
 Peranti teknologi
AI
Pasukan PyTorch melaksanakan semula model 'split everything' lapan kali lebih pantas daripada pelaksanaan asal
Peranti teknologi
AI
Pasukan PyTorch melaksanakan semula model 'split everything' lapan kali lebih pantas daripada pelaksanaan asal
Pasukan PyTorch melaksanakan semula model 'split everything' lapan kali lebih pantas daripada pelaksanaan asal

Dari awal tahun hingga sekarang, AI generatif telah berkembang pesat. Tetapi banyak kali, kita perlu menghadapi masalah yang sukar: bagaimana untuk mempercepatkan latihan, penaakulan, dll. AI generatif, terutamanya apabila menggunakan PyTorch.
Dalam artikel ini, penyelidik dari pasukan PyTorch memberikan kami penyelesaian. Artikel ini memfokuskan pada cara menggunakan PyTorch asli tulen untuk mempercepatkan model AI generatif Ia juga memperkenalkan ciri PyTorch baharu dan contoh praktikal tentang cara menggabungkannya.
Apakah hasilnya? Pasukan PyTorch berkata mereka menulis semula model "Split Everything" (SAM) Meta, menghasilkan kod yang 8 kali lebih pantas daripada pelaksanaan asal tanpa kehilangan ketepatan, semuanya dioptimumkan menggunakan PyTorch asli.

Alamat blog: https://pytorch.org/blog/accelerating-generative-ai/
Selepas membaca artikel ini, anda akan mendapat pemahaman berikut:
.Torch- : Penyusun model PyTorch, PyTorch 2.0 menambah fungsi baharu yang dipanggil torch.compile (), yang boleh mempercepatkan model sedia ada dengan satu baris kod
- Kuantiti GPU: mempercepatkan model dengan mengurangkan ketepatan pengiraan
- ; (Perhatian Produk Titik Berskala): pelaksanaan perhatian yang cekap memori; } bersama-sama untuk menyusun data bersaiz tidak seragam ke dalam satu tensor, seperti imej dengan saiz yang berbeza; pendaftaran.
