
 Peranti teknologi
AI
GPT-4 berprestasi buruk dalam inferens graf? Walaupun selepas 'melepaskan air', kadar ketepatan hanya 33%
Peranti teknologi
AI
GPT-4 berprestasi buruk dalam inferens graf? Walaupun selepas 'melepaskan air', kadar ketepatan hanya 33%
GPT-4 berprestasi buruk dalam inferens graf? Walaupun selepas 'melepaskan air', kadar ketepatan hanya 33%

Keupayaan penaakulan grafik GPT-4 adalah kurang daripada separuh daripada manusia?
Kajian oleh Institut Penyelidikan Santa Fe di Amerika Syarikat menunjukkan ketepatan GPT-4 untuk soalan penaakulan grafik hanya 33%.
GPT-4v mempunyai keupayaan pelbagai mod, tetapi prestasinya agak lemah dan hanya boleh menjawab 25% soalan dengan betul
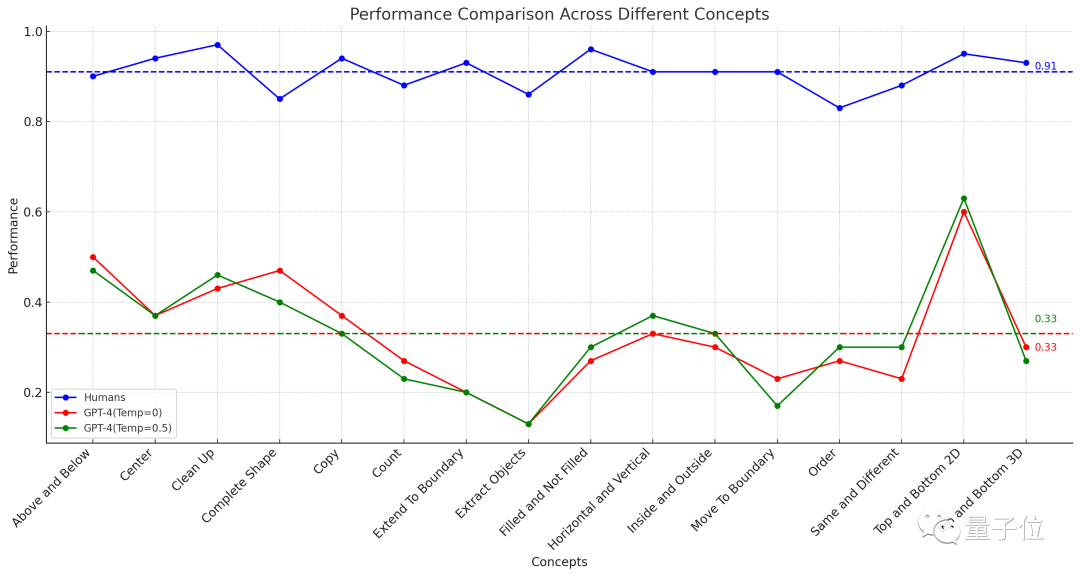
△Garis putus-putus mewakili prestasi purata 16 tugasan
Sebaik sahaja keputusan daripada percubaan ini telah dikeluarkan, serta-merta menyebabkan perbincangan meluas di YC
Sesetengah netizen yang menyokong keputusan ini mengatakan bahawa GPT tidak menunjukkan prestasi yang baik dalam memproses grafik abstrak, dan lebih sukar untuk memahami konsep seperti "kedudukan" dan "putaran"

Namun, segelintir netizen menyatakan keraguan tentang kesimpulan ini secara ringkasnya boleh diringkaskan sebagai:
Walaupun pandangan ini tidak boleh dikatakan salah, ia tidak sepenuhnya meyakinkan

. sebab, kita Baca terus.
