

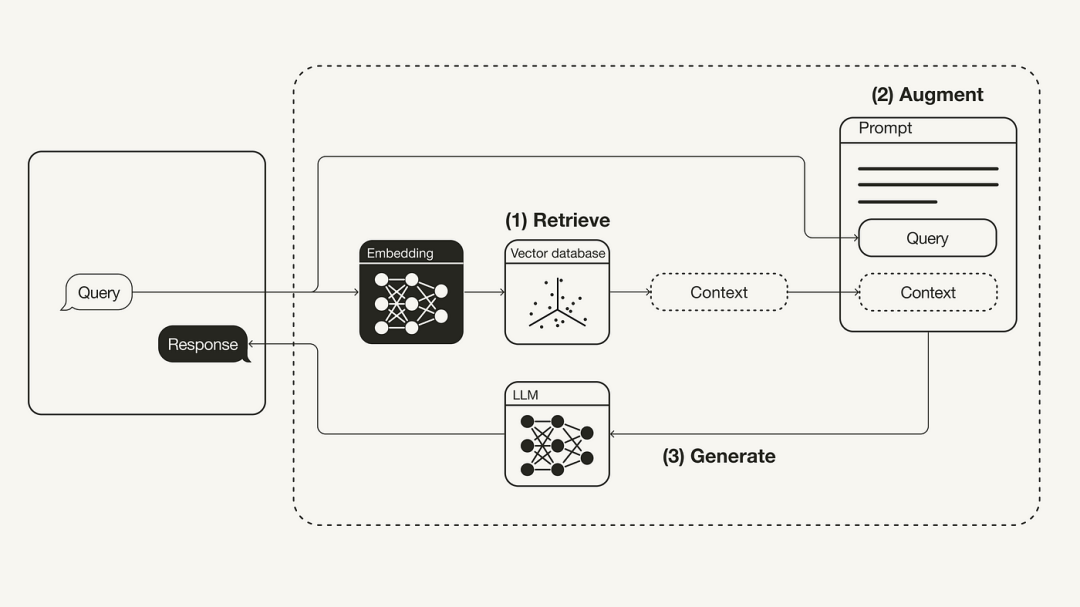
Tumpuan utama artikel ini ialah konsep dan teori RAG. Seterusnya, kami akan menunjukkan cara menggunakan LangChain, model bahasa OpenAI dan pangkalan data vektor Weaviate untuk melaksanakan sistem orkestrasi RAG yang mudah
Konsep Retrieval Augmented Generation (RAG) merujuk kepada penyediaan maklumat tambahan kepada LLM melalui sumber pengetahuan luaran. Ini membolehkan LLM menjana jawapan yang lebih tepat dan kontekstual sambil mengurangkan halusinasi.
Apabila menulis semula kandungan, teks asal perlu ditulis semula ke dalam bahasa Cina tanpa ayat asal
LLM terbaik semasa dilatih menggunakan sejumlah besar data, jadi berat rangkaian neuralnya disimpan dalam Banyak pengetahuan am (memori parameter). Walau bagaimanapun, jika gesaan memerlukan LLM menjana hasil yang memerlukan pengetahuan selain daripada data latihannya (seperti maklumat baharu, data proprietari atau maklumat khusus domain), ketidaktepatan fakta mungkin berlaku semasa menulis semula kandungan, anda perlu Teks asal telah ditulis semula ke dalam bahasa Cina tanpa ayat asal (ilusi), seperti yang ditunjukkan dalam tangkapan skrin di bawah:
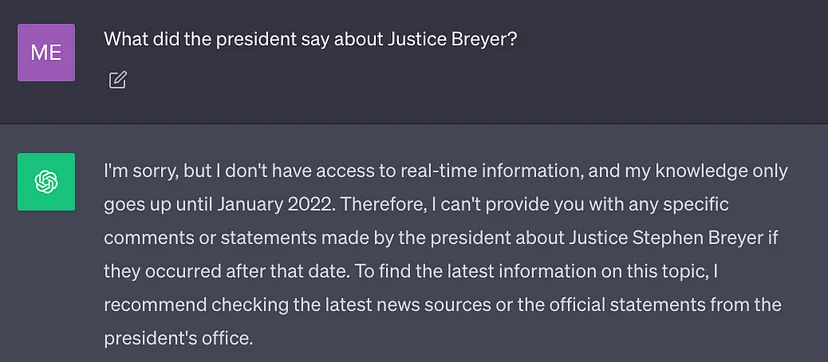
Oleh itu, adalah penting untuk menggabungkan pengetahuan am LLM dengan konteks tambahan untuk menjana lebih tepat dan lebih banyak hasil Kontekstual dan halusinasi yang dikurangkan
Penyelesaian
Secara tradisinya, kita boleh menyesuaikan rangkaian saraf kepada domain tertentu atau maklumat proprietari dengan memperhalusi model. Walaupun teknik ini berkesan, ia memerlukan sejumlah besar sumber pengkomputeran, mahal, dan memerlukan sokongan pakar teknikal, menjadikannya sukar untuk cepat menyesuaikan diri dengan perubahan maklumat
Pada tahun 2020, kertas kerja Lewis et al. "Retrieval " -Penjanaan Tambahan untuk Tugas NLP Intensif Pengetahuan" mencadangkan teknologi yang lebih fleksibel: Penjanaan Dipertingkatkan (RAG). Dalam kertas kerja ini, penyelidik menggabungkan model generatif dengan modul perolehan semula yang boleh memberikan maklumat tambahan menggunakan sumber pengetahuan luaran yang lebih mudah dikemas kini.
