
 Peranti teknologi
AI
Menerobos had resolusi: Byte dan Universiti Sains dan Teknologi China mendedahkan model dokumen berbilang modal yang besar
Peranti teknologi
AI
Menerobos had resolusi: Byte dan Universiti Sains dan Teknologi China mendedahkan model dokumen berbilang modal yang besar
Menerobos had resolusi: Byte dan Universiti Sains dan Teknologi China mendedahkan model dokumen berbilang modal yang besar

Kini terdapat juga dokumen resolusi tinggi berbilang modal yang besar!
Teknologi ini bukan sahaja boleh mengenal pasti maklumat dalam imej dengan tepat, tetapi juga memanggil pangkalan pengetahuannya sendiri untuk menjawab soalan mengikut keperluan pengguna
Sebagai contoh, apabila anda melihat antara muka Mario dalam gambar, anda boleh terus menjawab bahawa ia adalah dari Nintendo bekerja.

Model ini telah dikaji bersama oleh ByteDance dan Universiti Sains dan Teknologi China, dan dimuat naik ke arXiv pada 24 November 2023
Dalam penyelidikan ini, pasukan pengarang mencadangkan DocPedia, sebuah resolusi tinggi bersatu Dokumen multimodal model besar DocPedia.

Digabungkan dengan maklumat teks dalam imej, DocPedia juga boleh menggunakan keupayaan penaakulan model yang besar untuk menganalisis masalah berdasarkan konteks. 
Selepas membaca maklumat imej, DocPedia juga akan menjawab kandungan lanjutan yang tidak ditunjukkan dalam imej berdasarkan asas pengetahuan dunianya yang kaya
Jadual berikut secara kuantitatif membandingkan beberapa model besar berbilang mod sedia ada dan kunci DocPedia pengekstrakan maklumat (KIE) dan keupayaan menjawab soalan visual (VQA). 
Jadi, bagaimanakah DocPedia mencapai kesan sedemikian? 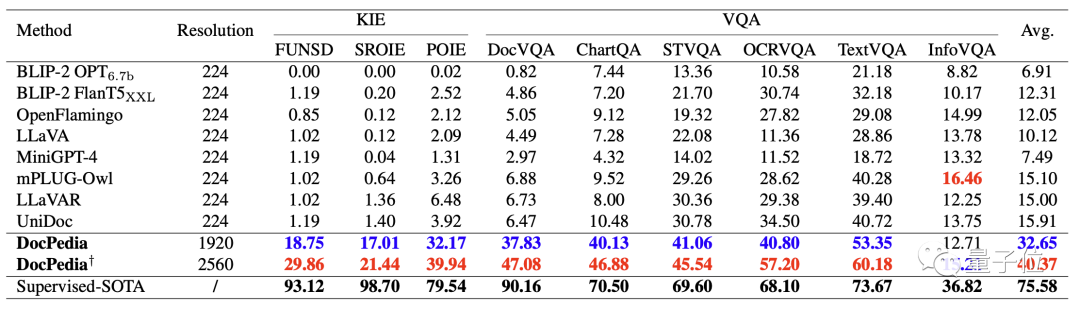
Dari segi strategi untuk isu penyelesaian, berbeza dengan kaedah sedia ada, DocPedia menyelesaikannya dari perspektif 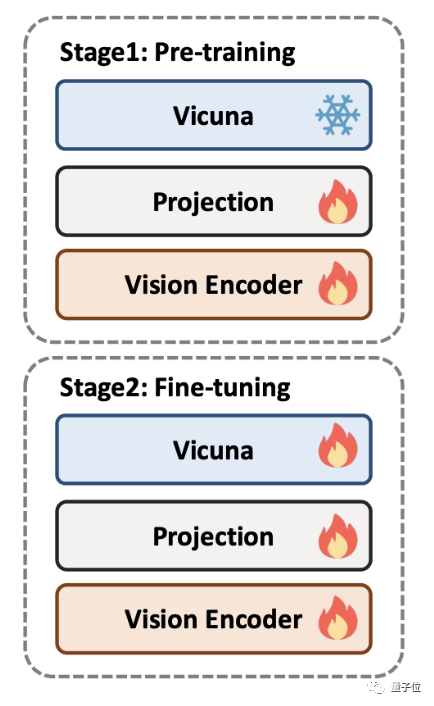 domain frekuensi
domain frekuensi
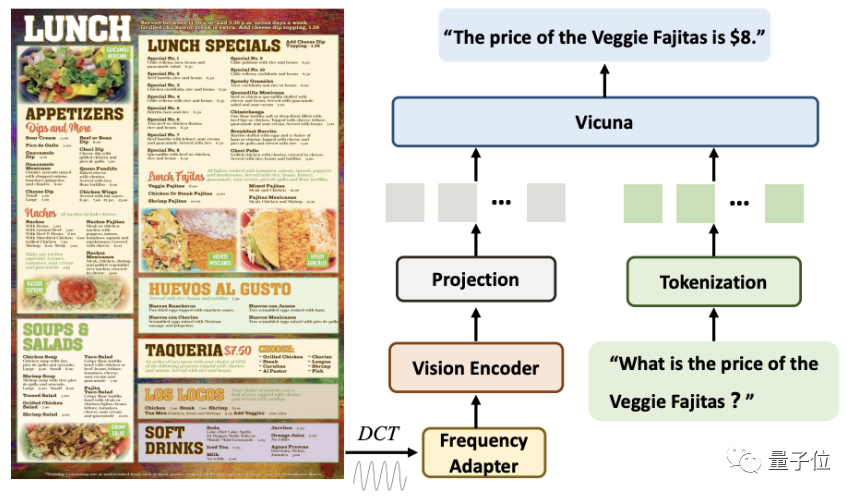
Apabila memproses imej dokumen resolusi tinggi, DocPedia mula-mula mengekstrak matriks pekali DCTnya. Matriks ini boleh menurunkan sampel resolusi spatial 8 kali tanpa kehilangan maklumat teks imej asal
Selepas langkah ini, kami akan menggunakan penyesuai domain frekuensi bertingkat (Penyesuai Frekuensi) untuk menghantar isyarat input Kepada Pengekod Penglihatan untuk pemampatan resolusi yang lebih mendalam dan pengekstrakan ciriDengan kaedah ini, imej 2560×2560 boleh diwakili oleh 1600 token.
