
 Peranti teknologi
AI
Ramalan keuntungan tidak lagi sukar, kaedah regresi linear scikit-belajar membolehkan anda memperoleh dua kali ganda hasil dengan separuh usaha
Peranti teknologi
AI
Ramalan keuntungan tidak lagi sukar, kaedah regresi linear scikit-belajar membolehkan anda memperoleh dua kali ganda hasil dengan separuh usaha
Ramalan keuntungan tidak lagi sukar, kaedah regresi linear scikit-belajar membolehkan anda memperoleh dua kali ganda hasil dengan separuh usaha

1. Pengenalan
Kecerdasan buatan generatif sudah pasti merupakan teknologi yang mengubah permainan, tetapi untuk kebanyakan masalah perniagaan, model pembelajaran mesin tradisional seperti regresi dan klasifikasi masih menjadi pilihan pertama.
Kandungan yang ditulis semula: Bayangkan bagaimana pelabur seperti ekuiti persendirian atau modal teroka boleh memanfaatkan pembelajaran mesin. Untuk menjawab soalan ini, anda perlu memahami perkara yang penting bagi pelabur data dan cara ia digunakan. Keputusan mengenai pelaburan dalam syarikat bukan sahaja berdasarkan data yang boleh diukur seperti perbelanjaan, pertumbuhan dan kadar pembakaran tunai, tetapi juga data kualitatif seperti rekod pengasas, maklum balas pelanggan dan pengalaman produk
Artikel ini akan memperkenalkan asas regresi linear, yang boleh didapati di Cari kod lengkap di sini.
Kandungan yang perlu ditulis semula ialah: [Kod]: https://github.com/RoyiHD/linear-regression
2 Tetapan projek
Artikel ini akan menggunakan Buku Nota Jupyter untuk projek ini. Mula-mula import beberapa perpustakaan.
Import perpustakaan
