

Cara menggunakan LangChain dan OpenAI API untuk analisis dokumen

Kandungan yang perlu ditulis semula oleh penterjemah ialah: |Kandungan yang perlu ditulis semula ialah: Bugatti
Kandungan yang perlu ditulis semula oleh penyemak ialah: |Kandungan yang perlu untuk ditulis semula ialah: Chonglou
Dari Mengekstrak pandangandaripada dokumen dan data adalah penting untuk andauntuk membuat keputusan termaklum. Namun, apabila berurusan dengan maklumat sensitif, isu privasi boleh timbul. Penggunaan gabungan LangChain dan OpenAI perlu ditulis semula: API, anda boleh menganalisis dokumen tempatan tanpa memuat naiknya ke Internet.
Mereka melakukannya ini dengan menyimpan data secara setempat, menggunakan pembenaman dan vektorisasi untuk analisis dan melaksanakan proses dalam persekitaran anda. OpenAI tidak menggunakan data yang diserahkan oleh pelanggan melalui APInya untuk melatih model atau menambah baik perkhidmatan. . Kemudian jalankan arahan terminal berikut untuk memasang perpustakaan yang diperlukan. pip需要改写的内容是:install需要改写的内容是:langchain需要改写的内容是:openai需要改写的内容是:tiktoken需要改写的内容是:faiss-cpu需要改写的内容是:pypdf
:
langchain: Anda akan menggunakannya untuk membuat dan mengurus aplikasi untuk pemprosesan teks dan linguistik rantaian analisis. Ia akan menyediakan modul untuk memuatkan dokumen, pembahagian teks, pembenaman dan storan volum.
OpenAI: Anda akan menggunakannya untuk menjalankan pertanyaan ,
- dan dapatkan hasil daripada model bahasa.
- tiktoken: Anda akan menggunakan ini untuk mengira bilangan token ( unit teks
- dalam teks yang diberikan) Apa yang perlu ditulis semula untuk menjejaki token dikira apabila berinteraksi dengan OpenAI yang mengecaj berdasarkan bilangan token yang anda gunakan ialah: API
- . FAISS: Anda akan menggunakannya untuk mencipta dan mengurus stor vektor, membenarkan pengambilan semula vektor serupa dengan pantas berdasarkan pembenaman. PyPDF: Perpustakaan ini mengekstrak teks daripada PDF. Ia membantu memuatkan PDF fail dan mengekstrak teksnya
- , untuk pemprosesan selanjutnya. Selepas memasang semua perpustakaan, persekitaran anda
- kini sedia sedia . get openai apa yang perlu ditulis semula adalah: API KEY Apabila anda membuat permintaan untuk Openai apa yang perlu ditulis semula adalah: api , anda perlu tambahkan
APIKunci sebagai sebahagian daripada permintaan. Kunci ini membolehkan APIpembekal mengesahkan bahawa permintaan itu datang daripada sumber yang sah dan anda
mempunyaikeizinan yang diperlukan untuk mengakses fungsinya. Apa yang perlu ditulis semula untuk mendapatkan OpenAI ialah: kunci API, masukkan platform OpenAI.
Kemudian di bawah akaun profil di bahagian atas sebelah kanan, klik pada "LihatAPI kekunci muncul APIRahsia halaman utama.
Klik butang "Buat Kunci Baharu"
. Namakan kunci
Namakan kunci
dan klik "Buat Kunci Baharu". OpenAI akan menjana kunci API, yang perlu anda salin dan simpan di tempat yang selamat. Atas sebab keselamatan, anda tidak akan dapat melihatnya lagi melalui akaun OpenAI anda. Jika anda kehilangan kunci , anda perlu menjana kunci baharu.