Berbanding dengan memasukkan terus imej asal ke dalam pengekod visual (seperti Swin Transformer), kaedah ini mengurangkan bilangan token sebanyak 4 kali ganda.
Akhir sekali, token ini digabungkan dengan token yang ditukar daripada arahan dalam dimensi jujukan dan dimasukkan ke dalam model besar untuk jawapan.
Hasil eksperimen ablasi menunjukkan bahawa meningkatkan resolusi dan melakukan penalaan kefahaman persepsi bersama adalah dua faktor penting untuk meningkatkan prestasi DocPedia
Angka berikut membandingkan prestasi DocPedia bagi imej kertas dan yang sama arahan pada input yang berbeza Jawapan pada skala. Ia boleh dilihat bahawa DocPedia menjawab dengan betul jika dan hanya jika resolusi ditingkatkan kepada 2560 × 2560.

Gambar di bawah membandingkan respons model DocPedia kepada imej teks adegan yang sama dan arahan yang sama di bawah strategi penalaan halus yang berbeza.
Dapat dilihat daripada contoh ini bahawa model yang telah diperhalusi melalui pemahaman-persepsi boleh melakukan pengecaman teks dan soal jawab semantik dengan tepat

Sila klik pautan berikut untuk melihat kertas kerja: https: //arxiv.org/abs/ 2311.11810
Atas ialah kandungan terperinci Menerobos had resolusi: Byte dan Universiti Sains dan Teknologi China mendedahkan model dokumen berbilang modal yang besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Gunakan ddrescue untuk memulihkan data pada Linux
Mar 20, 2024 pm 01:37 PM
Gunakan ddrescue untuk memulihkan data pada Linux
Mar 20, 2024 pm 01:37 PM
DDREASE ialah alat untuk memulihkan data daripada fail atau peranti sekat seperti cakera keras, SSD, cakera RAM, CD, DVD dan peranti storan USB. Ia menyalin data dari satu peranti blok ke peranti lain, meninggalkan blok data yang rosak dan hanya memindahkan blok data yang baik. ddreasue ialah alat pemulihan yang berkuasa yang automatik sepenuhnya kerana ia tidak memerlukan sebarang gangguan semasa operasi pemulihan. Selain itu, terima kasih kepada fail peta ddasue, ia boleh dihentikan dan disambung semula pada bila-bila masa. Ciri-ciri utama lain DDREASE adalah seperti berikut: Ia tidak menimpa data yang dipulihkan tetapi mengisi jurang sekiranya pemulihan berulang. Walau bagaimanapun, ia boleh dipotong jika alat itu diarahkan untuk melakukannya secara eksplisit. Pulihkan data daripada berbilang fail atau blok kepada satu
 Sumber terbuka! Di luar ZoeDepth! DepthFM: Anggaran kedalaman monokular yang cepat dan tepat!