# 绘制图表import matplotlib.pyplot as plt# 数据管理和处理from pandas import DataFrame# 绘制热力图import seaborn as sns# 分析from sklearn.metrics import r2_score# 用于训练和测试的数据管理from sklearn.model_selection import train_test_split# 导入线性模型from sklearn.linear_model import LinearRegression# 代码注释from typing import List
3. Data
Untuk memudahkan masalah, artikel ini akan menggunakan data serantau. Data tersebut mewakili kategori perbelanjaan dan keuntungan syarikat. Anda boleh melihat beberapa contoh titik data yang berbeza. Artikel ini berharap dapat menggunakan data perbelanjaan untuk melatih model regresi linear dan meramalkan keuntungan.
Adalah penting untuk memahami bahawa data yang diterangkan dalam artikel ini adalah mengenai perbelanjaan syarikat. Kuasa ramalan yang bermakna hanya mungkin apabila data perbelanjaan digabungkan dengan data seperti pertumbuhan hasil, cukai tempatan, pelunasan dan keadaan pasaran
|
|
| Kandungan yang perlu ditulis semula ialah: 192261.83||
| ialah: 7.5513 |
|||
| 191792.06 | |||
153441.51 |
101145.55 |
Apa yang perlu ditulis semula ialah: 407934 ditulis semula ialah: 1 91050.39 |
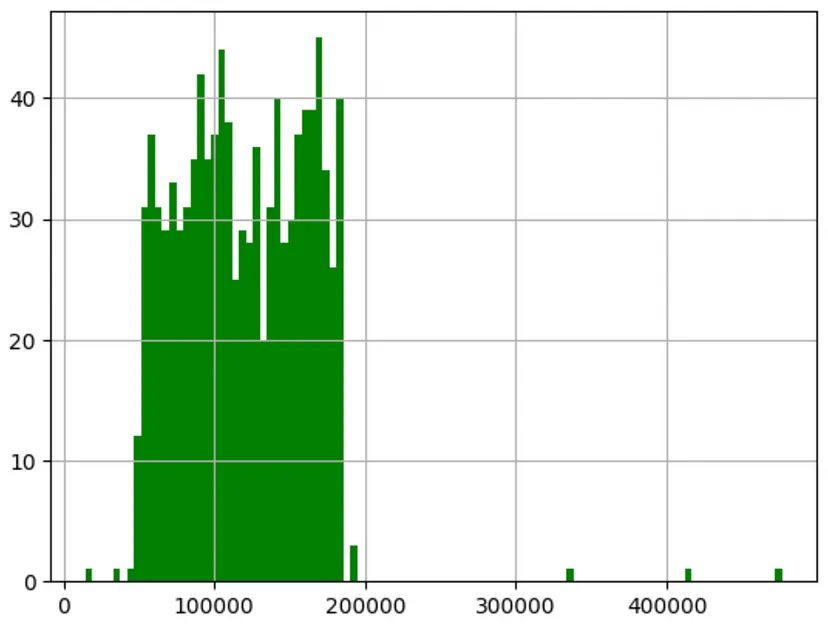
加载数据companies: DataFrame = pd.read_csv("companies.csv", header = 0)Salin selepas log masuk 4、数据可视化了解数据对于确定要使用的特征、需要进行归一化和转换的特征、从数据中删除异常值以及对特定数据点进行的处理是很重要的。 目标(利润)直方图 可以直接使用DataFrame绘制直方图(Pandas使用Matplotlib来绘制数据帧),可以直接访问利润并绘制它。 companies['Profit'].hist( color='g', bins=100); Salin selepas log masuk
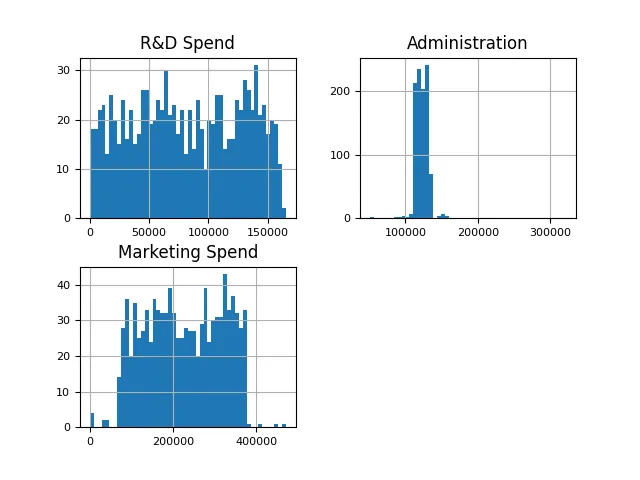
从数据中可以清楚地看出,利润超过20万美元的异常值非常罕见。这表明本文所涉及的数据代表的是规模较大的公司。鉴于异常值数量较少,可以将其保留 特征(支出)直方图在这里,本文旨在使用特征的直方图,并观察其分布情况。Y轴表示数字频率,X轴表示支出 companies[["R&D Spend", "行政管理", "Marketing Spend"]].hist(figsize=(16, 20), bins=50, xlabelsize=8, ylabelsize=8) Salin selepas log masuk
