
 Peranti teknologi
AI
Langkah baharu ke arah penjanaan imej berkualiti tinggi: kaedah pensampelan ultra pantas UFOGen Google
Peranti teknologi
AI
Langkah baharu ke arah penjanaan imej berkualiti tinggi: kaedah pensampelan ultra pantas UFOGen Google
Langkah baharu ke arah penjanaan imej berkualiti tinggi: kaedah pensampelan ultra pantas UFOGen Google

Pada tahun lalu, satu siri model penyebaran graf Vincentian yang diwakili oleh Stable Diffusion telah mengubah sepenuhnya bidang penciptaan visual. Banyak pengguna telah meningkatkan produktiviti mereka dengan imej yang dihasilkan oleh model penyebaran. Walau bagaimanapun, kelajuan penjanaan model penyebaran adalah masalah biasa. Oleh kerana model denoising bergantung pada denoising berbilang langkah untuk menukar hingar Gaussian awal secara beransur-ansur menjadi imej, ia memerlukan berbilang pengiraan rangkaian, menghasilkan kelajuan penjanaan yang sangat perlahan. Ini menjadikan model penyebaran graf Vincentian berskala besar sangat tidak mesra kepada sesetengah aplikasi yang memfokuskan pada masa nyata dan interaktiviti. Dengan pengenalan satu siri teknologi, bilangan langkah yang diperlukan untuk mengambil sampel daripada model penyebaran telah meningkat daripada beberapa ratus langkah awal kepada berpuluh-puluh langkah, atau bahkan hanya 4-8 langkah.
Baru-baru ini, pasukan penyelidik daripada Google mencadangkan model UFOGen, satu varian model resapan yang boleh mencuba dengan sangat cepat. Dengan memperhalusi Stable Diffusion dengan kaedah yang dicadangkan dalam kertas, UFOGen boleh menjana imej berkualiti tinggi dalam satu langkah sahaja. Pada masa yang sama, aplikasi hiliran Stable Diffusion, seperti penjanaan graf, ControlNet dan keupayaan lain, juga boleh dikekalkan.

Sila klik pautan berikut untuk melihat kertas kerja: https://arxiv.org/abs/2311.09257
Seperti yang anda lihat dari gambar di bawah, UFO,Gen boleh menjana kualiti tinggi imej dalam satu langkah sahaja.

Meningkatkan kelajuan penjanaan model resapan bukanlah hala tuju penyelidikan baharu. Penyelidikan terdahulu dalam bidang ini tertumpu terutamanya pada dua arah. Satu arah adalah untuk mereka bentuk kaedah pengiraan berangka yang lebih cekap,supaya mencapai tujuan menyelesaikan pensampelan ODE model resapan menggunakan langkah diskret yang lebih sedikit. Contohnya, siri penyelesai berangka DPM yang dicadangkan oleh pasukan Zhu Jun di Universiti Tsinghua telah disahkan sangat berkesan dalam Resapan Stabil, dan boleh mengurangkan dengan ketara bilangan langkah penyelesaian daripada 50 langkah lalai DDIM kepada kurang daripada 20 langkah. Arahan lain ialah menggunakan kaedah penyulingan pengetahuan untuk memampatkan laluan pensampelan berasaskan ODE model kepada bilangan langkah yang lebih kecil. Contoh ke arah ini ialah penyulingan Berpandu, salah satu calon kertas terbaik di CVPR2023, dan Model Ketekalan Terpendam (LCM) yang popular baru-baru ini. LCM, khususnya, boleh mengurangkan bilangan langkah pensampelan kepada hanya 4 dengan menyuling sasaran ketekalan, yang telah melahirkan banyak aplikasi penjanaan masa nyata.
Walau bagaimanapun, pasukan penyelidik Google tidak mengikut arahan umum di atas dalam model UFOGen, tetapi mengambil pendekatan berbeza dan menggunakan idea model hibrid model difusi dan GAN yang dicadangkan lebih setahun lalu. Mereka percaya bahawa pensampelan dan penyulingan berasaskan ODE yang dinyatakan di atas mempunyai had asasnya, dan sukar untuk memampatkan bilangan langkah pensampelan kepada had. Oleh itu, jika anda ingin mencapai matlamat generasi satu langkah, anda perlu membuka idea baharu.