- Ciri asli PyTorch membawa peningkatan daya pengeluaran dan mengurangkan overhed memori.
- Untuk maklumat lanjut tentang penyelidikan ini, sila rujuk SAM yang dicadangkan oleh Meta. Artikel terperinci boleh didapati dalam "CV tidak lagi wujud? Meta mengeluarkan "Split Everything" model AI, CV boleh menyambut detik GPT-3"
Kandungan akan mendalam lapisan demi lapisan . Pada akhir artikel ini, kami akan memperkenalkan SAM versi pantas. Untuk pembaca yang berminat, anda boleh memuat turunnya dari GitHub. Di samping itu, data ini divisualisasikan menggunakan Perfetto UI untuk menunjukkan nilai aplikasi pelbagai ciri PyTorch
Projek ini boleh didapati di alamat GitHub: https://github.com/pytorch-labs/segment-anything-fast Kod sumber

menulis semula split everything model SAM
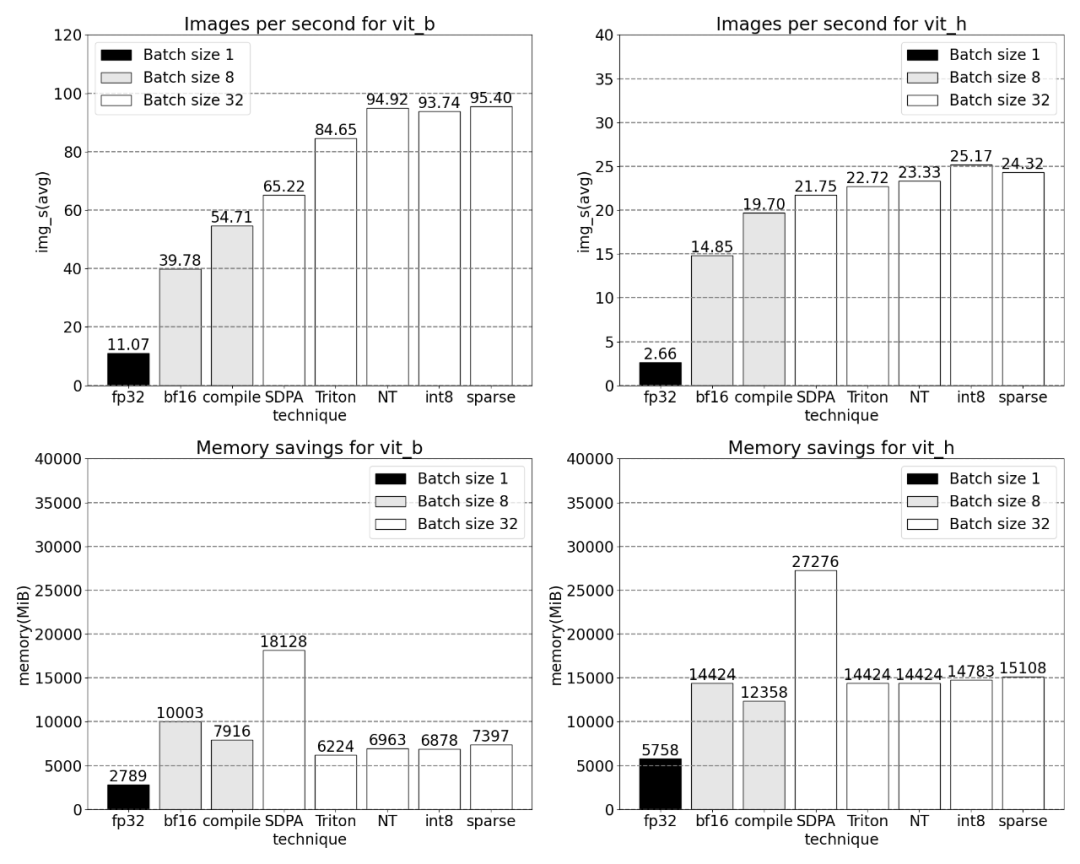
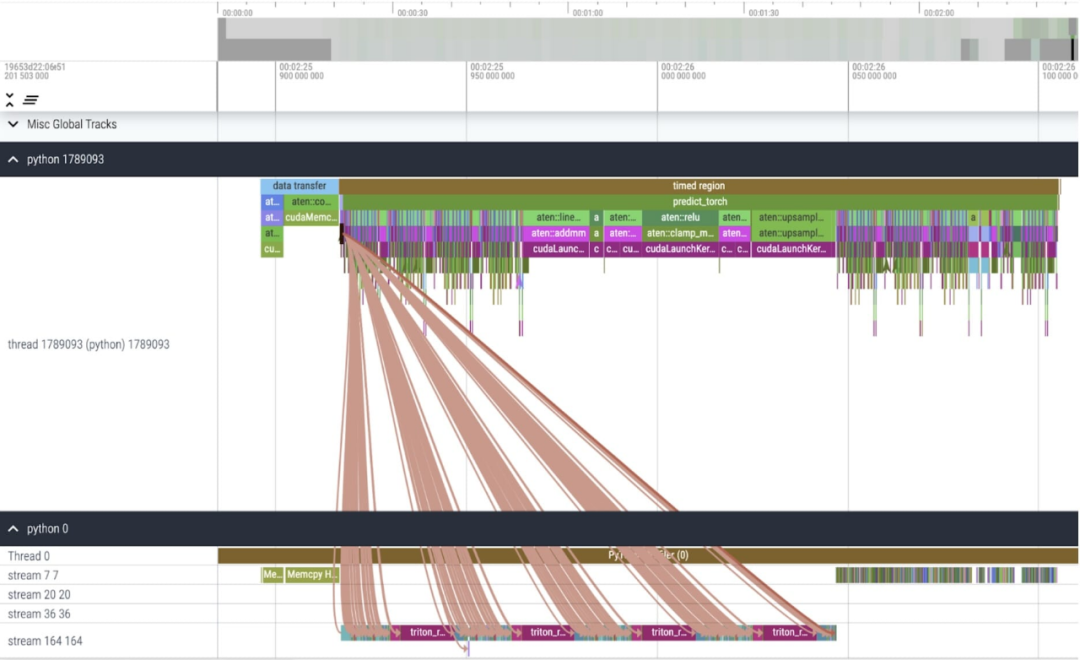
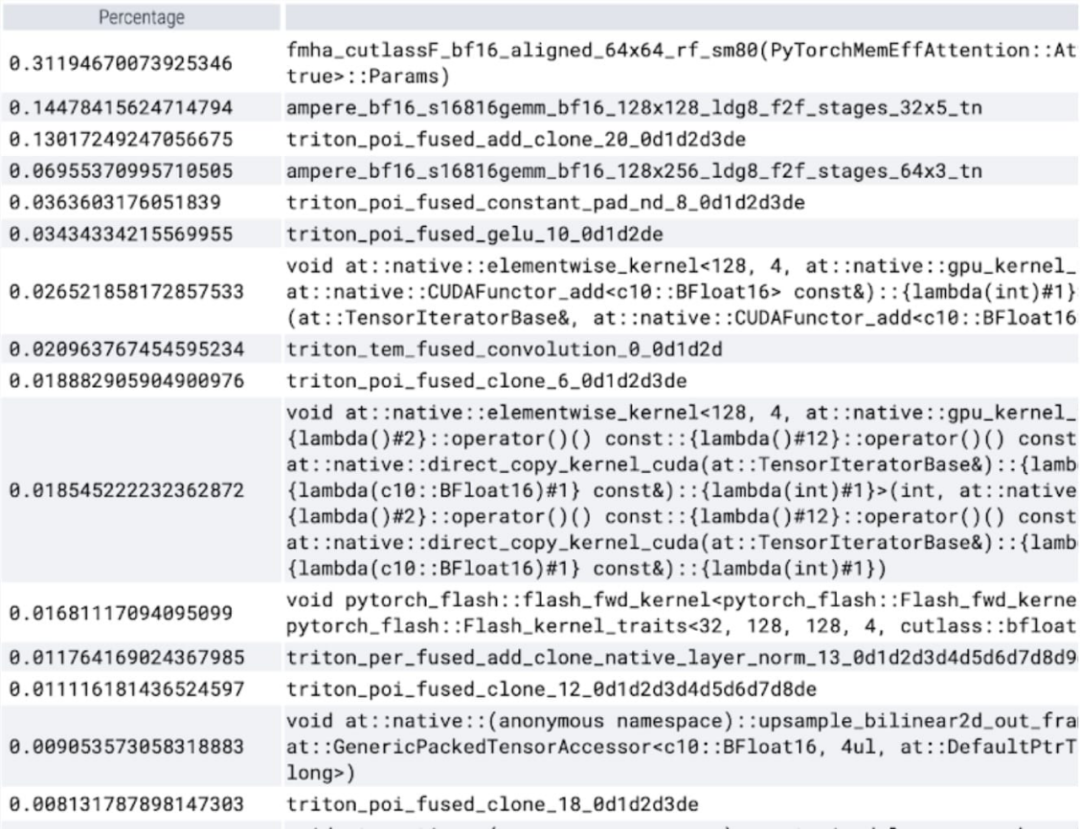
Kajian menunjukkan bahawa jenis data garis dasar SAM yang digunakan dalam artikel ini ialah float32 dtype, saiz batch ialah 1, dan PyTorch Profiler digunakan untuk melihat hasil penjejakan teras Seperti berikut:
Artikel ini mendapati SAM mempunyai dua tempat yang boleh dioptimumkan:
Yang pertama ialah panggilan panjang ke aten::index, yang disebabkan oleh operasi indeks tensor (seperti []) Disebabkan oleh panggilan asas yang dijana. Walau bagaimanapun, masa sebenar yang dibelanjakan oleh GPU untuk aten::index adalah agak rendah Sebabnya ialah semasa proses memulakan dua teras, aten::index menyekat cudaStreamSynchronize antara mereka. Ini bermakna CPU menunggu sehingga GPU selesai diproses sehingga teras kedua dilancarkan. Oleh itu, untuk mengoptimumkan SAM, kertas kerja ini percaya bahawa seseorang harus berusaha untuk menghapuskan penyegerakan GPU yang menyekat yang menyebabkan masa terbiar.
