
 Peranti teknologi
AI
Satu helah untuk membezakan model penipuan berskala besar, sumber terbuka AI matematik 'cermin syaitan' abang doktor
Peranti teknologi
AI
Satu helah untuk membezakan model penipuan berskala besar, sumber terbuka AI matematik 'cermin syaitan' abang doktor
Satu helah untuk membezakan model penipuan berskala besar, sumber terbuka AI matematik 'cermin syaitan' abang doktor
Nov 17, 2023 pm 12:38 PMKini, ramai model besar yang mengaku mahir dalam matematik, Siapa yang mempunyai bakat sebenar? Siapa yang "menipu" pada soalan ujian belakang ke belakang?
Tahun ini, seseorang menjalankan ujian komprehensif terhadap soalan yang baru diumumkan untuk Peperiksaan Akhir Matematik Kebangsaan Hungary
Banyak model sekaligus# 🎜 🎜#"Dedahkan bentuk sebenar anda".
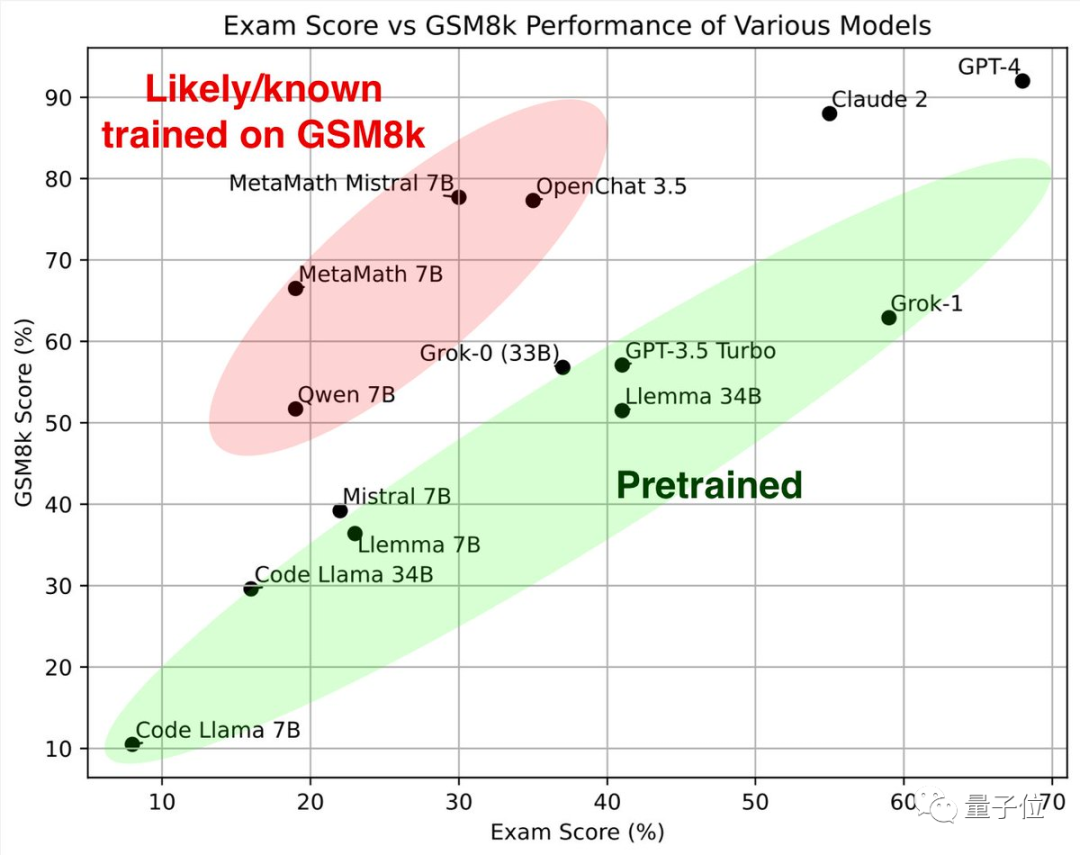
Lihat duluBahagian hijau, model besar ini diuji pada matematik klasik dan set GSM8k kertas baharu Keputusan yang dicapai adalah serupa, dan bersama-sama membentuk standard rujukan .
Melihat bahagian merah lagi, keputusan pada GSM8K adalah jauh lebih tinggi daripada model besar dengan model yang sama skala parameter,# 🎜 🎜#Sebaik sahaja saya mendapat kertas baharu, markah saya menurun dengan ketara, yang hampir sama dengan model besar dengan saiz yang sama. Para penyelidik mengklasifikasikan mereka sebagai
"disyaki atau diketahui telah dilatih menggunakan GSM8k" . Sesetengah orang melihat ujian ini dan berkata bahawa mereka harus mula menilai soalan yang mereka tidak pernah lihat sebelum ini
 Ada yang percaya bahawa ujian jenis ini, dan pengalaman semua orang dengan penggunaan sebenar model besar, adalah satu-satunya kaedah penilaian yang boleh dipercayai pada masa ini Untuk GPT-4, sumber terbuka Llemma telah mencapai keputusan yang cemerlang
Ada yang percaya bahawa ujian jenis ini, dan pengalaman semua orang dengan penggunaan sebenar model besar, adalah satu-satunya kaedah penilaian yang boleh dipercayai pada masa ini Untuk GPT-4, sumber terbuka Llemma telah mencapai keputusan yang cemerlang
