

Pasukan Profesor Mohammed Sawan di Pusat Cip Neural Termaju, pasukan Profesor Zhang Yue dan pasukan Profesor Zhu Junming dari Makmal Pemprosesan Bahasa Semulajadi bersama-sama mengeluarkan hasil penyelidikan terbaharu mereka: “Komunikasi ayat otak berprestasi tinggi yang direka untuk bahasa logosilabik" .

Antara muka otak-komputer (BCI) diiktiraf sebagai medan pertempuran utama untuk persimpangan masa depan dan integrasi sains hayat dan teknologi maklumat Ia merupakan hala tuju penyelidikan dengan nilai sosial yang penting dan kepentingan strategik.
Teknologi antara muka otak-komputer merujuk kepada penciptaan laluan sambungan untuk pertukaran maklumat antara otak manusia atau haiwan dan peranti luaran. mencapai komunikasi dengan otak Hubungan dengan dunia luar dengan itu menggantikan pergerakan manusia, bahasa dan fungsi lain pada tahap tertentu.
 Reka bentuk dan prestasi antara muka otak-komputer penyahkod Cina spektrum penuh
Reka bentuk dan prestasi antara muka otak-komputer penyahkod Cina spektrum penuh
Pada bulan Ogos tahun ini, dua artikel Nature berturut-turut menunjukkan kuasa antara muka otak-komputer dalam pemulihan bahasa. Walau bagaimanapun, kebanyakan teknologi antara muka otak-komputer bahasa sedia ada dibina untuk sistem bahasa abjad seperti bahasa Inggeris, dan penyelidikan tentang sistem antara muka otak-komputer bahasa untuk sistem bukan abjad seperti aksara Cina masih kosong.
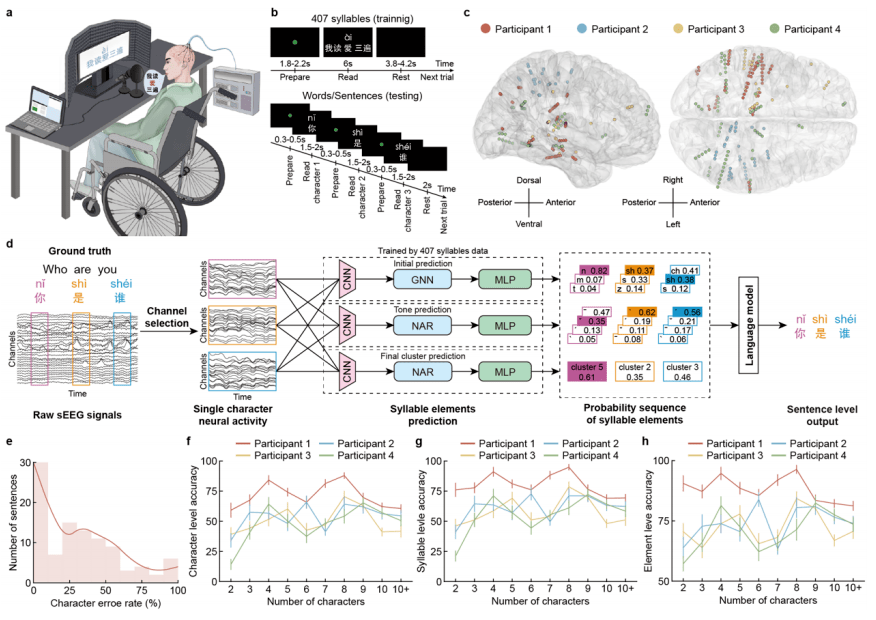
Dalam kajian ini, pasukan penyelidik menggunakan stereotactic electroencephalography (SEEG) untuk mengumpul isyarat aktiviti saraf dalam otak yang sepadan dengan proses sebutan semua aksara Cina Mandarin, dan digabungkan dengan algoritma pembelajaran mendalam dan model bahasa untuk mencapai penyahkodan spektrum penuh Sebutan aksara Cina Sistem antara muka otak-komputer Cina yang meliputi sebutan semua aksara Mandarin Cina telah diwujudkan, mencapai output hujung ke hujung daripada aktiviti otak untuk melengkapkan ayat Mandarin.