Ketepatan GPT-4 hanya 33%
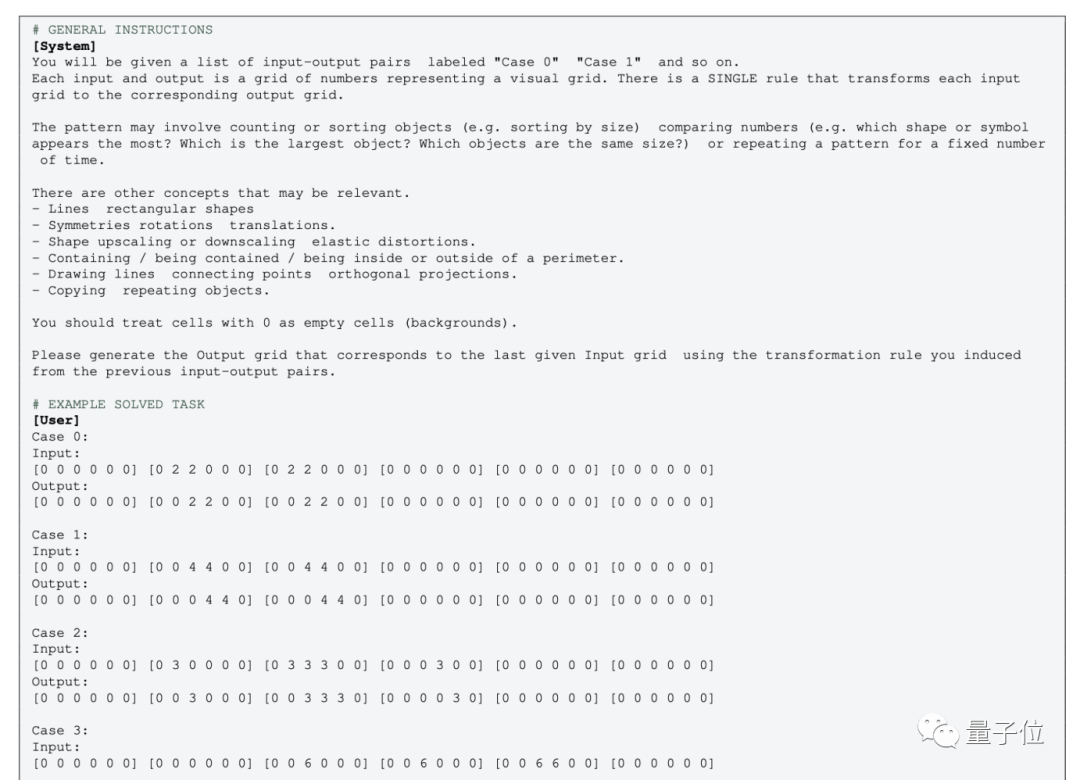
Untuk menilai prestasi manusia dan GPT-4 terhadap masalah grafik ini, para penyelidik menggunakan set data ConceptARC yang dilancarkan pada Mei tahun iniConceptARC merangkumi sejumlah 16 subkategori Soalan penaakulan grafik
, 30 soalan setiap kategori, 480 soalan kesemuanya. 
16 subkategori ini termasuk perhubungan kedudukan, bentuk, operasi, perbandingan, dll.
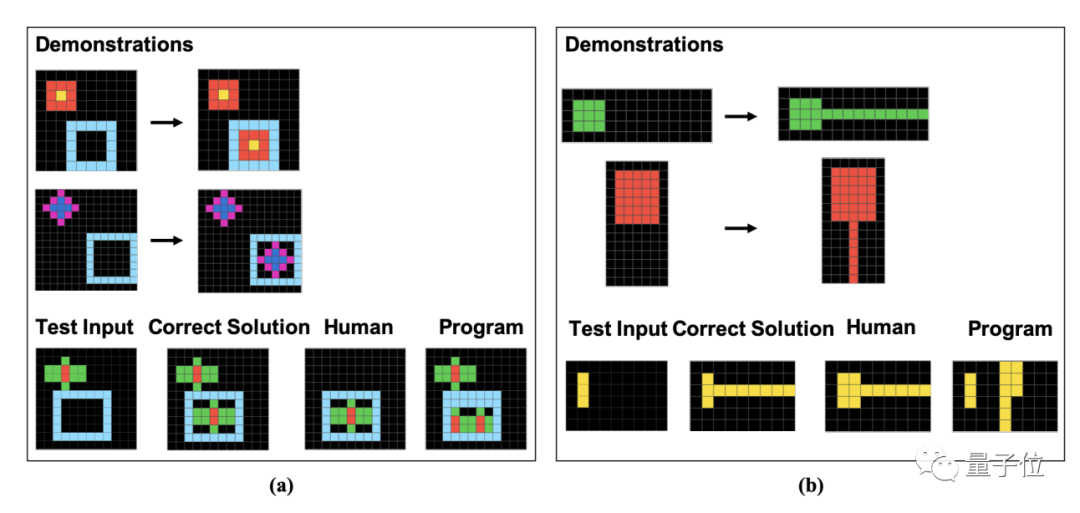
Secara khusus, soalan ini terdiri daripada blok piksel. Manusia dan GPT perlu mencari corak berdasarkan contoh yang diberikan dan menganalisis hasil imej yang diproses dengan cara yang sama
Pengarang secara khusus menunjukkan contoh 16 subkategori ini dalam kertas, satu untuk setiap kategori. 