Apr 03, 2024 pm 12:04 PM
Sumber terbuka! Di luar ZoeDepth! DepthFM: Anggaran kedalaman monokular yang cepat dan tepat!
Apr 03, 2024 pm 12:04 PM
0. Apakah fungsi artikel ini? Kami mencadangkan DepthFM: model anggaran kedalaman monokular generatif yang serba boleh dan pantas. Sebagai tambahan kepada tugas anggaran kedalaman tradisional, DepthFM juga menunjukkan keupayaan terkini dalam tugas hiliran seperti mengecat kedalaman. DepthFM cekap dan boleh mensintesis peta kedalaman dalam beberapa langkah inferens. Mari kita baca karya ini bersama-sama ~ 1. Tajuk maklumat kertas: DepthFM: FastMonocularDepthEstimationwithFlowMatching Pengarang: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Prestasi JAX, yang dipromosikan oleh Google, telah mengatasi Pytorch dan TensorFlow dalam ujian penanda aras baru-baru ini, menduduki tempat pertama dalam 7 penunjuk. Dan ujian tidak dilakukan pada TPU dengan prestasi JAX terbaik. Walaupun dalam kalangan pembangun, Pytorch masih lebih popular daripada Tensorflow. Tetapi pada masa hadapan, mungkin lebih banyak model besar akan dilatih dan dijalankan berdasarkan platform JAX. Model Baru-baru ini, pasukan Keras menanda aras tiga hujung belakang (TensorFlow, JAX, PyTorch) dengan pelaksanaan PyTorch asli dan Keras2 dengan TensorFlow. Pertama, mereka memilih satu set arus perdana
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
 Kelajuan Internet Data Selular Perlahan pada iPhone: Pembetulan
May 03, 2024 pm 09:01 PM
Kelajuan Internet Data Selular Perlahan pada iPhone: Pembetulan
May 03, 2024 pm 09:01 PM
Menghadapi ketinggalan, sambungan data mudah alih perlahan pada iPhone? Biasanya, kekuatan internet selular pada telefon anda bergantung pada beberapa faktor seperti rantau, jenis rangkaian selular, jenis perayauan, dsb. Terdapat beberapa perkara yang boleh anda lakukan untuk mendapatkan sambungan Internet selular yang lebih pantas dan boleh dipercayai. Betulkan 1 – Paksa Mulakan Semula iPhone Kadangkala, paksa memulakan semula peranti anda hanya menetapkan semula banyak perkara, termasuk sambungan selular. Langkah 1 – Hanya tekan kekunci naikkan kelantangan sekali dan lepaskan. Seterusnya, tekan kekunci Turun Kelantangan dan lepaskannya semula. Langkah 2 - Bahagian seterusnya proses adalah untuk menahan butang di sebelah kanan. Biarkan iPhone selesai dimulakan semula. Dayakan data selular dan semak kelajuan rangkaian. Semak semula Betulkan 2 – Tukar mod data Walaupun 5G menawarkan kelajuan rangkaian yang lebih baik, ia berfungsi lebih baik apabila isyarat lemah
 Daya hidup kecerdasan super membangkitkan! Tetapi dengan kedatangan AI yang mengemas kini sendiri, ibu tidak perlu lagi bimbang tentang kesesakan data
Apr 29, 2024 pm 06:55 PM
Daya hidup kecerdasan super membangkitkan! Tetapi dengan kedatangan AI yang mengemas kini sendiri, ibu tidak perlu lagi bimbang tentang kesesakan data
Apr 29, 2024 pm 06:55 PM
