

Sistem pengesyoran untuk teknologi permulaan sejuk NetEase Cloud Music


1. Latar belakang masalah: keperluan dan kepentingan pemodelan permulaan sejuk
 #🎜 🎜🎜#
#🎜 🎜🎜#
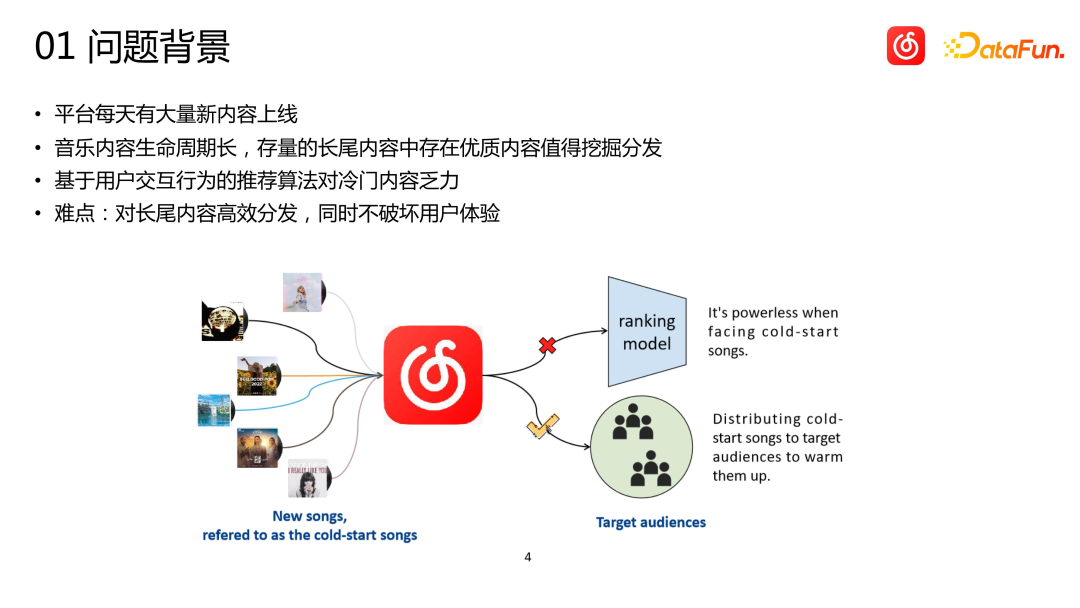
Sebagai platform kandungan, Cloud Music akan mempunyai sejumlah besar kandungan baharu dalam talian setiap hari. Walaupun bilangan kandungan baharu pada platform muzik awan agak kecil berbanding dengan platform lain seperti video pendek, bilangan sebenar mungkin jauh melebihi imaginasi semua orang. Pada masa yang sama, kandungan muzik jauh berbeza daripada video pendek, berita dan cadangan produk. Kitaran hayat muzik menjangkau tempoh masa yang sangat lama, selalunya diukur dalam tahun. Sesetengah lagu mungkin meletup selepas tidak aktif selama berbulan-bulan atau bertahun-tahun, dan lagu-lagu klasik mungkin masih mempunyai daya hidup yang kuat walaupun selepas lebih daripada sepuluh tahun. Oleh itu, untuk sistem pengesyoran platform muzik, adalah lebih penting untuk menemui kandungan berkualiti tinggi yang tidak popular dan berekor panjang dan mengesyorkannya kepada pengguna yang betul daripada pengesyoran dalam kategori lain #🎜🎜 ## 🎜🎜# Disebabkan kekurangan data interaksi pengguna untuk item (lagu) yang tidak popular dan berekor panjang, amat sukar bagi sistem pengesyoran yang bergantung terutamanya pada data tingkah laku untuk mencapai pengedaran yang tepat. Situasi yang ideal adalah untuk membenarkan sebahagian kecil trafik digunakan untuk penerokaan dan pengedaran, dan untuk mengumpul data semasa penerokaan. Walau bagaimanapun, trafik dalam talian sangat berharga, dan penerokaan selalunya merosakkan pengalaman pengguna dengan mudah. Sebagai peranan yang bertanggungjawab secara langsung untuk penunjuk perniagaan, pengesyoran tidak membenarkan kami melakukan terlalu banyak penerokaan yang tidak pasti untuk item ekor panjang ini. Oleh itu, kita perlu dapat mencari bakal pengguna sasaran item dengan lebih tepat dari awal, iaitu, mulakan sejuk item dengan rekod interaksi sifar.
2. Penyelesaian teknikal: pemilihan ciri, model model
Seterusnya, saya akan kongsikan kaedah yang digunakan oleh penyelesaian Teknikal Muzik Awan.
 Masalah utama ialah bagaimana mencari pengguna sasaran berpotensi projek cold start. Kami membahagikan soalan kepada dua bahagian:
Masalah utama ialah bagaimana mencari pengguna sasaran berpotensi projek cold start. Kami membahagikan soalan kepada dua bahagian:
Dalam kes di mana tiada pengguna mengklik untuk bermain, apakah maklumat berkesan lain yang ada pada projek permulaan sejuk yang boleh digunakan sebagai ciri untuk membantu kami mengedarkan? Di sini kami menggunakan ciri berbilang modal muzik
Bagaimana untuk menggunakan ciri ini untuk memodelkan pengedaran permulaan sejuk? Untuk menangani perkara ini, kami akan berkongsi dua penyelesaian pemodelan utama:
- Pemodelan I2I: Algoritma Permulaan Dingin Dipertingkatkan Pembelajaran Kontrastif Berpandu Kendiri.
- Pemodelan U2I: Pemodelan sempadan minat pengguna DSSM multimodal.
