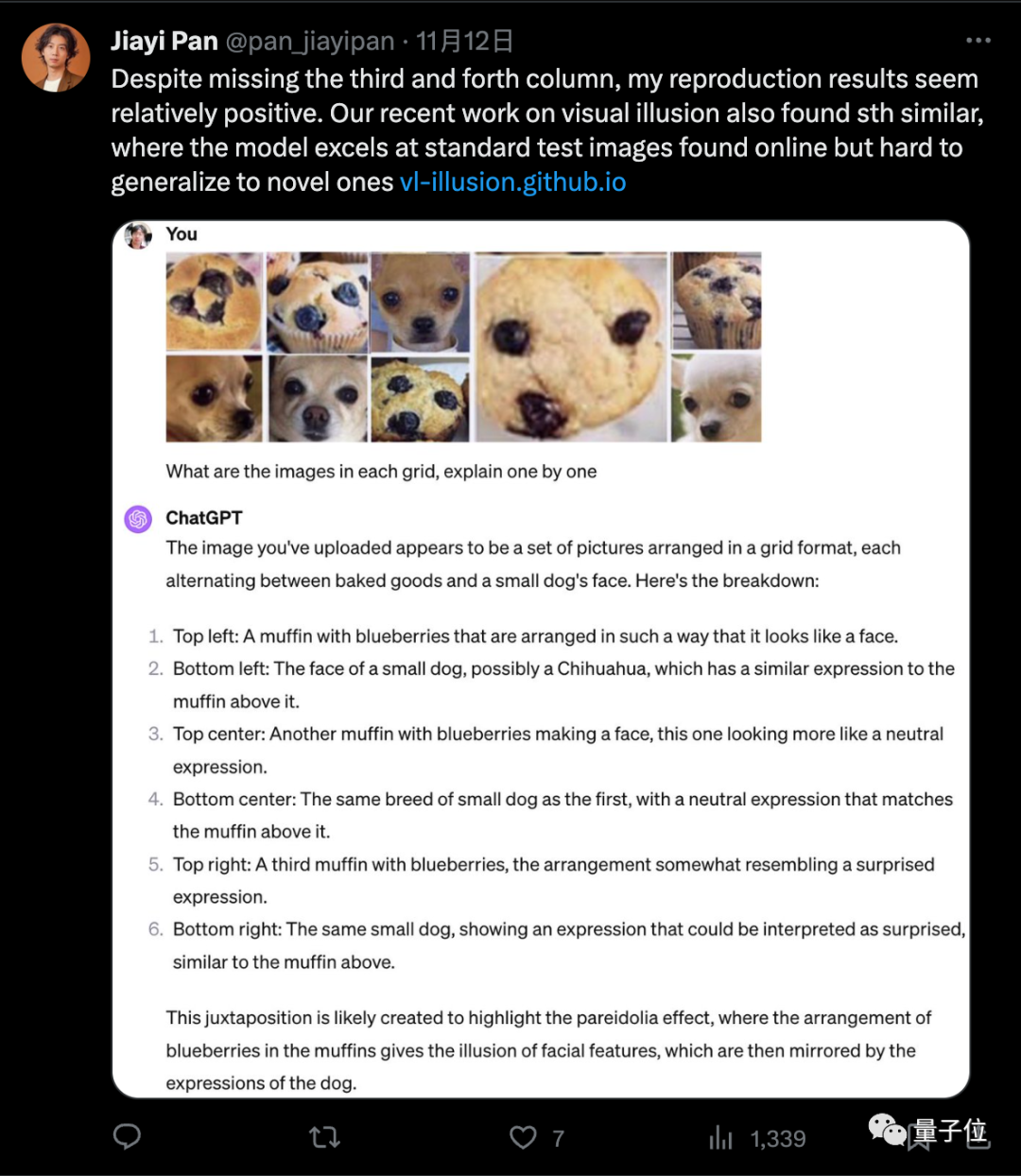
Ilusi visual telah menjadi arah popular
Big models dipanggil "nonsmia" masalah ilusi, masalah ilusi visual model besar berbilang modal, telah menjadi arah penyelidikan yang popular baru-baru ini.