Untuk meletakkannya dalam bahasa vernakular: RAG adalah untuk LLM apa itu peperiksaan buku terbuka kepada manusia. Untuk peperiksaan buku terbuka, pelajar boleh membawa bahan rujukan seperti buku teks dan nota di mana mereka boleh mencari maklumat yang berkaitan untuk menjawab soalan. Idea di sebalik peperiksaan buku terbuka ialah peperiksaan memberi tumpuan kepada keupayaan pelajar untuk menaakul dan bukannya keupayaan mereka untuk menghafal maklumat tertentu.
Begitu juga, pengetahuan de facto berbeza daripada keupayaan inferens LLM dan boleh disimpan dalam sumber pengetahuan luaran yang mudah diakses dan dikemas kini
Rewritten kandungan: Membangun semula aliran kerja pengambilan semula generasi tambahan (RAG)
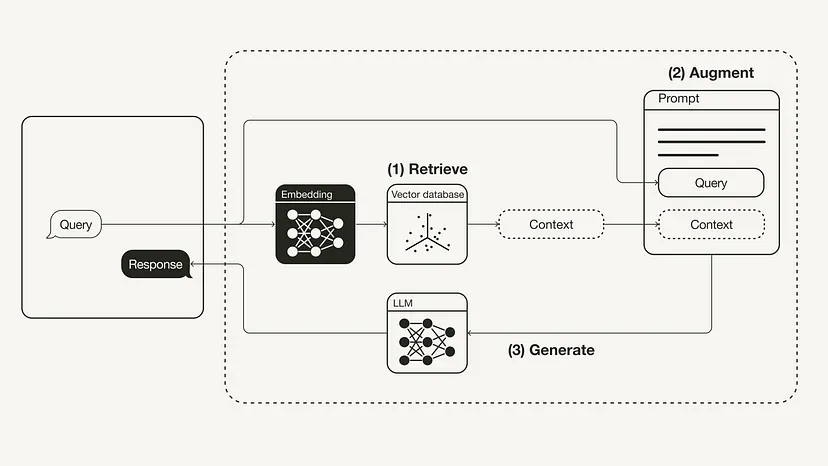
Retrieval: Memohon pertanyaan pengguna untuk mengambil konteks yang relevan dari sumber pengetahuan luar. Untuk melakukan ini, model benam digunakan untuk membenamkan pertanyaan pengguna ke dalam ruang vektor yang sama sebagai konteks tambahan dalam pangkalan data vektor. Ini membolehkan anda melakukan carian persamaan dan mengembalikan objek data k dalam pangkalan data vektor ini yang paling hampir dengan pertanyaan pengguna.
Sila frasa semula: Prasyarat yang diperlukan
Sila pastikan anda memasang pakej Python yang diperlukan:
#!pip install langchain openai weaviate-client
Selain itu, gunakan fail .env dalam direktori akar untuk menentukan pembolehubah persekitaran yang berkaitan. Anda memerlukan akaun OpenAI untuk mendapatkan Kunci API OpenAI, dan kemudian "Buat kunci baharu" dalam kunci API (https://platform.openai.com/account/api-keys).
OPENAI_API_KEY="<your_openai_api_key>"</your_openai_api_key>
Kemudian, jalankan arahan berikut untuk memuatkan pembolehubah persekitaran yang berkaitan.
import dotenvdotenv.load_dotenv()
Persediaan
#🎜 anda dalam fasa persediaan menyediakan pangkalan data vektor sebagai sumber pengetahuan luaran yang menyimpan semua maklumat tambahan. Pembinaan pangkalan data vektor ini termasuk langkah-langkah berikut:
Alamat dokumen asal: https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/ docs/modules/state_of_the_union.txt
import requestsfrom langchain.document_loaders import TextLoaderurl = "https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/state_of_the_union.txt"res = requests.get(url)with open("state_of_the_union.txt", "w") as f:f.write(res.text)loader = TextLoader('./state_of_the_union.txt')documents = loader.load()Seterusnya, pecahkan dokumen kepada beberapa bahagian. Oleh kerana keadaan asal dokumen terlalu panjang untuk dimuatkan ke dalam tetingkap konteks LLM, ia perlu dipecahkan kepada ketulan teks yang lebih kecil. LangChain juga mempunyai banyak alat pemisah terbina dalam. Untuk contoh mudah ini, kita boleh menggunakan CharacterTextSplitter dengan chunk_size ditetapkan kepada 500 dan chunk_overlap ditetapkan kepada 50, yang mengekalkan kesinambungan teks antara ketulan teks.