Model hibrid merujuk kepada kaedah yang menggabungkan model resapan dan rangkaian musuh generatif (GAN). Kaedah ini pertama kali dicadangkan oleh pasukan penyelidik NVIDIA di ICLR 2022 dan dipanggil DDGAN ("Menggunakan Denoising Diffusion GAN untuk Menyelesaikan Tiga Masalah dalam Pembelajaran Generatif"). DDGAN diilhamkan oleh kelemahan model resapan biasa yang membuat andaian Gaussian tentang pengagihan pengurangan hingar. Ringkasnya, model resapan mengandaikan bahawa taburan denosing (taburan bersyarat yang, diberikan sampel bising, menghasilkan sampel yang kurang bising) ialah taburan Gaussian yang mudah. Walau bagaimanapun, teori persamaan pembezaan stokastik membuktikan bahawa andaian sedemikian hanya berlaku apabila saiz langkah pengurangan hingar menghampiri 0. Oleh itu, model resapan memerlukan sejumlah besar langkah denoising berulang untuk memastikan saiz langkah denoising yang kecil, menghasilkan kelajuan penjanaan yang perlahan DDGAN mencadangkan untuk meninggalkan andaian Gaussian bagi pengedaran denoising dan sebaliknya menggunakan GAN bersyarat untuk mensimulasikannya. Pengagihan pengurangan hingar ini. Oleh kerana GAN mempunyai keupayaan perwakilan yang sangat kuat dan boleh mensimulasikan pengedaran kompleks, saiz langkah pengurangan hingar yang lebih besar boleh digunakan untuk mengurangkan bilangan langkah. Walau bagaimanapun, DDGAN menukar matlamat latihan pembinaan semula yang stabil bagi model resapan kepada matlamat latihan GAN, yang boleh menyebabkan ketidakstabilan latihan dengan mudah dan menyukarkan untuk melanjutkan kepada tugas yang lebih kompleks. Di NeurIPS 2023, pasukan penyelidik Google yang sama yang mencipta UGOGen mencadangkan SIDDM (tajuk kertas Semi-Implicit Denoising Diffusion Models), yang memperkenalkan semula fungsi objektif pembinaan semula ke dalam objektif latihan DDGAN, meningkatkan kestabilan latihan dan kualiti penjanaan Semua meningkat dengan ketara berbanding DDGAN.
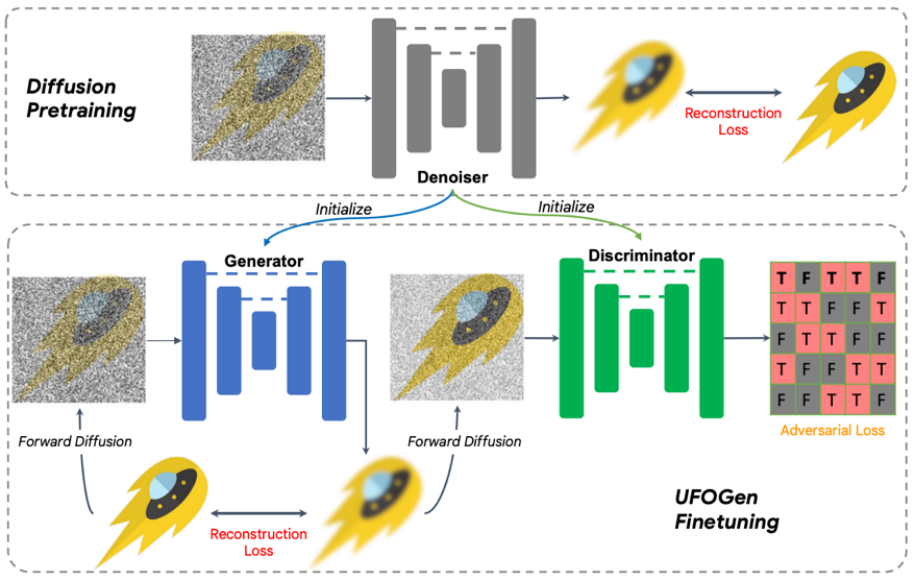
SIDDM, sebagai pendahulu UFOGen, boleh menjana imej berkualiti tinggi pada CIFAR-10, ImageNet dan set data penyelidikan lain dalam hanya 4 langkah. Tetapi SIDDM mempunyai dua masalah yang perlu diselesaikan: pertama, ia tidak boleh mencapai penjanaan satu langkah keadaan ideal kedua, ia tidak mudah untuk memanjangkannya ke bidang graf Vincentian yang lebih prihatin. Untuk tujuan ini, pasukan penyelidik Google mencadangkan UFOGen untuk menyelesaikan dua masalah ini. Khususnya, untuk soalan satu, melalui analisis matematik mudah, pasukan mendapati bahawa dengan menukar kaedah parameterisasi penjana dan menukar kaedah pengiraan fungsi kehilangan pembinaan semula, model teori boleh dijana dalam satu langkah. Untuk soalan dua, pasukan mencadangkan untuk menggunakan model Stable Diffusion sedia ada untuk permulaan bagi membolehkan model UFOGen dikembangkan kepada tugas rajah Vincent dengan lebih pantas dan lebih baik. Perlu diingat bahawa SIDDM telah mencadangkan bahawa kedua-dua penjana dan diskriminasi mengguna pakai seni bina UNet Oleh itu, berdasarkan reka bentuk ini, penjana dan diskriminator UFOGen dimulakan oleh model Stable Diffusion. Melakukannya memanfaatkan sepenuhnya maklumat dalaman Stable Diffusion, terutamanya tentang hubungan antara imej dan teks. Maklumat sebegini sukar diperoleh melalui pembelajaran