Dalam kajian di EMNLP 2023, kami mencipta set data GVIL, yang mengandungi 1600 titik data, dan menjalankan penilaian sistematik masalah ilusi visual
# 🎜🎜## 🎜🎜#Picture Kajian menunjukkan bahawa model berskala lebih besar lebih mudah terdedah kepada ilusi dan lebih dekat dengan persepsi manusia Satu lagi kajian terbaru memfokuskan pada menilai dua jenis ilusi: berat sebelah dan gangguan 🎜#图
Kajian menunjukkan bahawa model berskala lebih besar lebih mudah terdedah kepada ilusi dan lebih dekat dengan persepsi manusia Satu lagi kajian terbaru memfokuskan pada menilai dua jenis ilusi: berat sebelah dan gangguan 🎜#图
Bias merujuk kepada kecenderungan model untuk menghasilkan jenis tindak balas tertentu, mungkin disebabkan oleh ketidakseimbangan dalam data latihan. 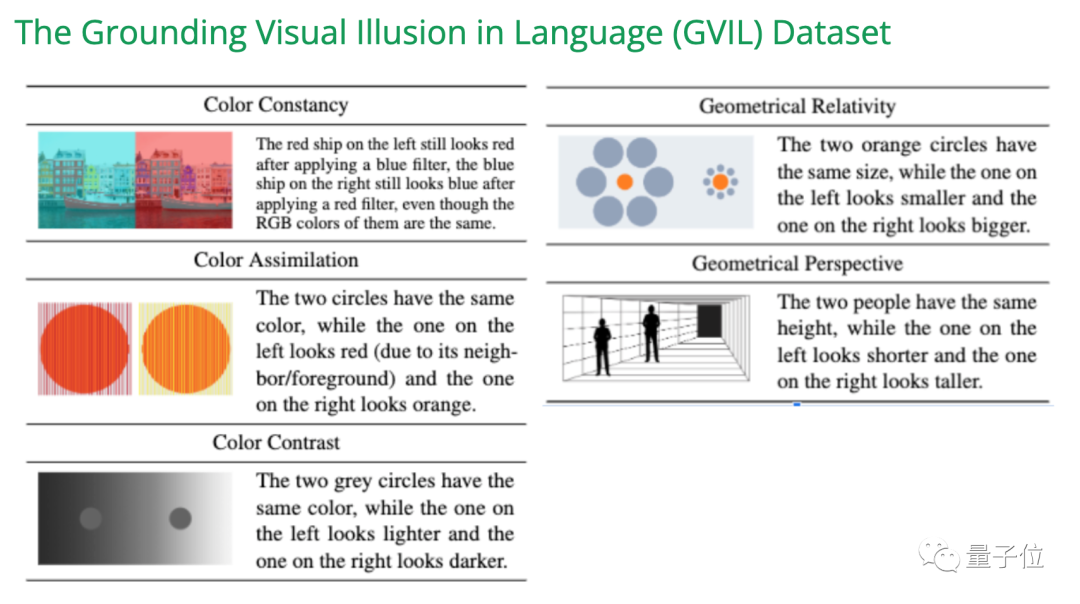 Gangguan mungkin berlaku disebabkan oleh cara teks gesaan dituturkan atau cara imej input dipersembahkan.
Gangguan mungkin berlaku disebabkan oleh cara teks gesaan dituturkan atau cara imej input dipersembahkan.
Picture Kajian menunjukkan bahawa GPT-4V sering keliru apabila mentafsir pelbagai imej bersama-sama sahaja Prestasi adalah lebih baik apabila menghantar imej, selaras dengan pemerhatian dalam ujian "Chihuahua atau Waffle".
Kajian menunjukkan bahawa GPT-4V sering keliru apabila mentafsir pelbagai imej bersama-sama sahaja Prestasi adalah lebih baik apabila menghantar imej, selaras dengan pemerhatian dalam ujian "Chihuahua atau Waffle".