Masalah kedua ialah SAM menghabiskan banyak masa GPU dalam pendaraban matriks (bahagian hijau gelap seperti yang ditunjukkan dalam gambar), yang sangat biasa dalam model Transformers. Jika kita boleh mengurangkan masa GPU model SAM pada pendaraban matriks, maka kita boleh meningkatkan kelajuan SAM dengan ketara
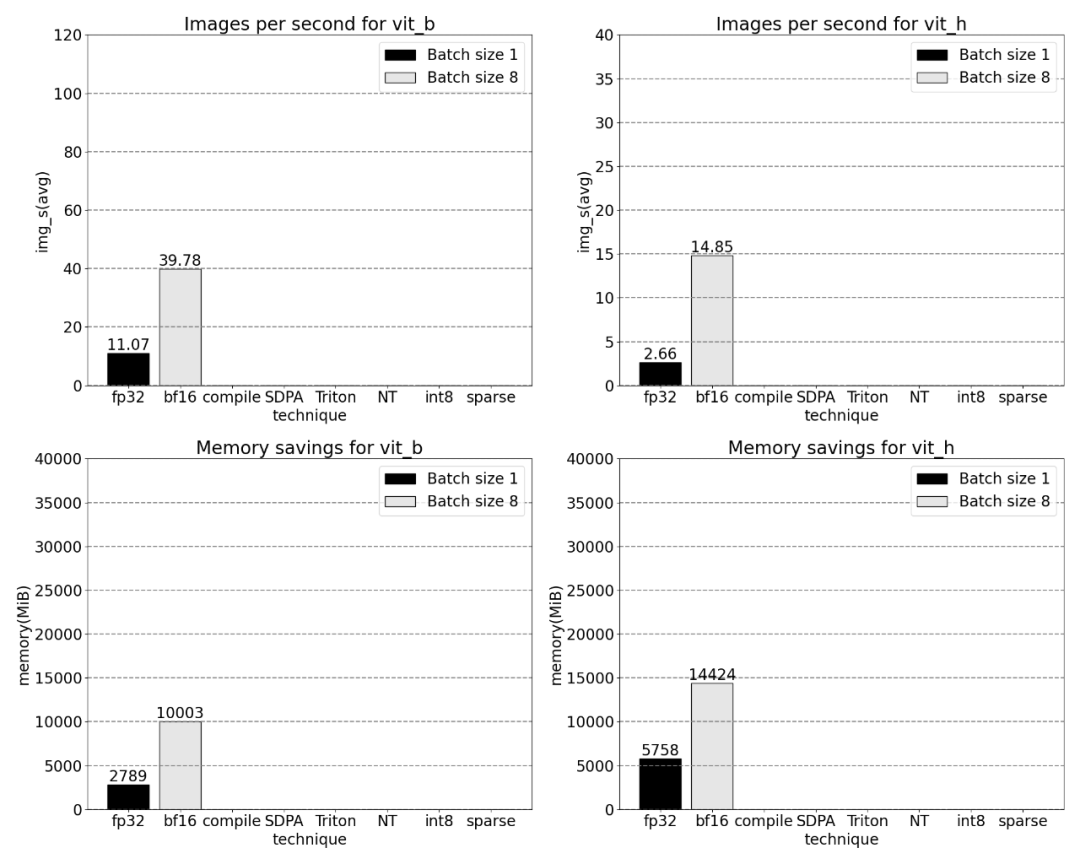
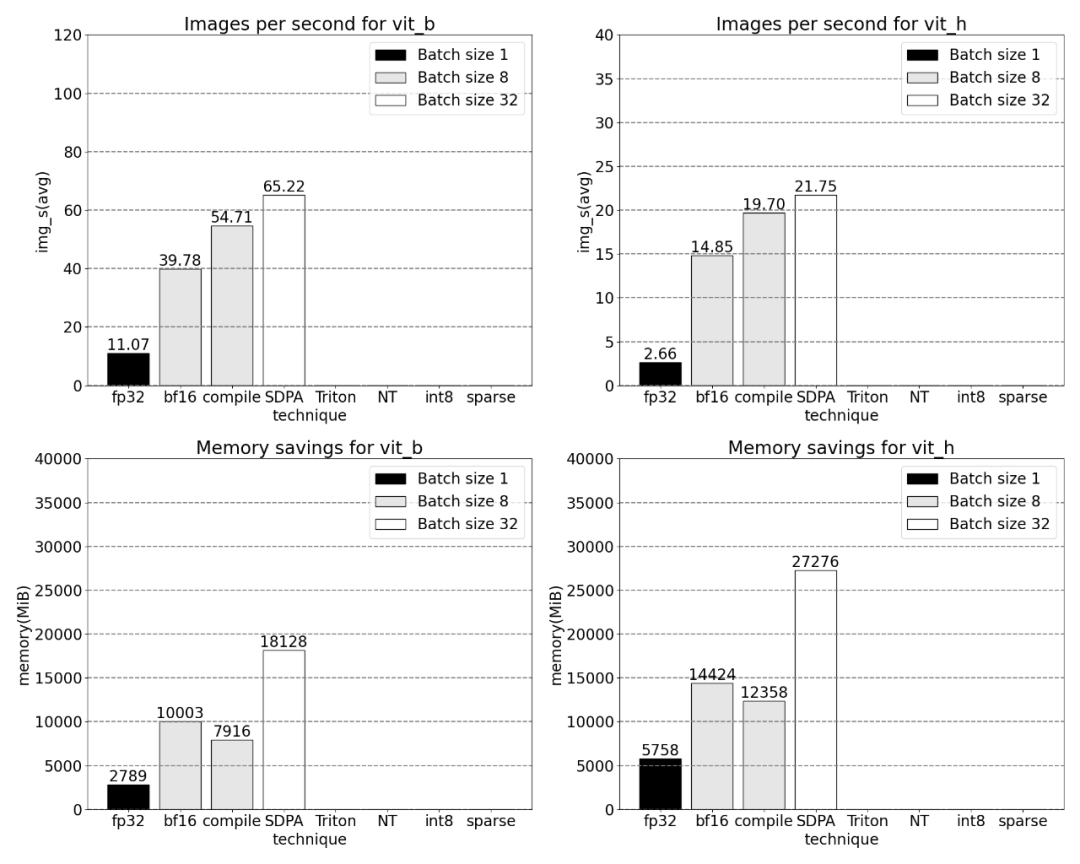
Seterusnya, kita akan membandingkan daya tampung (img/s) dan overhed memori (GiB) SAM Wujudkan garis dasar. Kemudian terdapat proses pengoptimuman
Ayat yang perlu ditulis semula ialah: Bfloat16 separuh ketepatan (ditambah penyegerakan GPU dan pemprosesan batch) untuk menyelesaikan masalah di atas
ialah, kurangkan masa yang diperlukan untuk masa pendaraban matriks, artikel ini bertukar kepada bfloat16. bfloat16 ialah jenis separuh ketepatan yang biasa digunakan, yang boleh menjimatkan banyak masa dan memori pengkomputeran dengan mengurangkan ketepatan setiap parameter dan pengaktifan Selain itu, artikel ini dijumpai Terdapat dua tempat yang boleh dioptimumkan untuk membuang penyegerakan GPU

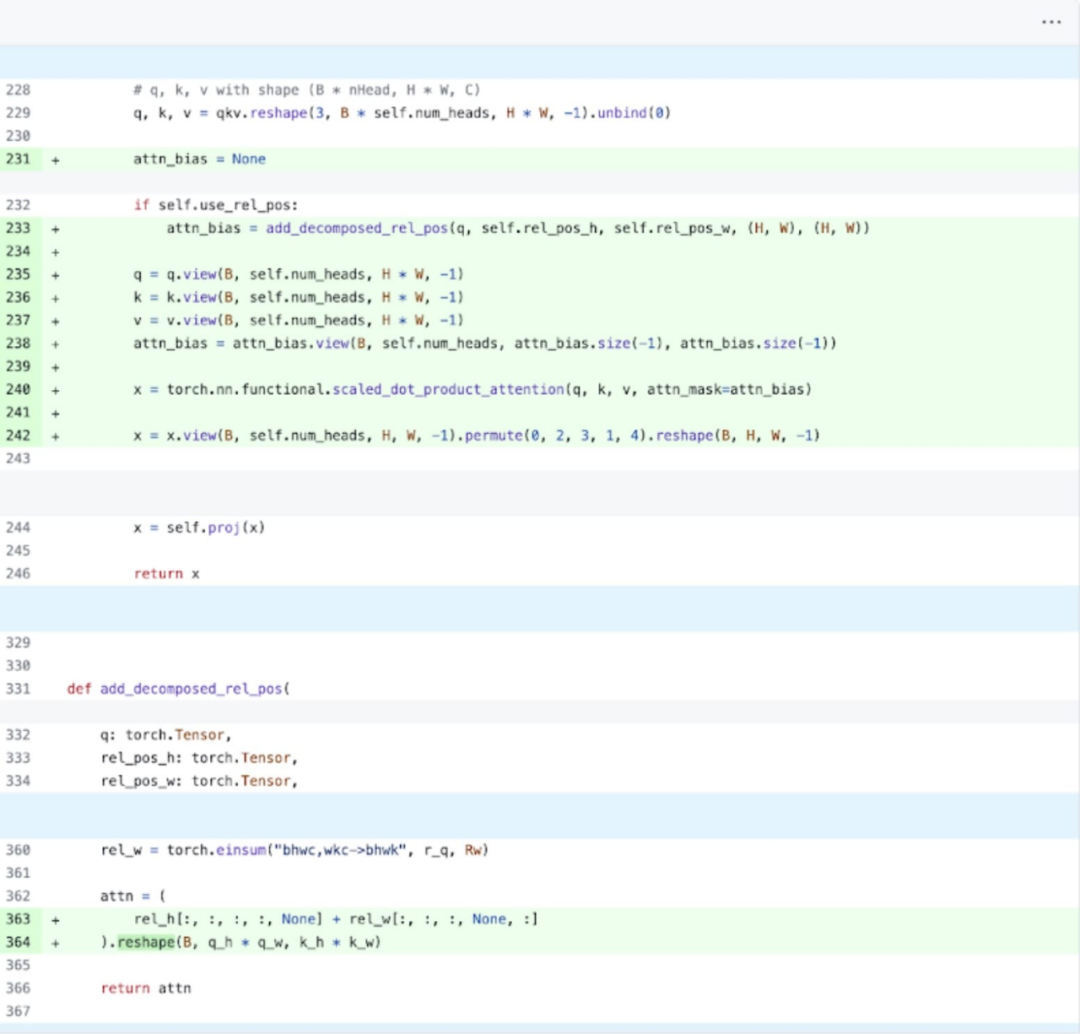
Secara khusus, lebih mudah difahami berdasarkan gambar di atas. pengekod imej SAM, Terdapat dua pembolehubah q_coords dan k_coords yang bertindak sebagai penimbang koordinat, dan pembolehubah ini diperuntukkan dan diproses pada CPU. Walau