
 Peranti teknologi
AI
Dengan kurang daripada 1,000 baris kod, pasukan PyTorch membuat Llama 7B 10 kali lebih pantas
Peranti teknologi
AI
Dengan kurang daripada 1,000 baris kod, pasukan PyTorch membuat Llama 7B 10 kali lebih pantas
Dengan kurang daripada 1,000 baris kod, pasukan PyTorch membuat Llama 7B 10 kali lebih pantas

Pasukan PyTorch secara peribadi mengajar anda cara mempercepatkan inferens model besar.

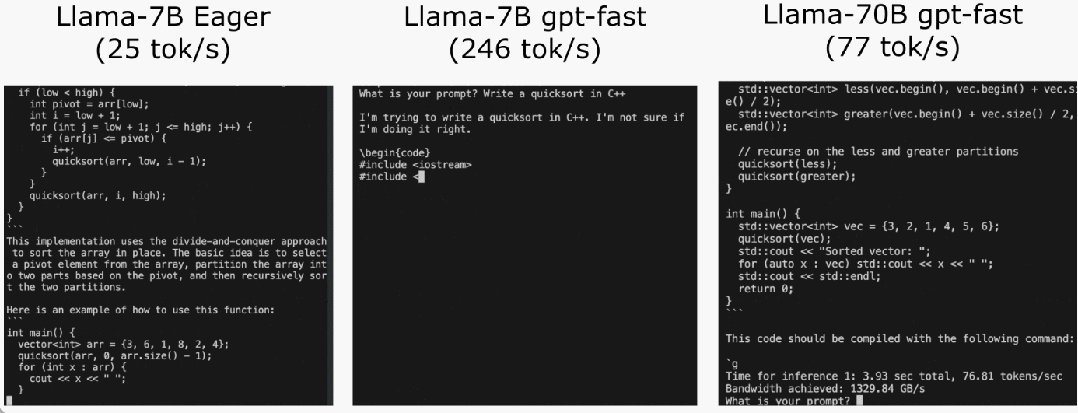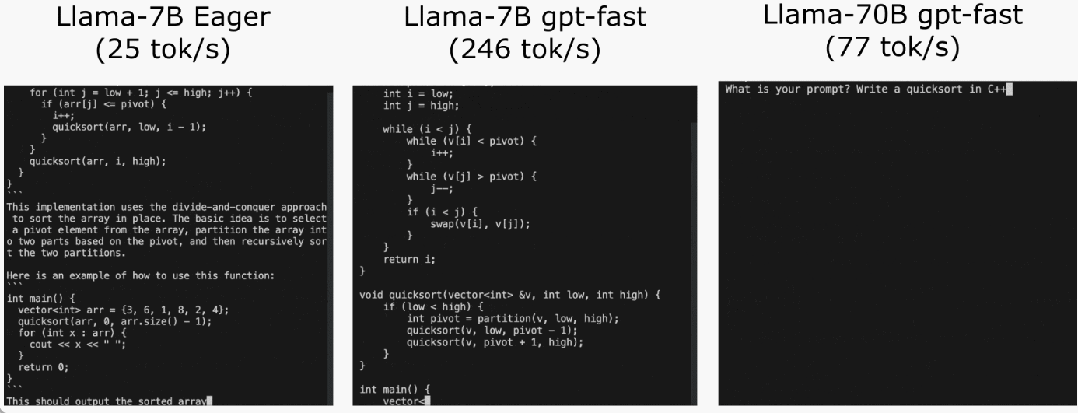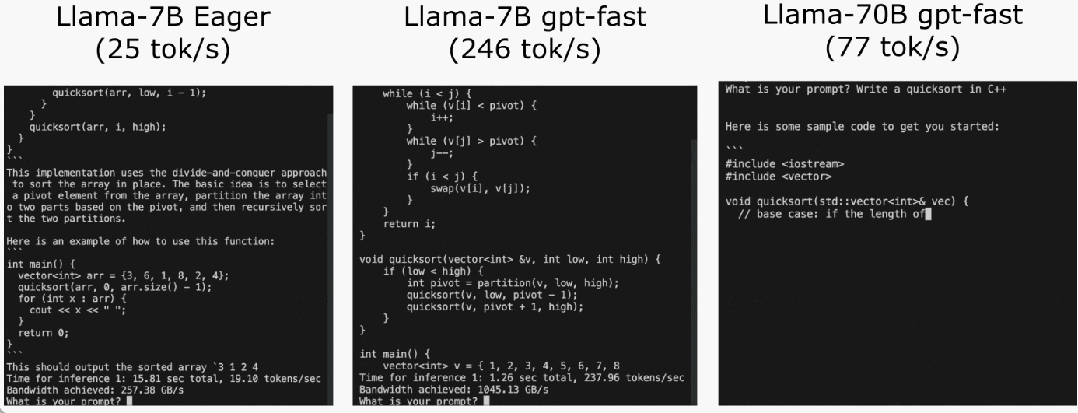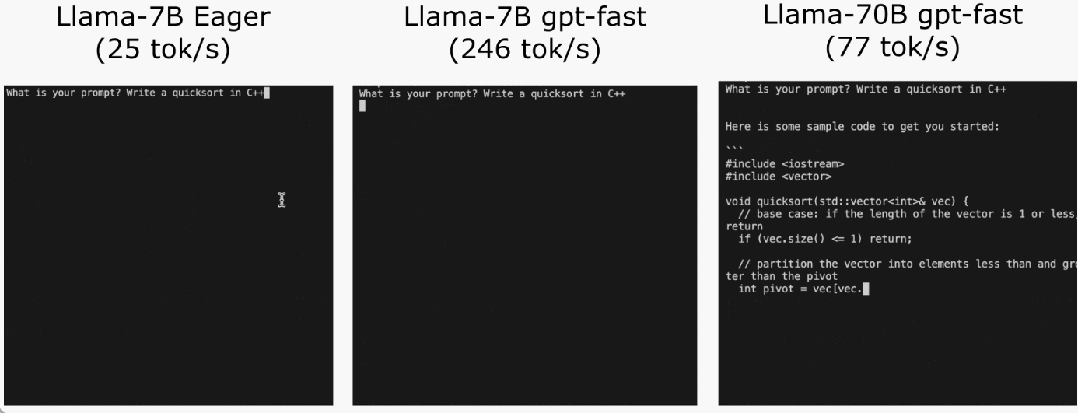