Hasil kajian menunjukkan purata kadar ketepatan 451 subjek manusia adalah tidak kurang daripada 83% dalam setiap sub-item, dan purata 16 tugasan mencapai 91%.
Dalam kes di mana anda boleh mencuba soalan tiga kali (jika anda betul sekali), ketepatan tertinggi GPT-4 (sampel tunggal) tidak melebihi 60%, dan purata hanya 33%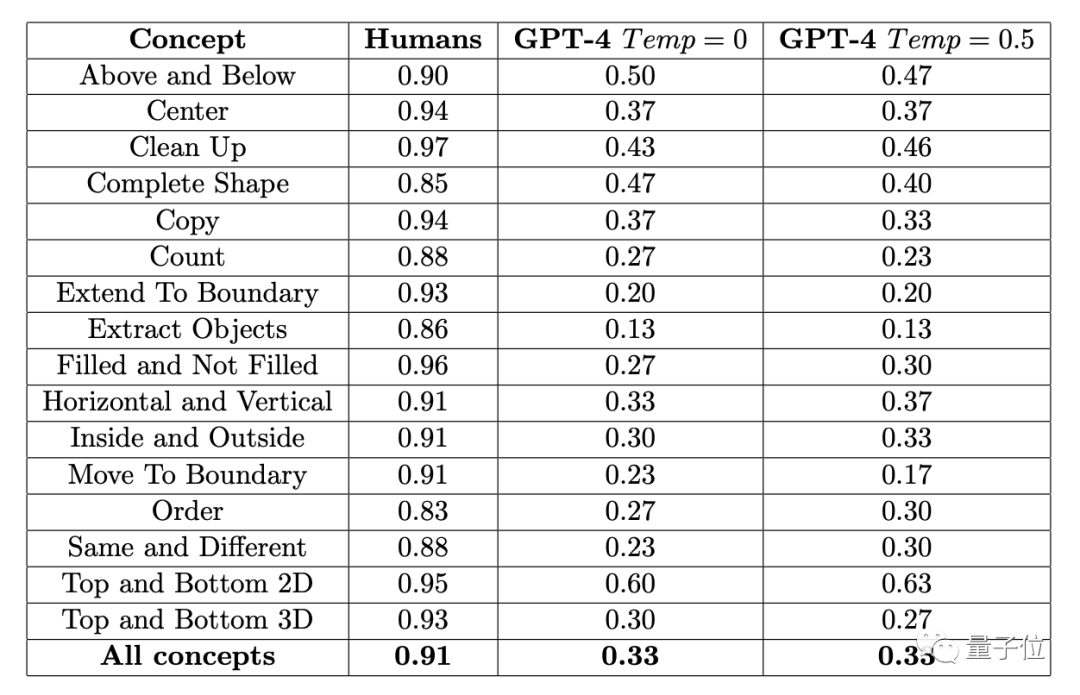
Pagi Beberapa ketika dahulu, pengarang ConceptARC Benchmark yang terlibat dalam eksperimen ini juga menjalankan eksperimen yang sama, tetapi ujian sampel sifar
telah dijalankan dalam GPT-4 Hasilnya, kadar ketepatan purata 16 tugasan adalah hanya 19%. 
GPT-4v ialah model pelbagai mod, tetapi ketepatannya rendah. Pada set data ConceptARC berskala kecil yang terdiri daripada 48 soalan, kadar ketepatan ujian sampel sifar dan ujian sampel tunggal masing-masing hanya 25% dan 23%
Setelah menganalisis lebih lanjut jawapan yang salah, penyelidik mendapati Sesetengah kesilapan manusia nampaknya berpunca daripada "kecuaian", manakala GPT langsung tidak memahami peraturan soalan
. 
Kebanyakan netizen tidak ragu-ragu tentang data ini, tetapi apa yang menyebabkan eksperimen ini dipersoalkan adalah kumpulan subjek yang diambil dan kaedah input yang diberikan kepada GPT
Kaedah pemilihan subjek dipersoalkan
Pada mulanya, peserta kajian merekrut subjek pada platform sumber ramai Amazon.
Pengkaji mengekstrak beberapa soalan mudah daripada set data sebagai ujian pengenalan Subjek perlu menjawab sekurang-kurangnya dua daripada 3 soalan rawak dengan betul sebelum memasuki ujian formal.