lawan. Algoritma latihan dan gambar rajah ditunjukkan di bawah. Perlu diperhatikan bahawa terdapat beberapa kerja sebelum ini menggunakan GAN untuk membuat graf Vincentian, seperti NVIDIA's StyleGAN-T dan Adobe's GigaGAN, yang telah mengembangkan seni bina asas StyleGAN kepada saiz yang lebih besar . skala, supaya gambar boleh dibuat dalam satu langkah. Pengarang UFOGen menegaskan bahawa berbanding dengan kerja berasaskan GAN sebelumnya, sebagai tambahan kepada kualiti penjanaan, UFOGen mempunyai beberapa kelebihan: Kandungan yang ditulis semula: 1. Dalam tugas graf Vincentian, latihan rangkaian adversarial generatif tulen (GAN) adalah sangat tidak stabil. Diskriminasi bukan sahaja perlu menilai tekstur imej, tetapi juga perlu memahami tahap padanan antara imej dan teks, yang merupakan tugas yang sangat sukar, terutamanya pada peringkat awal latihan. Oleh itu, model GAN terdahulu, seperti GigaGAN, memperkenalkan sejumlah besar kerugian tambahan untuk membantu latihan, yang menjadikan latihan dan pelarasan parameter amat sukar. Walau bagaimanapun, UFOGen menjadikan GAN memainkan peranan tambahan dalam hal ini dengan memperkenalkan kerugian pembinaan semula, dengan itu mencapai latihan yang sangat stabil 2 Latihan GAN secara langsung bukan sahaja tidak stabil tetapi juga sangat mahal, terutamanya pada graf Vincent sejumlah besar data dan langkah latihan. Oleh kerana dua set parameter perlu dikemas kini pada masa yang sama, latihan GAN menggunakan lebih banyak masa dan memori daripada model resapan. Reka bentuk inovatif UFOGen boleh memulakan parameter daripada Stable Diffusion, dengan sangat menjimatkan masa latihan. Biasanya penumpuan hanya memerlukan puluhan ribu langkah latihan. 3 Salah satu daya tarikan model penyebaran graf Vincent ialah ia boleh digunakan untuk tugasan lain, termasuk aplikasi yang tidak memerlukan penalaan halus seperti graf graf, dan aplikasi yang sudah memerlukan penalaan halus seperti. generasi terkawal. Model GAN sebelum ini sukar untuk dipertingkatkan kepada tugas hiliran ini kerana penalaan halus GAN adalah sukar. Sebaliknya, UFOGen mempunyai rangka kerja model penyebaran dan oleh itu boleh digunakan dengan lebih mudah untuk tugas-tugas ini. Rajah di bawah menunjukkan graf penjanaan graf UFOGen dan contoh penjanaan boleh dikawal Ambil perhatian bahawa penjanaan ini hanya memerlukan satu langkah persampelan. Percubaan telah menunjukkan bahawa UFOGen boleh menjana imej berkualiti tinggi yang sepadan dengan penerangan teks dalam hanya satu langkah pensampelan. Berbanding dengan kaedah pensampelan berkelajuan tinggi yang dicadangkan baru-baru ini untuk model resapan (seperti Instaflow dan LCM), UFOGen menunjukkan daya saing yang kukuh. Malah berbanding dengan Resapan Stabil, yang memerlukan 50 langkah persampelan, sampel yang dihasilkan oleh UFOGen tidaklah lebih rendah dari segi rupa. Berikut ialah beberapa hasil perbandingan: Pasukan Google mencadangkan model berkuasa yang dipanggil UFOGen, yang dilaksanakan dengan menambah baik model penyebaran sedia ada dan model hibrid GAN. Model ini diperhalusi oleh Stable Diffusion, dan sambil memastikan keupayaan untuk menjana graf dalam satu langkah, ia juga sesuai untuk aplikasi hiliran yang berbeza. Sebagai salah satu kerja awal untuk mencapai sintesis teks-ke-imej yang sangat pantas, UFOGen telah membuka laluan baharu dalam bidang model generatif berkecekapan tinggi


