
 Peranti teknologi
AI
Digabungkan dengan enjin fizik, model resapan GPT-4+ menghasilkan video yang realistik, koheren dan munasabah
Peranti teknologi
AI
Digabungkan dengan enjin fizik, model resapan GPT-4+ menghasilkan video yang realistik, koheren dan munasabah
Digabungkan dengan enjin fizik, model resapan GPT-4+ menghasilkan video yang realistik, koheren dan munasabah

Pengenalan model penyebaran telah menggalakkan pembangunan teknologi video penjanaan teks Walau bagaimanapun, kaedah ini selalunya mahal dari segi pengiraan dan sukar untuk mencapai video gerakan objek yang lancar
Untuk menangani masalah ini, penyelidik dari Shenzhen. Institut Teknologi Lanjutan, Akademi Sains China, Penyelidik dari Akademi Sains Universiti China dan Makmal Kecerdasan Buatan VIVO bersama-sama mencadangkan rangka kerja baharu yang dipanggil GPT4Motion yang boleh menjana video teks tanpa latihan. GPT4Motion menggabungkan keupayaan perancangan model bahasa besar seperti GPT, keupayaan simulasi fizikal yang disediakan oleh perisian Blender dan keupayaan penjanaan teks model penyebaran, bertujuan untuk meningkatkan kualiti sintesis video dengan lebih baik

- Pautan projek: https://gpt4motion.github.io/
Pautan kod: https://github.com/jiaxilv /GPT4Motion
GPT4Motion menggunakan GPT-4 untuk menjana skrip Blender berdasarkan gesaan teks input pengguna. Ia memanfaatkan enjin fizik Blender untuk mencipta komponen pemandangan asas dan merangkumnya sebagai gerakan silang bingkai yang berterusan. Komponen ini kemudiannya dimasukkan ke dalam model penyebaran untuk menghasilkan video yang sepadan dengan gesaan teks
Hasil eksperimen menunjukkan bahawa GPT4Motion boleh menjana video berkualiti tinggi dengan cekap sambil mengekalkan konsistensi gerakan dan konsistensi entiti. Perlu diingat bahawa GPT4Motion menggunakan enjin fizik untuk menjadikan video yang dihasilkan lebih realistik. Ini memberikan perspektif baharu untuk video penjanaan teks
Mari kita lihat dahulu kesan penjanaan GPT4Motion, seperti memasukkan gesaan teks: "Baju-T putih berkibar-kibar ditiup angin", "T-T putih baju berkibar ditiup angin", "baju T putih berkibar ditiup angin kencang". Disebabkan oleh kekuatan angin yang berbeza, amplitud baju-T putih yang berkibar dalam video yang dihasilkan oleh GPT4Motion juga berbeza:

Dari segi corak aliran cecair, video yang dihasilkan oleh GPT4Motion juga boleh menunjukkan ia dengan baik:
Bola keranjang berputar dan jatuh dari udara:
Pengenalan kaedah
Matlamat kajian ini adalah untuk menghasilkan video yang pantas berdasarkan ciri fizikal pengguna adegan gerakan fizikal asas. Sifat fizikal selalunya berkaitan dengan bahan objek. Para penyelidik memberi tumpuan kepada simulasi tiga bahan objek biasa dalam kehidupan seharian: 1) objek tegar, yang boleh mengekalkan bentuknya tanpa berubah apabila dikenakan paksaan; mempamerkan pergerakan berterusan dan boleh berubah bentuk.
Selain itu, para penyelidik memberi perhatian khusus kepada beberapa mod pergerakan tipikal bahan-bahan ini, termasuk perlanggaran (kesan langsung antara objek), kesan angin (pergerakan yang disebabkan oleh aliran udara), dan aliran (berterusan dan bergerak dalam satu arah) . Mensimulasikan senario fizikal ini selalunya memerlukan pengetahuan tentang mekanik klasik, mekanik bendalir dan fizik lain. Model penyebaran semasa yang memfokuskan pada video yang dihasilkan teks adalah sukar untuk memperoleh pengetahuan fizikal yang kompleks ini melalui latihan, dan oleh itu tidak dapat menghasilkan video yang mematuhi sifat fizikal Kelebihan GPT4Motion adalah untuk memastikan bahawa video yang dihasilkan bukan sahaja konsisten dengan menggesa input oleh pengguna, Dan ia juga betul dari segi fizikal. Pemahaman semantik GPT-4 dan keupayaan penjanaan kod boleh menukar gesaan pengguna kepada skrip Python Blender, yang boleh memacu enjin fizik terbina dalam Blender untuk mensimulasikan adegan fizikal yang sepadan. Selain itu, kajian juga menggunakan ControlNet, mengambil keputusan dinamik simulasi Blender sebagai input untuk membimbing model resapan untuk menjana bingkai video demi bingkai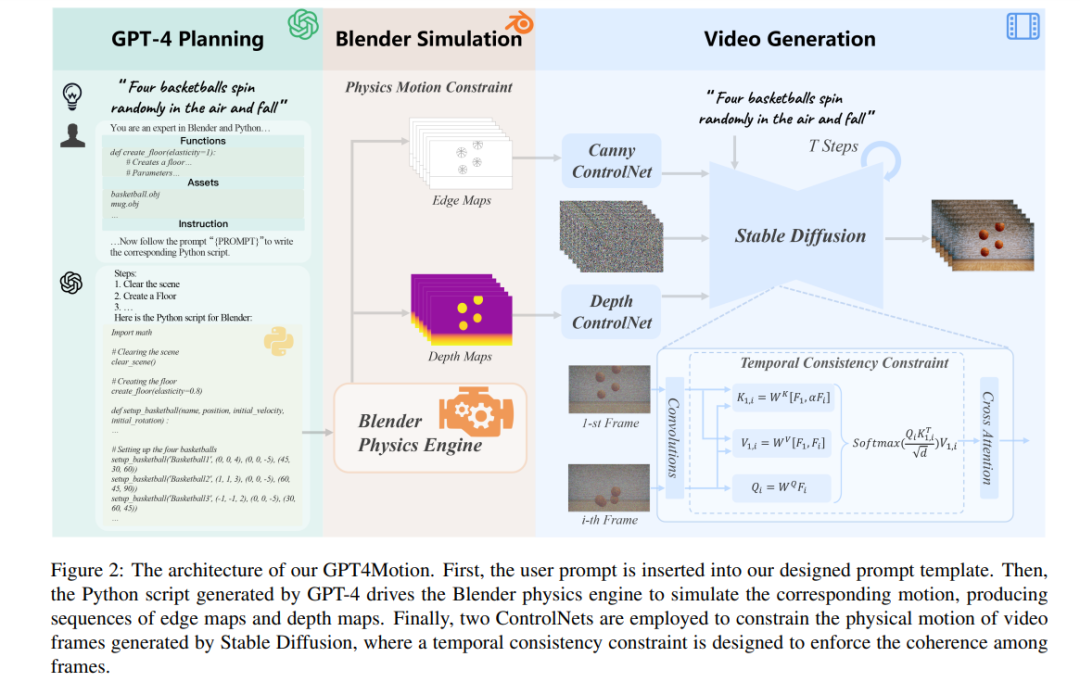
Menggunakan GPT-4 untuk mengaktifkan Blender untuk operasi simulasi🎜🎜🎜
Penyelidik memerhatikan bahawa walaupun GPT-4 mempunyai pemahaman tertentu tentang API Python Blender, keupayaannya untuk menjana skrip Python Blender berdasarkan gesaan pengguna masih kurang. Di satu pihak, meminta GPT-4 untuk mencipta walaupun model 3D yang mudah (seperti bola keranjang) secara langsung dalam Blender nampaknya seperti tugas yang sukar. Sebaliknya, memandangkan API Python Blender mempunyai sumber yang lebih sedikit dan versi API dikemas kini dengan cepat, adalah mudah untuk GPT-4 menyalahgunakan ciri tertentu atau membuat ralat disebabkan perbezaan versi. Untuk menyelesaikan masalah ini, kajian mencadangkan penyelesaian berikut:
- Gunakan model 3D luaran
- untuk merangkum fungsi Blender
- Tukar gesaan pengguna kepada sifat fizikal