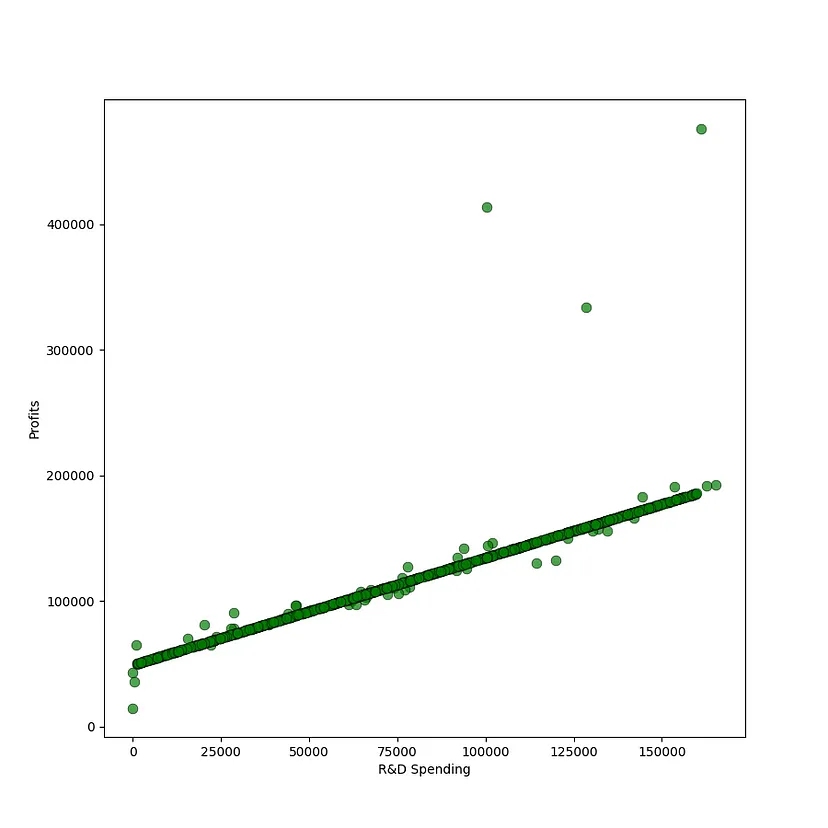
可以观察到一个健康的分布,只有很少的异常值。根据直觉,可以预期投入更多资金在研发和市场营销上的公司会获得更高的利润。从下面的散点图中可以看出,研发支出和利润之间存在明显的相关性 profits: DataFrame = companies[["Profit"]]research_and_development_spending: DataFrame = companies[["R&D Spend"]]figure, ax = plt.subplots(figsize = (9, 9))plt.xlabel("R&D Spending")plt.ylabel("Profits")ax.scatter(research_and_development_spending, profits, s=60, alpha=0.7, edgecolors="k",color='g',linewidths=0.5)Salin selepas log masuk
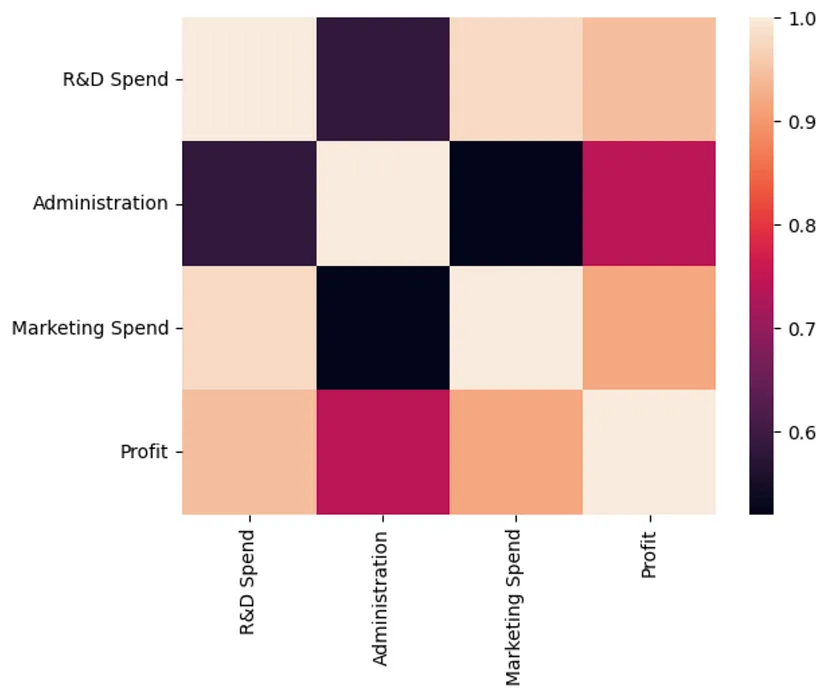
可以使用相关的热图来进一步探索支出和利润之间的关系。从图中可以观察到研发和市场营销支出与利润之间的相关性比行政支出更高 sns.heatmap(companies.corr()) Salin selepas log masuk
5、模型训练首先需要将数据集分割为训练集和测试集两部分。Sklearn提供了一个辅助方法来完成这个任务。鉴于本文的数据集很简单且足够小,可以按照以下方式将特征和目标分离开来。 数据集features: DataFrame = companies[["R&D Spend", "行政管理", "Marketing Spend",]]targets: DataFrame = companies[["Profit"]]train_features, test_features, train_targets, test_targets = train_test_split(features, targets,test_size=0.2) Salin selepas log masuk 大多数数据科学家会使用不同的命名约定,如X_train、y_train或其他类似的变体。
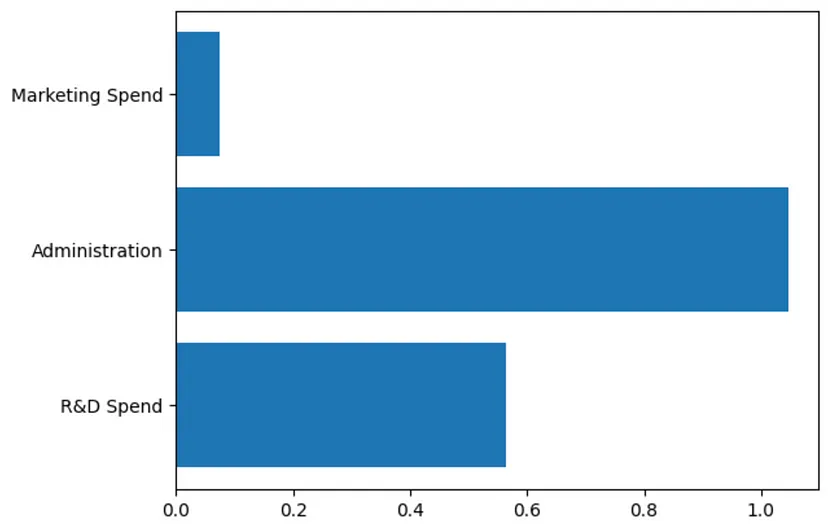
现在可以创建并训练模型了。Sklearn使事情变得非常简单。 model: LinearRegression = LinearRegression()model.fit(train_features, train_targets) Salin selepas log masuk 6、模型评估本文希望对模型的性能及其可用性进行评估。首先查看一下计算得到的系数。在机器学习中,系数是用来与每个特征相乘的学习到的权重或数值。期望看到每个特征都有一个学习系数。 coefficients = model.coef_"""We should see the following in our consoleCoefficients[[0.55664299 1.08398919 0.07529883]]""" Salin selepas log masuk 正如上述所看到的,有3个系数,每个特征对应一个系数(“研发支出”、“行政支出”、“市场营销支出”)。还可以将其绘制成图表,以便更直观地了解每个系数。 plt.figure()plt.barh(train_features.columns, coefficients[0])plt.show() Salin selepas log masuk