bagaimanapun, sebaik sahaja pembolehubah ini digunakan untuk mengindeks dalam rel_pos_resized, operasi pengindeksan mengalihkan pembolehubah ini secara automatik ke GPU, menyebabkan masalah penyegerakan GPU. Untuk menyelesaikan masalah ini, penyelidikan menunjukkan bahawa bahagian ini boleh diselesaikan dengan menulis semula menggunakan fungsi obor.where seperti yang ditunjukkan di atas

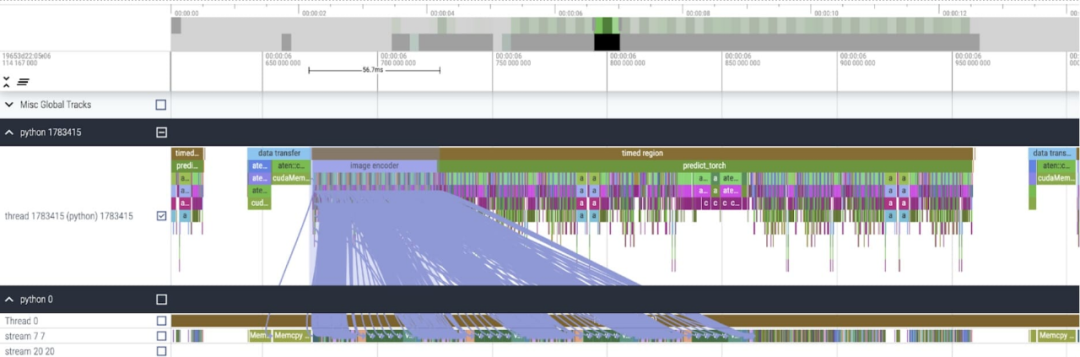
 Selepas menggunakan perubahan ini, kami dapati Terdapat perubahan yang ketara. jurang masa antara panggilan kernel individu, terutamanya dengan kelompok kecil (di sini 1). Untuk mendapatkan pemahaman yang lebih mendalam tentang fenomena ini, kami memulakan analisis prestasi inferens SAM dengan saiz kelompok 8
Selepas menggunakan perubahan ini, kami dapati Terdapat perubahan yang ketara. jurang masa antara panggilan kernel individu, terutamanya dengan kelompok kecil (di sini 1). Untuk mendapatkan pemahaman yang lebih mendalam tentang fenomena ini, kami memulakan analisis prestasi inferens SAM dengan saiz kelompok 8
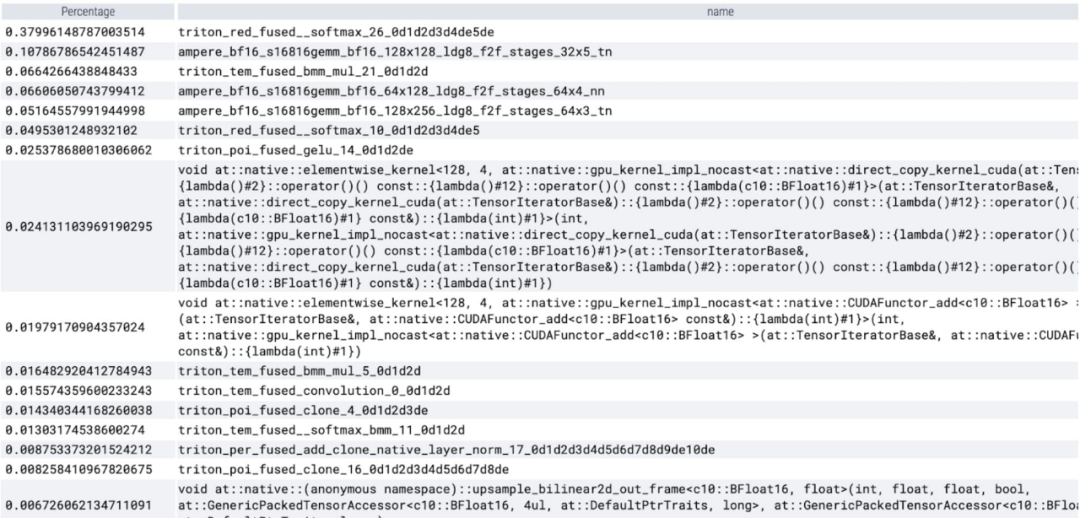
Semasa menganalisis masa yang dibelanjakan bagi setiap teras, kami mendapati bahawa majoriti GPU untuk Masa SAM adalah dibelanjakan untuk kernel mengikut unsur dan operasi softmax
Kini anda dapat melihat bahawa overhed relatif pendaraban matriks adalah jauh lebih kecil.
