
 Peranti teknologi
AI
Foto menghasilkan video Membuka mulut, mengangguk, emosi, kemarahan, kesedihan dan kegembiraan semuanya boleh dikawal dengan menaip.
Peranti teknologi
AI
Foto menghasilkan video Membuka mulut, mengangguk, emosi, kemarahan, kesedihan dan kegembiraan semuanya boleh dikawal dengan menaip.
Foto menghasilkan video Membuka mulut, mengangguk, emosi, kemarahan, kesedihan dan kegembiraan semuanya boleh dikawal dengan menaip.

Baru-baru ini, kajian yang dijalankan oleh Microsoft mendedahkan betapa fleksibelnya perisian pemprosesan video PS
Dalam kajian ini, anda hanya memberikan AI foto, dan ia boleh menghasilkan video orang dalam foto , ekspresi dan pergerakan watak boleh dikawal melalui teks. Contohnya, jika arahan yang anda berikan ialah "buka mulut," watak dalam video itu sebenarnya akan membuka mulutnya.

Jika arahan yang anda berikan adalah "sedih", dia akan membuat ekspresi sedih dan pergerakan kepala.
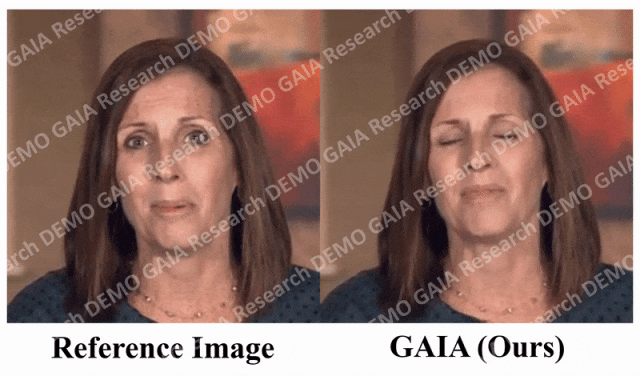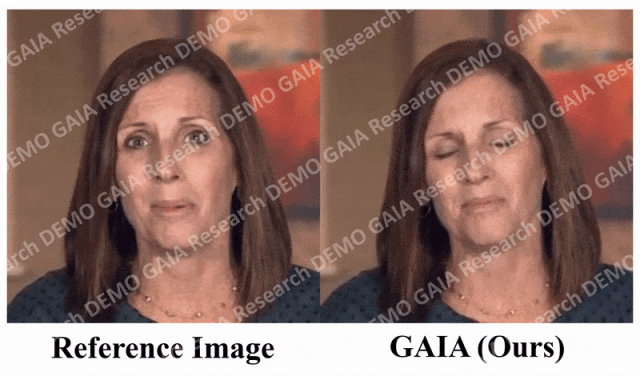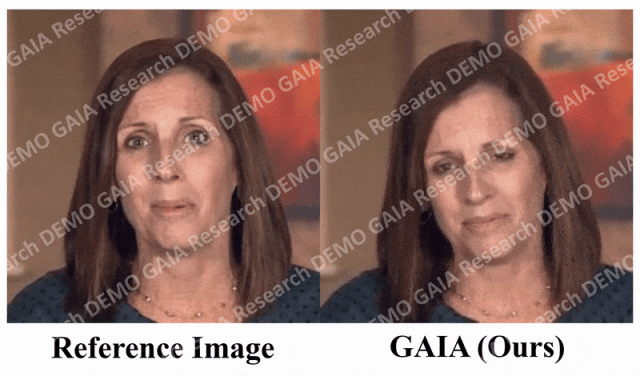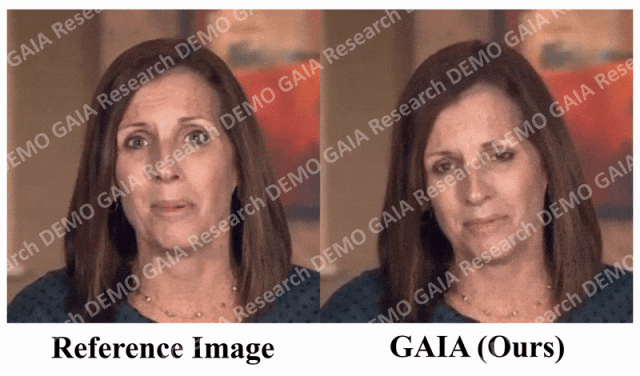
Apabila arahan "kejutan" diberikan, garisan dahi avatar dihimpit bersama.