Ringkasan
Atas ialah kandungan terperinci Langkah baharu ke arah penjanaan imej berkualiti tinggi: kaedah pensampelan ultra pantas UFOGen Google. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 phpmyadmin mencipta jadual data
Apr 10, 2025 pm 11:00 PM
phpmyadmin mencipta jadual data
Apr 10, 2025 pm 11:00 PM
Untuk membuat jadual data menggunakan phpmyadmin, langkah -langkah berikut adalah penting: Sambungkan ke pangkalan data dan klik tab baru. Namakan jadual dan pilih enjin penyimpanan (disyorkan innoDB). Tambah butiran lajur dengan mengklik butang Tambah Lajur, termasuk nama lajur, jenis data, sama ada untuk membenarkan nilai null, dan sifat lain. Pilih satu atau lebih lajur sebagai kunci utama. Klik butang Simpan untuk membuat jadual dan lajur.
 Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:33 PM
Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:33 PM
Mewujudkan pangkalan data Oracle tidak mudah, anda perlu memahami mekanisme asas. 1. Anda perlu memahami konsep pangkalan data dan Oracle DBMS; 2. Menguasai konsep teras seperti SID, CDB (pangkalan data kontena), PDB (pangkalan data pluggable); 3. Gunakan SQL*Plus untuk membuat CDB, dan kemudian buat PDB, anda perlu menentukan parameter seperti saiz, bilangan fail data, dan laluan; 4. Aplikasi lanjutan perlu menyesuaikan set aksara, memori dan parameter lain, dan melakukan penalaan prestasi; 5. Beri perhatian kepada ruang cakera, keizinan dan parameter, dan terus memantau dan mengoptimumkan prestasi pangkalan data. Hanya dengan menguasai ia dengan mahir memerlukan amalan yang berterusan, anda boleh benar -benar memahami penciptaan dan pengurusan pangkalan data Oracle.
 Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:36 PM
Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:36 PM
Untuk membuat pangkalan data Oracle, kaedah biasa adalah menggunakan alat grafik DBCA. Langkah -langkah adalah seperti berikut: 1. Gunakan alat DBCA untuk menetapkan DBName untuk menentukan nama pangkalan data; 2. Tetapkan SYSPASSWORD dan SYSTEMPASSWORD kepada kata laluan yang kuat; 3. Tetapkan aksara dan NationalCharacterset ke Al32utf8; 4. Tetapkan MemorySize dan Tablespacesize untuk menyesuaikan mengikut keperluan sebenar; 5. Tentukan laluan logfile. Kaedah lanjutan dibuat secara manual menggunakan arahan SQL, tetapi lebih kompleks dan terdedah kepada kesilapan. Perhatikan kekuatan kata laluan, pemilihan set aksara, saiz dan memori meja makan
 Cara Menulis Penyataan Pangkalan Data Oracle
Apr 11, 2025 pm 02:42 PM
Cara Menulis Penyataan Pangkalan Data Oracle
Apr 11, 2025 pm 02:42 PM
Inti dari pernyataan Oracle SQL adalah pilih, masukkan, mengemas kini dan memadam, serta aplikasi fleksibel dari pelbagai klausa. Adalah penting untuk memahami mekanisme pelaksanaan di sebalik pernyataan, seperti pengoptimuman indeks. Penggunaan lanjutan termasuk subqueries, pertanyaan sambungan, fungsi analisis, dan PL/SQL. Kesilapan umum termasuk kesilapan sintaks, isu prestasi, dan isu konsistensi data. Amalan terbaik pengoptimuman prestasi melibatkan menggunakan indeks yang sesuai, mengelakkan pilih *, mengoptimumkan di mana klausa, dan menggunakan pembolehubah terikat. Menguasai Oracle SQL memerlukan amalan, termasuk penulisan kod, debugging, berfikir dan memahami mekanisme asas.