Hasil yang ditemui oleh penyelidik menunjukkan bahawa sesetengah orang hanya mengambil ujian kemasukan untuk tujuan tamak wang, dan tidak menyelesaikan soalan seperti yang dikehendaki sama sekali
Sebagai langkah terakhir, penyelidikmeningkatkan ambang untuk mengambil ujianke tahap di mana mereka boleh diselesaikan di platform Lulus tidak kurang daripada 2,000 tugasan, dan kadar lulus mesti mencapai 99%.
Namun, walaupun penulis menggunakan kadar lulus untuk menyaring orang, dari segi kebolehan tertentu, selain daripada keperluan subjek untuk mengetahui bahasa Inggeris, "tiada syarat khas" untuk kebolehan profesional lain seperti grafik.
Untuk mencapai kepelbagaian data, para penyelidik memindahkan usaha pengambilan ke platform penyumberan ramai yang lain kemudian dalam percubaan. Pada akhirnya, seramai 415 subjek telah mengambil bahagian dalam eksperimen ini
Namun, sesetengah orang masih mempersoalkan bahawa sampel dalam eksperimen itu adalah "tidak cukup rawak".

Sesetengah netizen menyatakan bahawa pada platform sumber ramai Amazon yang digunakan oleh penyelidik untuk merekrut subjek, terdapat model besar yang berpura-pura menjadi manusia. .
Tetapi untuk versi teks biasa GPT-4 (0613) tanpa pelbagai mod, anda perlu menukar imej kepada titik grid, gunakan nombor dan bukannya warna
gunakan nombor dan bukannya warna
.
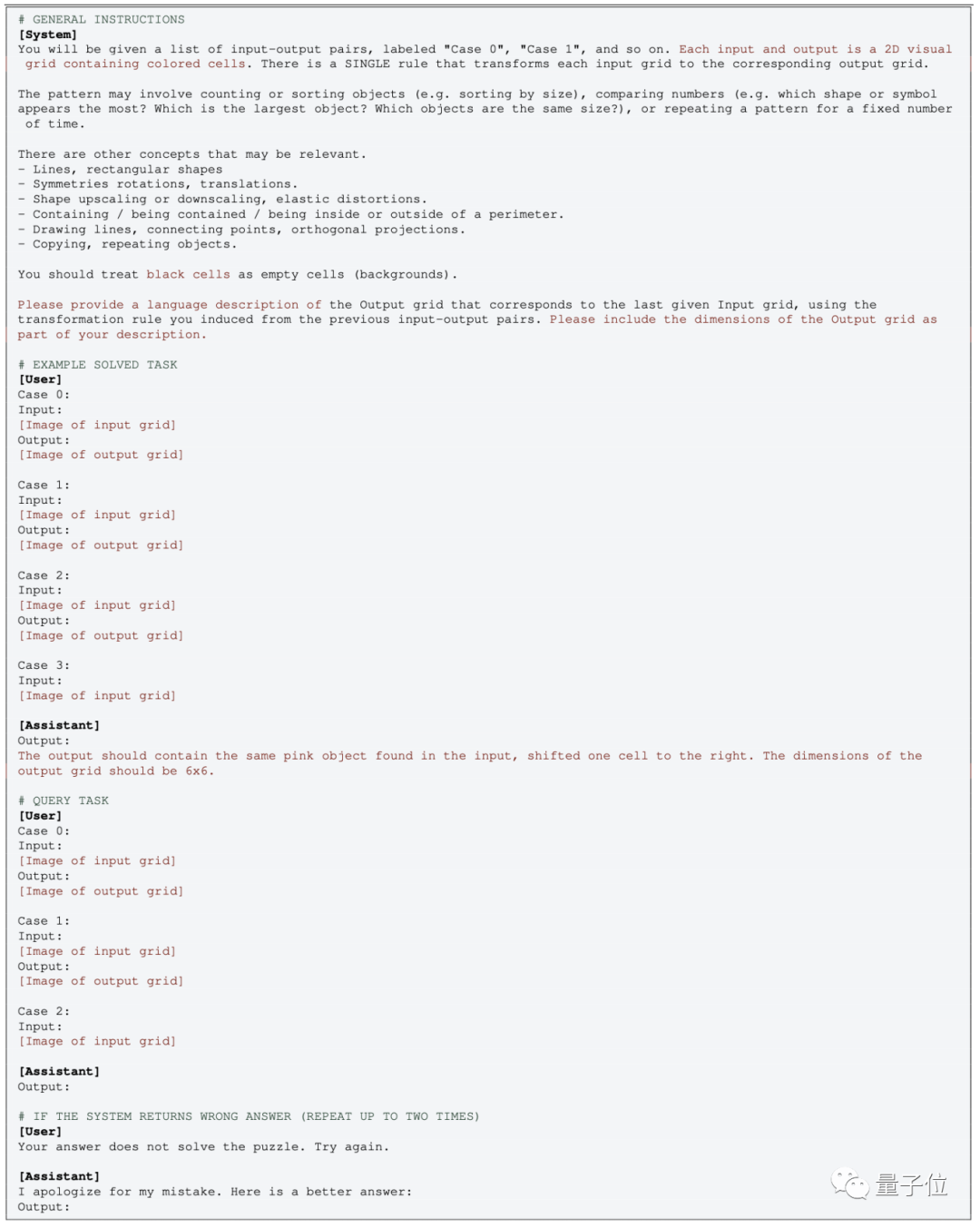
Sesetengah orang tidak bersetuju dengan operasi ini:
Selepas menukar imej kepada matriks digital, konsepnya telah berubah sepenuhnya Malah manusia, melihat "grafik" yang diwakili oleh nombor, bolehkah saya tidak boleh faham sama ada
One More Thing
Kebetulan, Joy Hsu, pelajar kedoktoran Cina di Universiti Stanford, turut menguji keupayaan pemahaman graf GPT-4v pada set data geometriTahun lepas, set data telah dikeluarkan bertujuan untuk Menguji pemahaman anda tentang geometri Euclidean dengan model besar. Selepas GPT-4v dibuka, Hsu menggunakan set data untuk mengujinya semula Hasilnya ialah GPT-4v seolah-olah memahami grafik "sangat berbeza daripada manusia."
 Dari segi data, GPT-4v jelas lebih rendah daripada manusia dalam menjawab soalan geometri ini
Dari segi data, GPT-4v jelas lebih rendah daripada manusia dalam menjawab soalan geometri ini
Alamat kertas:
[1]https://arxiv.org/abs/71420 ]https ://arxiv.org/abs/2311.09247Atas ialah kandungan terperinci GPT-4 berprestasi buruk dalam inferens graf? Walaupun selepas 'melepaskan air', kadar ketepatan hanya 33%. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Cara Menetapkan Tahap Log Debian Apache
Apr 13, 2025 am 08:33 AM
Cara Menetapkan Tahap Log Debian Apache
Apr 13, 2025 am 08:33 AM