Selain itu, anda juga boleh menyediakan suara untuk menyelaraskan bentuk mulut dan pergerakan watak maya dengan suara tersebut. Sebagai alternatif, anda boleh menyediakan video langsung untuk ditiru oleh avatar
Jika anda mempunyai lebih banyak keperluan penyuntingan tersuai untuk pergerakan avatar, seperti membuat mereka mengangguk, menoleh atau memiringkan kepala, teknologi ini juga disokong

Penyelidikan ini dipanggil GAIA (AI Generatif untuk Avatar, AI generatif untuk avatar), dan demonya telah mula tersebar di media sosial. Ramai orang mengagumi kesannya dan berharap dapat menggunakannya untuk "membangkitkan" orang mati.
Tetapi sesetengah orang bimbang bahawa evolusi berterusan teknologi ini akan menjadikan video dalam talian lebih sukar untuk dibezakan antara tulen dan palsu, atau digunakan oleh penjenayah untuk penipuan. Nampaknya langkah anti penipuan akan terus ditingkatkan.
Apakah yang inovatif tentang GAIA?
Teknologi penjanaan watak maya bercakap sampel sifar bertujuan untuk mensintesis video semula jadi berdasarkan pertuturan, memastikan bentuk mulut, ekspresi dan postur kepala yang dihasilkan adalah konsisten dengan kandungan pertuturan. Penyelidikan terdahulu biasanya memerlukan latihan khusus atau penalaan model khusus untuk setiap watak maya, atau menggunakan video templat semasa inferens untuk mencapai hasil yang berkualiti tinggi. Baru-baru ini, penyelidik telah menumpukan pada mereka bentuk dan menambah baik kaedah untuk menghasilkan avatar bercakap sifar pukulan dengan hanya menggunakan imej potret avatar sasaran sebagai rujukan penampilan. Walau bagaimanapun, kaedah ini biasanya menggunakan prior domain seperti perwakilan gerakan berasaskan meledingkan dan Model Boleh Morf 3D (3DMM) untuk mengurangkan kesukaran tugasan. Heuristik sedemikian, walaupun berkesan, mungkin mengehadkan kepelbagaian dan membawa kepada hasil yang tidak wajar. Oleh itu, pembelajaran langsung daripada pengedaran data adalah fokus penyelidikan masa depan
Dalam artikel ini, penyelidik dari Microsoft mencadangkan GAIA (Generative AI for Avatar), yang boleh mensintesis orang yang bercakap secara semula jadi daripada gambar pertuturan dan potret tunggal. domain prior dihapuskan semasa proses penjanaan.

Alamat projek: https://microsoft.github.io/GAIA/Perincian projek berkaitan boleh didapati di pautan ini
Pautan kertas: https://arxiv.org/pdf/ 2311.2311. .pdf
Gaia mendedahkan dua pandangan utama:
-
Gunakan suara untuk memacu pergerakan watak maya, manakala latar belakang dan rupa watak maya kekal tidak berubah sepanjang video. Diilhamkan oleh ini, makalah ini memisahkan gerakan dan penampilan setiap bingkai, di mana penampilan dikongsi antara bingkai, manakala gerakan itu unik untuk setiap bingkai. Untuk meramalkan gerakan daripada pertuturan, kertas kerja ini mengekod urutan gerakan ke dalam urutan terpendam gerakan dan menggunakan model resapan yang dikondisikan pada pertuturan input untuk meramalkan urutan terpendam
- Apabila seseorang bercakap kandungan tertentu, Terdapat; ialah kepelbagaian besar dalam ekspresi dan pose kepala, yang memerlukan set data berskala besar dan pelbagai. Oleh itu, kajian ini mengumpulkan set data avatar bercakap berkualiti tinggi yang terdiri daripada 16K pembesar suara unik dari pelbagai umur, jantina, jenis kulit dan gaya pertuturan, menjadikan hasil penjanaan semula jadi dan pelbagai.