 Cara Menambah, Ubah Suai dan Padam Panduan Operasi Lapangan Jadual MySQL Data
Apr 11, 2025 pm 05:42 PM
Cara Menambah, Ubah Suai dan Padam Panduan Operasi Lapangan Jadual MySQL Data
Apr 11, 2025 pm 05:42 PM
Panduan Operasi Lapangan di MySQL: Tambah, mengubah suai, dan memadam medan. Tambahkan medan: alter table table_name tambah column_name data_type [not null] [default default_value] [primary kekunci] [AUTO_INCREMENT] Modify Field: Alter Table Table_Name Ubah suai column_name data_type [not null] [default default_value] [Kunci Utama]
 Apakah kekangan integriti jadual pangkalan data Oracle?
Apr 11, 2025 pm 03:42 PM
Apakah kekangan integriti jadual pangkalan data Oracle?
Apr 11, 2025 pm 03:42 PM
Kekangan integriti pangkalan data Oracle dapat memastikan ketepatan data, termasuk: tidak null: nilai null dilarang; Unik: Keunikan menjamin, membolehkan nilai null tunggal; Kunci utama: kekangan utama utama, menguatkan unik, dan melarang nilai null; Kunci asing: Mengekalkan hubungan antara jadual, kunci asing merujuk kepada kunci utama jadual utama; Semak: Hadkan nilai lajur mengikut syarat.
 Penjelasan terperinci mengenai contoh pertanyaan bersarang dalam pangkalan data MySQL
Apr 11, 2025 pm 05:48 PM
Penjelasan terperinci mengenai contoh pertanyaan bersarang dalam pangkalan data MySQL
Apr 11, 2025 pm 05:48 PM
Pertanyaan bersarang adalah cara untuk memasukkan pertanyaan lain dalam satu pertanyaan. Mereka digunakan terutamanya untuk mendapatkan data yang memenuhi syarat kompleks, mengaitkan pelbagai jadual, dan mengira nilai ringkasan atau maklumat statistik. Contohnya termasuk mencari pekerja di atas gaji purata, mencari pesanan untuk kategori tertentu, dan mengira jumlah jumlah pesanan bagi setiap produk. Apabila menulis pertanyaan bersarang, anda perlu mengikuti: Tulis subqueries, tulis hasilnya kepada pertanyaan luar (dirujuk dengan alias atau sebagai klausa), dan mengoptimumkan prestasi pertanyaan (menggunakan indeks).
 Bagaimana log tomcat membantu menyelesaikan masalah kebocoran memori
Apr 12, 2025 pm 11:42 PM
Bagaimana log tomcat membantu menyelesaikan masalah kebocoran memori
Apr 12, 2025 pm 11:42 PM
Log Tomcat adalah kunci untuk mendiagnosis masalah kebocoran memori. Dengan menganalisis log tomcat, anda boleh mendapatkan wawasan mengenai kelakuan memori dan pengumpulan sampah (GC), dengan berkesan mencari dan menyelesaikan kebocoran memori. Berikut adalah cara menyelesaikan masalah kebocoran memori menggunakan log Tomcat: 1. GC Log Analysis terlebih dahulu, membolehkan pembalakan GC terperinci. Tambah pilihan JVM berikut kepada parameter permulaan TOMCAT: -XX: PrintGCDetails-XX: PrintGCDATestamps-XLogGC: GC.LOG Parameter ini akan menghasilkan log GC terperinci (GC.LOG), termasuk maklumat seperti jenis GC, saiz dan masa yang dikitar semula. Analisis GC.Log