导入所需的库
为了能够使用安装在虚拟环境中的库,您需要导入它们。
from需要改写的内容是:langchain.document_loaders需要改写的内容是:import需要改写的内容是:PyPDFLoader,需要改写的内容是:TextLoaderfrom需要改写的内容是:langchain.text_splitter需要改写的内容是:import需要改写的内容是:CharacterTextSplitterfrom需要改写的内容是:langchain.embeddings.openai需要改写的内容是:import需要改写的内容是:OpenAIEmbeddingsfrom需要改写的内容是:langchain.vectorstores需要改写的内容是:import需要改写的内容是:FAISSfrom需要改写的内容是:langchain.chains需要改写的内容是:import需要改写的内容是:RetrievalQAfrom需要改写的内容是:langchain.llms需要改写的内容是:import需要改写的内容是:OpenAI
注意,您从LangChain导入了依赖项库,这让您可以使用LangChain框架的特定功能。
加载用于分析的文档
先创建一个含有API密钥的变量。稍后,您将在代码中使用该变量用于身份验证。
#需要改写的内容是:Hardcoded需要改写的内容是:API需要改写的内容是:keyopenai_api_key需要改写的内容是:=需要改写的内容是:"Your需要改写的内容是:API需要改写的内容是:key"
如果您打算与第三方共享您的代码,不建议对API密钥进行硬编码。对于打算分发的生产级代码,则改而使用环境变量。
接下来,创建一个加载文档的函数。该函数应该加载PDF或文本文件。如果文档既不是PDF文件,也不是文本文件,该函数会抛出值错误。
def需要改写的内容是:load_document(filename):if需要改写的内容是:filename.endswith(".pdf"):需要改写的内容是:loader需要改写的内容是:=需要改写的内容是:PyPDFLoader(filename)需要改写的内容是:documents需要改写的内容是:=需要改写的内容是:loader.load()需要改写的内容是:elif需要改写的内容是:filename.endswith(".txt"):需要改写的内容是:loader需要改写的内容是:=需要改写的内容是:TextLoader(filename)需要改写的内容是:documents需要改写的内容是:=需要改写的内容是:loader.load()需要改写的内容是:else:需要改写的内容是:raise需要改写的内容是:ValueError("Invalid需要改写的内容是:file需要改写的内容是:type")加载文档后,创建一个CharacterTextSplitter。该分割器将基于字符将已加载的文档分隔成更小的块。
需要改写的内容是:
text_splitter需要改写的内容是:=需要改写的内容是:CharacterTextSplitter(chunk_size=1000,需要改写的内容是:需要改写的内容是:chunk_overlap=30,需要改写的内容是:separator="\n")需要改写的内容是:return需要改写的内容是:text_splitter.split_documents(documents=documents)
分割文档可确保块的大小易于管理,仍与一些重叠的上下文相连接。这对于文本分析和信息检索之类的任务非常有用。
查询文档
您需要一种方法来查询上传的文档,以便从中获得洞察力。为此,创建一个以查询字符串和检索器作为输入的函数。然后,它使用检索器和OpenAI语言模型的实例创建一个RetrievalQA实例。
def需要改写的内容是:query_pdf(query,需要改写的内容是:retriever):qa需要改写的内容是:=需要改写的内容是:RetrievalQA.from_chain_type(llm=OpenAI(openai_api_key=openai_api_key),需要改写的内容是:chain_type="stuff",需要改写的内容是:retriever=retriever)result需要改写的内容是:=需要改写的内容是:qa.run(query)需要改写的内容是:print(result)
该函数使用创建的QA实例来运行查询并输出结果。
创建主函数
主函数将控制整个程序流。它将接受用户输入的文档文件名并加载该文档。然后为文本嵌入创建OpenAIEmbeddings实例,并基于已加载的文档和文本嵌入构造一个向量存储。将该向量存储保存到本地文件。
接下来,从本地文件加载持久的向量存储。然后输入一个循环,用户可以在其中输入查询。主函数将这些查询与持久化向量存储的检索器一起传递给query_pdf函数。循环将继续,直到用户输入“exit”。
def需要改写的内容是:main():需要改写的内容是:filename需要改写的内容是:=需要改写的内容是:input("Enter需要改写的内容是:the需要改写的内容是:name需要改写的内容是:of需要改写的内容是:the需要改写的内容是:document需要改写的内容是:(.pdf需要改写的内容是:or需要改写的内容是:.txt):\n")docs需要改写的内容是:=需要改写的内容是:load_document(filename)embeddings需要改写的内容是:=需要改写的内容是:OpenAIEmbeddings(openai_api_key=openai_api_key)vectorstore需要改写的内容是:=需要改写的内容是:FAISS.from_documents(docs,需要改写的内容是:embeddings)需要改写的内容是:vectorstore.save_local("faiss_index_constitution")persisted_vectorstore需要改写的内容是:=需要改写的内容是:FAISS.load_local("faiss_index_constitution",需要改写的内容是:embeddings)query需要改写的内容是:=需要改写的内容是:input("Type需要改写的内容是:in需要改写的内容是:your需要改写的内容是:query需要改写的内容是:(type需要改写的内容是:'exit'需要改写的内容是:to需要改写的内容是:quit):\n")while需要改写的内容是:query需要改写的内容是:!=需要改写的内容是:"exit":query_pdf(query,需要改写的内容是:persisted_vectorstore.as_retriever())query需要改写的内容是:=需要改写的内容是:input("Type需要改写的内容是:in需要改写的内容是:your需要改写的内容是:query需要改写的内容是:(type需要改写的内容是:'exit'需要改写的内容是:to需要改写的内容是:quit):\n")嵌入捕获词之间的语义关系。向量是一种可以表示一段文本的形式。
