

Penterjemah |. konsep , dan fokus pada kaedah
SetFit yang digunakan secara meluas dalam pengelasan teks. . meramal dengan tepat. Selepas menyelesaikan proses latihan, kita boleh menggunakan data ujian untuk mendapatkan keputusan ramalan model. Walau bagaimanapun, pendekatan pembelajaran tradisional yang diselia ini mengalami kelemahan yang ketara: ia memerlukan set data latihan yang besar dan bebas ralat. Tetapi tidak semua medan dapat menyediakan set data tanpa ralat sedemikian. Oleh itu, konsep "pembelajaran beberapa pukulan" wujud.
Sebelum mendalami Sentence Transformer fine-tuning
(SetFit), adalah perlu untuk kita menyemak secara ringkas Pemprosesan Bahasa Asli (
NLP  Aspek penting
Aspek penting
Pembelajaran beberapa pukulan bermaksud: menggunakan set data latihan terhad untuk melatih model. Model boleh memperoleh pengetahuan daripada koleksi kecil ini yang dipanggil set sokongan. Jenis pembelajaran ini bertujuan untuk mengajar model beberapa pukulan untuk mengenali persamaan dan perbezaan dalam data latihan. Sebagai contoh, daripada mengarahkan model untuk mengklasifikasikan imej yang diberikan sebagai kucing atau anjing, kami mengarahkannya untuk memahami persamaan dan perbezaan antara pelbagai haiwan. Seperti yang dapat dilihat, pendekatan ini memberi tumpuan kepada pemahaman persamaan dan perbezaan dalam data input. Oleh itu, ia juga sering dipanggil meta-learning (meta-learning
), atau learning-to-learn (learning-to-learn). Perlu dinyatakan bahawa set sokongan pembelajaran beberapa pukulan juga dipanggil k ke (k-way) n pembelajaran sampel (n-shot). Antaranya, "k
" mewakili bilangan kategori dalam set sokongan. Contohnya, dalam pengelasan binari,. Dan "n" mewakili bilangan sampel yang tersedia untuk setiap kategori dalam set sokongan. Contohnya, jika klasifikasi positif mempunyai 10 mata data, dan klasifikasi negatif juga mempunyai 10
mata data, makan adalah sama dengan 10. Secara ringkasnya, set sokongan ini boleh disifatkan sebagai pembelajaran sampel dua hala 10. Sekarang kita mempunyai pemahaman asas tentang pembelajaran beberapa pukulan, mari belajar dengan cepat dengan menggunakan SetFit dan lakukan pengelasan teks pada set data e-dagang dalam aplikasi praktikal. SetFitArchitecture dibangunkan bersama oleh pasukan Hugging Face dan Intel sumber terbuka alat untuk klasifikasi foto beberapa sampel. Anda boleh mendapatkan maklumat komprehensif tentang SetFit dalam pautan perpustakaan projek-https://github.com/huggingface/setfit?ref=hackernoon.com. Dari segi output,
SetFithanya menggunakan lapan contoh beranotasi bagi setiap kategori dalam Ulasan Pelanggan (Ulasan Pelanggan, CR) set data analisis sentimen. Hasilnya adalah sama seperti hasil RoBERTa Large
yang ditala pada set latihan penuh yang terdiri daripada 3,000 contoh. Perlu ditekankan bahawa dari segi volum, modelSumber gambar: https://www.php.cn/link/2456b9cd2668fa69e3c7ecd6b69e3c7ec6b6b