tester
.Keiran Paster
Biar model besar mengambil peperiksaan akhir matematik sekolah menengah kebangsaan Hungary Helah ini datang daripada xAI#🎜 Musk. 🎜#
. Untuk menolak masalah bahawa model besar Grok xAI secara tidak sengaja telah melihat soalan ujian dalam data rangkaian, sebagai tambahan kepada beberapa set ujian biasa, ujian ini juga dijalankan
Untuk menolak masalah bahawa model besar Grok xAI secara tidak sengaja telah melihat soalan ujian dalam data rangkaian, sebagai tambahan kepada beberapa set ujian biasa, ujian ini juga dijalankan
Apabila xAI dikeluarkan, ia turut mengumumkan keputusan GPT-3.5, GPT-4 dan Claude 2 sebagai perbandingan.
Berdasarkan set data ini, Paster menjalankan ujian selanjutnya, dan objek ujian ialah berbilang model sumber terbuka dengan keupayaan matematik yang kukuh#🎜 🎜## 🎜🎜#Dan soalan ujian, skrip ujian dan keputusan jawapan setiap model adalah
#🎜🎜🎜# sumber terbuka pada Huggingface untuk semua orang menyemak dan menguji model lain.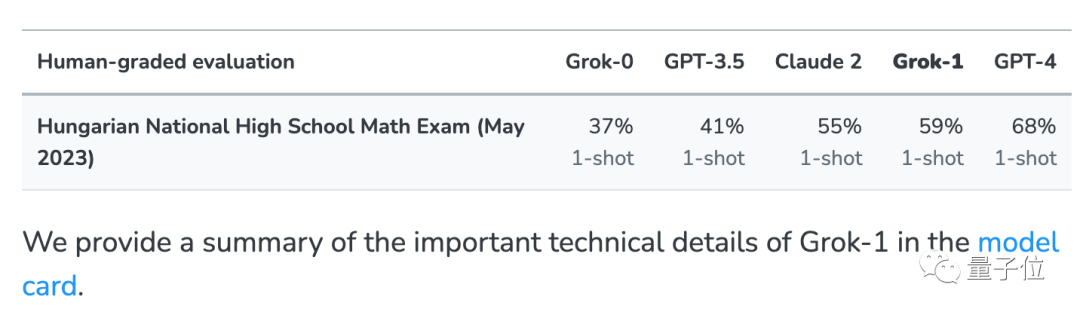
Seterusnya, Musk xAI's Grok-0 (33B) dan Grok-1 (skala parameter yang tidak diumumkan)
kedua-duanya berprestasi baik .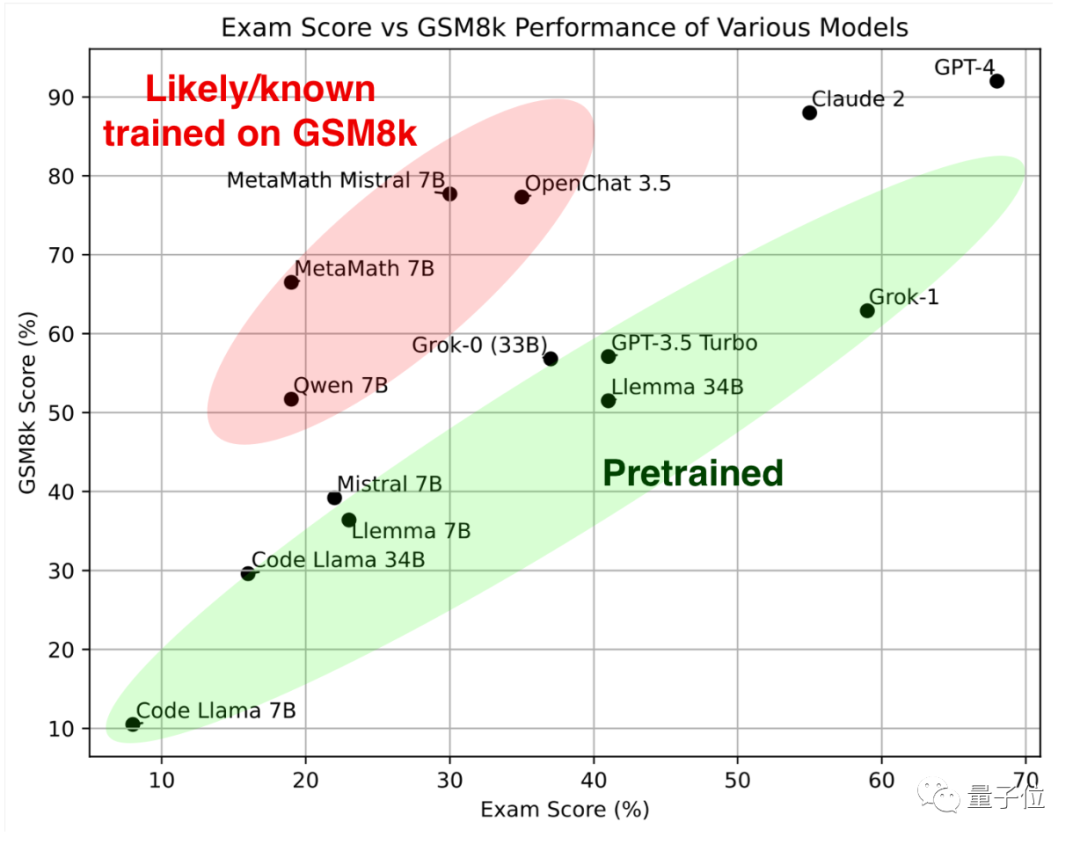
Grok-1 mempunyai markah tertinggi dalam "kumpulan tidak menipu", dan markah kertas baharu lebih tinggi daripada Claude 2.
#🎜🎜Prestasi #Grok-0 pada GSM8k hampir kepada GPT3.5-Turbo, dan lebih teruk sedikit pada kertas baharu.Kecuali model tertutup yang disebutkan di atas, model lain dalam ujian semuanya adalah sumber terbuka
Kod Llama Series# . .
Atas dasar Kod Llama, banyak universiti dan institusi penyelidikan secara bersama melancarkan Llemma siri #🎜🎜 🎜#, dan sumber terbuka oleh EleutherAI.Pasukan mengumpul set data Proof-Pile-2 daripada kertas saintifik, data rangkaian yang mengandungi matematik dan kod matematik Selepas latihan, Llemma boleh menggunakan alatan dan melakukan pembuktian teorem formal tanpa sebarang penalaan lebih lanjut. . Pada kertas baharu, prestasi Llemma 34B hampir dengan tahap GPT-3.5 Turbo

