
 Peranti teknologi
AI
LLMLingua: Sepadukan LlamaIndex, mampatkan petunjuk dan menyediakan perkhidmatan inferens model bahasa besar yang cekap
Peranti teknologi
AI
LLMLingua: Sepadukan LlamaIndex, mampatkan petunjuk dan menyediakan perkhidmatan inferens model bahasa besar yang cekap
LLMLingua: Sepadukan LlamaIndex, mampatkan petunjuk dan menyediakan perkhidmatan inferens model bahasa besar yang cekap

Kemunculan model bahasa besar (LLM) telah merangsang inovasi dalam pelbagai bidang. Walau bagaimanapun, peningkatan kerumitan gesaan, didorong oleh strategi seperti gesaan rantaian pemikiran (CoT) dan pembelajaran kontekstual (ICL), menimbulkan cabaran pengiraan. Gesaan yang panjang ini memerlukan sumber yang besar untuk membuat penaakulan dan oleh itu memerlukan penyelesaian yang cekap. Artikel ini akan memperkenalkan integrasi LLMLingua dengan LlamaIndex proprietari untuk melakukan inferens yang cekap
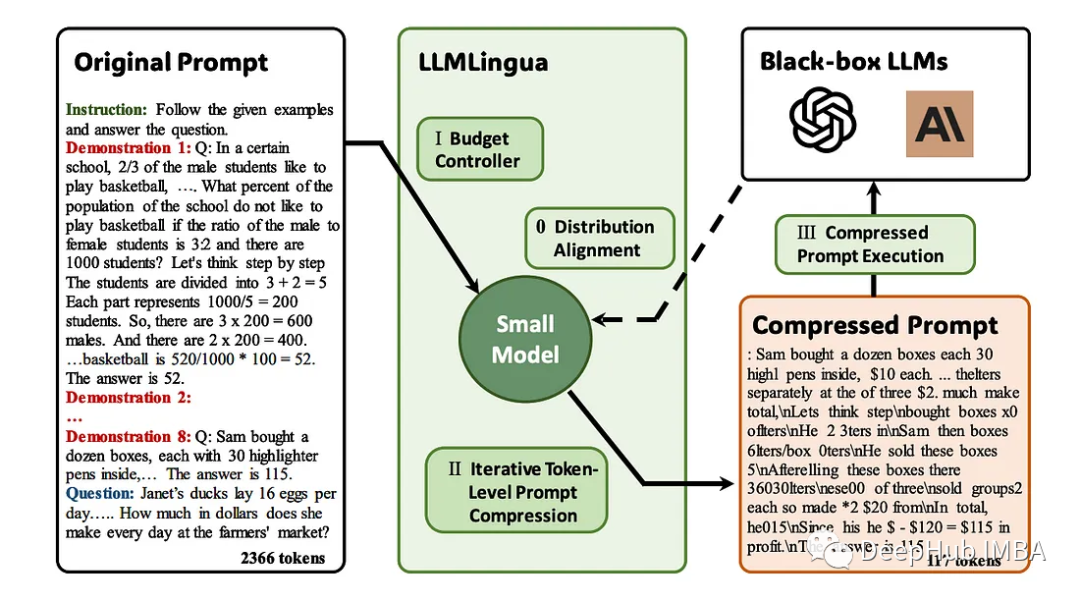
LLMLlingua ialah kertas kerja yang diterbitkan oleh penyelidik Microsoft di EMNLP 2023. LongLLMLingua ialah kaedah yang meningkatkan pemampatan dalam konteks yang panjang dan pantas . untuk keupayaan untuk memahami maklumat penting.
LLMLingua bekerja bersama-sama dengan llamindex
LLMLingua muncul sebagai penyelesaian perintis untuk gesaan verbose dalam aplikasi LLM. Pendekatan ini memberi tumpuan kepada memampatkan gesaan yang panjang sambil memastikan integriti semantik dan meningkatkan kelajuan inferens. Ia menggabungkan pelbagai strategi mampatan untuk menyediakan cara yang halus untuk mengimbangi panjang petunjuk dan kecekapan pengiraan.