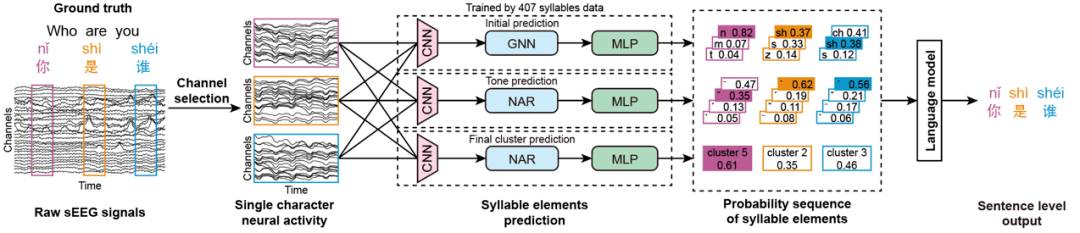
Bahasa Cina, sebagai bahasa yang menggabungkan piktogram dan suku kata, mempunyai lebih daripada 50,000 aksara, yang jauh berbeza daripada bahasa Inggeris, yang terdiri daripada 26 huruf Oleh itu, ini merupakan satu cabaran besar untuk sistem antara muka otak bahasa yang sedia ada. Bagi menyelesaikan masalah ini, sejak tiga tahun lalu, pasukan penyelidik telah menjalankan analisis mendalam tentang peraturan sebutan dan ciri-ciri bahasa Cina itu sendiri. Bermula daripada tiga elemen konsonan awal, nada dan akhir suku kata sebutan bahasa Cina, dan menggabungkan ciri-ciri sistem input Pinyin, sistem antara muka otak-komputer bahasa baharu yang sesuai untuk bahasa Cina telah direka bentuk. Pasukan penyelidik membina pangkalan data pertuturan-SEEG bahasa Cina selama lebih daripada 100 jam dengan mereka bentuk pangkalan data pertuturan yang meliputi semua 407 suku kata Pinyin Cina dan ciri sebutan bahasa Cina dan pada masa yang sama mengumpul isyarat EEG. Melalui latihan model kecerdasan buatan, sistem membina model ramalan untuk tiga elemen suku kata sebutan aksara Cina (termasuk konsonan awal, nada dan akhir), dan akhirnya menyepadukan semua elemen ramalan melalui model bahasa, menggabungkan maklumat semantik untuk menjana kemungkinan besar. Ayat bahasa Cina yang lengkap.
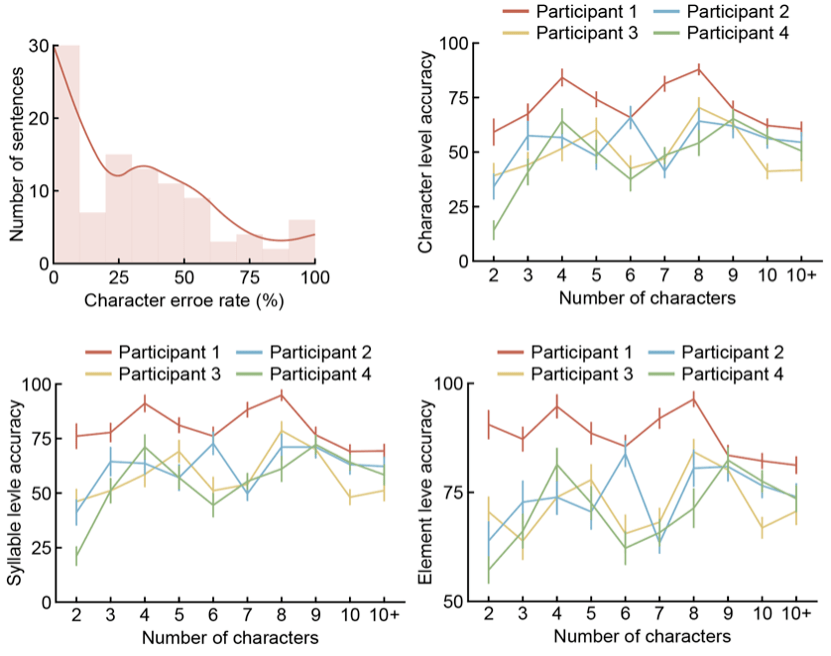
Pasukan penyelidik menilai keupayaan penyahkodan sistem antara muka otak-komputer ini dalam persekitaran Cina harian yang disimulasikan. Selepas lebih daripada 100 ujian penyahkodan adegan komunikasi kompleks yang dipilih secara rawak sebanyak 2 hingga 15 aksara, purata kadar ralat aksara median bagi semua peserta hanyalah 29%, dan sesetengah peserta mencapai ayat yang betul sepenuhnya melalui penyahkodan EEG mencapai 30%. Prestasi penyahkodan yang agak cekap mendapat manfaat daripada prestasi cemerlang tiga penyahkod unsur suku kata bebas dan kerjasama sempurna model bahasa pintar. Khususnya, dari segi mengklasifikasikan 21 konsonan awal, ketepatan penyahkod konsonan awal melebihi 40% (lebih daripada 3 kali garis