 Ditulis semula ke dalam bahasa Cina:
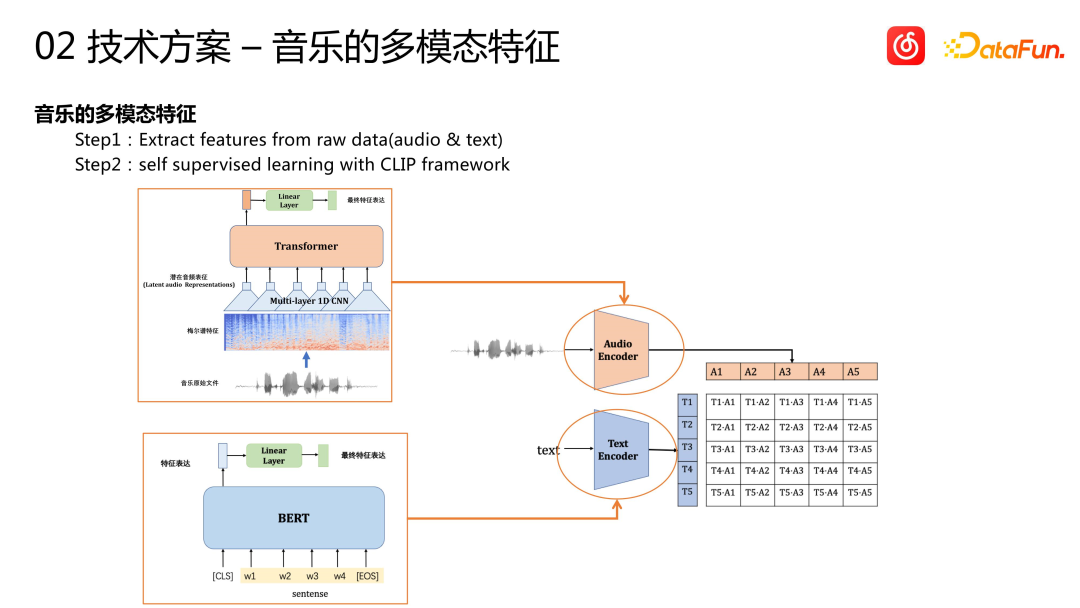
Lagu itu sendiri adalah sejenis maklumat berbilang modal Selain maklumat tag seperti bahasa dan genre, audio dan teks lagu (termasuk tajuk lagu dan lirik) mengandungi maklumat yang kaya. Memahami maklumat ini dan menemui korelasi antara maklumat tersebut dengan tingkah laku pengguna adalah kunci kepada permulaan yang berjaya. Pada masa ini, platform muzik awan menggunakan rangka kerja CLIP untuk mencapai ekspresi ciri berbilang modal. Untuk ciri audio, beberapa kaedah pemprosesan isyarat audio mula-mula digunakan untuk menukarnya ke dalam bentuk domain video, dan kemudian model jujukan seperti Transformer digunakan untuk pengekstrakan dan pemodelan ciri, dan akhirnya vektor audio diperolehi. Untuk ciri teks, model BERT digunakan untuk pengekstrakan ciri. Akhir sekali, rangka kerja pra-latihan yang diselia sendiri oleh CLIP digunakan untuk mensiri ciri-ciri ini untuk mendapatkan representasi pelbagai mod lagu. Salah satunya ialah meletakkan ciri berbilang modal ke dalam model pengesyoran perniagaan untuk latihan satu peringkat hujung ke hujung, tetapi kaedah ini lebih mahal. Oleh itu, kami memilih pemodelan dua peringkat. Mula-mula lakukan pemodelan pra-latihan, dan kemudian masukkan ciri ini ke dalam model panggil semula atau model penghalusan perniagaan hiliran untuk digunakan.
Ditulis semula ke dalam bahasa Cina:
Lagu itu sendiri adalah sejenis maklumat berbilang modal Selain maklumat tag seperti bahasa dan genre, audio dan teks lagu (termasuk tajuk lagu dan lirik) mengandungi maklumat yang kaya. Memahami maklumat ini dan menemui korelasi antara maklumat tersebut dengan tingkah laku pengguna adalah kunci kepada permulaan yang berjaya. Pada masa ini, platform muzik awan menggunakan rangka kerja CLIP untuk mencapai ekspresi ciri berbilang modal. Untuk ciri audio, beberapa kaedah pemprosesan isyarat audio mula-mula digunakan untuk menukarnya ke dalam bentuk domain video, dan kemudian model jujukan seperti Transformer digunakan untuk pengekstrakan dan pemodelan ciri, dan akhirnya vektor audio diperolehi. Untuk ciri teks, model BERT digunakan untuk pengekstrakan ciri. Akhir sekali, rangka kerja pra-latihan yang diselia sendiri oleh CLIP digunakan untuk mensiri ciri-ciri ini untuk mendapatkan representasi pelbagai mod lagu. Salah satunya ialah meletakkan ciri berbilang modal ke dalam model pengesyoran perniagaan untuk latihan satu peringkat hujung ke hujung, tetapi kaedah ini lebih mahal. Oleh itu, kami memilih pemodelan dua peringkat. Mula-mula lakukan pemodelan pra-latihan, dan kemudian masukkan ciri ini ke dalam model panggil semula atau model penghalusan perniagaan hiliran untuk digunakan.
Bagaimana untuk mengedarkan lagu kepada pengguna tanpa interaksi pengguna? Kami mengguna pakai penyelesaian pemodelan tidak langsung: mengubah masalah lagu kepada pengguna (I2U) kepada masalah pengguna lagu serupa lagu (I2I2U), iaitu, mula-mula cari lagu yang serupa dengan lagu permulaan sejuk ini, dan kemudian lagu serupa ini dipadankan dengan pengguna Terdapat beberapa rekod interaksi sejarah, seperti koleksi dan isyarat lain yang agak kuat, dan sekumpulan pengguna sasaran boleh ditemui. Lagu pelancaran sejuk ini kemudiannya diedarkan kepada pengguna sasaran ini.