Berikut ialah kelebihan penyepaduan LLMLingua dan LlamaIndex:
Penyepaduan LLMLingua dan LlamaIndex menandakan langkah penting untuk llm dalam pengoptimuman pantas. LlamaIndex ialah repositori khusus yang mengandungi pembayang pra-dioptimumkan yang disesuaikan untuk pelbagai aplikasi LLM, dan melalui penyepaduan ini LLMLingua boleh mengakses satu set pembayang khusus domain yang diperhalusi, dengan itu meningkatkan keupayaan pemampatan pembayangnya.
LLMLingua meningkatkan kecekapan aplikasi LLM melalui sinergi dengan perpustakaan petunjuk pengoptimuman LlamaIndex. Dengan memanfaatkan isyarat khusus LLAMA, LLMLingua boleh memperhalusi strategi pemampatannya untuk memastikan konteks khusus domain dipelihara sambil mengurangkan panjang isyarat. Kerjasama ini mempercepatkan inferens secara mendadak sambil mengekalkan nuansa domain utama
Penyepaduan LLMLingua dengan LlamaIndex meluaskan impaknya pada aplikasi LLM berskala besar. Dengan memanfaatkan petua pakar LLAMA, LLMLingua telah mengoptimumkan teknologi pemampatannya, mengurangkan beban pengiraan memproses petua yang panjang. Penyepaduan ini bukan sahaja mempercepatkan inferens tetapi juga memastikan pengekalan maklumat khusus domain kritikal.
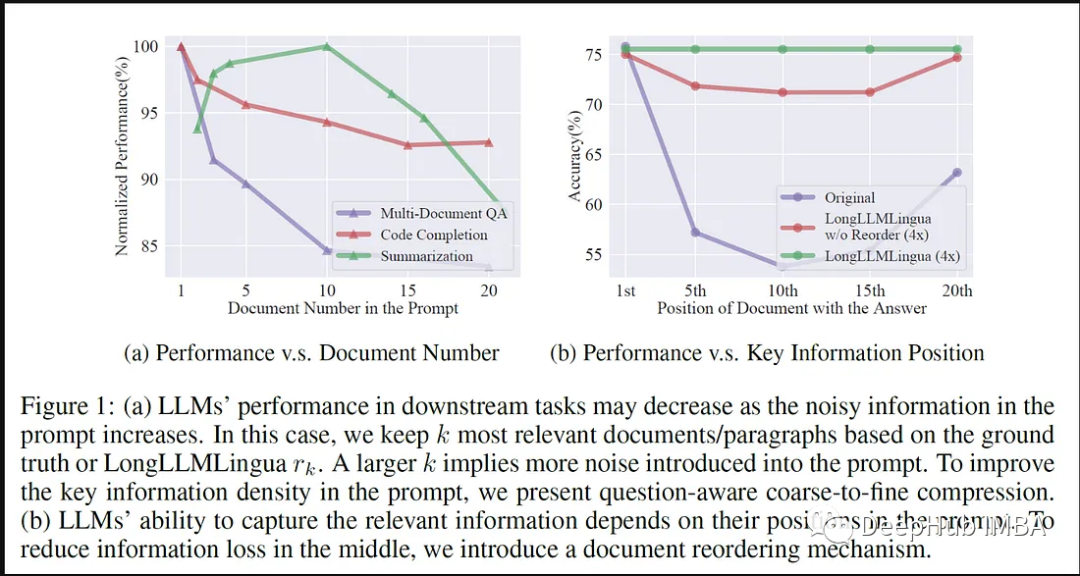
Aliran kerja antara LLMLingua dan LlamaIndex
Menggunakan LlamaIndex untuk melaksanakan LLMLingua memerlukan satu siri proses berstruktur, termasuk penggunaan perpustakaan inferens khusus untuk mencapai pembayang yang lebih pantas dan cekap
1 . Integrasi Rangka KerjaMula-mula anda perlu mewujudkan hubungan antara LLMLingua dan LlamaIndex. Ini termasuk hak akses, konfigurasi API dan mewujudkan sambungan untuk mendapatkan semula tepat pada masanya.