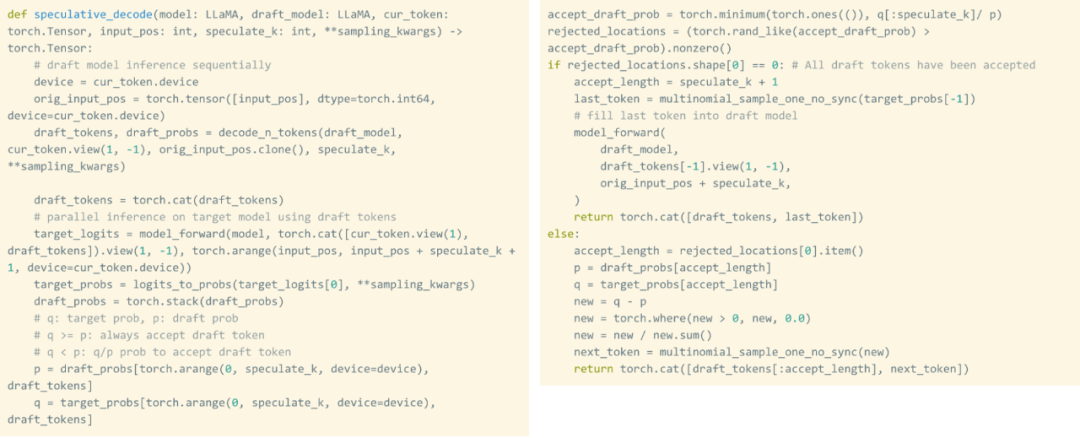
Torch.compile: Penyusun model PyTorch, PyTorch 2.0 menambah satu fungsi pengkompil baris baharu yang dipanggil () torch.compile yang mana can.compile yang sedia ada. model; GPU kuantisasi: mempercepatkan model dengan mengurangkan ketepatan pengiraan Penyahkodan Spekulatif: kaedah pecutan inferens model besar yang menggunakan model "draf" kecil untuk meramalkan "model" yang besar ; Tensor Selari: Mempercepatkan inferens model dengan menjalankan model pada berbilang peranti.