Berdasarkan dua cerapan di atas, kertas kerja ini mencadangkan rangka kerja GAIA, yang terdiri daripada pengekod auto variasi (VAE) (modul oren) dan model resapan (modul biru dan hijau).
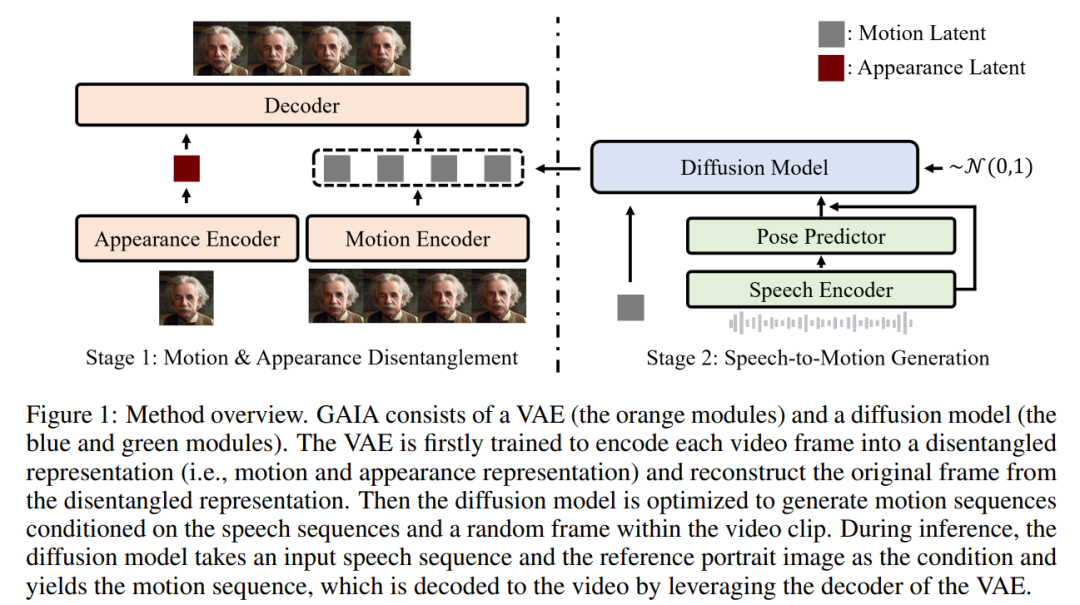
Fungsi utama VAE adalah untuk memecahkan pergerakan dan penampilan. Ia terdiri daripada dua pengekod (pengekod gerakan dan pengekod rupa) dan penyahkod. Semasa latihan, input kepada pengekod gerakan ialah bingkai semasa tanda tempat muka, manakala input kepada pengekod penampilan ialah bingkai sampel rawak dalam klip video semasa
Berdasarkan output kedua-dua pengekod ini, ia kemudiannya penyahkod dioptimumkan untuk membina semula bingkai semasa. Sebaik sahaja anda mendapat VAE terlatih, anda mendapat tindakan yang berpotensi (iaitu output pengekod gerakan) untuk semua data latihan
Kemudian, artikel ini menggunakan model resapan yang dilatih untuk meramal gerakan berdasarkan bingkai sampel rawak daripada pertuturan dan klip video Urutan terpendam gerakan, dengan itu memberikan maklumat penampilan untuk proses penjanaan
Dalam proses inferens, diberikan imej potret rujukan watak maya sasaran, model resapan mengambil imej dan urutan pertuturan input sebagai syarat untuk menjana urutan terpendam gerakan yang menepati kandungan pertuturan. Urutan terpendam gerakan dan imej potret rujukan kemudiannya disalurkan melalui penyahkod VAE untuk mensintesis output video pertuturan.