这段代码使用OpenAIEmbeddings生成的嵌入将文档中的文本数据转换成向量。然后使用FAISS对这些向量进行索引,以便高效地检索和比较相似的向量。这便于对上传的文档进行分析。
最后,如果用户独立运行程序,使用__name__需要改写的内容是:==需要改写的内容是:"__main__"构造函数来调用主函数:
if需要改写的内容是:__name__需要改写的内容是:==需要改写的内容是:"__main__":需要改写的内容是:main()
这个应用程序是一个命令行应用程序。作为一个扩展,您可以使用Streamlit为该应用程序添加Web界面。
执行文件分析
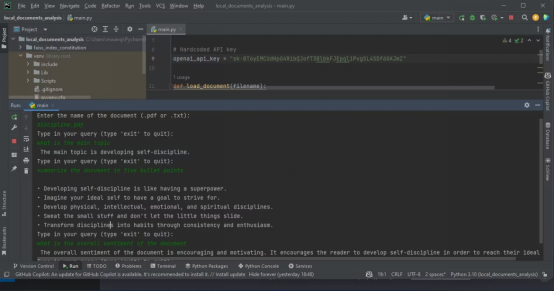
要执行文档分析,将所要分析的文档存储在项目所在的同一个文件夹中,然后运行该程序。它将询问所要分析的文档的名称。输入全名,然后输入查询,以便程序分析。
以下截图展示了对PDF进行分析的结果
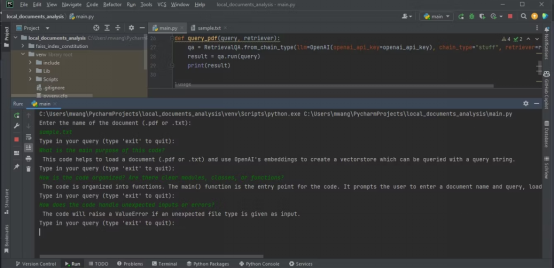
Output di bawah menunjukkan hasil analisis fail teks yang mengandungi dengan kod sumber.
Pastikan fail yang ingin anda analisis adalah dalam format PDF atau teks. Jika dokumen anda berada dalam format lain , anda boleh menggunakan alatan dalam talian untuk menukarnya kepada format PDF . Kod sumber lengkap tersedia dalam repositori kod GitHub: https://github.com/makeuseofcode/Document-analysis-using-LangChain-and-OpenAI
Tajuk asal: ditulis semula Kandungan yang perlu ditulis semula ialah: hingga Kandungan yang perlu ditulis semula ialah: Menganalisis Kandungan yang perlu ditulis semula ialah: Dokumen Kandungan yang perlu ditulis semula ialah: Dengan Kandungan yang perlu ditulis semula ialah : LangChain Kandungan yang perlu ditulis semula ialah: dan Kandungan yang perlu ditulis semula ialah: kandungan yang perlu ditulis semula ialah: Kandungannya ialah: OpenAI Kandungan yang perlu ditulis semula ialah: API , pengarang: Denis Kandungan yang perlu ditulis semula ialah: Kuria
Kandungan yang perlu ditulis semula ialah:
Atas ialah kandungan terperinci Cara menggunakan LangChain dan OpenAI API untuk analisis dokumen. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1379
1379
 52
52

 Paradigma pengaturcaraan baharu, apabila Spring Boot bertemu OpenAI
Feb 01, 2024 pm 09:18 PM
Paradigma pengaturcaraan baharu, apabila Spring Boot bertemu OpenAI
Feb 01, 2024 pm 09:18 PM
Pada tahun 2023, teknologi AI telah menjadi topik hangat dan memberi impak besar kepada pelbagai industri, terutamanya dalam bidang pengaturcaraan. Orang ramai semakin menyedari kepentingan teknologi AI, dan komuniti Spring tidak terkecuali. Dengan kemajuan berterusan teknologi GenAI (General Artificial Intelligence), ia menjadi penting dan mendesak untuk memudahkan penciptaan aplikasi dengan fungsi AI. Dengan latar belakang ini, "SpringAI" muncul, bertujuan untuk memudahkan proses membangunkan aplikasi berfungsi AI, menjadikannya mudah dan intuitif serta mengelakkan kerumitan yang tidak perlu. Melalui "SpringAI", pembangun boleh membina aplikasi dengan lebih mudah dengan fungsi AI, menjadikannya lebih mudah untuk digunakan dan dikendalikan.