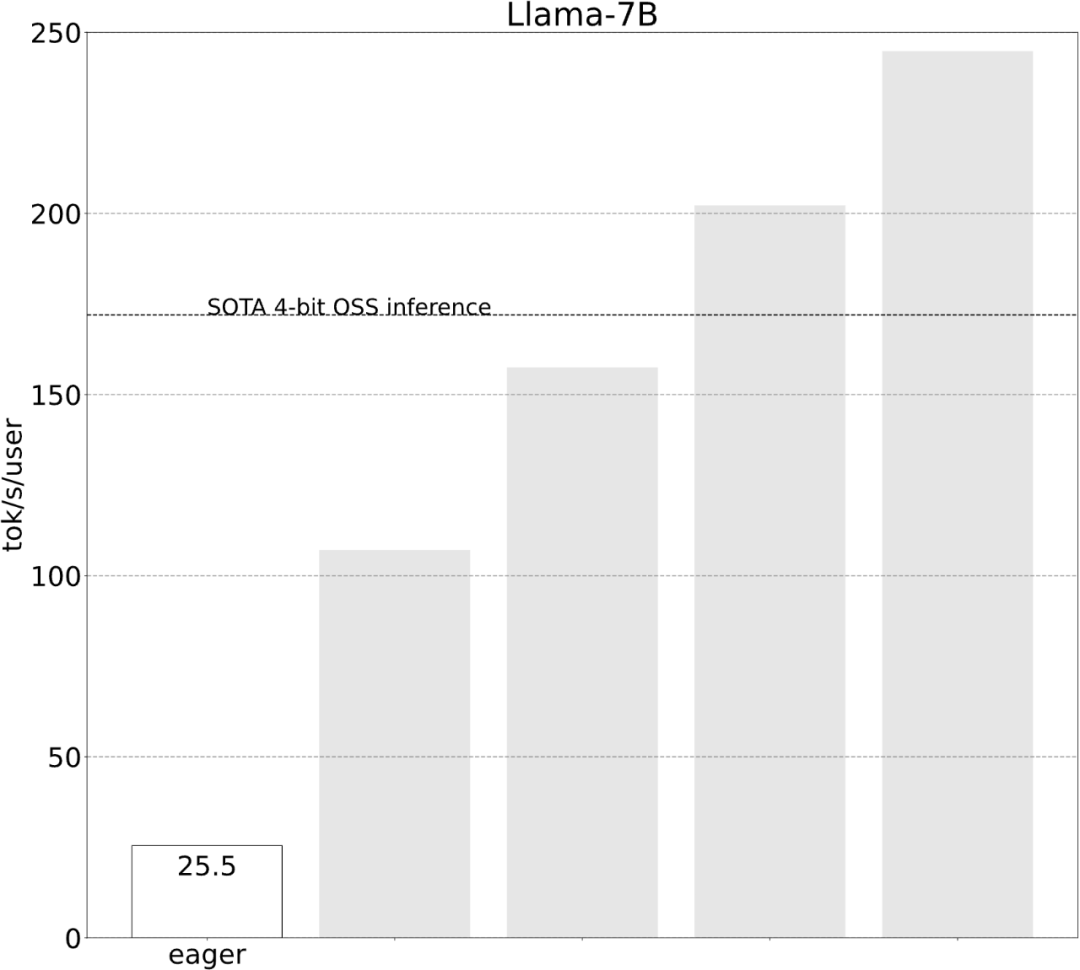 Selepas beberapa penerokaan, akhirnya saya menemui sebabnya: overhed CPU yang berlebihan. Kemudian terdapat proses pengoptimuman 6 langkah berikut.
Selepas beberapa penerokaan, akhirnya saya menemui sebabnya: overhed CPU yang berlebihan. Kemudian terdapat proses pengoptimuman 6 langkah berikut.

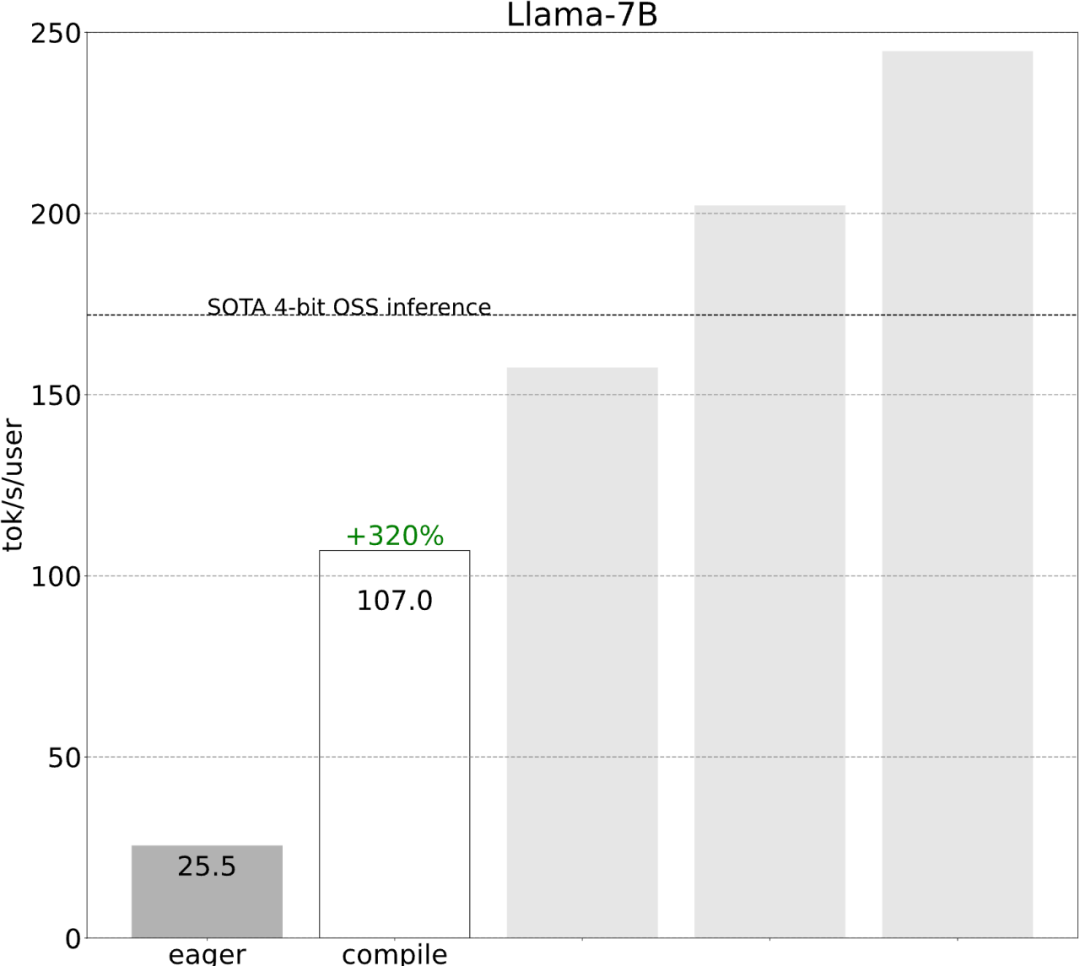
torch.compile membenarkan pengguna untuk menangkap satu kawasan yang lebih besar ke dalam satu rantau yang lebih besar. ="reduce-overhead" (rujuk kod di bawah), fungsi ini sangat berkesan dalam mengurangkan overhead CPU Selain itu, artikel ini juga menyatakan fullgraph=True untuk mengesahkan bahawa tiada "gangguan graf" dalam model ( Iaitu. , bahagian yang torch.compile tidak boleh compile).
 Namun, walaupun dengan restu obor.compile, masih terdapat beberapa halangan.
Namun, walaupun dengan restu obor.compile, masih terdapat beberapa halangan.
Halangan pertama ialah cache kv. Iaitu, apabila pengguna menjana lebih banyak token, "panjang logik" cache kv akan berkembang. Masalah ini berlaku kerana dua sebab: pertama, adalah sangat mahal untuk mengagihkan semula (dan menyalin) cache kv setiap kali cache berkembang kedua, peruntukan dinamik ini menjadikannya lebih sukar untuk mengurangkan overhed.
Untuk menyelesaikan masalah ini, artikel ini menggunakan cache KV statik, memperuntukkan saiz cache KV secara statik, dan kemudian menutup nilai yang tidak digunakan dalam mekanisme perhatian.