Siri Mistral dilatih oleh Unicorn AI Perancis Mistral AI Perjanjian sumber terbuka Apache2.0 lebih longgar daripada Llama dan telah menjadi model asas paling popular dalam komuniti sumber terbuka selepas keluarga alpaca.
"Overfitting Group" OpenChat 3.5 dan MetaMath Mistral adalah kedua-duanya berasaskan Mi-tuned ecosystem
MetaMath dan MAmmoTH Code adalah berdasarkan ekosistem Code Llama.
Mereka yang memilih untuk menggunakan model sumber terbuka yang besar dalam perniagaan sebenar perlu berhati-hati untuk mengelakkan kumpulan ini, kerana mereka mungkin menunjukkan prestasi yang baik hanya untuk mendapatkan kedudukan, tetapi keupayaan sebenar mereka mungkin tidak sekuat model lain yang sama skala

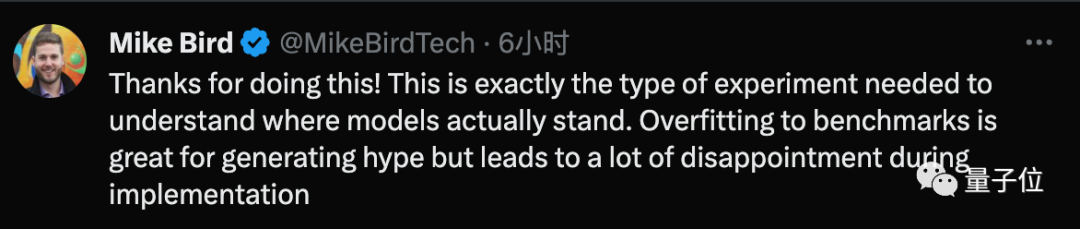
Tidak Ramai netizen menyatakan rasa terima kasih mereka kepada Paster untuk eksperimen ini, percaya bahawa ini adalah perkara yang diperlukan untuk memahami situasi sebenar model itu.
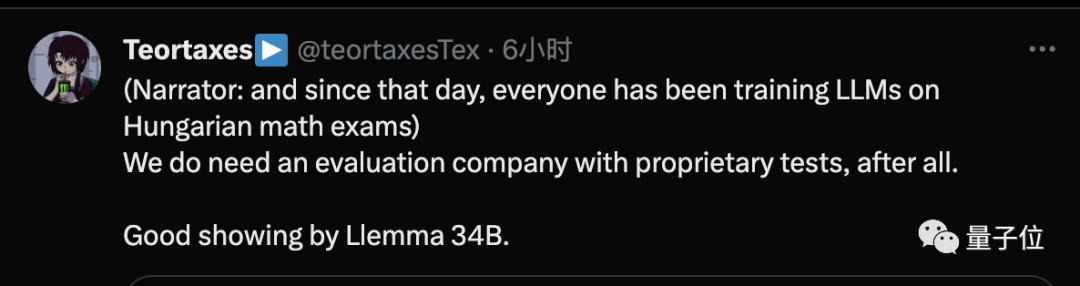
Sesetengah orang telah menyatakan kebimbangan:
Mulai hari ini, semua orang yang melatih model besar akan memasukkan soalan peperiksaan matematik Hungary dari tahun-tahun sebelumnya.
Pada masa yang sama, dia percaya bahawa penyelesaiannya mungkin mempunyai syarikat penilaian model besar yang khusus dengan ujian proprietari.
Satu lagi cadangan ialah mewujudkan penanda aras ujian yang dikemas kini tahun demi tahun untuk mengurangkan masalah overfitting.