 Memilih model benam yang paling sesuai dengan data anda: Ujian perbandingan OpenAI dan benam berbilang bahasa sumber terbuka
Feb 26, 2024 pm 06:10 PM
Memilih model benam yang paling sesuai dengan data anda: Ujian perbandingan OpenAI dan benam berbilang bahasa sumber terbuka
Feb 26, 2024 pm 06:10 PM
OpenAI baru-baru ini mengumumkan pelancaran model benam generasi terbaru mereka embeddingv3, yang mereka dakwa sebagai model benam paling berprestasi dengan prestasi berbilang bahasa yang lebih tinggi. Kumpulan model ini dibahagikan kepada dua jenis: pembenaman teks-3-kecil yang lebih kecil dan pembenaman teks-3-besar yang lebih berkuasa dan lebih besar. Sedikit maklumat didedahkan tentang cara model ini direka bentuk dan dilatih, dan model hanya boleh diakses melalui API berbayar. Jadi terdapat banyak model pembenaman sumber terbuka Tetapi bagaimana model sumber terbuka ini dibandingkan dengan model sumber tertutup OpenAI? Artikel ini akan membandingkan secara empirik prestasi model baharu ini dengan model sumber terbuka. Kami merancang untuk membuat data
 Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
Jika jawapan yang diberikan oleh model AI tidak dapat difahami sama sekali, adakah anda berani menggunakannya? Memandangkan sistem pembelajaran mesin digunakan dalam bidang yang lebih penting, menjadi semakin penting untuk menunjukkan sebab kita boleh mempercayai output mereka, dan bila tidak mempercayainya. Satu cara yang mungkin untuk mendapatkan kepercayaan dalam output sistem yang kompleks adalah dengan menghendaki sistem menghasilkan tafsiran outputnya yang boleh dibaca oleh manusia atau sistem lain yang dipercayai, iaitu, difahami sepenuhnya sehingga apa-apa ralat yang mungkin boleh dilakukan. dijumpai. Contohnya, untuk membina kepercayaan dalam sistem kehakiman, kami memerlukan mahkamah memberikan pendapat bertulis yang jelas dan boleh dibaca yang menjelaskan dan menyokong keputusan mereka. Untuk model bahasa yang besar, kita juga boleh menggunakan pendekatan yang sama. Walau bagaimanapun, apabila mengambil pendekatan ini, pastikan model bahasa menjana
 Editor Zed berasaskan Rust telah menjadi sumber terbuka, dengan sokongan terbina dalam untuk OpenAI dan GitHub Copilot
Feb 01, 2024 pm 02:51 PM
Editor Zed berasaskan Rust telah menjadi sumber terbuka, dengan sokongan terbina dalam untuk OpenAI dan GitHub Copilot
Feb 01, 2024 pm 02:51 PM
Pengarang丨Disusun oleh TimAnderson丨Dihasilkan oleh Noah|51CTO Technology Stack (WeChat ID: blog51cto) Projek editor Zed masih dalam peringkat pra-keluaran dan telah menjadi sumber terbuka di bawah lesen AGPL, GPL dan Apache. Editor menampilkan prestasi tinggi dan berbilang pilihan dibantu AI, tetapi pada masa ini hanya tersedia pada platform Mac. Nathan Sobo menjelaskan dalam catatan bahawa dalam asas kod projek Zed di GitHub, bahagian editor dilesenkan di bawah GPL, komponen bahagian pelayan dilesenkan di bawah AGPL dan bahagian GPUI (GPU Accelerated User) The interface) mengguna pakai Lesen Apache2.0. GPUI ialah produk yang dibangunkan oleh pasukan Zed
 Jangan tunggu OpenAI, tunggu Open-Sora menjadi sumber terbuka sepenuhnya
Mar 18, 2024 pm 08:40 PM
Jangan tunggu OpenAI, tunggu Open-Sora menjadi sumber terbuka sepenuhnya
Mar 18, 2024 pm 08:40 PM
