

Hari ini, Syarikat Stable AI melancarkan produk AI generasi muzik dan bunyi pertama mereka - Audio Stable. Industri muzik terkenal sukar untuk dipecahkan. Walaupun anda mempunyai bakat dan pemanduan, anda masih perlu mempunyai kemahiran dan sumber untuk mencipta dan menghasilkan muzik. Tetapi bagaimana jika anda tidak memerlukan semua ini? Bagaimana jika yang anda perlukan hanyalah kreativiti dan gesaan AI yang baik untuk mengarang muzik?
Audio Stabil ialah alat yang boleh menjana muzik dari awal oleh AI. Hanya berikan arahan mudah dan AI akan melakukan yang lain
Pautan rasmi ada di sini: https://stableaudio.com/

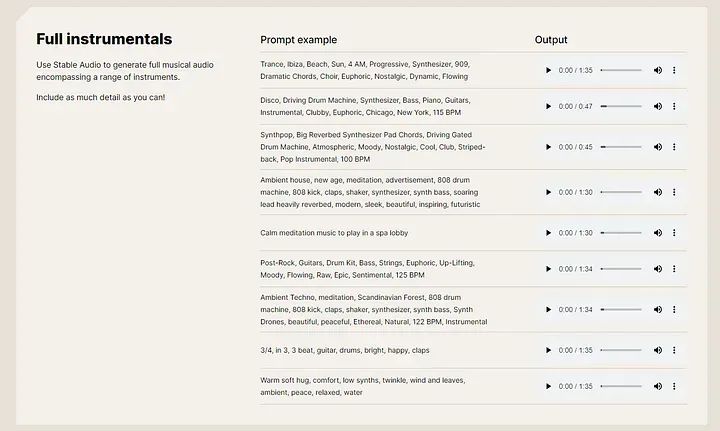
Audio Stabil ialah alat AI asli yang menggunakan teknologi AI generatif untuk mencipta muzik dan kesan bunyi berkualiti tinggi. Untuk menggunakan audio yang stabil, anda hanya menyediakan gesaan teks deskriptif dan panjang audio yang diingini. Contohnya, anda boleh memasukkan "pasca-rock, gitar, kit dram, bes, rentetan, ceria, menaikkan semangat, sayu, lancar, mentah, epik, sentimental, 125 BPM" untuk menjana trek gaya pasca-rock selama 95 saat. Audio Distabilkan bagus untuk pemuzik yang ingin membuat sampel dalam muzik mereka. Anda boleh menggunakannya untuk mencipta kesan bunyi, muzik latar belakang, atau bahkan gubahan asal anda sendiri. .
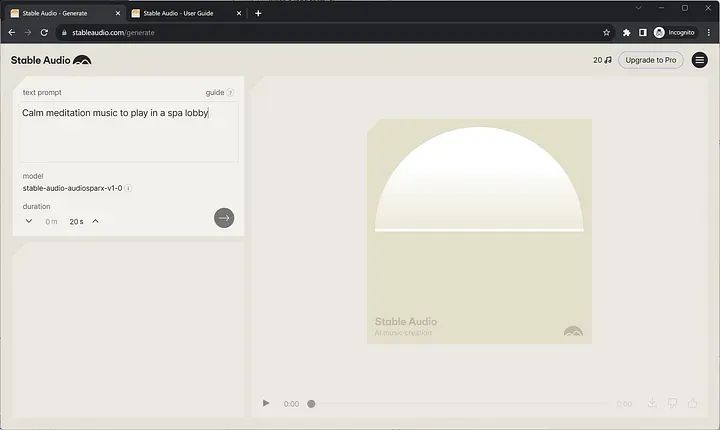
Sila berikan petua anda dan tetapkan tempohnya. Sila ambil perhatian bahawa langganan percuma mempunyai panjang audio maksimum 20 saat
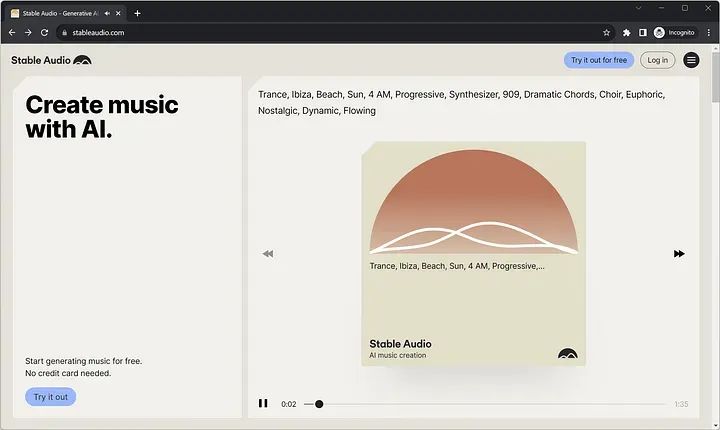
Tekan kekunci anak panah kanan untuk memulakan penjanaan audio
Berikut ialah beberapa butiran teknikal utama tentang cara Audio Distabilkan berfungsi: 
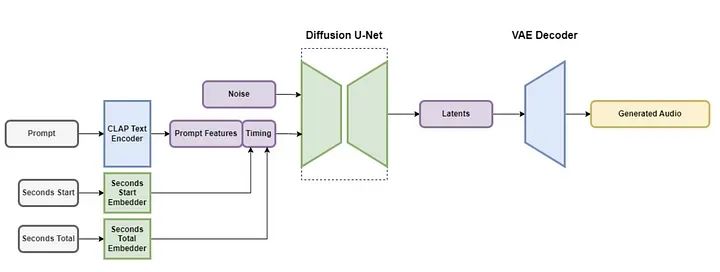 Model resapan ialah model berasaskan U-Net yang menggunakan gabungan lapisan baki, lapisan perhatian kendiri dan lapisan perhatian silang untuk menafikan input dan membina semula audio yang diingini.
Model resapan ialah model berasaskan U-Net yang menggunakan gabungan lapisan baki, lapisan perhatian kendiri dan lapisan perhatian silang untuk menafikan input dan membina semula audio yang diingini.
Atas ialah kandungan terperinci Audio Stabil Kini Tersedia — Buat Muzik dengan Kepintaran Buatan secara Percuma. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Aplikasi kecerdasan buatan dalam kehidupan
Aplikasi kecerdasan buatan dalam kehidupan
 Apakah konsep asas kecerdasan buatan
Apakah konsep asas kecerdasan buatan
 Bagaimana untuk menukar ape kepada wav
Bagaimana untuk menukar ape kepada wav
 Apakah teknologi teras yang diperlukan untuk pembangunan Java?
Apakah teknologi teras yang diperlukan untuk pembangunan Java?
 Penggunaan fungsi urlencode
Penggunaan fungsi urlencode
 Apakah perdagangan mata wang digital
Apakah perdagangan mata wang digital
 Apa yang perlu dilakukan jika imej terbenam tidak dipaparkan sepenuhnya
Apa yang perlu dilakukan jika imej terbenam tidak dipaparkan sepenuhnya
 Bagaimana untuk mengalih keluar tera air akaun Douyin daripada video yang dimuat turun daripada Douyin
Bagaimana untuk mengalih keluar tera air akaun Douyin daripada video yang dimuat turun daripada Douyin








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