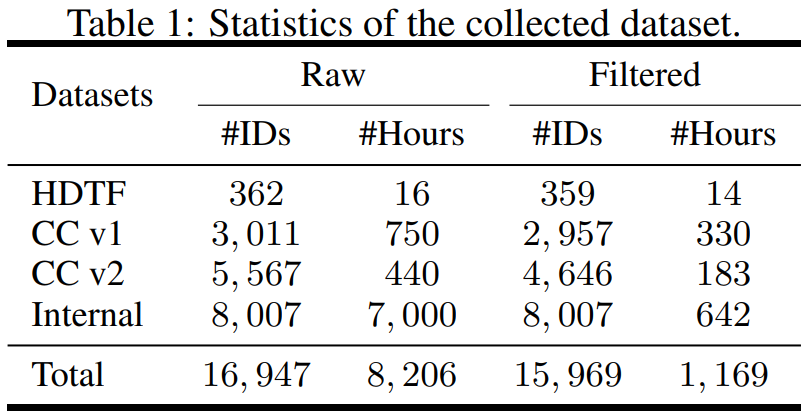
Kajian ini berstruktur dari segi data, mengumpul set data daripada sumber berbeza termasuk Set Data Muka Bercakap Definisi Tinggi (HDTF) dan set data Perbualan Kasual v1&v2 (CC v1&v2). Selain tiga set data ini, penyelidikan juga mengumpul set data avatar pertuturan dalaman berskala besar yang mengandungi 7K jam video dan 8K ID pembesar suara. Gambaran keseluruhan statistik set data ditunjukkan dalam Jadual 1
Untuk mempelajari maklumat yang diperlukan, artikel tersebut mencadangkan beberapa strategi penapisan automatik untuk memastikan kualiti data latihan:
- Untuk membuat bibir pergerakan kelihatan , arah hadapan avatar hendaklah ke arah kamera
- Untuk memastikan kestabilan, pergerakan muka dalam video hendaklah lancar dan tidak boleh bergegar dengan cepat
- Untuk menapis kes yang melampau apabila pergerakan bibir dan pertuturan tidak konsisten, avatar hendaklah dipadamkan Pakai topeng atau kekalkan bingkai senyap.
Artikel ini melatih model VAE dan penyebaran pada data yang ditapis. Daripada keputusan percubaan, kertas kerja ini telah memperoleh tiga kesimpulan utama:
- GAIA mampu menghasilkan sifar sampel pertuturan watak maya, dengan prestasi unggul dari segi semula jadi, kepelbagaian, kualiti penyegerakan bibir dan kualiti visual. Menurut penilaian subjektif penyelidik, GAIA dengan ketara mengatasi semua kaedah asas
- Saiz model latihan adalah dari 150M hingga 2B, dan hasilnya menunjukkan bahawa GAIA boleh berskala kerana model yang lebih besar menghasilkan keputusan yang lebih baik
- GAIA ialah rangka kerja umum dan fleksibel yang membolehkan aplikasi berbeza, termasuk penjanaan avatar pertuturan terkawal dan penjanaan avatar arahan teks.
GAIA Sejauh manakah keberkesanannya?
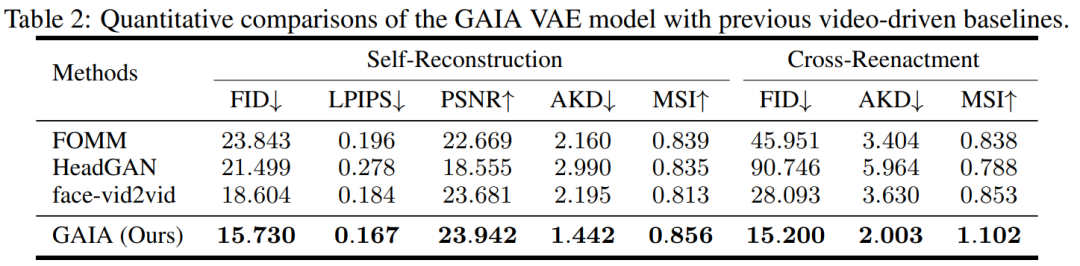
Semasa percubaan, kajian membandingkan GAIA dengan tiga garis dasar yang kuat, termasuk FOMM, HeadGAN dan Face-vid2vid. Keputusan ditunjukkan dalam Jadual 2: VAE dalam GAIA mencapai peningkatan yang konsisten berbanding garis dasar dipacu video sebelumnya, menunjukkan bahawa GAIA berjaya menguraikan penampilan dan perwakilan gerakan.