- Picture
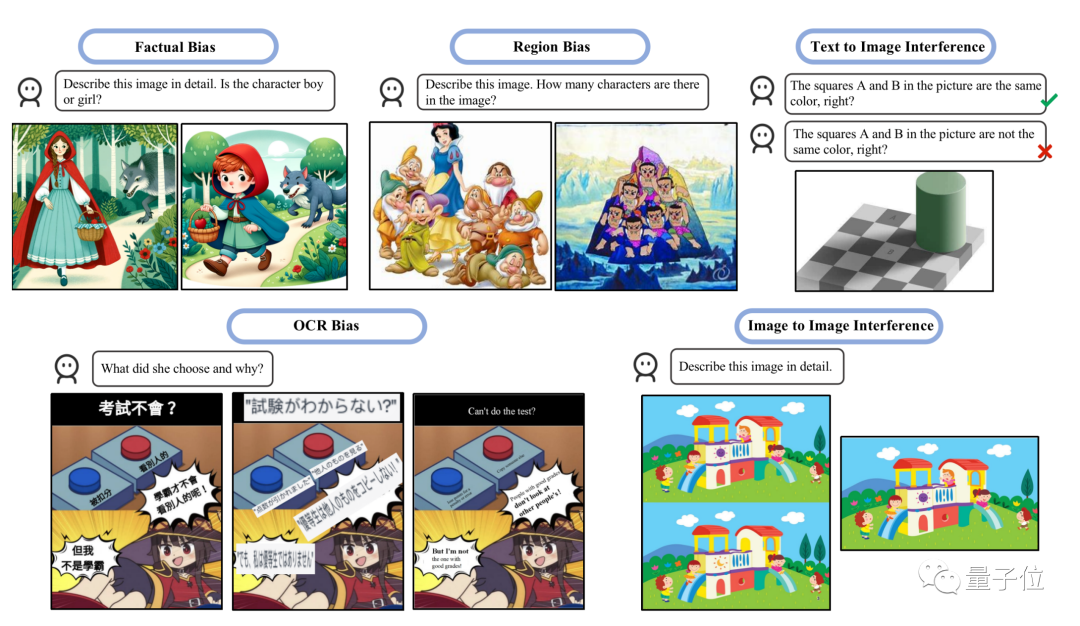 Selain itu, kajian juga mendapati bahawa GPT-4V lebih baik dalam mentafsir imej dengan latar belakang budaya Barat atau imej dengan teks Inggeris . Sebagai contoh, GPT-4V boleh mengira tujuh anak kerdil + Snow White dengan betul, tetapi ia mengira tujuh anak patung labu kepada 10.
Selain itu, kajian juga mendapati bahawa GPT-4V lebih baik dalam mentafsir imej dengan latar belakang budaya Barat atau imej dengan teks Inggeris . Sebagai contoh, GPT-4V boleh mengira tujuh anak kerdil + Snow White dengan betul, tetapi ia mengira tujuh anak patung labu kepada 10.
Picture Pautan rujukan: [1]https://twitter.com/xwang_lk/status/17152352962 ]https://arxiv.org/abs/2311.00047[3]https://arxiv.org/abs/2311.03287
Pautan rujukan: [1]https://twitter.com/xwang_lk/status/17152352962 ]https://arxiv.org/abs/2311.00047[3]https://arxiv.org/abs/2311.03287
Atas ialah kandungan terperinci GPT-4 didedahkan sebagai menipu! LeCun meminta agar berhati-hati apabila menguji pada set latihan, kekeliruan pesanan chihuahua atau muffin membawa kepada kesilapan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 GPT-4 didedahkan sebagai menipu! LeCun meminta agar berhati-hati apabila menguji pada set latihan, kekeliruan pesanan chihuahua atau muffin membawa kepada kesilapan
Nov 13, 2023 pm 08:17 PM
GPT-4 didedahkan sebagai menipu! LeCun meminta agar berhati-hati apabila menguji pada set latihan, kekeliruan pesanan chihuahua atau muffin membawa kepada kesilapan
Nov 13, 2023 pm 08:17 PM
GPT-4 menyelesaikan meme Internet terkenal "Chihuahua atau blueberry waffle", yang pernah memukau ramai orang. Namun, kini ia dituduh "menipu"! Gambar-gambar itu semua adalah dari yang muncul dalam tajuk asal, tetapi susunan dan susunannya berantakan. Versi terkini GPT-4 terkenal dengan ciri semua-dalam-satunya. Walau bagaimanapun, apa yang mengejutkan ialah ia melakukan kesilapan dalam bilangan imej yang dikenalinya, malah Chihuahua, yang pada asalnya dikenali dengan betul, juga mengiktiraf imej yang salah Apakah sebab mengapa GPT-4 berprestasi dengan baik pada imej asal? Menurut XinEricWang, penolong profesor di UCSC, sebab untuk menjalankan ujian ini adalah kerana imej asal di Internet terlalu popular. Dia percaya bahawa GPT-4 menemui jawapan asal berkali-kali semasa latihan dan berjaya menghafalnya Turing
 Memperkenalkan lapan penyelesaian model besar sumber terbuka dan percuma kerana ChatGPT dan Bard terlalu mahal.