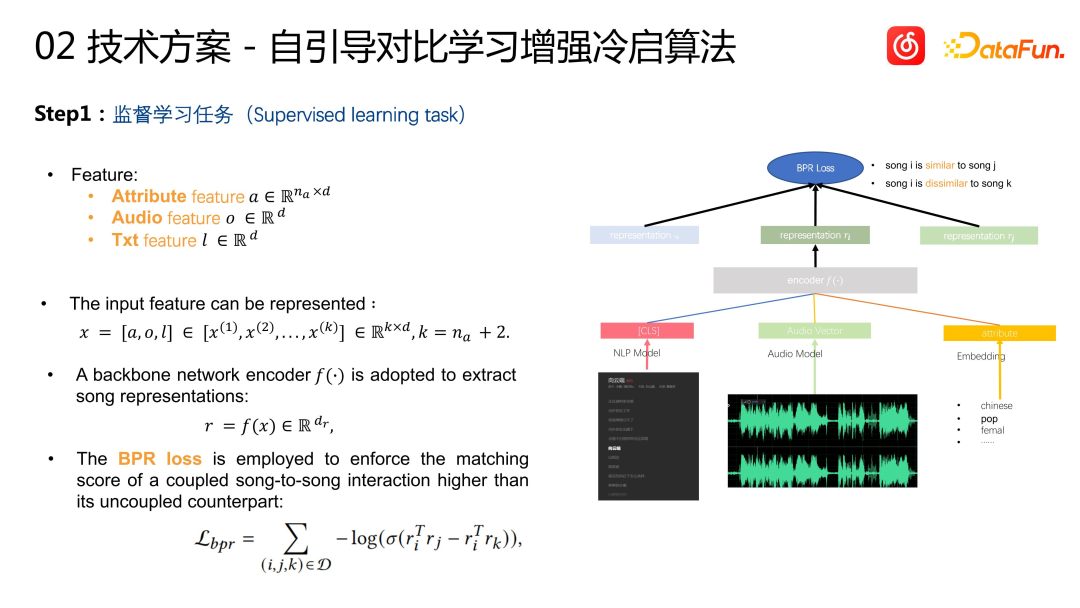
Kaedah khusus adalah seperti berikut. Dari segi ciri lagu, sebagai tambahan kepada maklumat berbilang modal yang baru disebut, ia juga termasuk maklumat tag lagu, seperti bahasa, genre, dll., untuk membantu kami menjalankan pemodelan yang diperibadikan. Kami mengagregatkan semua ciri bersama-sama, memasukkannya ke dalam pengekod, dan akhirnya mengeluarkan vektor lagu Persamaan setiap vektor lagu boleh diwakili oleh produk dalaman vektor. Matlamat pembelajaran ialah persamaan I2I yang dikira berdasarkan tingkah laku, iaitu persamaan penapisan kolaboratif Kami menambah lapisan pengesahan ujian pasca berdasarkan data penapisan kolaboratif, iaitu berdasarkan cadangan I2I, kesan maklum balas pengguna. adalah lebih baik Sepasang item digunakan sebagai sampel positif untuk pembelajaran bagi memastikan ketepatan sasaran pembelajaran. Sampel negatif dibina menggunakan pensampelan rawak global. Fungsi kerugian menggunakan kehilangan BPR. Ini adalah pendekatan CB2CF yang sangat standard dalam sistem pengesyoran, iaitu mempelajari persamaan lagu dalam ciri tingkah laku pengguna berdasarkan kandungan dan maklumat tag lagu
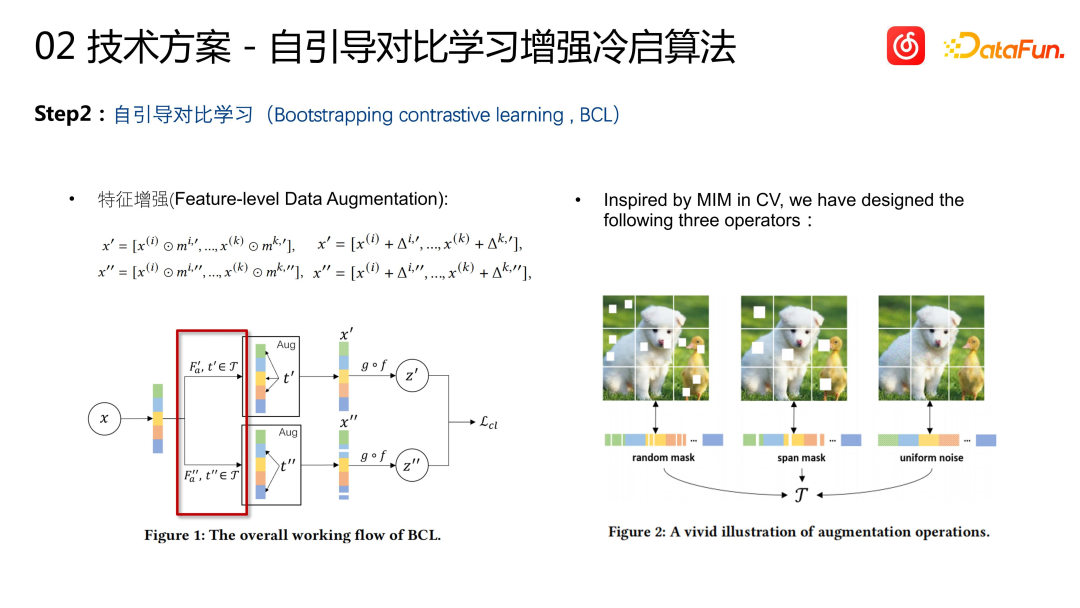
Berdasarkan kaedah di atas, kami memperkenalkan pembelajaran kontrastif Sebagai lelaran kedua. Sebab mengapa kami memilih untuk memperkenalkan pembelajaran kontrastif adalah kerana dalam set pembelajaran proses ini, kami masih menggunakan data CF dan perlu belajar melalui tingkah laku interaksi pengguna. Walau bagaimanapun, kaedah pembelajaran sebegini boleh membawa kepada masalah, iaitu item yang dipelajari akan mempunyai kecenderungan "item yang lebih popular dipelajari dan item yang kurang popular dipelajari". Walaupun matlamat kami adalah untuk belajar daripada kandungan pelbagai mod lagu kepada persamaan tingkah laku lagu, didapati dalam latihan sebenar masih terdapat masalah berat sebelah yang popular dan tidak popular
Oleh itu kami memperkenalkan satu set algoritma pembelajaran kontrastif , bertujuan untuk Meningkatkan keupayaan pembelajaran item yang tidak popular. Pertama, kita perlu mempunyai perwakilan Item, yang dipelajari melalui pengekod berbilang modal sebelumnya. Kemudian, dua transformasi rawak dilakukan pada perwakilan ini. Ini adalah amalan biasa dalam CV, yang melibatkan penutupan secara rawak atau menambah hingar pada ciri. Dua perwakilan yang diubah secara rawak yang dijana oleh Item yang sama dianggap serupa, dan dua perwakilan yang dijana oleh Item yang berbeza dianggap tidak serupa Mekanisme pembelajaran kontrastif ini adalah peningkatan data untuk pembelajaran permulaan sejuk Melalui ini Kaedah menjana pasangan sampel asas pengetahuan pembelajaran.