 Menggabungkan penyegerakan GPU dan pengoptimuman bfloat16, prestasi SAM dipertingkatkan sebanyak 3 kali ganda.
Menggabungkan penyegerakan GPU dan pengoptimuman bfloat16, prestasi SAM dipertingkatkan sebanyak 3 kali ganda.
Torch.compile (+pemecahan graf dan graf CUDA)
Saya menemui banyak operasi kecil semasa kajian SAM. Penyelidik percaya bahawa menggunakan pengkompil untuk menyatukan operasi ini adalah sangat berfaedah, jadi PyTorch membuat pengoptimuman berikut untuk torch.compile 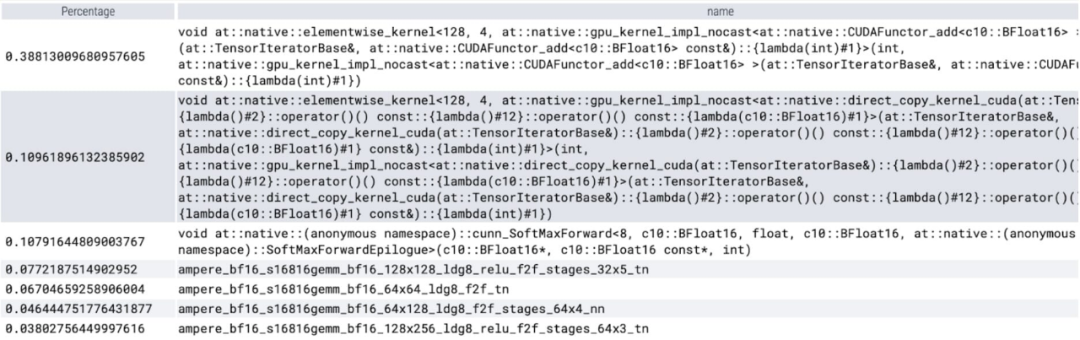
Menyatukan urutan operasi seperti nn.LayerNorm atau nn.GELU menjadi satu kernel GPU
 Kendalian fius serta-merta mengikuti kernel pendaraban matriks untuk mengurangkan bilangan panggilan kernel GPU.
Kendalian fius serta-merta mengikuti kernel pendaraban matriks untuk mengurangkan bilangan panggilan kernel GPU.
Melalui pengoptimuman ini, penyelidikan mengurangkan bilangan perjalanan balik memori global GPU, dengan itu mempercepatkan inferens. Kini kita boleh mencuba torch.compile pada pengekod imej SAM. Untuk memaksimumkan prestasi, artikel ini menggunakan beberapa teknik kompilasi lanjutan:
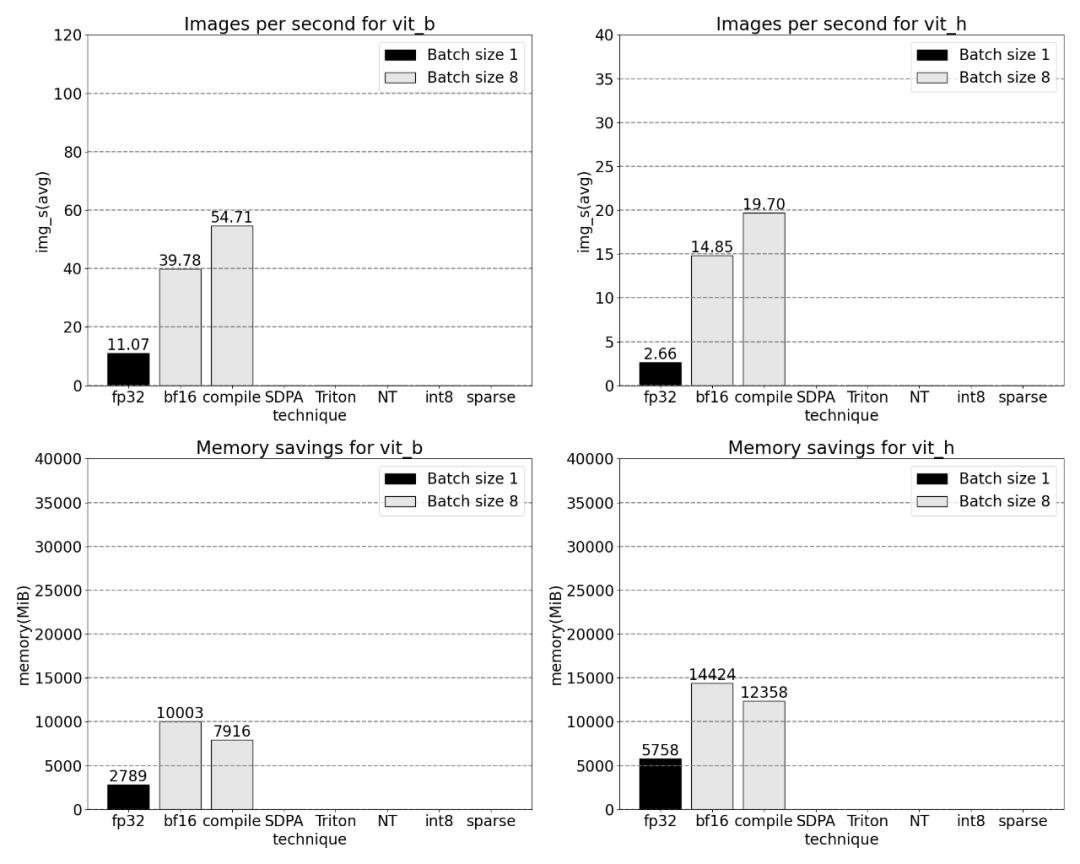
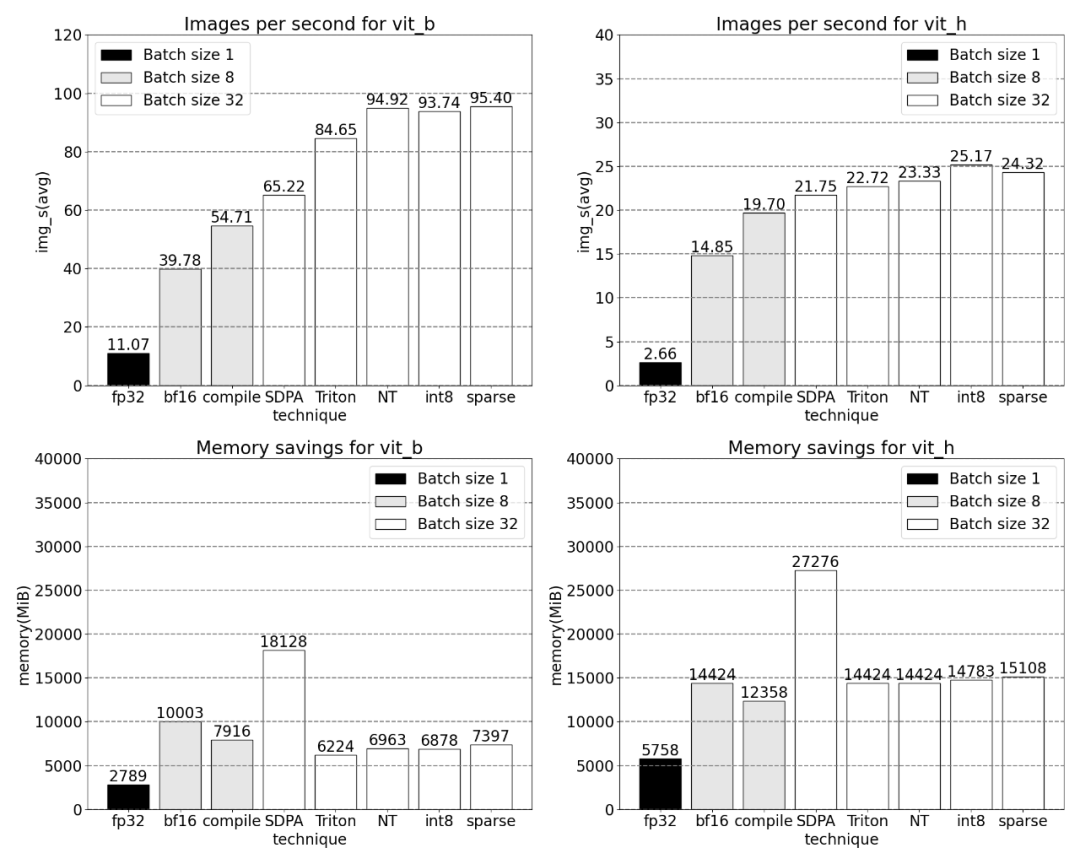
Penjejakan teras Menurut keputusan, torch.compile berfungsi dengan sangat baik sehingga sebahagian besar masa , dan kemudian setiap varian GEMM. Ukuran berikut adalah untuk saiz kelompok 8 dan ke atas. SDPA: scaled_dot_product_attention Penjejakan Teras Anda kini boleh melihat kernel perhatian yang cekap memori mengambil banyak masa pengiraan pada GPU: skala_titik _perhatian_produk, ya Meningkatkan saiz kelompok dengan ketara. Graf di bawah menunjukkan perubahan untuk saiz kelompok 32 dan ke atas. Seterusnya, kajian itu menjalankan eksperimen ke atas Triton, NestedTensor, batch Predict_torch, kuantisasi int8, sparsity separa berstruktur (2:4) dan operasi lain
