
 Peranti teknologi
AI
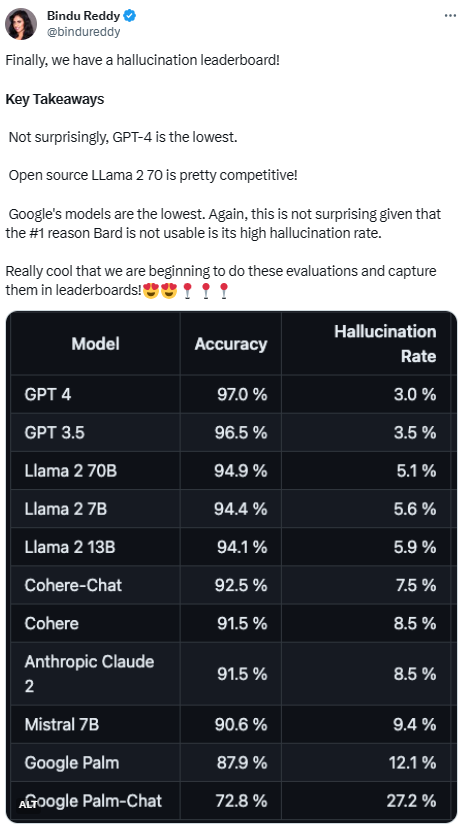
Kedudukan kadar halusinasi model besar: GPT-4 adalah yang paling rendah pada 3% dan Google Palm adalah setinggi 27.2%
Peranti teknologi
AI
Kedudukan kadar halusinasi model besar: GPT-4 adalah yang paling rendah pada 3% dan Google Palm adalah setinggi 27.2%
Kedudukan kadar halusinasi model besar: GPT-4 adalah yang paling rendah pada 3% dan Google Palm adalah setinggi 27.2%

Perkembangan kecerdasan buatan sedang berkembang pesat, tetapi masalah kerap berlaku. API penglihatan GPT baharu OpenAI sangat mengagumkan untuk bahagian hadapannya, tetapi ia juga sukar untuk dirungut kerana masalah halusinasinya.
Ilusi sentiasa menjadi kecacatan maut bagi model besar. Disebabkan oleh kerumitan set data, tidak dapat dielakkan bahawa akan terdapat maklumat yang lapuk dan salah, menyebabkan kualiti output menghadapi cabaran yang teruk. Terlalu banyak maklumat berulang juga boleh berat sebelah model besar, yang juga merupakan sejenis ilusi. Tetapi halusinasi bukanlah dalil yang tidak boleh dijawab. Semasa proses pembangunan, penggunaan set data yang teliti, penapisan yang ketat, pembinaan set data berkualiti tinggi, dan pengoptimuman struktur model dan kaedah latihan boleh mengurangkan masalah halusinasi pada tahap tertentu.
Terdapat banyak model berskala besar yang popular, sejauh manakah keberkesanannya dalam mengurangkan halusinasi? Berikut ialah kedudukan yang jelas membandingkan perbezaan mereka
Platform Vectara mengeluarkan ranking ini, yang memfokuskan pada kecerdasan buatan. Tarikh kemas kini ranking ialah 1 November 2023. Vectara menyatakan bahawa mereka akan terus membuat susulan terhadap penilaian halusinasi untuk mengemas kini kedudukan semasa model dikemas kini
Alamat projek: https://github.com /vectara /halusinasi-papan pendahulu
Untuk menentukan papan pendahulu ini, Vectara menjalankan kajian konsistensi fakta dan melatih model untuk mengesan halusinasi dalam output LLM. Mereka menggunakan model SOTA yang setanding dan menyediakan setiap LLM dengan 1,000 dokumen ringkas melalui API awam dan meminta mereka meringkaskan setiap dokumen menggunakan hanya fakta yang dibentangkan dalam dokumen itu. Antara 1000 dokumen ini, hanya 831 dokumen telah diringkaskan oleh setiap model, dan dokumen selebihnya telah ditolak oleh sekurang-kurangnya satu model kerana sekatan kandungan. Menggunakan 831 dokumen ini, Vectara mengira ketepatan keseluruhan dan kadar