Dicapai dengan SetFit Pembelajaran PantasSetFit latihan sangat pantas dan cekap. Prestasinya amat kompetitif berbanding model besar seperti GPT-3 dan T-FEW. Lihat imej di bawah: Perbandingan model
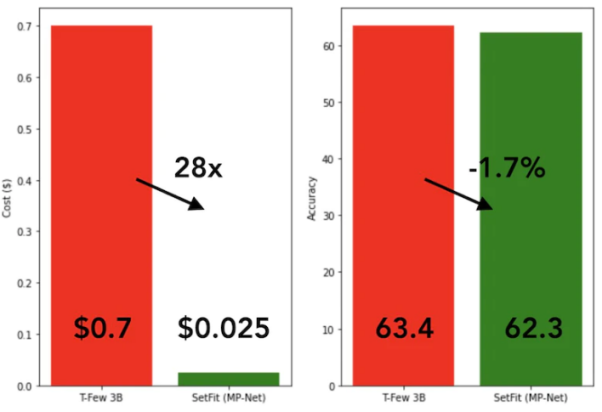 SetFit dan T-Few 3B
SetFit dan T-Few 3B
Seperti yang ditunjukkan dalam rajah di bawah, SetFit berprestasi lebih baik daripada Pembelajaran RoBERTa
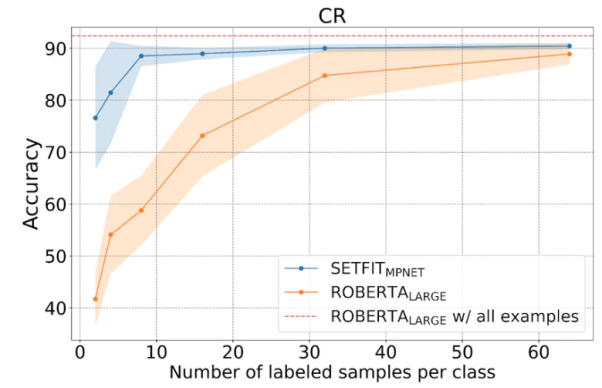
Perbandingan antara SetFit dan RoBERT, sumber gambar: https://www.php.cn/link/3ff4cea152080fd7d692a82a
di bawah , kami akan menggunakan set data e-dagang unik yang terdiri daripada empat kategori berbeza: buku, pakaian dan aksesori, elektronik dan kelengkapan rumah. Tujuan utama set data ini adalah untuk mengklasifikasikan perihalan produk daripada tapak web e-dagang ke dalam teg tertentu.
Untuk memudahkan penggunaan kaedah latihan beberapa sampel, kami akan memilih lapan sampel daripada setiap empat kategori, menghasilkan sejumlah 32 sampel latihan. Sampel yang selebihnya akan dikhaskan untuk tujuan ujian. Pendek kata, set sokongan yang kami gunakan di sini ialah 4 belajar daripada 8 sampel. Rajah di bawah menunjukkan contoh set data e-dagang tersuai:
 Sampel set data e-dagang tersuai
Sampel set data e-dagang tersuai
Kami menggunakan nama "all-mpnet-base-v2" Pengubah Ayat model pra-latihan untuk mengubah data teks kepada pelbagai pembenaman vektor. Model ini boleh menjana pembenaman vektor dimensi 768 untuk teks input.
Seperti yang ditunjukkan dalam arahan berikut, kami akan memulakan SetFit dengan memasang pakej yang diperlukan dalam persekitaran conda (yang merupakan sistem pengurusan pakej pengurusan sumber terbuka).
!pip3 install SetFit !pip3 install sklearn !pip3 install transformers !pip3 install sentence-transformers
Selepas memasang pakej perisian, kami boleh memuatkan set data melalui kod berikut.
from datasets import load_datasetdataset = load_dataset('csv', data_files={"train": 'E_Commerce_Dataset_Train.csv',"test": 'E_Commerce_Dataset_Test.csv'})Jom rujuk rajah di bawah untuk melihat bilangan sampel latihan dan sampel ujian.
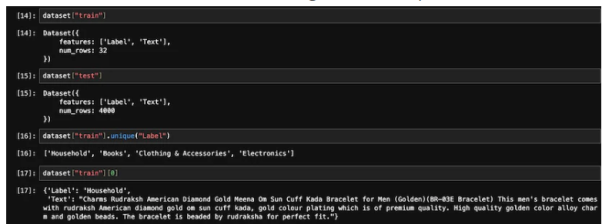 Data latihan dan ujian
Data latihan dan ujian
Kami menggunakan LabelEncoder daripada pakej sklearnsklearn kepada label teks encoded
from sklearn.preprocessing import LabelEncoder le = LabelEncoder()
Dengan LabelEncoder, kami akan mengekod set data latihan dan ujian serta menambah label yang dikodkan pada lajur "Label" set data. Lihat kod di bawah:
Encoded_Product = le.fit_transform(dataset["train"]['Label']) dataset["train"] = dataset["train"].remove_columns("Label").add_column("Label", Encoded_Product).cast(dataset["train"].features)Encoded_Product = le.fit_transform(dataset["test"]['Label']) dataset["test"] = dataset["test"].remove_columns("Label").add_column("Label", Encoded_Product).cast(dataset["test"].features)Di bawah, kami akan memulakan model SetFit dan model pengubah ayat.