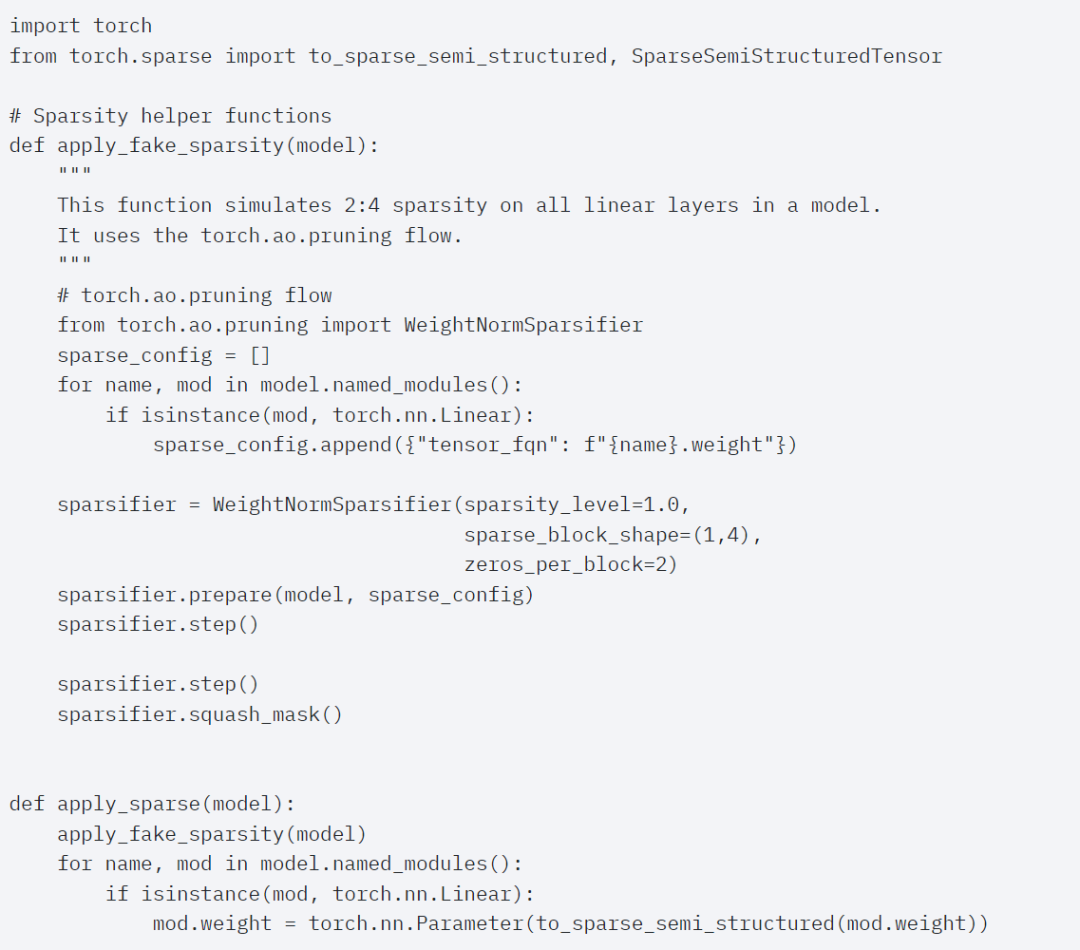
Penghujung artikel ialah sparsity separa berstruktur. Kajian menunjukkan bahawa pendaraban matriks masih menjadi hambatan yang perlu dihadapi. Penyelesaiannya adalah dengan menggunakan sparsifikasi untuk menganggarkan pendaraban matriks. Dengan matriks yang jarang (iaitu mensifarkan nilai) lebih sedikit bit boleh digunakan untuk menyimpan pemberat dan tensor pengaktifan. Proses menetapkan pemberat dalam tensor yang ditetapkan kepada sifar dipanggil pemangkasan. Pemangkasan berat yang lebih kecil berpotensi mengurangkan saiz model tanpa kehilangan ketepatan yang ketara. Terdapat banyak cara untuk memangkas, bermula daripada tidak berstruktur sepenuhnya kepada berstruktur tinggi. Walaupun pemangkasan tidak berstruktur secara teorinya mempunyai kesan minimum pada ketepatan, dalam kes yang jarang GPU mungkin mengalami kemerosotan prestasi yang ketara walaupun sangat cekap apabila melakukan pendaraban matriks padat yang besar. Satu kaedah pemangkasan baru-baru ini disokong oleh PyTorch ialah sparsity separa berstruktur (atau 2:4), yang bertujuan untuk mencari keseimbangan. Kaedah penyimpanan jarang ini mengurangkan tensor asal sebanyak 50% sambil menghasilkan output tensor padat. Sila rujuk rajah di bawah untuk penjelasan Untuk menggunakan format storan jarang ini dan kernel pantas yang berkaitan, langkah seterusnya Apa yang dilakukannya ialah pemberat prun. Artikel ini memilih dua pemberat terkecil untuk pemangkasan pada kesederhanaan 2:4 Menukar pemberat daripada reka letak lalai PyTorch ("strided") kepada reka letak jarang separa berstruktur ini adalah mudah. Untuk