计算误差希望了解模型的误差率,我们将使用Sklearn的R2得分 test_predictions: List[float] = model.predict(test_features)root_squared_error: float = r2_score(test_targets, test_predictions)"""floatWe should see an ouput similar to this0.9781424529214315""" Salin selepas log masuk 离1越近,模型就越准确。实际上可以用一种非常简单的方式对这一点进行测试。 使用下面的支出模型来预测利润,并希望得到一个接近192261美元的数字,可以提取数据集的第一行 "R&D Spend" |"行政管理" |"Marketing Spend" | "Profit"需要进行重写的内容是:165349.2 136897.8需要重写的内容是:471784.1需要改写的内容是:192261.83 Salin selepas log masuk 接下来创建一个推理请求。 inference_request: DataFrame = pd.DataFrame([{"R&D Spend":需要进行重写的内容是:165349.2, "行政管理":136897.8, "Marketing Spend":需要重写的内容是:471784.1 }])Salin selepas log masuk 运行模型。 inference: float = model.predict(inference_request)"""We should get a number that is around199739.88721901""" Salin selepas log masuk 现在可以看到的误差率是abs(199739-192261)/192261=0.0388。这是非常准确的。 7、结论处理数据、搭建模型和分析数据有很多方法。没有一种解决方案适用于所有情况,当用机器学习解决业务问题时,其中一个关键过程是搭建多个旨在解决同一个问题的模型,并选择最有前途的模型 |
Atas ialah kandungan terperinci Ramalan keuntungan tidak lagi sukar, kaedah regresi linear scikit-belajar membolehkan anda memperoleh dua kali ganda hasil dengan separuh usaha. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Penjana Seni AI Terbaik (Percuma & amp; Dibayar) untuk projek kreatif
Apr 02, 2025 pm 06:10 PM
Penjana Seni AI Terbaik (Percuma & amp; Dibayar) untuk projek kreatif
Apr 02, 2025 pm 06:10 PM
Artikel ini mengkaji semula penjana seni AI atas, membincangkan ciri -ciri mereka, kesesuaian untuk projek kreatif, dan nilai. Ia menyerlahkan Midjourney sebagai nilai terbaik untuk profesional dan mengesyorkan Dall-E 2 untuk seni berkualiti tinggi dan disesuaikan.