Kandungan yang ditulis semula: Membuat video yang mematuhi undang-undang fizik
Kajian ini bertujuan untuk menjana, berdasarkan pada usul dan syarat yang disediakan oleh pengguna Blender, Video yang konsisten dengan teks dan realistik secara visual. Untuk tujuan ini, kajian itu mengguna pakai Model DifusiKawal sifat fizikal
- Rajah 4 menunjukkan video gerakan bola keranjang yang dijana oleh GPT4Motion di bawah tiga gesaan, yang melibatkan kejatuhan dan perlanggaran bola keranjang. Di sebelah kiri Rajah 4, bola keranjang mengekalkan tekstur yang sangat realistik semasa ia berputar dan dengan tepat mereplikasi gelagat melantunnya selepas hentaman dengan tanah. Bahagian tengah Rajah 4 menunjukkan kaedah ini boleh mengawal bilangan bola keranjang dengan tepat dan berkesan menjana perlanggaran dan lantunan yang berlaku apabila berbilang bola keranjang mendarat. Yang menghairankan, seperti yang ditunjukkan di sebelah kanan Rajah 4, apabila pengguna meminta untuk melempar bola keranjang ke arah kamera, GPT-4 akan mengira halaju awal yang diperlukan berdasarkan masa jatuh bola keranjang dalam skrip yang dihasilkan, dengan itu mencapai visual yang realistik kesan. Ini menunjukkan bahawa GPT4Motion boleh digabungkan dengan pengetahuan fizik yang dikuasai oleh GPT-4 untuk mengawal kandungan video yang dihasilkan daripada
- kain yang ditiup angin. Rajah 5 dan 6 menunjukkan keupayaan GPT4Motion untuk menghasilkan pergerakan kain di bawah pengaruh angin. Memanfaatkan enjin fizik sedia ada untuk simulasi, GPT4Motion boleh menjana gelombang dan ombak di bawah kuasa angin yang berbeza. Rajah 5 menunjukkan hasil bendera yang dikibarkan. Bendera memaparkan corak riak dan ombak yang kompleks dalam keadaan angin yang berbeza-beza. Rajah 6 menunjukkan pergerakan objek kain tidak teratur, baju-T, di bawah daya angin yang berbeza. Dijejaskan oleh sifat fizikal fabrik, seperti keanjalan dan berat, baju-T goyah dan berpusing, dan mengalami perubahan kedutan yang ketara.
Rajah 7 menunjukkan tiga video menuang air yang berbeza kelikatan ke dalam mug. Apabila kelikatan air rendah, air yang mengalir berlanggar dengan air di dalam cawan dan bergabung, membentuk fenomena aliran gelora yang kompleks. Apabila kelikatan meningkat, aliran air menjadi lebih perlahan dan cecair mula melekat antara satu sama lain

Dalam Rajah 1, GPT4Motion dibandingkan secara visual dengan kaedah asas yang lain. Adalah jelas bahawa keputusan kaedah garis dasar tidak sepadan dengan gesaan pengguna. DirecT2V dan Text2Video-Zero mempunyai kelemahan dalam kesetiaan tekstur dan ketekalan gerakan, manakala AnimateDiff dan ModelScope meningkatkan kelancaran video, tetapi masih terdapat ruang untuk penambahbaikan dalam ketekalan tekstur dan kesetiaan gerakan. Berbanding dengan kaedah ini, GPT4Motion boleh menghasilkan perubahan tekstur yang licin semasa bola keranjang jatuh dan melantun selepas berlanggar dengan lantai, yang kelihatan lebih realistik

Seperti yang ditunjukkan dalam Rajah 8 (baris pertama), AnimateDiff dan Video yang dihasilkan oleh Text2Video-Zero mempunyai artifak/herotan pada bendera, manakala ModelScope dan DirecT2V tidak dapat menjana kecerunan bendera yang berkibar dengan lancar ditiup angin. Walau bagaimanapun, seperti yang ditunjukkan di tengah-tengah Rajah 5, video yang dihasilkan oleh GPT4Motion boleh menunjukkan perubahan berterusan kedutan dan riak dalam bendera di bawah pengaruh graviti dan angin.