Atas dasar peningkatan ciri, kami juga menambah mekanisme pengumpulan persatuan
Kandungan yang ditulis semula adalah seperti berikut: Mekanisme pengumpulan korelasi: Mula-mula hitung korelasi antara setiap pasangan ciri, iaitu, mengekalkan matriks korelasi, dan kemas kini matriks semasa proses latihan model. Ciri-ciri tersebut kemudiannya dibahagikan kepada dua kumpulan berdasarkan korelasi antaranya. Operasi khusus adalah untuk memilih ciri secara rawak, meletakkan separuh daripada ciri yang paling berkaitan dengan ciri itu ke dalam satu kumpulan, dan meletakkan yang selebihnya ke dalam kumpulan lain. Akhir sekali, setiap set ciri diubah secara rawak untuk menjana pasangan sampel untuk pembelajaran kontrastif. Dengan cara ini, N item dalam setiap kelompok akan menjana 2N paparan. Sepasang pandangan daripada projek yang sama digunakan sebagai sampel positif untuk pembelajaran kontrastif, dan sepasang pandangan daripada projek yang berbeza digunakan sebagai sampel negatif untuk pembelajaran kontrastif. Kehilangan pembelajaran kontrastif menggunakan maklumat entropi silang ternormal (infoNCE), dan digabungkan dengan kehilangan BPR bahagian pembelajaran yang diselia sebelumnya sebagai fungsi kehilangan terakhir
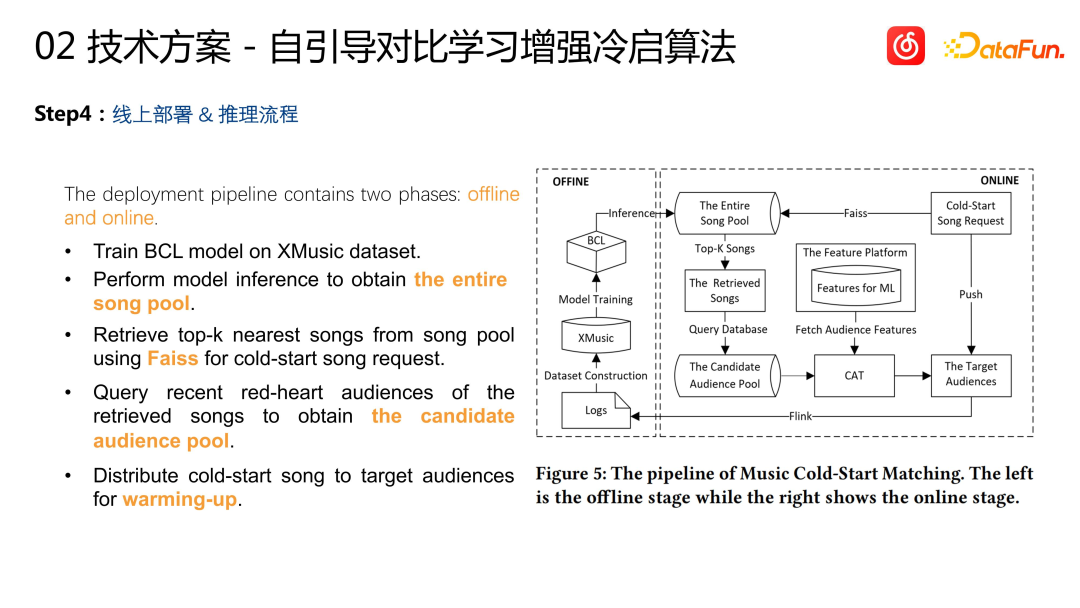
Proses penyebaran dan inferens dalam talian: Selesai dalam latihan luar talian Akhirnya. , indeks vektor dibina untuk semua lagu sedia ada. Untuk projek permulaan sejuk yang baharu, vektornya diperoleh melalui penaakulan model, dan kemudian beberapa projek yang paling serupa diambil daripada indeks vektor Projek ini adalah projek saham masa lalu, jadi terdapat sekumpulan interaksi sejarah dengan mereka. seperti main balik, pengumpulan, dsb.) mengedarkan projek yang memerlukan permulaan sejuk kepada kumpulan pengguna ini untuk melengkapkan permulaan sejuk projek
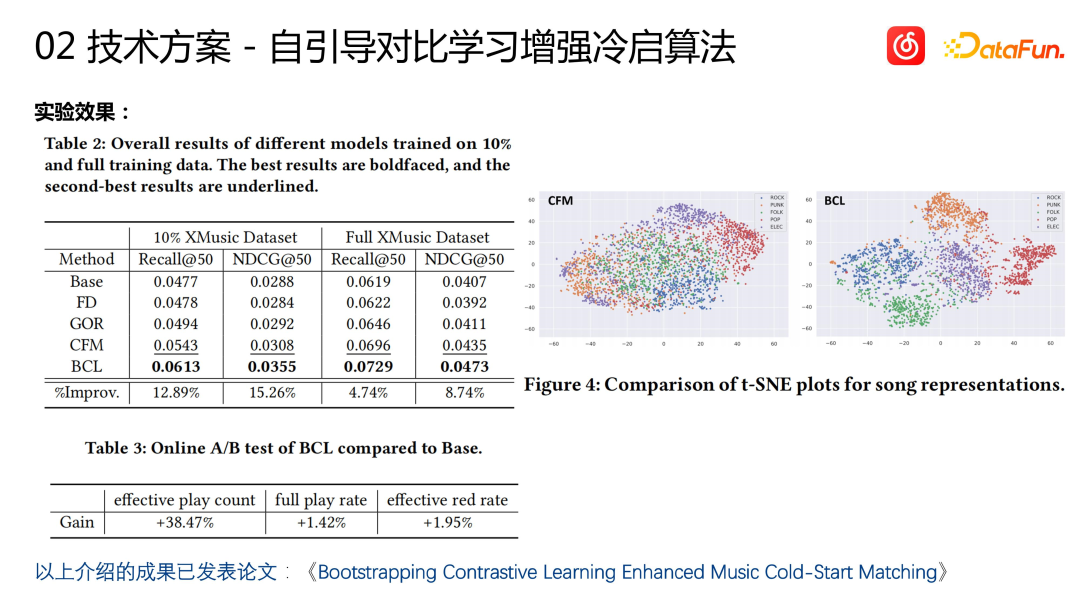
Kami menilai algoritma permulaan sejuk, termasuk penilaian penunjuk luar talian dan luar talian, dan mencapai hasil yang sangat baik Seperti yang ditunjukkan dalam rajah di atas, perwakilan lagu yang dikira oleh model permulaan sejuk boleh mencapai hasil yang sangat baik untuk lagu dari genre yang berbeza. kesan pengelompokan. Beberapa keputusan telah diterbitkan dalam kertas kerja awam (Bootstrapping Contrastive Learning Enhanced Music Cold-Start Matching). Dalam talian, sambil mencari lebih ramai pengguna sasaran yang berpotensi (+38%), algoritma permulaan sejuk juga mencapai peningkatan dalam penunjuk perniagaan seperti kadar pengumpulan item permulaan sejuk (+1.95%) dan kadar penyiapan (+1.42%).