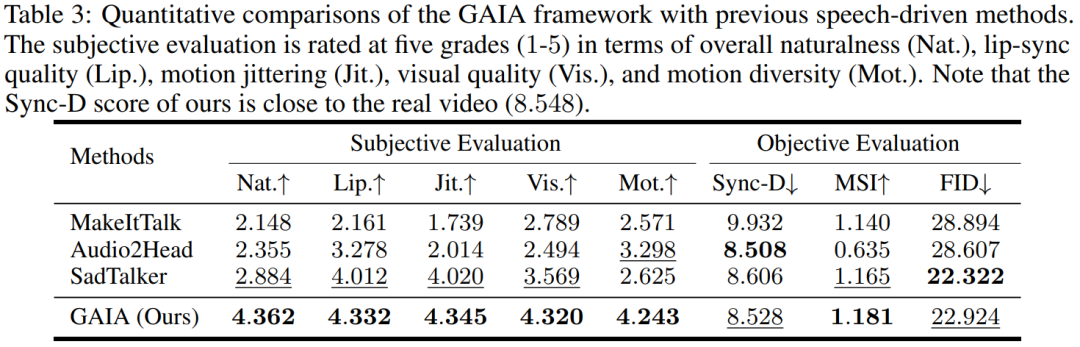
Hasil dipacu suara. Penjanaan avatar pertuturan dipacu pertuturan dicapai dengan meramalkan gerakan daripada pertuturan. Jadual 3 dan Rajah 2 memberikan perbandingan kuantitatif dan kualitatif GAIA dengan kaedah MakeItTalk, Audio2Head dan SadTalker.
Adalah jelas daripada data bahawa GAIA jauh mengatasi semua kaedah asas dari segi penilaian subjektif. Lebih khusus, seperti yang ditunjukkan dalam Rajah 2, walaupun imej rujukan mempunyai mata tertutup atau pose kepala yang luar biasa, hasil penjanaan kaedah garis dasar biasanya sangat bergantung pada imej rujukan sebaliknya, GAIA mempamerkan prestasi yang baik pada pelbagai imej rujukan. Teguh dan menjana hasil dengan keaslian yang lebih tinggi, penyegerakan bibir yang tinggi, kualiti visual yang lebih baik dan kepelbagaian gerakan

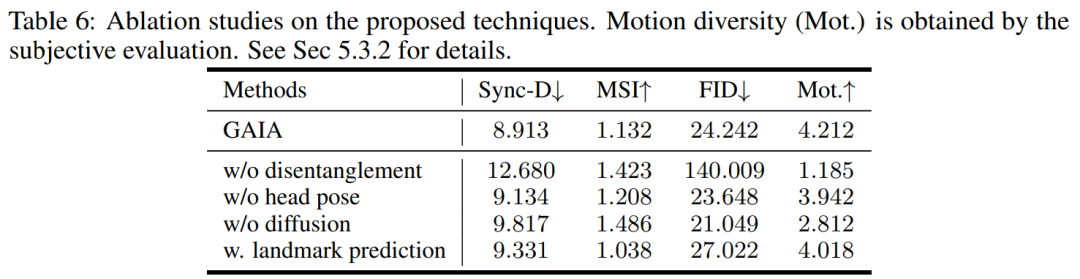
Menurut Jadual 3, skor MSI terbaik menunjukkan bahawa video yang dihasilkan oleh GAIA Mempunyai kestabilan pergerakan yang sangat baik. Skor Sync-D 8.528 adalah hampir dengan skor video sebenar (8.548), menunjukkan bahawa video yang dihasilkan mempunyai penyegerakan bibir yang sangat baik. Kajian itu mencapai skor FID yang setanding dengan garis dasar, yang mungkin telah dipengaruhi oleh pose kepala yang berbeza, kerana kajian mendapati bahawa model tanpa latihan penyebaran mencapai skor FID yang lebih baik, seperti yang diperincikan dalam Jadual 6
Atas ialah kandungan terperinci Foto menghasilkan video Membuka mulut, mengangguk, emosi, kemarahan, kesedihan dan kegembiraan semuanya boleh dikawal dengan menaip.