2. Mendapatkan semula petua pra-pengoptimuman
LlamaIndex berfungsi sebagai repositori khusus yang mengandungi petua pra-pengoptimuman yang disesuaikan untuk pelbagai aplikasi LLM. LLMLingua mengakses repositori ini, mendapatkan pembayang khusus domain dan menggunakan pembayang ini untuk pemampatan
3. Teknologi Pemampatan Petunjuk
LLMLingua menggunakan kaedah pemampatan pembayangnya untuk memudahkan pemampatan. Teknik ini memfokuskan pada memampatkan gesaan yang panjang sambil memastikan ketekalan semantik, dengan itu meningkatkan kelajuan inferens tanpa menjejaskan konteks atau perkaitan.
4. Perhalusi strategi pemampatan
LLMLingua memperhalusi strategi pemampatannya berdasarkan petua khusus yang diperolehi daripada LlamaIndex. Proses penghalusan ini memastikan bahawa nuansa khusus domain dipelihara sambil mengurangkan panjang segera dengan cekap.
5. Pelaksanaan dan Inferens
Selepas pemampatan menggunakan strategi tersuai LLMLingua dan digabungkan dengan pembayang pra-pengoptimuman LlamaIndex, pembayang yang terhasil boleh digunakan untuk tugasan inferens LLM. Pada peringkat ini, kami melakukan pembayang mampatan dalam rangka kerja LLM untuk membolehkan inferens sedar konteks yang cekap
6 Penambahbaikan dan penambahbaikan berulang
Pelaksanaan kod secara berterusan mengalami pemurnian berulang. Proses ini termasuk menambah baik algoritma mampatan, mengoptimumkan perolehan semula pembayang daripada LlamaIndex dan memperhalusi penyepaduan untuk memastikan konsistensi dan prestasi yang dipertingkatkan bagi pembayang termampat dan inferens LLM.
7. Pengujian dan pengesahan
Jika perlu, ujian dan pengesahan juga boleh dijalankan, supaya kecekapan dan keberkesanan integrasi LLMLingua dan LlamaIndex dapat dinilai. Metrik prestasi dinilai untuk memastikan pembayang mampatan mengekalkan integriti semantik dan meningkatkan kelajuan inferens tanpa menjejaskan ketepatan.
Pelaksanaan Kod
Kami akan mula mendalami pelaksanaan kod LLMLingua dan LlamaIndex
Pakej pemasangan:
# Install dependency. !pip install llmlingua llama-index openai tiktoken -q # Using the OAI import openai openai.api_key = "<insert_openai_key>"</insert_openai_key>
!wget "https://www.dropbox.com/s/f6bmb19xdg0xedm/paul_graham_essay.txt?dl=1" -O paul_graham_essay.txt
from llama_index import (VectorStoreIndex,SimpleDirectoryReader,load_index_from_storage,StorageContext, ) # load documents documents = SimpleDirectoryReader(input_files=["paul_graham_essay.txt"] ).load_data()
index = VectorStoreIndex.from_documents(documents) retriever = index.as_retriever(similarity_top_k=10) question = "Where did the author go for art school?" # Ground-truth Answer answer = "RISD" contexts = retriever.retrieve(question) contexts = retriever.retrieve(question) context_list = [n.get_content() for n in contexts] len(context_list) #Output #10
# The response from original prompt from llama_index.llms import OpenAI llm = OpenAI(model="gpt-3.5-turbo-16k") prompt = "\n\n".join(context_list + [question]) response = llm.complete(prompt) print(str(response)) #Output The author went to the Rhode Island School of Design (RISD) for art school.