from setfit import SetFitModel, SetFitTrainer from sentence_transformers.losses import CosineSimilarityLossmodel_id = "sentence-transformers/all-mpnet-base-v2" model = SetFitModel.from_pretrained(model_id)trainer = SetFitTrainer( model=model, train_dataset=dataset["train"], eval_dataset=dataset["test"], loss_class=CosineSimilarityLoss, metric="accuracy", batch_size=64, num_iteratinotallow=20, num_epochs=2, column_mapping={"Text": "text", "Label": "label"})Selepas memulakan kedua-dua model, kini kita boleh memanggil program latihan.
trainer.train()
Selepas melengkapkan 2 pusingan latihan (zaman), kami akan menilai model terlatih pada eval_dataset.
trainer.evaluate()
Selepas ujian, model latihan kami mencapai ketepatan tertinggi 87.5%. Walaupun ketepatan 87.5% tidak tinggi, lagipun model kami hanya menggunakan 32 sampel untuk latihan. Dengan kata lain, memandangkan saiz set data yang terhad, mencapai ketepatan 87.5% pada set data ujian sebenarnya agak mengagumkan.
Selain itu, SetFit juga boleh menyimpan model terlatih ke storan tempatan untuk pemuatan seterusnya dari cakera untuk ramalan masa hadapan.
trainer.model._save_pretrained(save_directory="SetFit_ECommerce_Output/")model=SetFitModel.from_pretrained("SetFit_ECommerce_Output/", local_files_notallow=True)Kod berikut menunjukkan keputusan ramalan berdasarkan data baharu:
input = ["Campus Sutra Men's Sports Jersey T-Shirt Cool-Gear: Our Proprietary Moisture Management technology. Helps to absorb and evaporate sweat quickly. Keeps you Cool & Dry. Ultra-Fresh: Fabrics treated with Ultra-Fresh Antimicrobial Technology. Ultra-Fresh is a trademark of (TRA) Inc, Ontario, Canada. Keeps you odour free."]output = model(input)
Ia boleh dilihat bahawa output ramalan ialah 1, dan nilai EncoLa label adalah Enco Aksesori" . Model AI tradisional memerlukan sejumlah besar sumber latihan (termasuk masa dan data) untuk menghasilkan tahap output yang stabil. Sebaliknya, model kami adalah tepat dan cekap.
Pada ketika ini, saya percaya anda pada asasnya telah menguasai konsep "pembelajaran beberapa pukulan" dan cara menggunakan SetFit untuk pengelasan teks dan aplikasi lain. Sudah tentu, untuk mendapatkan pemahaman yang lebih mendalam, saya amat mengesyorkan agar anda memilih senario sebenar, mencipta set data, menulis kod yang sepadan dan melanjutkan proses kepada pembelajaran sifar pukulan dan pembelajaran pukulan tunggal. . Untuk menyebarkan pengetahuan dan pengalaman Rangkaian dan Keselamatan Maklumat
mastering beberapa pukulan pembelajaran dengan setfit untuk klasifikasi teks, Pengarang: Shyam Ganesh s)
Atas ialah kandungan terperinci Dalam pembelajaran beberapa pukulan, gunakan SetFit untuk klasifikasi teks. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 sempadan-runtuh
sempadan-runtuh
 Apakah perbezaan utama antara linux dan windows
Apakah perbezaan utama antara linux dan windows
 Perbezaan antara halaman web statik dan halaman web dinamik
Perbezaan antara halaman web statik dan halaman web dinamik
 Tutorial menggabungkan beberapa perkataan menjadi satu perkataan
Tutorial menggabungkan beberapa perkataan menjadi satu perkataan
 Peranan c++ penunjuk ini
Peranan c++ penunjuk ini
 Bagaimana untuk menutup port 445 dalam xp
Bagaimana untuk menutup port 445 dalam xp
 Bagaimana untuk memasang pycharm
Bagaimana untuk memasang pycharm
 Bagaimana untuk membuka Windows 7 Explorer
Bagaimana untuk membuka Windows 7 Explorer
 Google earth tidak boleh menyambung kepada penyelesaian pelayan
Google earth tidak boleh menyambung kepada penyelesaian pelayan








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