Kami berfikir lebih jauh:
- Dalam skema I2I2U di atas, tiada ciri sisi pengguna digunakan.
- Bagaimana untuk memperkenalkan ciri pengguna untuk membantu Item mula sejuk?
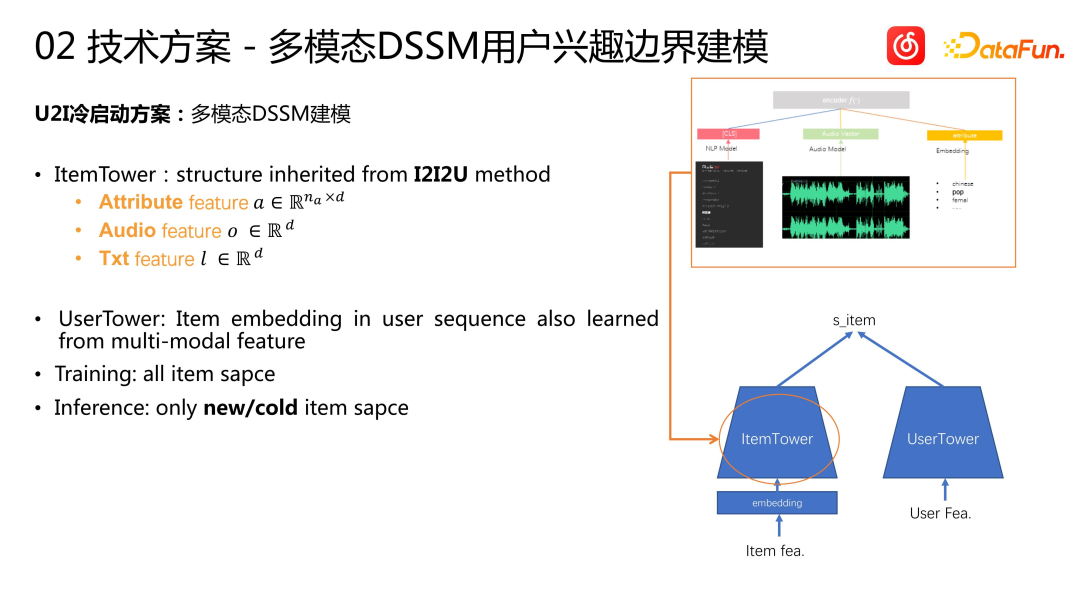
Skim permulaan sejuk U2I mengamalkan kaedah pemodelan DSSM berbilang modal. Model ini terdiri daripada ItemTower dan UserTower. Kami mewarisi ciri multimodal lagu sebelumnya ke dalam ItemTower, Menara Pengguna, mencipta Menara Pengguna biasa. Kami menjalankan pemodelan pembelajaran pelbagai mod bagi urutan pengguna Latihan model adalah berdasarkan ruang item penuh Sama ada lagu tidak popular atau popular, ia akan digunakan sebagai sampel untuk melatih model. Apabila membuat inferens, hanya membuat inferens tentang lagu baharu yang dilingkari atau kumpulan lagu yang tidak popular. Pendekatan ini serupa dengan beberapa penyelesaian dua menara sebelumnya: untuk item popular, bina satu menara, dan untuk item baharu atau tidak popular, bina menara lain untuk mengendalikannya. Walau bagaimanapun, kami mengendalikan item biasa dan item yang dimulakan dengan lebih bebas. Kami menggunakan model panggil balik biasa untuk item biasa, dan untuk item yang tidak popular, kami menggunakan model DSSM yang dibina khas
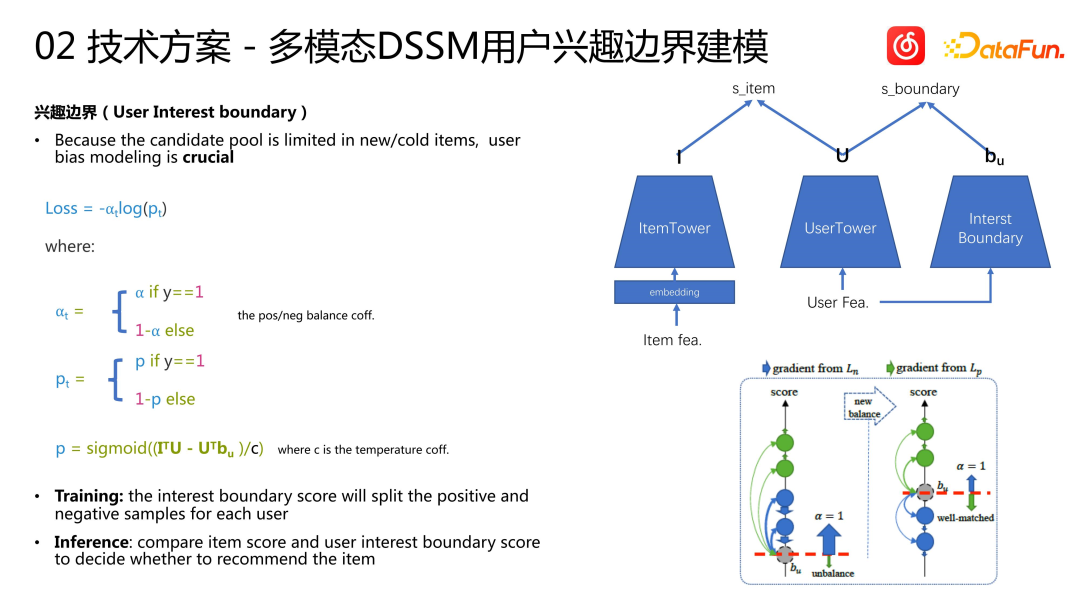
Oleh kerana model DSSM yang mula sejuk hanya digunakan untuk membuat alasan tentang lagu yang tidak popular atau baru, kami mendapati Modelling BIAS pengguna adalah sangat penting kerana kami tidak dapat menjamin bahawa semua pengguna akan menyukai item yang tidak popular atau baru. Set calon itu sendiri ialah kumpulan yang sangat besar, dan kami perlu memodelkan Item pengguna, kerana sesetengah pengguna mungkin lebih suka Item popular dan Item kegemarannya mungkin tiada daripada kumpulan cadangan. Oleh itu, berdasarkan kaedah tradisional, kami membina menara yang dipanggil "sempadan kepentingan" untuk memodelkan pilihan pengguna. Sempadan minat digunakan untuk memisahkan sampel positif dan negatif Semasa latihan, skor sempadan minat digunakan untuk membahagikan sampel positif dan negatif setiap pengguna semasa inferens, skor item dan skor sempadan minat pengguna dibandingkan untuk memutuskan sama ada mengesyorkan item tersebut. Semasa latihan, kami menggunakan vektor sempadan minat dan vektor minat pengguna untuk melakukan pengiraan produk dalaman untuk mendapatkan vektor perwakilan sempadan. Berdasarkan kehilangan dalam rajah di atas, entropi silang dua kelas tradisional digunakan untuk pemodelan. Sampel negatif akan meningkatkan sempadan minat pengguna, manakala sampel positif akan menurunkan sempadan minat pengguna Akhirnya, keadaan keseimbangan akan dicapai selepas latihan, dan sempadan minat pengguna akan memisahkan sampel positif dan negatif. Apabila digunakan dalam talian, kami memutuskan sama ada untuk mengesyorkan item yang tidak popular atau ekor panjang kepada pengguna berdasarkan sempadan minat pengguna.
3. Rumusan

Akhir sekali, buat rumusan. Kerja utama pemodelan permulaan sejuk berbilang mod yang disyorkan oleh Cloud Music termasuk:
- Dari segi ciri, rangka kerja pra-latihan CLIP digunakan untuk memodelkan pelbagai moditi.
- Dua skema pemodelan digunakan dalam skema pemodelan, pemodelan tidak langsung I2I2U dan pemodelan langsung DSSM multi-modal mula sejuk.
