

Perkembangan pesat model bahasa besar tahun ini telah menyebabkan model seperti BERT kini dipanggil model "kecil". Dalam pertandingan peperiksaan sains LLM Kaggle, pemain yang menggunakan deberta mencapai tempat keempat, yang merupakan keputusan yang cemerlang. Oleh itu, dalam domain atau keperluan tertentu, model bahasa yang besar tidak semestinya diperlukan sebagai penyelesaian terbaik, dan model kecil juga mempunyai tempatnya. Oleh itu, apa yang akan kami perkenalkan hari ini ialah PubMedBERT, sebuah kertas kerja yang diterbitkan oleh Microsoft Research di ACM pada 2022. Model ini melatih BERT dari awal dengan menggunakan korpora khusus domain
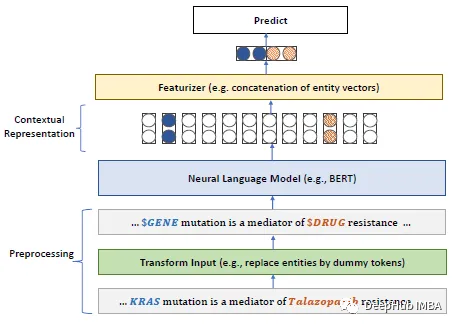
Berikut adalah Perkara utama kertas kerja:
Untuk domain tertentu dengan jumlah teks tidak berlabel yang banyak, seperti medan bioperubatan, model bahasa pralatihan dari awal adalah lebih berkesan daripada pralatihan model bahasa domain am secara berterusan. Untuk tujuan ini, kami mencadangkan Penanda Aras Pemahaman dan Penaakulan Bahasa Bioperubatan (BLURB) untuk pralatihan khusus domain
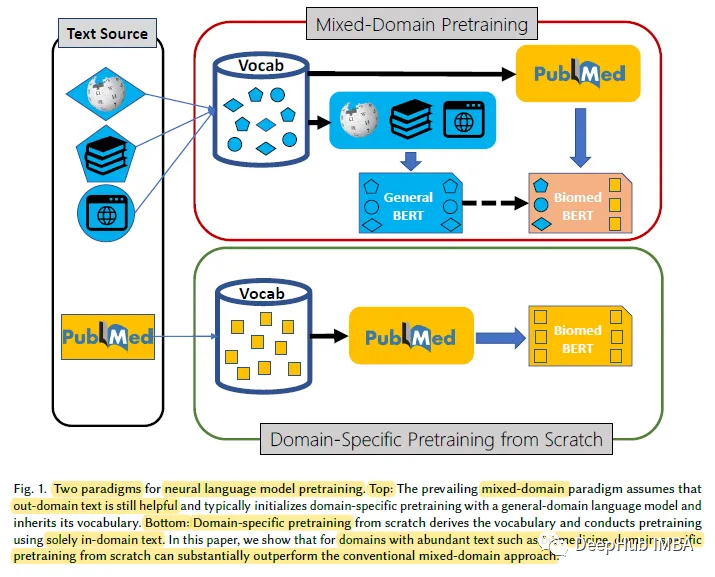
Domain -pra-latihan khusus dengan ketara mengatasi prestasi pra-latihan berterusan model bahasa tujuan umum, menunjukkan bahawa andaian lazim yang menyokong pra-latihan domain campuran tidak selalu digunakan.
Menurut penulis, BIRU [45] adalah percubaan pertama untuk mencipta penanda aras NLP dalam bidang bioperubatan. Tetapi liputan BLUE adalah terhad. Untuk aplikasi bioperubatan berdasarkan pubmed, penulis mencadangkan Penanda Aras Pemahaman dan Penaakulan Bahasa Bioperubatan (BLURB).
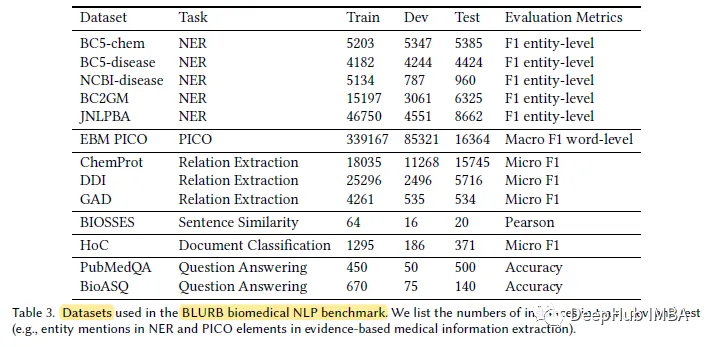
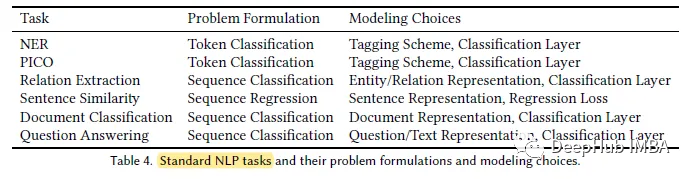
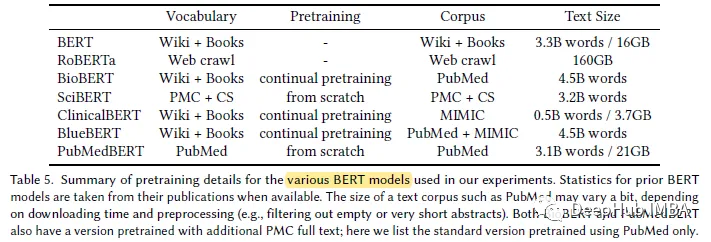
Atas ialah kandungan terperinci Model pra-latihan khusus untuk domain NLP bioperubatan: PubMedBERT. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