dasar), dan kadar ketepatan 3 Teratas mencapai hampir 100% manakala penyahkod nada digunakan untuk membezakan 4 nada Ketepatan juga mencapai 50% (lebih daripada 2 kali garis dasar). Sebagai tambahan kepada sumbangan cemerlang tiga penyahkod unsur suku kata bebas, keupayaan pembetulan ralat automatik yang berkuasa dan keupayaan sambungan kontekstual model bahasa pintar juga menjadikan prestasi keseluruhan sistem antara muka otak-komputer bahasa lebih cemerlang.
Penyelidikan ini menyediakan perspektif baharu untuk kajian penyahkodan BCI bahasa Cina, bahasa fonetik, dan juga membuktikan bahawa prestasi sistem antara muka otak-komputer bahasa boleh dipertingkatkan dengan ketara melalui model bahasa yang berkuasa, menyediakan penyelidikan masa depan tentang prostesis saraf bahasa fonetik. arah baru. Kerja ini juga menunjukkan bahawa pesakit yang menghidap penyakit saraf tidak lama lagi akan dapat mengawal ayat Cina yang dijana komputer melalui pemikiran mereka dan mendapatkan semula keupayaan untuk berkomunikasi!
Kandungan rujukan
https://www.biorxiv.org/content/10.1101/2023.11.05.562313v1.full.pdf
Atas ialah kandungan terperinci Kejayaan penting! Pasukan Universiti Westlake dan Hospital Kedua Zhejiang bersama-sama merealisasikan penyahkodan bahasa Cina antara muka otak-komputer. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk menyahpasang One-Click Restore
Bagaimana untuk menyahpasang One-Click Restore
 Bagaimana untuk mengkonfigurasi phpstudy
Bagaimana untuk mengkonfigurasi phpstudy
 Apakah maksud tambah dalam java?
Apakah maksud tambah dalam java?
 Bagaimana untuk membuka panel kawalan win11
Bagaimana untuk membuka panel kawalan win11
 Bagaimana untuk menyelesaikan status http 404
Bagaimana untuk menyelesaikan status http 404
 Penjelasan terperinci tentang acara onbeforeunload
Penjelasan terperinci tentang acara onbeforeunload
 Bagaimana untuk memulakan semula dengan kerap
Bagaimana untuk memulakan semula dengan kerap
 Bagaimana untuk menyediakan penghala
Bagaimana untuk menyediakan penghala








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