ilusi untuk setiap model. Kadar di mana setiap model enggan membalas gesaan diperincikan dalam lajur "Kadar Jawapan". Tiada kandungan yang dihantar kepada model mengandungi kandungan yang menyalahi undang-undang atau tidak selamat, tetapi mengandungi perkataan pencetus yang mencukupi untuk mencetuskan penapis kandungan tertentu. Dokumen ini terutamanya daripada CNN/Daily Mail corpus
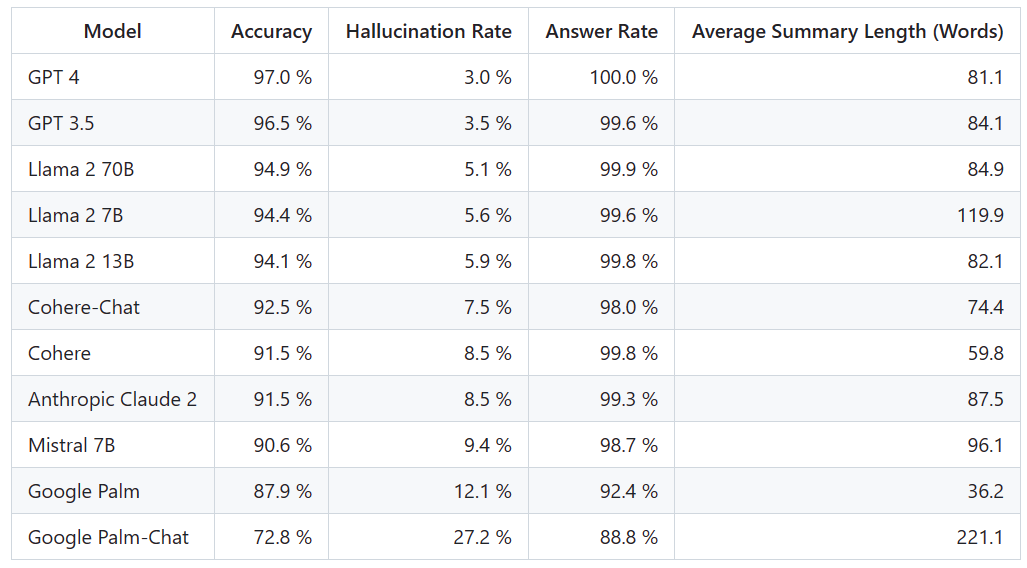
Adalah penting untuk ambil perhatian bahawa Vectara menilai ketepatan ringkasan, bukan ketepatan fakta keseluruhan. Ini membolehkan perbandingan tindak balas model terhadap maklumat yang diberikan. Dalam erti kata lain, apa yang dinilai ialah sama ada ringkasan output adalah "selaras dengan fakta" dengan dokumen sumber. Tanpa mengetahui data apa yang setiap LLM dilatih, menentukan halusinasi adalah mustahil untuk sebarang masalah tertentu. Tambahan pula, membina model yang boleh menentukan sama ada tindak balas adalah halusinasi tanpa sumber rujukan memerlukan menangani masalah halusinasi, dan memerlukan latihan model yang sama besar atau lebih besar daripada LLM yang dinilai. Oleh itu, Vectara memilih untuk melihat kadar halusinasi dalam tugasan ringkasan kerana analogi sedemikian adalah cara yang baik untuk menentukan realisme keseluruhan model.
Alamat pengesanan model halusinasi ialah: https://huggingface.co/vectara/hallucination_evaluation_model
Selain itu, semakin banyak LLM digunakan dalam saluran paip RAG (Retrieval Augmented Generation) untuk menjawab pertanyaan seperti Bing Chat dan integrasi Google Chat. Dalam sistem RAG, model ini digunakan sebagai agregator hasil carian, jadi papan pendahulu ini juga merupakan penunjuk yang baik bagi ketepatan model apabila digunakan dalam sistem RAG
Memandangkan prestasi GPT-4, ilusinya Kadar terendah nampaknya tidak mengejutkan. Namun, ada netizen berkata terkejut kerana tidak banyak perbezaan antara GPT-3.5 dan GPT-4

Selepas mengejar GPT-4 dan GPT-3.5, LLaMA 2 beraksi dengan baik. Walau bagaimanapun, prestasi model besar Google adalah tidak memuaskan. Sesetengah netizen berkata bahawa BARD Google sering menggunakan "Saya masih berlatih" untuk mengelakkan jawapan yang salah

Dengan senarai kedudukan sedemikian, kita boleh mempunyai pemahaman yang lebih intuitif tentang kelebihan dan kekurangan model yang berbeza . Beberapa hari lalu, OpenAI melancarkan GPT-4 Turbo Tidak, beberapa netizen segera mencadangkan untuk mengemas kini dalam ranking.