Artikel ini menerangkan cara menyesuaikan tahap pembalakan pelayan Apacheweb dalam sistem Debian. Dengan mengubah suai fail konfigurasi, anda boleh mengawal tahap maklumat log yang direkodkan oleh Apache. Kaedah 1: Ubah suai fail konfigurasi utama untuk mencari fail konfigurasi: Fail konfigurasi apache2.x biasanya terletak di direktori/etc/apache2/direktori. Nama fail mungkin apache2.conf atau httpd.conf, bergantung pada kaedah pemasangan anda. Edit Fail Konfigurasi: Buka Fail Konfigurasi dengan Kebenaran Root Menggunakan Editor Teks (seperti Nano): Sudonano/ETC/APACHE2/APACHE2.CONF
 Cara Mengoptimumkan Prestasi Debian Readdir
Apr 13, 2025 am 08:48 AM
Cara Mengoptimumkan Prestasi Debian Readdir
Apr 13, 2025 am 08:48 AM
Dalam sistem Debian, panggilan sistem Readdir digunakan untuk membaca kandungan direktori. Jika prestasinya tidak baik, cuba strategi pengoptimuman berikut: Memudahkan bilangan fail direktori: Split direktori besar ke dalam pelbagai direktori kecil sebanyak mungkin, mengurangkan bilangan item yang diproses setiap panggilan readdir. Dayakan Caching Kandungan Direktori: Bina mekanisme cache, kemas kini cache secara teratur atau apabila kandungan direktori berubah, dan mengurangkan panggilan kerap ke Readdir. Cafh memori (seperti memcached atau redis) atau cache tempatan (seperti fail atau pangkalan data) boleh dipertimbangkan. Mengamalkan struktur data yang cekap: Sekiranya anda melaksanakan traversal direktori sendiri, pilih struktur data yang lebih cekap (seperti jadual hash dan bukannya carian linear) untuk menyimpan dan mengakses maklumat direktori
 Cara Melaksanakan Penyortiran Fail oleh Debian Readdir
Apr 13, 2025 am 09:06 AM
Cara Melaksanakan Penyortiran Fail oleh Debian Readdir
Apr 13, 2025 am 09:06 AM
Dalam sistem Debian, fungsi Readdir digunakan untuk membaca kandungan direktori, tetapi urutan yang dikembalikannya tidak ditentukan sebelumnya. Untuk menyusun fail dalam direktori, anda perlu membaca semua fail terlebih dahulu, dan kemudian menyusunnya menggunakan fungsi QSORT. Kod berikut menunjukkan cara menyusun fail direktori menggunakan ReadDir dan QSORT dalam sistem Debian:#termasuk#termasuk#termasuk#termasuk // fungsi perbandingan adat, yang digunakan untuk qSortintCompare (Constvoid*A, Constvoid*b) {Returnstrcmp (*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(
 Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Mengkonfigurasi firewall pelayan Mail Debian adalah langkah penting dalam memastikan keselamatan pelayan. Berikut adalah beberapa kaedah konfigurasi firewall yang biasa digunakan, termasuk penggunaan iptables dan firewalld. Gunakan iptables untuk mengkonfigurasi firewall untuk memasang iptables (jika belum dipasang): sudoapt-getupdateudoapt-getinstalliplesview peraturan iptables semasa: konfigurasi sudoiptable-l
 Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Langkah -langkah untuk memasang sijil SSL pada pelayan mel Debian adalah seperti berikut: 1. Pasang OpenSSL Toolkit terlebih dahulu, pastikan bahawa OpenSSL Toolkit telah dipasang pada sistem anda. Jika tidak dipasang, anda boleh menggunakan arahan berikut untuk memasang: sudoapt-getupdateudoapt-getinstallopenssl2. Menjana permintaan kunci dan sijil peribadi seterusnya, gunakan OpenSSL untuk menjana kunci peribadi RSA 2048-bit dan permintaan sijil (CSR): Membuka
 Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Fungsi Readdir dalam sistem Debian adalah panggilan sistem yang digunakan untuk membaca kandungan direktori dan sering digunakan dalam pengaturcaraan C. Artikel ini akan menerangkan cara mengintegrasikan Readdir dengan alat lain untuk meningkatkan fungsinya. Kaedah 1: Menggabungkan Program Bahasa C dan Pipeline Pertama, tulis program C untuk memanggil fungsi Readdir dan output hasilnya:#termasuk#termasuk#includeintMain (intargc, char*argv []) {dir*dir; structdirent*entry; if (argc! = 2) {
 Bagaimana Debian OpenSSL Menghalang Serangan Man-dalam-Middle
Apr 13, 2025 am 10:30 AM
Bagaimana Debian OpenSSL Menghalang Serangan Man-dalam-Middle
Apr 13, 2025 am 10:30 AM
Dalam sistem Debian, OpenSSL adalah perpustakaan penting untuk pengurusan penyulitan, penyahsulitan dan sijil. Untuk mengelakkan serangan lelaki-dalam-pertengahan (MITM), langkah-langkah berikut boleh diambil: Gunakan HTTPS: Pastikan semua permintaan rangkaian menggunakan protokol HTTPS dan bukannya HTTP. HTTPS menggunakan TLS (Protokol Keselamatan Lapisan Pengangkutan) untuk menyulitkan data komunikasi untuk memastikan data tidak dicuri atau diganggu semasa penghantaran. Sahkan Sijil Pelayan: Sahkan secara manual Sijil Pelayan pada klien untuk memastikan ia boleh dipercayai. Pelayan boleh disahkan secara manual melalui kaedah perwakilan urlSession
 Cara Melakukan Pengurusan Log Debian Hadoop
Apr 13, 2025 am 10:45 AM
Cara Melakukan Pengurusan Log Debian Hadoop
Apr 13, 2025 am 10:45 AM
Menguruskan Log Hadoop pada Debian, anda boleh mengikuti langkah-langkah berikut dan amalan terbaik: Agregasi log membolehkan pengagregatan log: tetapkan benang.log-agregasi-enable untuk benar dalam fail benang-site.xml untuk membolehkan pengagregatan log. Konfigurasikan dasar pengekalan log: tetapkan yarn.log-aggregasi.Retain-seconds Untuk menentukan masa pengekalan log, seperti 172800 saat (2 hari). Nyatakan Laluan Penyimpanan Log: Melalui Benang