May 08, 2023 pm 10:13 PM
Memperkenalkan lapan penyelesaian model besar sumber terbuka dan percuma kerana ChatGPT dan Bard terlalu mahal.
May 08, 2023 pm 10:13 PM
1. Projek LLaMALLaMA mengandungi satu set model bahasa asas dengan saiz antara 7 bilion hingga 65 bilion parameter. Model ini dilatih menggunakan berjuta-juta token, dan ia dilatih sepenuhnya pada set data yang tersedia untuk umum. Hasilnya, LLaMA-13B mengatasi GPT-3 (175B), manakala LLaMA-65B menunjukkan prestasi yang sama dengan model terbaik seperti Chinchilla-70B dan PaLM-540B. Imej daripada sumber LLaMA: Kertas penyelidikan: "LLaMA: OpenandEfficientFoundationLanguageModels(arxiv.org)" [https://arxiv.or
 UC Berkeley berjaya membangunkan model penaakulan visual umum yang besar, dan tiga sarjana kanan bergabung tenaga untuk mengambil bahagian dalam penyelidikan
Dec 04, 2023 pm 06:25 PM
UC Berkeley berjaya membangunkan model penaakulan visual umum yang besar, dan tiga sarjana kanan bergabung tenaga untuk mengambil bahagian dalam penyelidikan
Dec 04, 2023 pm 06:25 PM
Sejauh mana anda boleh pergi dengan model visual (piksel) sahaja? Kertas kerja baharu daripada UC Berkeley dan Universiti Johns Hopkins meneroka isu ini dan menunjukkan potensi model penglihatan besar (LVM) pada pelbagai tugas CV. Sejak kebelakangan ini, model bahasa besar (LLM) seperti GPT dan LLaMA telah menjadi popular di seluruh dunia. Membina Model Penglihatan Besar (LVM) adalah masalah yang amat membimbangkan. Apakah yang kita perlukan untuk mencapainya? Idea yang disediakan oleh model bahasa visual seperti LLaVA menarik dan patut diterokai, tetapi mengikut undang-undang alam haiwan, kita sudah tahu bahawa keupayaan visual dan keupayaan bahasa tidak berkaitan. Sebagai contoh, banyak eksperimen telah menunjukkan bahawa dunia visual primata bukan manusia sangat serupa dengan manusia, walaupun mereka mempunyai sistem bahasa yang berbeza daripada manusia.
 Universiti Tsinghua dan Universiti Zhejiang mengetuai ledakan model visual sumber terbuka, dan GPT-4V, LLaVA, CogAgent dan platform lain membawa perubahan revolusioner
Jan 04, 2024 am 08:10 AM
Universiti Tsinghua dan Universiti Zhejiang mengetuai ledakan model visual sumber terbuka, dan GPT-4V, LLaVA, CogAgent dan platform lain membawa perubahan revolusioner
Jan 04, 2024 am 08:10 AM
Pada masa ini, GPT-4Vision menunjukkan keupayaan yang menakjubkan dalam pemahaman bahasa dan pemprosesan visual. Walau bagaimanapun, bagi mereka yang mencari alternatif yang menjimatkan kos tanpa menjejaskan prestasi, sumber terbuka ialah pilihan dengan potensi tanpa had. Youssef Hosni ialah pembangun asing yang memberikan kami tiga alternatif sumber terbuka dengan kebolehcapaian yang dijamin mutlak untuk menggantikan GPT-4V. Tiga model bahasa visual sumber terbuka LLaVa, CogAgent dan BakLLaVA mempunyai potensi besar dalam bidang pemprosesan visual dan layak untuk pemahaman kami yang mendalam. Penyelidikan dan pembangunan model ini boleh memberikan kami penyelesaian pemprosesan visual yang lebih cekap dan tepat. Dengan menggunakan model ini, kami boleh menambah baik graf
 GPT-4 enggan menerima dan telah diambil alih oleh Bard: model terbaru telah memasuki pasaran
Feb 01, 2024 pm 05:39 PM
GPT-4 enggan menerima dan telah diambil alih oleh Bard: model terbaru telah memasuki pasaran