- Kerugian & Dari segi matlamat pembelajaran, BPR & pembelajaran kontrastif diperkenalkan di bahagian Item, dan sempadan minat di bahagian Pengguna meningkatkan pembelajaran Item dan pembelajaran pengguna yang tidak popular.
Terdapat dua arah utama untuk pengoptimuman masa hadapan. Arah pertama ialah pemodelan melalui gabungan pelbagai mod kandungan dan ciri tingkah laku. Arah kedua ialah pengoptimuman pautan penuh ingatan dan pengisihan
4. Sesi Soal Jawab
S1: Apakah petunjuk teras muzik mula sejuk?
A1: Kami akan memberi perhatian kepada banyak penunjuk, yang lebih penting ialah kadar kutipan dan kadar penyiapan = PV kutipan/PV yang dimainkan, kadar siap = PV yang dimainkan sepenuhnya.
S2: Adakah ciri berbilang modal dilatih atau dipraktikkan dari hujung ke hujung? Apabila menjana paparan perbandingan dalam langkah kedua, apakah ciri khusus input x?
A2: Penyelesaian yang kami gunakan pada masa ini ialah pra-latihan berdasarkan rangka kerja CLIP, dan menggunakan ciri berbilang modal yang diperolehi daripada pra-latihan untuk menyokong perkhidmatan panggil balik dan pengisihan hiliran. Proses pra-latihan kami dilakukan dalam dua peringkat dan bukannya latihan hujung ke hujung. Walaupun latihan hujung ke hujung mungkin lebih baik dalam teori, ia juga memerlukan keperluan mesin dan kos yang lebih tinggi. Oleh itu, kami memilih penyelesaian pra-latihan, yang juga disebabkan oleh pertimbangan kos
x mewakili ciri asal lagu, termasuk audio lagu, ciri multi-modal teks dan ciri tag seperti bahasa. dan genre. Ciri-ciri ini dikumpulkan dan tertakluk kepada dua penjelmaan rawak berbeza F’a dan F’’a untuk mendapatkan x’ dan x’’. f ialah pengekod, yang juga merupakan struktur tulang belakang model g ditambah pada kepala selepas output pengekod dan hanya digunakan untuk bahagian pembelajaran kontras
S3: Lapisan benam dan DNN bagi dua menara yang dipertingkatkan. semasa latihan pembelajaran kontras adalah kedua-duanya Adakah ia dikongsi? Mengapakah pembelajaran kontras berkesan untuk permulaan sejuk kandungan Adakah persampelan negatif khusus untuk kandungan permulaan bukan sejuk?
A3: Model sentiasa hanya mempunyai satu pengekod, iaitu satu menara, jadi tiada masalah perkongsian parameter
Mengenai mengapa ia membantu untuk item yang tidak popular, saya faham dengan cara ini, tidak ada perlu menjalankan beban tambahan pada item yang tidak popular Persampelan dan kerja lain. Malah, hanya mempelajari perwakilan pembenaman lagu berdasarkan pembelajaran terselia boleh membawa kepada berat sebelah, kerana data yang dipelajari adalah penapisan kolaboratif, yang akan membawa kepada masalah memihak kepada lagu-lagu popular, dan vektor pembenaman akhir juga akan menjadi berat sebelah. Dengan memperkenalkan mekanisme pembelajaran kontrastif dan kehilangan pembelajaran kontrastif dalam fungsi kehilangan akhir, bias pembelajaran data penapisan kolaboratif boleh diperbetulkan. Oleh itu, melalui pembelajaran kontrastif, pengedaran vektor dalam ruang boleh dipertingkatkan tanpa memerlukan pemprosesan tambahan item yang tidak popular
S4: Adakah terdapat pemodelan berbilang objektif di sempadan minat? Nampaknya tidak banyak. Bolehkah anda memperkenalkan dua kuantiti ⍺ dan p?