Keputusan semua garis dasar tidak konsisten dengan gesaan pengguna, seperti yang ditunjukkan dalam baris kedua dalam Rajah 8. Walaupun video AnimateDiff dan ModelScope mencerminkan perubahan dalam aliran air, mereka tidak dapat menangkap kesan fizikal air yang dituangkan ke dalam cawan. Sebaliknya, video yang dihasilkan oleh Text2VideoZero dan DirecT2V mencipta cawan yang sentiasa bergegar. Sebaliknya, seperti yang ditunjukkan dalam Rajah 7 (kiri), video yang dihasilkan oleh GPT4Motion dengan tepat menggambarkan pergolakan apabila aliran air berlanggar dengan cawan, dan kesannya lebih realistik
Pembaca yang berminat boleh membaca kertas asal untuk mengetahui lebih lanjut Banyak kandungan kajian
Atas ialah kandungan terperinci Digabungkan dengan enjin fizik, model resapan GPT-4+ menghasilkan video yang realistik, koheren dan munasabah. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Sumber terbuka! Di luar ZoeDepth! DepthFM: Anggaran kedalaman monokular yang cepat dan tepat!
Apr 03, 2024 pm 12:04 PM
Sumber terbuka! Di luar ZoeDepth! DepthFM: Anggaran kedalaman monokular yang cepat dan tepat!
Apr 03, 2024 pm 12:04 PM
0. Apakah fungsi artikel ini? Kami mencadangkan DepthFM: model anggaran kedalaman monokular generatif yang serba boleh dan pantas. Sebagai tambahan kepada tugas anggaran kedalaman tradisional, DepthFM juga menunjukkan keupayaan terkini dalam tugas hiliran seperti mengecat kedalaman. DepthFM cekap dan boleh mensintesis peta kedalaman dalam beberapa langkah inferens. Mari kita baca karya ini bersama-sama ~ 1. Tajuk maklumat kertas: DepthFM: FastMonocularDepthEstimationwithFlowMatching Pengarang: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 Apr 09, 2024 am 11:52 AM
Apr 09, 2024 am 11:52 AM
AI memang mengubah matematik. Baru-baru ini, Tao Zhexuan, yang telah mengambil perhatian terhadap isu ini, telah memajukan keluaran terbaru "Buletin Persatuan Matematik Amerika" (Buletin Persatuan Matematik Amerika). Memfokuskan pada topik "Adakah mesin akan mengubah matematik?", ramai ahli matematik menyatakan pendapat mereka Seluruh proses itu penuh dengan percikan api, tegar dan menarik. Penulis mempunyai barisan yang kuat, termasuk pemenang Fields Medal Akshay Venkatesh, ahli matematik China Zheng Lejun, saintis komputer NYU Ernest Davis dan ramai lagi sarjana terkenal dalam industri. Dunia AI telah berubah secara mendadak Anda tahu, banyak artikel ini telah dihantar setahun yang lalu.
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
 Kelajuan Internet Data Selular Perlahan pada iPhone: Pembetulan
May 03, 2024 pm 09:01 PM
Kelajuan Internet Data Selular Perlahan pada iPhone: Pembetulan
May 03, 2024 pm 09:01 PM
Menghadapi ketinggalan, sambungan data mudah alih perlahan pada iPhone? Biasanya, kekuatan internet selular pada telefon anda bergantung pada beberapa faktor seperti rantau, jenis rangkaian selular, jenis perayauan, dsb. Terdapat beberapa perkara yang boleh anda lakukan untuk mendapatkan sambungan Internet selular yang lebih pantas dan boleh dipercayai. Betulkan 1 – Paksa Mulakan Semula iPhone Kadangkala, paksa memulakan semula peranti anda hanya menetapkan semula banyak perkara, termasuk sambungan selular. Langkah 1 – Hanya tekan kekunci naikkan kelantangan sekali dan lepaskan. Seterusnya, tekan kekunci Turun Kelantangan dan lepaskannya semula. Langkah 2 - Bahagian seterusnya proses adalah untuk menahan butang di sebelah kanan. Biarkan iPhone selesai dimulakan semula. Dayakan data selular dan semak kelajuan rangkaian. Semak semula Betulkan 2 – Tukar mod data Walaupun 5G menawarkan kelajuan rangkaian yang lebih baik, ia berfungsi lebih baik apabila isyarat lemah
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
Pengesanan objek ialah masalah yang agak matang dalam sistem pemanduan autonomi, antaranya pengesanan pejalan kaki adalah salah satu algoritma terawal untuk digunakan. Penyelidikan yang sangat komprehensif telah dijalankan dalam kebanyakan kertas kerja. Walau bagaimanapun, persepsi jarak menggunakan kamera fisheye untuk pandangan sekeliling agak kurang dikaji. Disebabkan herotan jejari yang besar, perwakilan kotak sempadan standard sukar dilaksanakan dalam kamera fisheye. Untuk mengurangkan perihalan di atas, kami meneroka kotak sempadan lanjutan, elips dan reka bentuk poligon am ke dalam perwakilan kutub/sudut dan mentakrifkan metrik mIOU pembahagian contoh untuk menganalisis perwakilan ini. Model fisheyeDetNet yang dicadangkan dengan bentuk poligon mengatasi model lain dan pada masa yang sama mencapai 49.5% mAP pada set data kamera fisheye Valeo untuk pemanduan autonomi
 Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Video terbaru robot Tesla Optimus dikeluarkan, dan ia sudah boleh berfungsi di kilang. Pada kelajuan biasa, ia mengisih bateri (bateri 4680 Tesla) seperti ini: Pegawai itu juga mengeluarkan rupanya pada kelajuan 20x - pada "stesen kerja" kecil, memilih dan memilih dan memilih: Kali ini ia dikeluarkan Salah satu sorotan video itu ialah Optimus menyelesaikan kerja ini di kilang, sepenuhnya secara autonomi, tanpa campur tangan manusia sepanjang proses. Dan dari perspektif Optimus, ia juga boleh mengambil dan meletakkan bateri yang bengkok, memfokuskan pada pembetulan ralat automatik: Berkenaan tangan Optimus, saintis NVIDIA Jim Fan memberikan penilaian yang tinggi: Tangan Optimus adalah robot lima jari di dunia paling cerdik. Tangannya bukan sahaja boleh disentuh