 Adakah chatgpt 4 o tersedia?
Mar 28, 2025 pm 05:29 PM
Adakah chatgpt 4 o tersedia?
Mar 28, 2025 pm 05:29 PM
CHATGPT 4 kini tersedia dan digunakan secara meluas, menunjukkan penambahbaikan yang ketara dalam memahami konteks dan menjana tindak balas yang koheren berbanding dengan pendahulunya seperti ChATGPT 3.5. Perkembangan masa depan mungkin merangkumi lebih banyak Inter yang diperibadikan
 Bermula dengan Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Bermula dengan Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta's Llama 3.2: Lompat ke hadapan dalam Multimodal dan Mobile AI META baru -baru ini melancarkan Llama 3.2, kemajuan yang ketara dalam AI yang memaparkan keupayaan penglihatan yang kuat dan model teks ringan yang dioptimumkan untuk peranti mudah alih. Membina kejayaan o
 CHATBOTS AI terbaik berbanding (Chatgpt, Gemini, Claude & amp; Lagi)
Apr 02, 2025 pm 06:09 PM
CHATBOTS AI terbaik berbanding (Chatgpt, Gemini, Claude & amp; Lagi)
Apr 02, 2025 pm 06:09 PM
Artikel ini membandingkan chatbots AI seperti Chatgpt, Gemini, dan Claude, yang memberi tumpuan kepada ciri -ciri unik mereka, pilihan penyesuaian, dan prestasi dalam pemprosesan bahasa semula jadi dan kebolehpercayaan.
 Pembantu Menulis AI Teratas untuk Meningkatkan Penciptaan Kandungan Anda
Apr 02, 2025 pm 06:11 PM
Pembantu Menulis AI Teratas untuk Meningkatkan Penciptaan Kandungan Anda
Apr 02, 2025 pm 06:11 PM
Artikel ini membincangkan pembantu penulisan AI terkemuka seperti Grammarly, Jasper, Copy.ai, WriteSonic, dan Rytr, yang memberi tumpuan kepada ciri -ciri unik mereka untuk penciptaan kandungan. Ia berpendapat bahawa Jasper cemerlang dalam pengoptimuman SEO, sementara alat AI membantu mengekalkan nada terdiri
 Sistem Rag Agentik 7 Teratas untuk Membina Ejen AI
Mar 31, 2025 pm 04:25 PM
Sistem Rag Agentik 7 Teratas untuk Membina Ejen AI
Mar 31, 2025 pm 04:25 PM
2024 menyaksikan peralihan daripada menggunakan LLMS untuk penjanaan kandungan untuk memahami kerja dalaman mereka. Eksplorasi ini membawa kepada penemuan agen AI - sistem pengendalian sistem autonomi dan keputusan dengan intervensi manusia yang minimum. Buildin
 Bagaimana cara mengakses Falcon 3? - Analytics Vidhya
Mar 31, 2025 pm 04:41 PM
Bagaimana cara mengakses Falcon 3? - Analytics Vidhya
Mar 31, 2025 pm 04:41 PM
Falcon 3: Model bahasa besar sumber terbuka revolusioner Falcon 3, lelaran terkini dalam siri Falcon yang terkenal LLMS, mewakili kemajuan yang ketara dalam teknologi AI. Dibangunkan oleh Institut Inovasi Teknologi (TII), ini terbuka
 Memilih Penjana Suara AI Terbaik: Pilihan Teratas Ditinjau
Apr 02, 2025 pm 06:12 PM
Memilih Penjana Suara AI Terbaik: Pilihan Teratas Ditinjau
Apr 02, 2025 pm 06:12 PM
Artikel ini mengulas penjana suara AI atas seperti Google Cloud, Amazon Polly, Microsoft Azure, IBM Watson, dan Descript, memberi tumpuan kepada ciri -ciri mereka, kualiti suara, dan kesesuaian untuk keperluan yang berbeza.