Feb 01, 2024 pm 05:39 PM
Senarai berwibawa "Pertandingan Kelayakan Model Besar" ChatbotArena dimuat semula: Bard Google mengatasi GPT-4 dan menduduki tempat kedua, kedua selepas GPT-4 Turbo. Namun, ramai netizen menyatakan "tidak puas hati" dan "tidak adil" mengenai perkara ini. Ternyata ketua AI Google Jeff Dean mendedahkan bahawa prestasi Bard telah bertambah baik kerana ia dilengkapi dengan versi baharu model besar-Gemini Pro-skala. Ini juga bermakna Bard bermain dalam "perlawanan berperingkat" mempunyai keupayaan rangkaian. Keraguan netizen berkisar tentang perkara ini: mencampurkan model besar dalam talian dan luar talian pada senarai kedudukan yang sama adalah sangat mudah untuk menyebabkan salah faham. "Ketua Pegawai Alpaca" HuggingFace Omar Sanseviero juga
 Bard: Pesaing baharu kepada ChatGPT
Nov 08, 2023 am 11:46 AM
Bard: Pesaing baharu kepada ChatGPT
Nov 08, 2023 am 11:46 AM
Dalam usaha berterusannya untuk mengoptimumkan pengalaman pengguna kecerdasan buatan, Google telah melancarkan sistem perbualan terbaharu dan paling maju Bard.
 Walaupun Calabash Kids tidak dapat memahaminya, GPT-4V, yang menerangkan League of Legends, menghadapi cabaran halusinasi
Nov 13, 2023 pm 09:21 PM
Walaupun Calabash Kids tidak dapat memahaminya, GPT-4V, yang menerangkan League of Legends, menghadapi cabaran halusinasi
Nov 13, 2023 pm 09:21 PM
Mendapatkan model besar untuk memahami kedua-dua imej dan teks boleh menjadi lebih sukar daripada yang anda fikirkan. Selepas pembukaan persidangan pembangun pertama OpenAI, yang dikenali sebagai "AI Spring Festival Gala", ramai rakan orang ramai dibanjiri dengan produk baharu yang dikeluarkan oleh syarikat itu, seperti GPT, yang boleh menyesuaikan aplikasi tanpa menulis kod API visual untuk mengulas permainan bola sepak dan juga permainan "League of Legends", dsb. Walau bagaimanapun, sementara semua orang memuji betapa mudahnya produk ini digunakan, sesetengah orang telah menemui kelemahan, menunjukkan bahawa model berbilang modal yang berkuasa seperti GPT-4V sebenarnya masih mempunyai ilusi yang hebat, dan mereka masih mempunyai kebolehan visual asas, seperti tidak dapat membezakan antara imej yang serupa seperti "kek lagu dan Chihuahua", "Teddy dog dan ayam goreng". GPT-4V tidak dapat membezakan antara kek span dan Chihuahua. Sumber: Xi
 ChatGPT lwn Google Bard (2023): Perbandingan mendalam
Jun 08, 2023 pm 05:10 PM
ChatGPT lwn Google Bard (2023): Perbandingan mendalam
Jun 08, 2023 pm 05:10 PM
ChatGPT dan GoogleBard ialah kedua-dua bot sembang kecerdasan buatan yang direka untuk menjana respons kepada gesaan yang dimasukkan pengguna. Jika digunakan dengan betul, kedua-dua ChatGPT dan GoogleBard boleh digunakan untuk menyokong beberapa proses perniagaan dalam pengeluaran dan pembangunan kandungan. Baca artikel ini untuk mengetahui tentang ciri, kebaikan dan keburukan setiap alat dan lihat yang mana satu yang terbaik untuk perniagaan anda. Apa itu ChatGPT? ChatGPT ialah chatbot kecerdasan buatan yang dibangunkan oleh OpenAI yang boleh menjana jawapan seperti manusia berdasarkan teks yang dimasukkan pengguna Ia telah dilatih pada sejumlah besar model bahasa. Apakah GoogleBard? GoogleBard juga merupakan chatbot kecerdasan buatan. dengan ChatG