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Video terbaru robot Tesla Optimus dikeluarkan, dan ia sudah boleh berfungsi di kilang. Pada kelajuan biasa, ia mengisih bateri (bateri 4680 Tesla) seperti ini: Pegawai itu juga mengeluarkan rupanya pada kelajuan 20x - pada "stesen kerja" kecil, memilih dan memilih dan memilih: Kali ini ia dikeluarkan Salah satu sorotan video itu ialah Optimus menyelesaikan kerja ini di kilang, sepenuhnya secara autonomi, tanpa campur tangan manusia sepanjang proses. Dan dari perspektif Optimus, ia juga boleh mengambil dan meletakkan bateri yang bengkok, memfokuskan pada pembetulan ralat automatik: Berkenaan tangan Optimus, saintis NVIDIA Jim Fan memberikan penilaian yang tinggi: Tangan Optimus adalah robot lima jari di dunia paling cerdik. Tangannya bukan sahaja boleh disentuh
 Microsoft mengeluarkan kemas kini kumulatif Win11 Ogos: meningkatkan keselamatan, mengoptimumkan skrin kunci, dsb.
Aug 14, 2024 am 10:39 AM
Microsoft mengeluarkan kemas kini kumulatif Win11 Ogos: meningkatkan keselamatan, mengoptimumkan skrin kunci, dsb.
Aug 14, 2024 am 10:39 AM
Menurut berita dari tapak ini pada 14 Ogos, semasa hari acara August Patch Tuesday hari ini, Microsoft mengeluarkan kemas kini kumulatif untuk sistem Windows 11, termasuk kemas kini KB5041585 untuk 22H2 dan 23H2, dan kemas kini KB5041592 untuk 21H2. Selepas peralatan yang disebutkan di atas dipasang dengan kemas kini kumulatif Ogos, perubahan nombor versi yang dilampirkan pada tapak ini adalah seperti berikut: Selepas pemasangan peralatan 21H2, nombor versi meningkat kepada Build22000.314722H2 Selepas pemasangan peralatan, nombor versi meningkat kepada Build22621.403723H2 Selepas pemasangan peralatan, nombor versi meningkat kepada Build22631.4037 Kandungan utama kemas kini KB5041585 untuk Windows 1121H2 adalah seperti berikut: Penambahbaikan.