A4: Pemodelan DSSM berbilang modal mengandungi ItemTower dan UserTower, dan kemudian berdasarkan UserTower, kami memodelkan menara tambahan untuk ciri pengguna, dipanggil Menara Sempadan Minat. Setiap satu daripada tiga menara ini mengeluarkan vektor. Semasa latihan, kami melakukan produk dalam vektor item dan vektor pengguna untuk mendapatkan skor item, dan kemudian melakukan produk dalam vektor pengguna dan vektor sempadan minat pengguna untuk mewakili skor sempadan minat pengguna. Parameter ⍺ ialah parameter pemberat sampel konvensional yang digunakan untuk mengimbangi perkadaran sampel positif dan negatif yang menyumbang kepada kehilangan. p ialah skor akhir item, dikira dengan menolak skor produk dalaman vektor pengguna dan vektor sempadan minat pengguna daripada skor produk dalaman vektor item dan vektor pengguna, dan mengira skor akhir melalui fungsi sigmoid. Semasa proses pengiraan, sampel positif akan meningkatkan skor produk dalaman item dan pengguna, dan mengurangkan skor produk dalaman pengguna dan sempadan minat pengguna, manakala sampel negatif akan melakukan sebaliknya. Sebaik-baiknya, skor produk dalaman bagi sempadan minat pengguna dan pengguna boleh membezakan antara sampel positif dan negatif. Dalam peringkat pengesyoran dalam talian, kami menggunakan sempadan minat sebagai nilai rujukan untuk mengesyorkan item dengan skor yang lebih tinggi kepada pengguna, manakala item dengan skor yang lebih rendah tidak disyorkan. Jika pengguna hanya berminat dengan item yang popular, maka secara idealnya, skor sempadan pengguna, iaitu, produk dalaman vektor pengguna dan vektor sempadan minatnya, akan menjadi sangat tinggi, malah lebih tinggi daripada semua skor item permulaan sejuk , beberapa item permulaan sejuk tidak akan disyorkan kepada pengguna ini
S5: Apakah perbezaan struktur antara menara pengguna (userTower) dan menara sempadan minat Nampaknya inputnya sama?
A5: Input kedua-duanya memang sama, dan strukturnya serupa, tetapi parameter tidak dikongsi. Perbezaan terbesar hanya dalam pengiraan fungsi kerugian. Produk dalaman output menara pengguna dan output menara item dikira, dan skor item diperolehi. Hasil dalam keluaran menara sempadan faedah dan keluaran menara pengguna dikira, dan hasilnya ialah skor sempadan. Semasa latihan, kedua-duanya ditolak dan kemudian mengambil bahagian dalam pengiraan fungsi kehilangan binari Semasa inferens, saiz kedua-duanya dibandingkan untuk memutuskan sama ada untuk mengesyorkan item kepada pengguna
.Atas ialah kandungan terperinci Sistem pengesyoran untuk teknologi permulaan sejuk NetEase Cloud Music. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Cara melaksanakan sistem pengesyoran menggunakan bahasa Go dan Redis
Oct 27, 2023 pm 12:54 PM
Cara melaksanakan sistem pengesyoran menggunakan bahasa Go dan Redis
Oct 27, 2023 pm 12:54 PM
Cara menggunakan bahasa Go dan Redis untuk melaksanakan sistem pengesyoran Sistem pengesyoran merupakan bahagian penting platform Internet moden. Ia membantu pengguna menemui dan mendapatkan maklumat yang diminati. Bahasa Go dan Redis ialah dua alatan yang sangat popular yang boleh memainkan peranan penting dalam proses melaksanakan sistem pengesyoran. Artikel ini akan memperkenalkan cara menggunakan bahasa Go dan Redis untuk melaksanakan sistem pengesyoran mudah dan memberikan contoh kod khusus. Redis ialah pangkalan data dalam memori sumber terbuka yang menyediakan antara muka simpanan pasangan nilai kunci dan menyokong pelbagai data
 Algoritma dan aplikasi sistem pengesyoran dilaksanakan dalam Java
Jun 19, 2023 am 09:06 AM
Algoritma dan aplikasi sistem pengesyoran dilaksanakan dalam Java
Jun 19, 2023 am 09:06 AM
Dengan pembangunan berterusan dan mempopularkan teknologi Internet, sistem pengesyoran, sebagai teknologi penapisan maklumat yang penting, semakin digunakan dan diberi perhatian secara meluas. Dari segi pelaksanaan algoritma sistem pengesyoran, Java, sebagai bahasa pengaturcaraan yang pantas dan boleh dipercayai, telah digunakan secara meluas. Artikel ini akan memperkenalkan algoritma sistem pengesyoran dan aplikasi yang dilaksanakan dalam Java, dan menumpukan pada tiga algoritma sistem pengesyoran biasa: algoritma penapisan kolaboratif berasaskan pengguna, algoritma penapisan kolaboratif berasaskan item dan algoritma pengesyoran berasaskan kandungan. Algoritma penapisan kolaboratif berasaskan pengguna adalah berdasarkan penapisan kolaboratif berasaskan pengguna
 Contoh aplikasi: Gunakan go-micro untuk membina sistem pengesyoran perkhidmatan mikro
Jun 18, 2023 pm 12:43 PM
Contoh aplikasi: Gunakan go-micro untuk membina sistem pengesyoran perkhidmatan mikro
Jun 18, 2023 pm 12:43 PM
Dengan populariti aplikasi Internet, seni bina perkhidmatan mikro telah menjadi kaedah seni bina yang popular. Antaranya, kunci kepada seni bina perkhidmatan mikro adalah untuk memisahkan aplikasi kepada perkhidmatan yang berbeza dan berkomunikasi melalui RPC untuk mencapai seni bina perkhidmatan yang digandingkan secara longgar. Dalam artikel ini, kami akan memperkenalkan cara menggunakan go-micro untuk membina sistem pengesyoran perkhidmatan mikro berdasarkan kes sebenar. 1. Apakah sistem pengesyoran perkhidmatan mikro? Sistem pengesyoran perkhidmatan mikro ialah sistem pengesyoran berdasarkan seni bina perkhidmatan mikro Ia menyepadukan modul yang berbeza dalam sistem pengesyoran (seperti kejuruteraan ciri, pengelasan
 Rahsia Pengesyoran Tepat: Penjelasan Terperinci mengenai Model Pengingatan Tanpa Pinggir Adaptasi Domain Dipisahkan Alibaba
Jun 05, 2023 am 08:55 AM
Rahsia Pengesyoran Tepat: Penjelasan Terperinci mengenai Model Pengingatan Tanpa Pinggir Adaptasi Domain Dipisahkan Alibaba
Jun 05, 2023 am 08:55 AM
1. Pengenalan senario Mula-mula, mari kita perkenalkan senario yang terlibat dalam artikel ini—senario "barangan bagus tersedia". Lokasinya adalah dalam grid empat persegi pada laman utama Taobao, yang dibahagikan kepada halaman pemilihan satu lompatan dan halaman penerimaan dua lompatan. Terdapat dua bentuk utama halaman penerimaan, satu ialah halaman penerimaan imej dan teks, dan satu lagi ialah halaman penerimaan video pendek. Matlamat senario ini adalah terutamanya untuk menyediakan pengguna dengan barangan yang memuaskan dan memacu pertumbuhan GMV, seterusnya memanfaatkan bekalan pakar. 2. Apakah bias populariti, dan mengapa seterusnya kita masukkan fokus artikel ini, bias populariti. Apakah bias populariti? Mengapa bias populariti berlaku? 1. Apakah bias populariti? Bias populariti mempunyai banyak alias, seperti kesan Matthew dan ruang kepompong maklumat, ia adalah karnival produk letupan tinggi, lebih mudah ia didedahkan. Ini akan mengakibatkan
 Bagaimanakah bahasa Go melaksanakan sistem carian dan pengesyoran awan?