melaksanakan apply_sparse (model), hanya 32 baris kod Python diperlukan: pada jarak 2: 4, kami memerhatikan prestasi puncak SAM dengan vit_b dan saiz kelompok 32 Ringkasan artikel adalah seperti berikut: Artikel ini memperkenalkan cara terpantas untuk melaksanakan Segmen Apa-apa pada PyTorch setakat ini dengan satu siri ciri baharu yang dikeluarkan secara rasmi artikel menulis semula SAM asal dalam PyTorch tulen tanpa kehilangan ketepatan #🎜🎜 # Untuk pembaca yang berminat, anda boleh menyemak blog asal untuk maklumat lanjut 
 Seterusnya, artikel ini menjalankan eksperimen pada SDPA (scaled_dot_product_attention), memfokuskan pada mekanisme perhatian. Secara umum, mekanisme perhatian asli berskala kuadratik dengan panjang jujukan dalam masa dan ingatan. Operasi SDPA PyTorch dibina berdasarkan prinsip perhatian cekap memori Flash Attention, FlashAttentionV2 dan xFormer, yang boleh mempercepatkan perhatian GPU dengan ketara. Digabungkan dengan torch.compile, operasi ini membenarkan ekspresi dan gabungan corak biasa dalam varian MultiheadAttention. Selepas perubahan kecil, model kini boleh menggunakan perhatian_produk_berskala.
Seterusnya, artikel ini menjalankan eksperimen pada SDPA (scaled_dot_product_attention), memfokuskan pada mekanisme perhatian. Secara umum, mekanisme perhatian asli berskala kuadratik dengan panjang jujukan dalam masa dan ingatan. Operasi SDPA PyTorch dibina berdasarkan prinsip perhatian cekap memori Flash Attention, FlashAttentionV2 dan xFormer, yang boleh mempercepatkan perhatian GPU dengan ketara. Digabungkan dengan torch.compile, operasi ini membenarkan ekspresi dan gabungan corak biasa dalam varian MultiheadAttention. Selepas perubahan kecil, model kini boleh menggunakan perhatian_produk_berskala.