from llama_index.query_engine import RetrieverQueryEngine from llama_index.response_synthesizers import CompactAndRefine from llama_index.indices.postprocessor import LongLLMLinguaPostprocessor node_postprocessor = LongLLMLinguaPostprocessor(instruction_str="Given the context, please answer the final question",target_token=300,rank_method="longllmlingua",additional_compress_kwargs={"condition_compare": True,"condition_in_question": "after","context_budget": "+100","reorder_context": "sort", # enable document reorder,"dynamic_context_compression_ratio": 0.3,}, )
通过LLMLingua进行压缩 打印2个结果对比: 打印的结果如下: 验证输出: LLMLingua与LlamaIndex的集成证明了协作关系在优化大型语言模型(LLM)应用程序方面的变革潜力。这种协作彻底改变了即时压缩方法和推理效率,为上下文感知、简化的LLM应用程序铺平了道路。 这种集成不仅可以提升推理速度,而且可以保证在压缩提示中保持语义的完整性。通过对基于LlamaIndex特定领域提示的压缩策略进行微调,我们平衡了提示长度的减少和基本上下文的保留,从而提高了LLM推理的准确性 从本质上讲,LLMLingua与LlamaIndex的集成超越了传统的提示压缩方法,为未来大型语言模型应用程序的优化、上下文准确和有效地针对不同领域进行定制奠定了基础。这种协作集成预示着大型语言模型应用程序领域中效率和精细化的新时代的到来。from llama_index.query_engine import RetrieverQueryEngine from llama_index.response_synthesizers import CompactAndRefine from llama_index.indices.postprocessor import LongLLMLinguaPostprocessor node_postprocessor = LongLLMLinguaPostprocessor(instruction_str="Given the context, please answer the final question",target_token=300,rank_method="longllmlingua",additional_compress_kwargs={"condition_compare": True,"condition_in_question": "after","context_budget": "+100","reorder_context": "sort", # enable document reorder,"dynamic_context_compression_ratio": 0.3,}, )retrieved_nodes = retriever.retrieve(question) synthesizer = CompactAndRefine() from llama_index.indices.query.schema import QueryBundle # postprocess (compress), synthesize new_retrieved_nodes = node_postprocessor.postprocess_nodes(retrieved_nodes, query_bundle=QueryBundle(query_str=question) ) original_contexts = "\n\n".join([n.get_content() for n in retrieved_nodes]) compressed_contexts = "\n\n".join([n.get_content() for n in new_retrieved_nodes]) original_tokens = node_postprocessor._llm_lingua.get_token_length(original_contexts) compressed_tokens = node_postprocessor._llm_lingua.get_token_length(compressed_contexts)
print(compressed_contexts) print() print("Original Tokens:", original_tokens) print("Compressed Tokens:", compressed_tokens) print("Comressed Ratio:", f"{original_tokens/(compressed_tokens + 1e-5):.2f}x")next Rtm's advice hadn' included anything that. I wanted to do something completely different, so I decided I'd paint. I wanted to how good I could get if I focused on it. the day after stopped on YC, I painting. I was rusty and it took a while to get back into shape, but it was at least completely engaging.1] I wanted to back RISD, was now broke and RISD was very expensive so decided job for a year and return RISD the fall. I got one at Interleaf, which made software for creating documents. You like Microsoft Word? Exactly That was I low end software tends to high. Interleaf still had a few years to live yet. [] the Accademia wasn't, and my money was running out, end year back to thelot the color class I tookD, but otherwise I was basically myself to do that for in993 I dropped I aroundidence bit then my friend Par did me a big A rent-partment building New York. Did I want it Itt more my place, and York be where the artists. wanted [For when you that ofs you big painting of this type hanging in the apartment of a hedge fund manager, you know he paid millions of dollars for it. That's not always why artists have a signature style, but it's usually why buyers pay a lot for such work. [6] Original Tokens: 10719 Compressed Tokens: 308 Comressed Ratio: 34.80x
response = synthesizer.synthesize(question, new_retrieved_nodes) print(str(response)) #Output #The author went to RISD for art school.