Kami akan tunggu dan lihat bagaimana kedudukan seterusnya dan sama ada akan berlaku sebarang perubahan besar.
Atas ialah kandungan terperinci Kedudukan kadar halusinasi model besar: GPT-4 adalah yang paling rendah pada 3% dan Google Palm adalah setinggi 27.2%. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1662
1662
 14
1419
52
1313
25
1262
29
1235
24
14
1419
52
1313
25
1262
29
1235
24

 Platform perdagangan mata wang teratas yang manakah di dunia adalah antara sepuluh platform perdagangan mata wang teratas pada tahun 2025
Apr 28, 2025 pm 08:12 PM
Platform perdagangan mata wang teratas yang manakah di dunia adalah antara sepuluh platform perdagangan mata wang teratas pada tahun 2025
Apr 28, 2025 pm 08:12 PM
Sepuluh pertukaran cryptocurrency teratas di dunia pada tahun 2025 termasuk Binance, OKX, Gate.io, Coinbase, Kraken, Huobi, Bitfinex, Kucoin, Bittrex dan Poloniex, yang semuanya dikenali dengan jumlah dan keselamatan perdagangan mereka yang tinggi.
 Berapa bernilai bitcoin
Apr 28, 2025 pm 07:42 PM
Berapa bernilai bitcoin
Apr 28, 2025 pm 07:42 PM
Harga Bitcoin berkisar antara $ 20,000 hingga $ 30,000. 1. Harga Bitcoin telah berubah secara dramatik sejak tahun 2009, mencapai hampir $ 20,000 pada tahun 2017 dan hampir $ 60,000 pada tahun 2021. Harga dipengaruhi oleh faktor -faktor seperti permintaan pasaran, bekalan, dan persekitaran makroekonomi. 3. Dapatkan harga masa nyata melalui pertukaran, aplikasi mudah alih dan laman web. 4. Harga Bitcoin sangat tidak menentu, didorong oleh sentimen pasaran dan faktor luaran. 5. Ia mempunyai hubungan tertentu dengan pasaran kewangan tradisional dan dipengaruhi oleh pasaran saham global, kekuatan dolar AS, dan sebagainya. 6. Trend jangka panjang adalah yakin, tetapi risiko perlu dinilai dengan berhati-hati.
 Decryption Gate.IO Strategy Upgrade: Bagaimana untuk mentakrifkan semula Pengurusan Aset Crypto di Memebox 2.0?
Apr 28, 2025 pm 03:33 PM
Decryption Gate.IO Strategy Upgrade: Bagaimana untuk mentakrifkan semula Pengurusan Aset Crypto di Memebox 2.0?
Apr 28, 2025 pm 03:33 PM
Memebox 2.0 mentakrifkan semula pengurusan aset crypto melalui seni bina yang inovatif dan kejayaan prestasi. 1) Ia menyelesaikan tiga titik kesakitan utama: silo aset, kerosakan pendapatan dan paradoks keselamatan dan kemudahan. 2) Melalui hab aset pintar, pengurusan risiko dinamik dan enjin peningkatan pulangan, kelajuan pemindahan rantaian, kadar hasil purata dan kelajuan tindak balas insiden keselamatan diperbaiki. 3) Menyediakan pengguna dengan visualisasi aset, automasi dasar dan integrasi tadbir urus, merealisasikan pembinaan semula nilai pengguna. 4) Melalui kerjasama ekologi dan inovasi pematuhan, keberkesanan keseluruhan platform telah dipertingkatkan. 5) Pada masa akan datang, kolam insurans kontrak pintar, ramalan integrasi pasaran dan peruntukan aset yang didorong AI akan dilancarkan untuk terus memimpin pembangunan industri.