Atas ialah kandungan terperinci Satu helah untuk membezakan model penipuan berskala besar, sumber terbuka AI matematik 'cermin syaitan' abang doktor. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Artikel Panas

Alat panas Tag

Artikel Panas

Tag artikel panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Di belakang akses Android pertama ke DeepSeek: Melihat Kekuatan Wanita
Mar 12, 2025 pm 12:27 PM
Di belakang akses Android pertama ke DeepSeek: Melihat Kekuatan Wanita
Mar 12, 2025 pm 12:27 PM
Di belakang akses Android pertama ke DeepSeek: Melihat Kekuatan Wanita

 Kedudukan terbaru dari sepuluh aplikasi perdagangan teratas pada tahun 2025
Mar 11, 2025 pm 04:06 PM
Kedudukan terbaru dari sepuluh aplikasi perdagangan teratas pada tahun 2025
Mar 11, 2025 pm 04:06 PM
Kedudukan terbaru dari sepuluh aplikasi perdagangan teratas pada tahun 2025
 Cara menyelesaikan masalah pelayan yang sibuk untuk DeepSeek
Mar 12, 2025 pm 01:39 PM
Cara menyelesaikan masalah pelayan yang sibuk untuk DeepSeek
Mar 12, 2025 pm 01:39 PM
Cara menyelesaikan masalah pelayan yang sibuk untuk DeepSeek
 Pintu Laman Web Rasmi DeepSeek yang mendalam
Mar 12, 2025 pm 01:33 PM
Pintu Laman Web Rasmi DeepSeek yang mendalam
Mar 12, 2025 pm 01:33 PM
Pintu Laman Web Rasmi DeepSeek yang mendalam
 Satu lagi produk kebangsaan dari Baidu disambungkan ke Deepseek.
Mar 12, 2025 pm 01:48 PM
Satu lagi produk kebangsaan dari Baidu disambungkan ke Deepseek.
Mar 12, 2025 pm 01:48 PM
Satu lagi produk kebangsaan dari Baidu disambungkan ke Deepseek.
 Top 10 Disyorkan untuk App Perdagangan Aset Digital Crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 Disyorkan untuk App Perdagangan Aset Digital Crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 Disyorkan untuk App Perdagangan Aset Digital Crypto (2025 Global Ranking)
 Midea melancarkan penghawa dingin DeepSeek yang pertama: Interaksi Suara AI boleh mencapai 400,000 arahan!
Mar 12, 2025 pm 12:18 PM
Midea melancarkan penghawa dingin DeepSeek yang pertama: Interaksi Suara AI boleh mencapai 400,000 arahan!
Mar 12, 2025 pm 12:18 PM
Midea melancarkan penghawa dingin DeepSeek yang pertama: Interaksi Suara AI boleh mencapai 400,000 arahan!