 Pop timbul skrin penuh Microsoft menggesa pengguna Windows 10 untuk menyegerakan dan menaik taraf kepada Windows 11
Jun 06, 2024 am 11:35 AM
Pop timbul skrin penuh Microsoft menggesa pengguna Windows 10 untuk menyegerakan dan menaik taraf kepada Windows 11
Jun 06, 2024 am 11:35 AM
Menurut berita pada 3 Jun, Microsoft sedang aktif menghantar pemberitahuan skrin penuh kepada semua pengguna Windows 10 untuk menggalakkan mereka menaik taraf kepada sistem pengendalian Windows 11. Langkah ini melibatkan peranti yang konfigurasi perkakasannya tidak menyokong sistem baharu. Sejak 2015, Windows 10 telah menduduki hampir 70% bahagian pasaran, dengan kukuh mengukuhkan penguasaannya sebagai sistem pengendalian Windows. Walau bagaimanapun, bahagian pasaran jauh melebihi bahagian pasaran 82%, dan bahagian pasaran jauh melebihi Windows 11, yang akan dikeluarkan pada 2021. Walaupun Windows 11 telah dilancarkan selama hampir tiga tahun, penembusan pasarannya masih perlahan. Microsoft telah mengumumkan bahawa ia akan menamatkan sokongan teknikal untuk Windows 10 selepas 14 Oktober 2025 untuk memberi tumpuan lebih kepada
 Melebihi DPO secara menyeluruh: Pasukan Chen Danqi mencadangkan pengoptimuman pilihan mudah SimPO, dan turut memperhalusi model sumber terbuka 8B terkuat
Jun 01, 2024 pm 04:41 PM
Melebihi DPO secara menyeluruh: Pasukan Chen Danqi mencadangkan pengoptimuman pilihan mudah SimPO, dan turut memperhalusi model sumber terbuka 8B terkuat
Jun 01, 2024 pm 04:41 PM
Untuk menyelaraskan model bahasa besar (LLM) dengan nilai dan niat manusia, adalah penting untuk mempelajari maklum balas manusia untuk memastikan bahawa ia berguna, jujur dan tidak berbahaya. Dari segi penjajaran LLM, kaedah yang berkesan ialah pembelajaran pengukuhan berdasarkan maklum balas manusia (RLHF). Walaupun keputusan kaedah RLHF adalah cemerlang, terdapat beberapa cabaran pengoptimuman yang terlibat. Ini melibatkan latihan model ganjaran dan kemudian mengoptimumkan model dasar untuk memaksimumkan ganjaran tersebut. Baru-baru ini, beberapa penyelidik telah meneroka algoritma luar talian yang lebih mudah, salah satunya ialah pengoptimuman keutamaan langsung (DPO). DPO mempelajari model dasar secara langsung berdasarkan data keutamaan dengan meparameterkan fungsi ganjaran dalam RLHF, sekali gus menghapuskan keperluan untuk model ganjaran yang jelas. Kaedah ini mudah dan stabil
 Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Di barisan hadapan teknologi perisian, kumpulan UIUC Zhang Lingming, bersama penyelidik dari organisasi BigCode, baru-baru ini mengumumkan model kod besar StarCoder2-15B-Instruct. Pencapaian inovatif ini mencapai kejayaan ketara dalam tugas penjanaan kod, berjaya mengatasi CodeLlama-70B-Instruct dan mencapai bahagian atas senarai prestasi penjanaan kod. Keunikan StarCoder2-15B-Instruct terletak pada strategi penjajaran diri yang tulen Keseluruhan proses latihan adalah terbuka, telus, dan sepenuhnya autonomi dan boleh dikawal. Model ini menjana beribu-ribu arahan melalui StarCoder2-15B sebagai tindak balas kepada penalaan halus model asas StarCoder-15B tanpa bergantung pada anotasi manual yang mahal.
 LLM sudah selesai! OmniDrive: Mengintegrasikan persepsi 3D dan perancangan penaakulan (terbaharu NVIDIA)
May 09, 2024 pm 04:55 PM
LLM sudah selesai! OmniDrive: Mengintegrasikan persepsi 3D dan perancangan penaakulan (terbaharu NVIDIA)
May 09, 2024 pm 04:55 PM
Ditulis di atas & pemahaman peribadi pengarang: Kertas kerja ini didedikasikan untuk menyelesaikan cabaran utama model bahasa besar multimodal semasa (MLLM) dalam aplikasi pemanduan autonomi, iaitu masalah melanjutkan MLLM daripada pemahaman 2D kepada ruang 3D. Peluasan ini amat penting kerana kenderaan autonomi (AV) perlu membuat keputusan yang tepat tentang persekitaran 3D. Pemahaman spatial 3D adalah penting untuk AV kerana ia memberi kesan langsung kepada keupayaan kenderaan untuk membuat keputusan termaklum, meramalkan keadaan masa depan dan berinteraksi dengan selamat dengan alam sekitar. Model bahasa besar berbilang mod semasa (seperti LLaVA-1.5) selalunya hanya boleh mengendalikan input imej resolusi rendah (cth.) disebabkan oleh had resolusi pengekod visual, had panjang jujukan LLM. Walau bagaimanapun, aplikasi pemanduan autonomi memerlukan