Tidak lama dahulu, OpenAISora dengan cepat menjadi popular dengan kesan penjanaan video yang menakjubkan Ia menonjol di kalangan ramai model video sastera dan menjadi tumpuan perhatian global. Berikutan pelancaran proses pembiakan inferens latihan Sora dengan pengurangan kos sebanyak 46% 2 minggu lalu, pasukan Colossal-AI telah menggunakan sumber terbuka sepenuhnya model penjanaan video seni bina mirip Sora pertama di dunia "Open-Sora1.0", meliputi keseluruhan proses latihan, termasuk pemprosesan data, semua butiran latihan dan berat model, dan berganding bahu dengan peminat AI global untuk mempromosikan era baharu penciptaan video. Untuk melihat sekilas, mari lihat video bandar yang sibuk yang dihasilkan oleh model "Open-Sora1.0" yang dikeluarkan oleh pasukan Colossal-AI. Buka-Sora1.0
 Microsoft, OpenAI merancang untuk melabur $100 juta dalam robot humanoid! Netizen memanggil Musk
Feb 01, 2024 am 11:18 AM
Microsoft, OpenAI merancang untuk melabur $100 juta dalam robot humanoid! Netizen memanggil Musk
Feb 01, 2024 am 11:18 AM
Microsoft dan OpenAI didedahkan akan melabur sejumlah besar wang ke dalam permulaan robot humanoid pada awal tahun ini. Antaranya, Microsoft merancang untuk melabur AS$95 juta, dan OpenAI akan melabur AS$5 juta. Menurut Bloomberg, syarikat itu dijangka mengumpul sejumlah AS$500 juta dalam pusingan ini, dan penilaian pra-wangnya mungkin mencecah AS$1.9 bilion. Apa yang menarik mereka? Mari kita lihat pencapaian robotik syarikat ini terlebih dahulu. Robot ini semuanya berwarna perak dan hitam, dan penampilannya menyerupai imej robot dalam filem fiksyen sains Hollywood: Sekarang, dia meletakkan kapsul kopi ke dalam mesin kopi: Jika ia tidak diletakkan dengan betul, ia akan menyesuaikan dirinya tanpa sebarang kawalan jauh manusia: Walau bagaimanapun, Selepas beberapa ketika, secawan kopi boleh dibawa pergi dan dinikmati: Adakah anda mempunyai ahli keluarga yang mengenalinya Ya, robot ini telah dicipta suatu masa dahulu?
 Prestasi larian tempatan perkhidmatan Embedding melebihi OpenAI Text-Embedding-Ada-002, yang sangat mudah!
Apr 15, 2024 am 09:01 AM
Prestasi larian tempatan perkhidmatan Embedding melebihi OpenAI Text-Embedding-Ada-002, yang sangat mudah!
Apr 15, 2024 am 09:01 AM
Ollama ialah alat super praktikal yang membolehkan anda menjalankan model sumber terbuka dengan mudah seperti Llama2, Mistral dan Gemma secara tempatan. Dalam artikel ini, saya akan memperkenalkan cara menggunakan Ollama untuk mengvektorkan teks. Jika anda belum memasang Ollama secara tempatan, anda boleh membaca artikel ini. Dalam artikel ini kita akan menggunakan model nomic-embed-text[2]. Ia ialah pengekod teks yang mengatasi prestasi OpenAI text-embedding-ada-002 dan text-embedding-3-small pada konteks pendek dan tugas konteks panjang. Mulakan perkhidmatan nomic-embed-text apabila anda telah berjaya memasang o
 Tiba-tiba! OpenAI memecat sekutu Ilya kerana disyaki kebocoran maklumat
Apr 15, 2024 am 09:01 AM
Tiba-tiba! OpenAI memecat sekutu Ilya kerana disyaki kebocoran maklumat
Apr 15, 2024 am 09:01 AM
Tiba-tiba! OpenAI memecat orang, sebabnya: kebocoran maklumat yang disyaki. Salah satunya ialah Leopold Aschenbrenner, sekutu ketua saintis Ilya yang hilang dan ahli teras pasukan Superalignment. Orang lain juga tidak mudah. Dia ialah Pavel Izmailov, seorang penyelidik dalam pasukan inferens LLM, yang juga bekerja pada pasukan penjajaran super. Tidak jelas maklumat yang dibocorkan oleh kedua-dua lelaki itu. Selepas berita itu didedahkan, ramai netizen menyatakan "agak terkejut": Saya melihat siaran Aschenbrenner tidak lama dahulu dan merasakan bahawa dia semakin meningkat dalam kerjayanya Saya tidak menjangkakan perubahan sedemikian. Sesetengah netizen dalam gambar berfikir: OpenAI kehilangan Aschenbrenner, I