 Platform perdagangan mata wang teratas yang manakah di dunia adalah versi terbaru dari Platform Perdagangan Top Top Top
Apr 28, 2025 pm 08:09 PM
Platform perdagangan mata wang teratas yang manakah di dunia adalah versi terbaru dari Platform Perdagangan Top Top Top
Apr 28, 2025 pm 08:09 PM
Sepuluh platform perdagangan cryptocurrency teratas di dunia termasuk Binance, OKX, Gate.io, Coinbase, Kraken, Huobi Global, Bitfinex, Bittrex, Kucoin dan Poloniex, yang semuanya menyediakan pelbagai kaedah perdagangan dan langkah -langkah keselamatan yang kuat.
 Apakah platform perdagangan mata wang teratas? 10 pertukaran mata wang maya terkini
Apr 28, 2025 pm 08:06 PM
Apakah platform perdagangan mata wang teratas? 10 pertukaran mata wang maya terkini
Apr 28, 2025 pm 08:06 PM
Saat ini disenaraikan di antara sepuluh mata wang mata wang maya yang teratas: 1. Binance, 2 Okx, 3. Gate.io, 4. Perpustakaan duit syiling, 5. Siren, 6. Huobi Global Station, 7. Bybit, 8. Kucoin, 9.
 Apakah sepuluh aplikasi perdagangan mata wang maya teratas? Kedudukan pertukaran mata wang digital terkini
Apr 28, 2025 pm 08:03 PM
Apakah sepuluh aplikasi perdagangan mata wang maya teratas? Kedudukan pertukaran mata wang digital terkini
Apr 28, 2025 pm 08:03 PM
Sepuluh pertukaran mata wang digital teratas seperti Binance, OKX, Gate.io telah meningkatkan sistem mereka, urus niaga yang pelbagai dan langkah -langkah keselamatan yang ketat.
 Bagaimana cara menggunakan Perpustakaan Chrono di C?
Apr 28, 2025 pm 10:18 PM
Bagaimana cara menggunakan Perpustakaan Chrono di C?
Apr 28, 2025 pm 10:18 PM
Menggunakan perpustakaan Chrono di C membolehkan anda mengawal selang masa dan masa dengan lebih tepat. Mari kita meneroka pesona perpustakaan ini. Perpustakaan Chrono C adalah sebahagian daripada Perpustakaan Standard, yang menyediakan cara moden untuk menangani selang waktu dan masa. Bagi pengaturcara yang telah menderita dari masa. H dan CTime, Chrono tidak diragukan lagi. Ia bukan sahaja meningkatkan kebolehbacaan dan mengekalkan kod, tetapi juga memberikan ketepatan dan fleksibiliti yang lebih tinggi. Mari kita mulakan dengan asas -asas. Perpustakaan Chrono terutamanya termasuk komponen utama berikut: STD :: Chrono :: System_Clock: Mewakili jam sistem, yang digunakan untuk mendapatkan masa semasa. Std :: Chron
 Bagaimana untuk mengendalikan paparan DPI yang tinggi di C?
Apr 28, 2025 pm 09:57 PM
Bagaimana untuk mengendalikan paparan DPI yang tinggi di C?
Apr 28, 2025 pm 09:57 PM
Mengendalikan paparan DPI yang tinggi di C boleh dicapai melalui langkah -langkah berikut: 1) Memahami DPI dan skala, gunakan API Sistem Operasi untuk mendapatkan maklumat DPI dan menyesuaikan output grafik; 2) Mengendalikan keserasian silang platform, gunakan perpustakaan grafik silang platform seperti SDL atau QT; 3) Melaksanakan pengoptimuman prestasi, meningkatkan prestasi melalui cache, pecutan perkakasan, dan pelarasan dinamik tahap butiran; 4) Selesaikan masalah biasa, seperti teks kabur dan elemen antara muka terlalu kecil, dan selesaikan dengan betul menggunakan skala DPI.