 Sebagai contoh, artikel ini menggunakan a
Sebagai contoh, artikel ini menggunakan a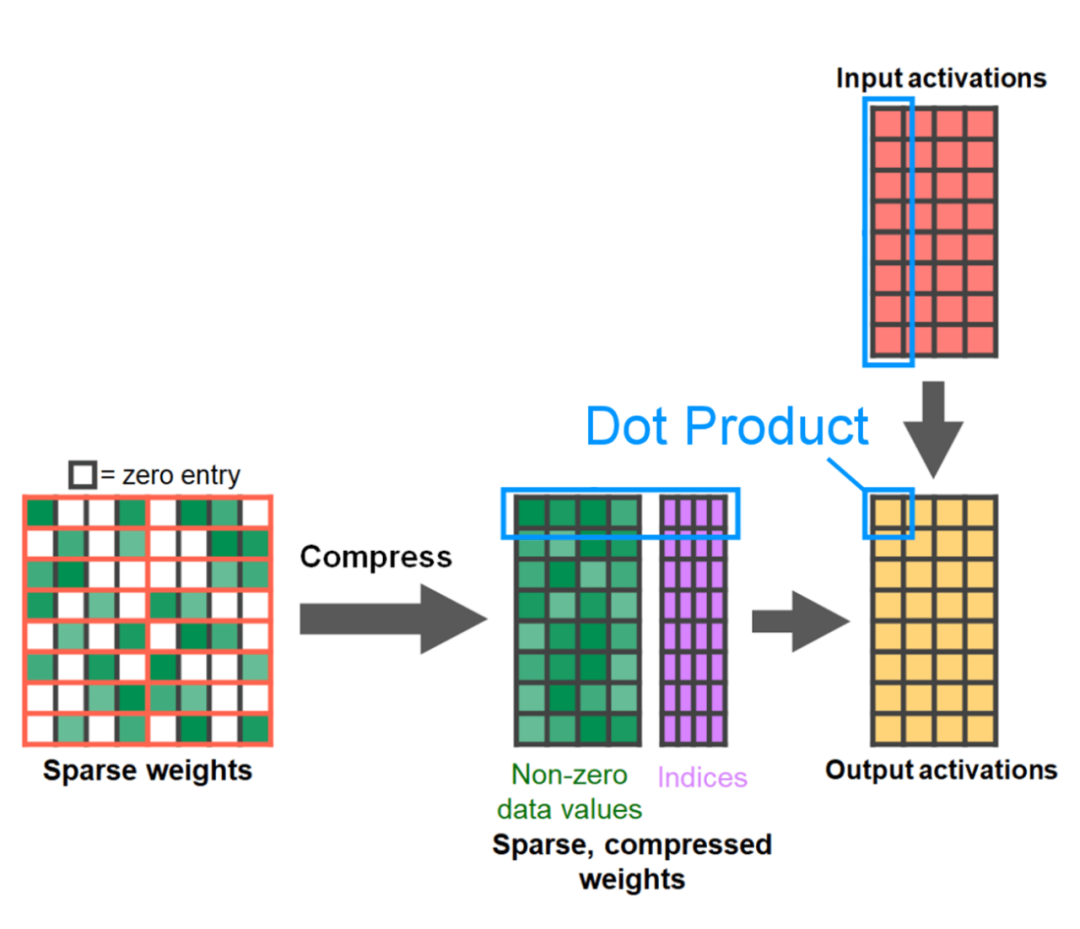
Atas ialah kandungan terperinci Pasukan PyTorch melaksanakan semula model 'split everything' lapan kali lebih pantas daripada pelaksanaan asal. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
Pengesanan objek ialah masalah yang agak matang dalam sistem pemanduan autonomi, antaranya pengesanan pejalan kaki adalah salah satu algoritma terawal untuk digunakan. Penyelidikan yang sangat komprehensif telah dijalankan dalam kebanyakan kertas kerja. Walau bagaimanapun, persepsi jarak menggunakan kamera fisheye untuk pandangan sekeliling agak kurang dikaji. Disebabkan herotan jejari yang besar, perwakilan kotak sempadan standard sukar dilaksanakan dalam kamera fisheye. Untuk mengurangkan perihalan di atas, kami meneroka kotak sempadan lanjutan, elips dan reka bentuk poligon am ke dalam perwakilan kutub/sudut dan mentakrifkan metrik mIOU pembahagian contoh untuk menganalisis perwakilan ini. Model fisheyeDetNet yang dicadangkan dengan bentuk poligon mengatasi model lain dan pada masa yang sama mencapai 49.5% mAP pada set data kamera fisheye Valeo untuk pemanduan autonomi
 Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Video terbaru robot Tesla Optimus dikeluarkan, dan ia sudah boleh berfungsi di kilang. Pada kelajuan biasa, ia mengisih bateri (bateri 4680 Tesla) seperti ini: Pegawai itu juga mengeluarkan rupanya pada kelajuan 20x - pada "stesen kerja" kecil, memilih dan memilih dan memilih: Kali ini ia dikeluarkan Salah satu sorotan video itu ialah Optimus menyelesaikan kerja ini di kilang, sepenuhnya secara autonomi, tanpa campur tangan manusia sepanjang proses. Dan dari perspektif Optimus, ia juga boleh mengambil dan meletakkan bateri yang bengkok, memfokuskan pada pembetulan ralat automatik: Berkenaan tangan Optimus, saintis NVIDIA Jim Fan memberikan penilaian yang tinggi: Tangan Optimus adalah robot lima jari di dunia paling cerdik. Tangannya bukan sahaja boleh disentuh
 Alat dengar Meta Quest 3S VR mampu milik baharu muncul di FCC, mencadangkan pelancaran yang akan berlaku
Sep 04, 2024 am 06:51 AM
Alat dengar Meta Quest 3S VR mampu milik baharu muncul di FCC, mencadangkan pelancaran yang akan berlaku
Sep 04, 2024 am 06:51 AM
Acara Meta Connect 2024 ditetapkan pada 25 hingga 26 September, dan dalam acara ini, syarikat itu dijangka memperkenalkan set kepala realiti maya mampu milik baharu. Dikhabarkan sebagai Meta Quest 3S, set kepala VR nampaknya telah muncul pada penyenaraian FCC. cadangan ini
 Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Pautan projek ditulis di hadapan: https://nianticlabs.github.io/mickey/ Memandangkan dua gambar, pose kamera di antara mereka boleh dianggarkan dengan mewujudkan kesesuaian antara gambar. Biasanya, surat-menyurat ini adalah 2D hingga 2D, dan anggaran pose kami adalah skala-tak tentu. Sesetengah aplikasi, seperti realiti tambahan segera pada bila-bila masa, di mana-mana sahaja, memerlukan anggaran pose metrik skala, jadi mereka bergantung pada penganggar kedalaman luaran untuk memulihkan skala. Makalah ini mencadangkan MicKey, proses pemadanan titik utama yang mampu meramalkan korespondensi metrik dalam ruang kamera 3D. Dengan mempelajari padanan koordinat 3D merentas imej, kami dapat membuat kesimpulan relatif metrik
 Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
FP8 dan ketepatan pengiraan titik terapung yang lebih rendah bukan lagi "paten" H100! Lao Huang mahu semua orang menggunakan INT8/INT4, dan pasukan Microsoft DeepSpeed memaksa diri mereka menjalankan FP6 pada A100 tanpa sokongan rasmi daripada Nvidia. Keputusan ujian menunjukkan bahawa kaedah baharu TC-FPx FP6 kuantisasi pada A100 adalah hampir atau kadangkala lebih pantas daripada INT4, dan mempunyai ketepatan yang lebih tinggi daripada yang terakhir. Selain itu, terdapat juga sokongan model besar hujung ke hujung, yang telah bersumberkan terbuka dan disepadukan ke dalam rangka kerja inferens pembelajaran mendalam seperti DeepSpeed. Keputusan ini juga mempunyai kesan serta-merta pada mempercepatkan model besar - di bawah rangka kerja ini, menggunakan satu kad untuk menjalankan Llama, daya pemprosesan adalah 2.65 kali lebih tinggi daripada dua kad. satu