from langchain.text_splitter import CharacterTextSplittertext_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)chunks = text_splitter.split_documents(documents)
Akhir sekali, benamkan blok teks dan simpannya. Untuk membolehkan carian semantik dilakukan merentasi blok teks, pembenaman vektor perlu dijana untuk setiap blok teks dan disimpan bersama dengan pembenamannya. Untuk menjana benam vektor, gunakan model benam OpenAI untuk penyimpanan, gunakan pangkalan data vektor Weaviate. Blok teks boleh diisi secara automatik ke dalam pangkalan data vektor dengan memanggil .from_documents().
from langchain.embeddings import OpenAIEmbeddingsfrom langchain.vectorstores import Weaviateimport weaviatefrom weaviate.embedded import EmbeddedOptionsclient = weaviate.Client(embedded_options = EmbeddedOptions())vectorstore = Weaviate.from_documents(client = client,documents = chunks,embedding = OpenAIEmbeddings(),by_text = False)
Langkah 1: Dapatkan
#🎜##🎜##🎜##🎜 🎜🎜#Selepas mengisi pangkalan data vektor, kami boleh mentakrifkannya sebagai komponen retriever yang boleh mendapatkan konteks tambahan berdasarkan persamaan semantik antara pertanyaan pengguna dan blok terbenamretriever = vectorstore.as_retriever()
from langchain.prompts import ChatPromptTemplatetemplate = """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.Question: {question} Context: {context} Answer:"""prompt = ChatPromptTemplate.from_template(template)print(prompt)
Langkah 3: Jana
#🎜🎜🎜##🎜🎜🎜##🎜🎜 🎜#Akhirnya, kita boleh membina rantaian pemikiran untuk proses RAG ini, menghubungkan retriever, templat segera dan LLM bersama-sama. Setelah rantai RAG ditakrifkan, ia boleh dipanggil
from langchain.chat_models import ChatOpenAIfrom langchain.schema.runnable import RunnablePassthroughfrom langchain.schema.output_parser import StrOutputParserllm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)rag_chain = ({"context": retriever,"question": RunnablePassthrough()} | prompt | llm| StrOutputParser() )query = "What did the president say about Justice Breyer"rag_chain.invoke(query)"The president thanked Justice Breyer for his service and acknowledged his dedication to serving the country. The president also mentioned that he nominated Judge Ketanji Brown Jackson as a successor to continue Justice Breyer's legacy of excellence."Artikel ini memperkenalkan konsep RAG, yang merupakan karya terawal Daripada kertas kerja trieval 2020 Penjanaan Tambahan untuk Tugas NLP Intensif Pengetahuan". Selepas memperkenalkan teori di sebalik RAG, termasuk motivasi dan penyelesaian, artikel ini menunjukkan cara untuk melaksanakannya dalam Python. Artikel ini menunjukkan cara untuk melaksanakan aliran kerja RAG menggunakan OpenAI LLM ditambah dengan pangkalan data vektor Weaviate dan model pembenaman OpenAI. Peranan LangChain ialah orkestrasi.
Atas ialah kandungan terperinci Laksanakan kod Python untuk meningkatkan keupayaan mendapatkan semula untuk model besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk menyambung jalur lebar ke pelayan
Bagaimana untuk menyambung jalur lebar ke pelayan
 Penyelesaian ralat HTTP 503
Penyelesaian ralat HTTP 503
 Bagaimana untuk melangkau sambungan ke Internet selepas boot Windows 11
Bagaimana untuk melangkau sambungan ke Internet selepas boot Windows 11
 Cara menghidupkan mod selamat Word
Cara menghidupkan mod selamat Word
 Peranan tag tajuk html
Peranan tag tajuk html
 animasi jquery
animasi jquery
 kb4012212 Apa yang perlu dilakukan jika kemas kini gagal
kb4012212 Apa yang perlu dilakukan jika kemas kini gagal
 Apa yang perlu dilakukan jika imej terbenam tidak dipaparkan sepenuhnya
Apa yang perlu dilakukan jika imej terbenam tidak dipaparkan sepenuhnya
 Bagaimana untuk mengeksport perkataan daripada powerdesigner
Bagaimana untuk mengeksport perkataan daripada powerdesigner








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