May 16, 2023 pm 11:21 PM
Bagaimanakah bahasa Go melaksanakan sistem carian dan pengesyoran awan?
May 16, 2023 pm 11:21 PM
Dengan pembangunan berterusan dan mempopularkan teknologi pengkomputeran awan, carian awan dan sistem pengesyoran menjadi semakin popular. Sebagai tindak balas kepada permintaan ini, bahasa Go juga menyediakan penyelesaian yang baik. Dalam bahasa Go, kami boleh menggunakan keupayaan pemprosesan serentak berkelajuan tinggi dan perpustakaan standard yang kaya untuk melaksanakan sistem carian dan pengesyoran awan yang cekap. Berikut akan memperkenalkan cara bahasa Go melaksanakan sistem sedemikian. 1. Cari di awan Pertama, kita perlu memahami postur dan prinsip carian. Postur carian merujuk kepada halaman padanan enjin carian berdasarkan kata kunci yang dimasukkan oleh pengguna.
 Sistem pengesyoran untuk teknologi permulaan sejuk NetEase Cloud Music
Nov 14, 2023 am 08:14 AM
Sistem pengesyoran untuk teknologi permulaan sejuk NetEase Cloud Music
Nov 14, 2023 am 08:14 AM
1. Latar belakang masalah: Keperluan dan kepentingan pemodelan permulaan sejuk Sebagai platform kandungan, Cloud Music mempunyai sejumlah besar kandungan baharu dalam talian setiap hari. Walaupun jumlah kandungan baharu pada platform muzik awan agak kecil berbanding dengan platform lain seperti video pendek, jumlah sebenar mungkin jauh melebihi imaginasi semua orang. Pada masa yang sama, kandungan muzik jauh berbeza daripada video pendek, berita dan cadangan produk. Kitaran hayat muzik menjangkau tempoh masa yang sangat lama, selalunya diukur dalam tahun. Sesetengah lagu mungkin meletup selepas tidak aktif selama berbulan-bulan atau bertahun-tahun, dan lagu-lagu klasik mungkin masih mempunyai daya hidup yang kuat walaupun selepas lebih daripada sepuluh tahun. Oleh itu, untuk sistem pengesyoran platform muzik, adalah lebih penting untuk menemui kandungan berkualiti tinggi yang tidak popular dan berekor panjang dan mengesyorkannya kepada pengguna yang betul daripada mengesyorkan kategori lain.
 Aplikasi kaedah pembetulan sebab dan akibat dalam senario pengesyoran Ant Marketing
Jan 13, 2024 pm 12:15 PM
Aplikasi kaedah pembetulan sebab dan akibat dalam senario pengesyoran Ant Marketing
Jan 13, 2024 pm 12:15 PM
1. Latar belakang pembetulan sebab dan akibat 1. Penyelewengan berlaku dalam sistem pengesyoran Model pengesyoran dilatih dengan mengumpul data untuk mengesyorkan item yang sesuai kepada pengguna. Apabila pengguna berinteraksi dengan item yang disyorkan, data yang dikumpul digunakan untuk terus melatih model, membentuk gelung tertutup. Walau bagaimanapun, mungkin terdapat pelbagai faktor yang mempengaruhi dalam gelung tertutup ini, mengakibatkan ralat. Sebab utama ralat ialah kebanyakan data yang digunakan untuk melatih model adalah data pemerhatian dan bukannya data latihan yang ideal, yang dipengaruhi oleh faktor seperti strategi pendedahan dan pemilihan pengguna. Intipati berat sebelah ini terletak pada perbezaan antara jangkaan anggaran risiko empirikal dan jangkaan anggaran risiko ideal sebenar. 2. Kecondongan biasa Terdapat tiga jenis utama bias biasa dalam sistem pemasaran pengesyoran: Kecondongan selektif: Ini disebabkan oleh akar pengguna
 Sistem pengesyoran dan teknologi penapisan kolaboratif dalam PHP
May 11, 2023 pm 12:21 PM
Sistem pengesyoran dan teknologi penapisan kolaboratif dalam PHP
May 11, 2023 pm 12:21 PM
Dengan perkembangan pesat Internet, sistem pengesyoran telah menjadi semakin penting. Sistem pengesyoran ialah algoritma yang digunakan untuk meramal item yang menarik minat pengguna. Dalam aplikasi Internet, sistem pengesyoran boleh memberikan cadangan dan pengesyoran yang diperibadikan, dengan itu meningkatkan kepuasan pengguna dan kadar penukaran. PHP ialah bahasa pengaturcaraan yang digunakan secara meluas dalam pembangunan web. Artikel ini akan meneroka sistem pengesyoran dan teknologi penapisan kolaboratif dalam PHP. Prinsip sistem pengesyoran Sistem pengesyoran bergantung pada algoritma pembelajaran mesin dan analisis data Ia menganalisis dan meramalkan kelakuan sejarah pengguna.