总结
Atas ialah kandungan terperinci LLMLingua: Sepadukan LlamaIndex, mampatkan petunjuk dan menyediakan perkhidmatan inferens model bahasa besar yang cekap. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Laman web ini melaporkan pada 27 Jun bahawa Jianying ialah perisian penyuntingan video yang dibangunkan oleh FaceMeng Technology, anak syarikat ByteDance Ia bergantung pada platform Douyin dan pada asasnya menghasilkan kandungan video pendek untuk pengguna platform tersebut Windows , MacOS dan sistem pengendalian lain. Jianying secara rasmi mengumumkan peningkatan sistem keahliannya dan melancarkan SVIP baharu, yang merangkumi pelbagai teknologi hitam AI, seperti terjemahan pintar, penonjolan pintar, pembungkusan pintar, sintesis manusia digital, dsb. Dari segi harga, yuran bulanan untuk keratan SVIP ialah 79 yuan, yuran tahunan ialah 599 yuan (nota di laman web ini: bersamaan dengan 49.9 yuan sebulan), langganan bulanan berterusan ialah 59 yuan sebulan, dan langganan tahunan berterusan ialah 499 yuan setahun (bersamaan dengan 41.6 yuan sebulan) . Di samping itu, pegawai yang dipotong juga menyatakan bahawa untuk meningkatkan pengalaman pengguna, mereka yang telah melanggan VIP asal
 Pembantu pengekodan AI yang ditambah konteks menggunakan Rag dan Sem-Rag
Jun 10, 2024 am 11:08 AM
Pembantu pengekodan AI yang ditambah konteks menggunakan Rag dan Sem-Rag
Jun 10, 2024 am 11:08 AM
Tingkatkan produktiviti, kecekapan dan ketepatan pembangun dengan menggabungkan penjanaan dipertingkatkan semula dan memori semantik ke dalam pembantu pengekodan AI. Diterjemah daripada EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, pengarang JanakiramMSV. Walaupun pembantu pengaturcaraan AI asas secara semulajadi membantu, mereka sering gagal memberikan cadangan kod yang paling relevan dan betul kerana mereka bergantung pada pemahaman umum bahasa perisian dan corak penulisan perisian yang paling biasa. Kod yang dijana oleh pembantu pengekodan ini sesuai untuk menyelesaikan masalah yang mereka bertanggungjawab untuk menyelesaikannya, tetapi selalunya tidak mematuhi piawaian pengekodan, konvensyen dan gaya pasukan individu. Ini selalunya menghasilkan cadangan yang perlu diubah suai atau diperhalusi agar kod itu diterima ke dalam aplikasi
 Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Untuk mengetahui lebih lanjut tentang AIGC, sila layari: 51CTOAI.x Komuniti https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou berbeza daripada bank soalan tradisional yang boleh dilihat di mana-mana sahaja di Internet memerlukan pemikiran di luar kotak. Model Bahasa Besar (LLM) semakin penting dalam bidang sains data, kecerdasan buatan generatif (GenAI) dan kecerdasan buatan. Algoritma kompleks ini meningkatkan kemahiran manusia dan memacu kecekapan dan inovasi dalam banyak industri, menjadi kunci kepada syarikat untuk kekal berdaya saing. LLM mempunyai pelbagai aplikasi Ia boleh digunakan dalam bidang seperti pemprosesan bahasa semula jadi, penjanaan teks, pengecaman pertuturan dan sistem pengesyoran. Dengan belajar daripada sejumlah besar data, LLM dapat menjana teks
 Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Model Bahasa Besar (LLM) dilatih pada pangkalan data teks yang besar, di mana mereka memperoleh sejumlah besar pengetahuan dunia sebenar. Pengetahuan ini dibenamkan ke dalam parameter mereka dan kemudiannya boleh digunakan apabila diperlukan. Pengetahuan tentang model ini "diperbaharui" pada akhir latihan. Pada akhir pra-latihan, model sebenarnya berhenti belajar. Selaraskan atau perhalusi model untuk mempelajari cara memanfaatkan pengetahuan ini dan bertindak balas dengan lebih semula jadi kepada soalan pengguna. Tetapi kadangkala pengetahuan model tidak mencukupi, dan walaupun model boleh mengakses kandungan luaran melalui RAG, ia dianggap berfaedah untuk menyesuaikan model kepada domain baharu melalui penalaan halus. Penalaan halus ini dilakukan menggunakan input daripada anotasi manusia atau ciptaan LLM lain, di mana model menemui pengetahuan dunia sebenar tambahan dan menyepadukannya
 Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) set data memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik. Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan bidang lain, set data ini masih mempunyai beberapa kekurangan. Pertama, borang data adalah agak mudah, kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi mengehadkan julat pemilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, Soal Jawab terbuka
 Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Editor |. KX Dalam bidang penyelidikan dan pembangunan ubat, meramalkan pertalian pengikatan protein dan ligan dengan tepat dan berkesan adalah penting untuk pemeriksaan dan pengoptimuman ubat. Walau bagaimanapun, kajian semasa tidak mengambil kira peranan penting maklumat permukaan molekul dalam interaksi protein-ligan. Berdasarkan ini, penyelidik dari Universiti Xiamen mencadangkan rangka kerja pengekstrakan ciri berbilang mod (MFE) novel, yang buat pertama kalinya menggabungkan maklumat mengenai permukaan protein, struktur dan jujukan 3D, dan menggunakan mekanisme perhatian silang untuk membandingkan ciri modaliti yang berbeza penjajaran. Keputusan eksperimen menunjukkan bahawa kaedah ini mencapai prestasi terkini dalam meramalkan pertalian mengikat protein-ligan. Tambahan pula, kajian ablasi menunjukkan keberkesanan dan keperluan maklumat permukaan protein dan penjajaran ciri multimodal dalam rangka kerja ini. Penyelidikan berkaitan bermula dengan "S
 Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Pembelajaran mesin ialah cabang penting kecerdasan buatan yang memberikan komputer keupayaan untuk belajar daripada data dan meningkatkan keupayaan mereka tanpa diprogramkan secara eksplisit. Pembelajaran mesin mempunyai pelbagai aplikasi dalam pelbagai bidang, daripada pengecaman imej dan pemprosesan bahasa semula jadi kepada sistem pengesyoran dan pengesanan penipuan, dan ia mengubah cara hidup kita. Terdapat banyak kaedah dan teori yang berbeza dalam bidang pembelajaran mesin, antaranya lima kaedah yang paling berpengaruh dipanggil "Lima Sekolah Pembelajaran Mesin". Lima sekolah utama ialah sekolah simbolik, sekolah sambungan, sekolah evolusi, sekolah Bayesian dan sekolah analogi. 1. Simbolisme, juga dikenali sebagai simbolisme, menekankan penggunaan simbol untuk penaakulan logik dan ekspresi pengetahuan. Aliran pemikiran ini percaya bahawa pembelajaran adalah proses penolakan terbalik, melalui sedia ada
 Era baharu pembangunan bahagian hadapan VSCode: 12 pembantu kod AI yang sangat disyorkan
Jun 11, 2024 pm 07:47 PM
Era baharu pembangunan bahagian hadapan VSCode: 12 pembantu kod AI yang sangat disyorkan
Jun 11, 2024 pm 07:47 PM
Dalam dunia pembangunan bahagian hadapan, VSCode telah menjadi alat pilihan untuk banyak pembangun dengan fungsi yang berkuasa dan ekosistem pemalam yang kaya. Dalam beberapa tahun kebelakangan ini, dengan perkembangan pesat teknologi kecerdasan buatan, pembantu kod AI pada VSCode telah muncul, meningkatkan kecekapan pengekodan pembangun. Pembantu kod AI pada VSCode telah muncul seperti cendawan selepas hujan, meningkatkan kecekapan pengekodan pembangun. Ia menggunakan teknologi kecerdasan buatan untuk menganalisis kod secara bijak dan menyediakan penyiapan kod yang tepat, pembetulan ralat automatik, semakan tatabahasa dan fungsi lain, yang mengurangkan kesilapan pembangun dan kerja manual yang membosankan semasa proses pengekodan. Hari ini, saya akan mengesyorkan 12 pembantu kod AI pembangunan bahagian hadapan VSCode untuk membantu anda dalam perjalanan pengaturcaraan anda.