Saya menangis hingga mati. Dunia sedang membina model besar. Data di Internet tidak mencukupi. Model latihan kelihatan seperti "The Hunger Games", dan penyelidik AI di seluruh dunia bimbang tentang cara memberi makan data ini kepada pemakan yang rakus. Masalah ini amat ketara dalam tugas berbilang modal. Pada masa mereka mengalami kerugian, pasukan pemula dari Jabatan Universiti Renmin China menggunakan model baharu mereka sendiri untuk menjadi yang pertama di China untuk menjadikan "suapan data yang dijana model itu sendiri" menjadi kenyataan. Selain itu, ia merupakan pendekatan serampang dua mata dari segi pemahaman dan sisi penjanaan Kedua-dua pihak boleh menjana data baharu berbilang modal yang berkualiti tinggi dan memberikan maklum balas data kepada model itu sendiri. Apakah model? Awaker 1.0, model berbilang modal besar yang baru sahaja muncul di Forum Zhongguancun. Siapa pasukan itu? Enjin Sophon. Diasaskan oleh Gao Yizhao, pelajar kedoktoran di Sekolah Kecerdasan Buatan Hillhouse Universiti Renmin.
 Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Video terbaru robot Tesla Optimus dikeluarkan, dan ia sudah boleh berfungsi di kilang. Pada kelajuan biasa, ia mengisih bateri (bateri 4680 Tesla) seperti ini: Pegawai itu juga mengeluarkan rupanya pada kelajuan 20x - pada "stesen kerja" kecil, memilih dan memilih dan memilih: Kali ini ia dikeluarkan Salah satu sorotan video itu ialah Optimus menyelesaikan kerja ini di kilang, sepenuhnya secara autonomi, tanpa campur tangan manusia sepanjang proses. Dan dari perspektif Optimus, ia juga boleh mengambil dan meletakkan bateri yang bengkok, memfokuskan pada pembetulan ralat automatik: Berkenaan tangan Optimus, saintis NVIDIA Jim Fan memberikan penilaian yang tinggi: Tangan Optimus adalah robot lima jari di dunia paling cerdik. Tangannya bukan sahaja boleh disentuh
 Versi Kuaishou Sora 'Ke Ling' dibuka untuk ujian: menghasilkan video lebih 120-an, memahami fizik dengan lebih baik dan boleh memodelkan pergerakan kompleks dengan tepat
Jun 11, 2024 am 09:51 AM
Versi Kuaishou Sora 'Ke Ling' dibuka untuk ujian: menghasilkan video lebih 120-an, memahami fizik dengan lebih baik dan boleh memodelkan pergerakan kompleks dengan tepat
Jun 11, 2024 am 09:51 AM
Apa? Adakah Zootopia dibawa menjadi realiti oleh AI domestik? Didedahkan bersama-sama dengan video itu ialah model penjanaan video domestik berskala besar baharu yang dipanggil "Keling". Sora menggunakan laluan teknikal yang serupa dan menggabungkan beberapa inovasi teknologi yang dibangunkan sendiri untuk menghasilkan video yang bukan sahaja mempunyai pergerakan yang besar dan munasabah, tetapi juga mensimulasikan ciri-ciri dunia fizikal dan mempunyai keupayaan gabungan konsep dan imaginasi yang kuat. Mengikut data, Keling menyokong penjanaan video ultra panjang sehingga 2 minit pada 30fps, dengan resolusi sehingga 1080p dan menyokong berbilang nisbah aspek. Satu lagi perkara penting ialah Keling bukanlah demo atau demonstrasi hasil video yang dikeluarkan oleh makmal, tetapi aplikasi peringkat produk yang dilancarkan oleh Kuaishou, pemain terkemuka dalam bidang video pendek. Selain itu, tumpuan utama adalah untuk menjadi pragmatik, bukan untuk menulis cek kosong, dan pergi ke dalam talian sebaik sahaja ia dikeluarkan Model besar Ke Ling telah pun dikeluarkan di Kuaiying.