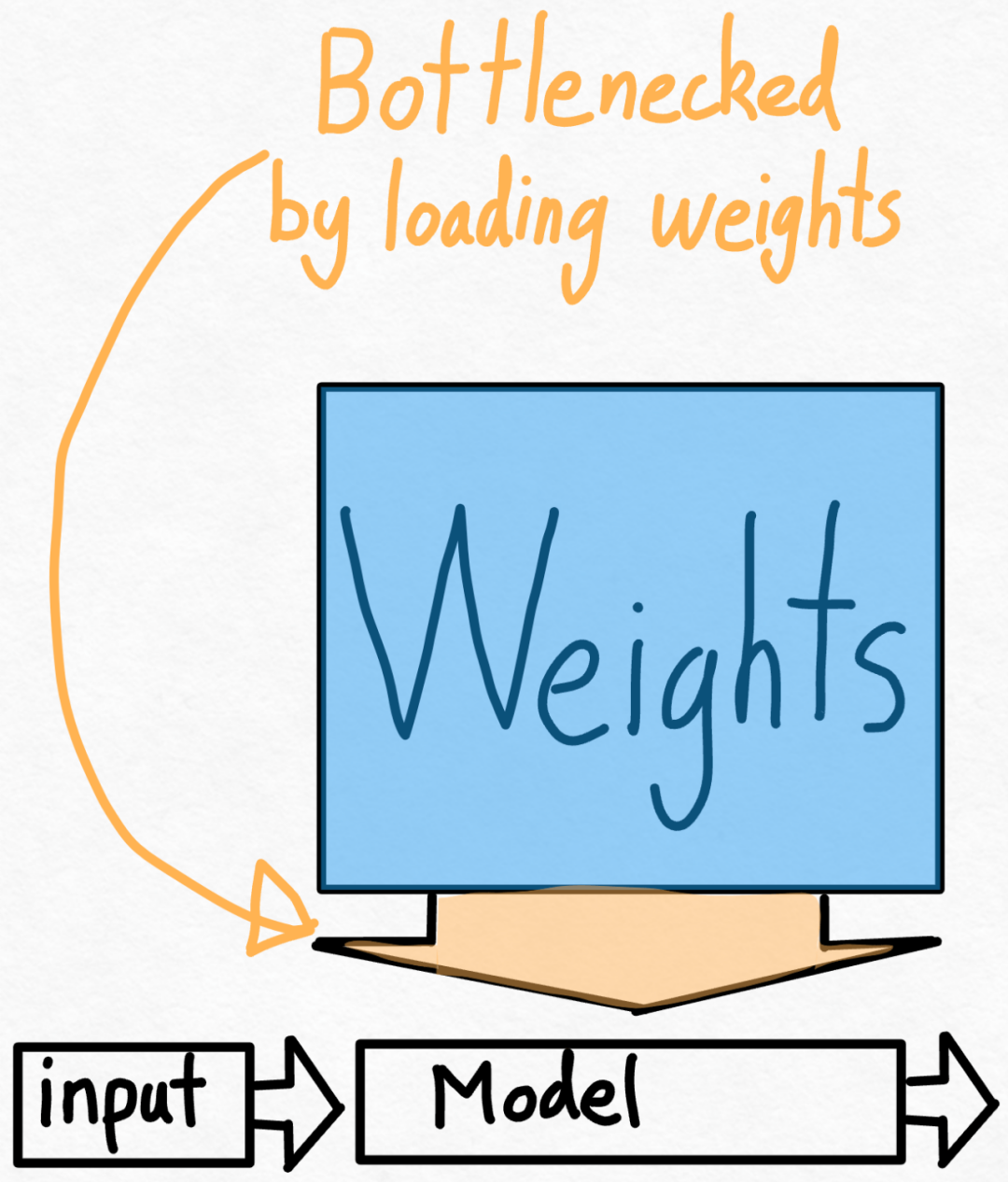

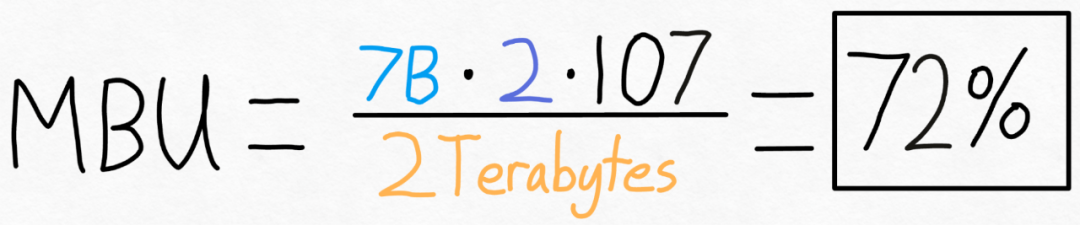

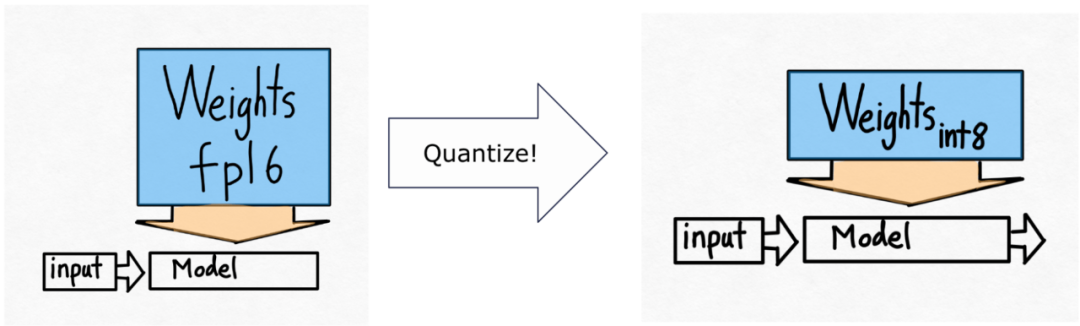

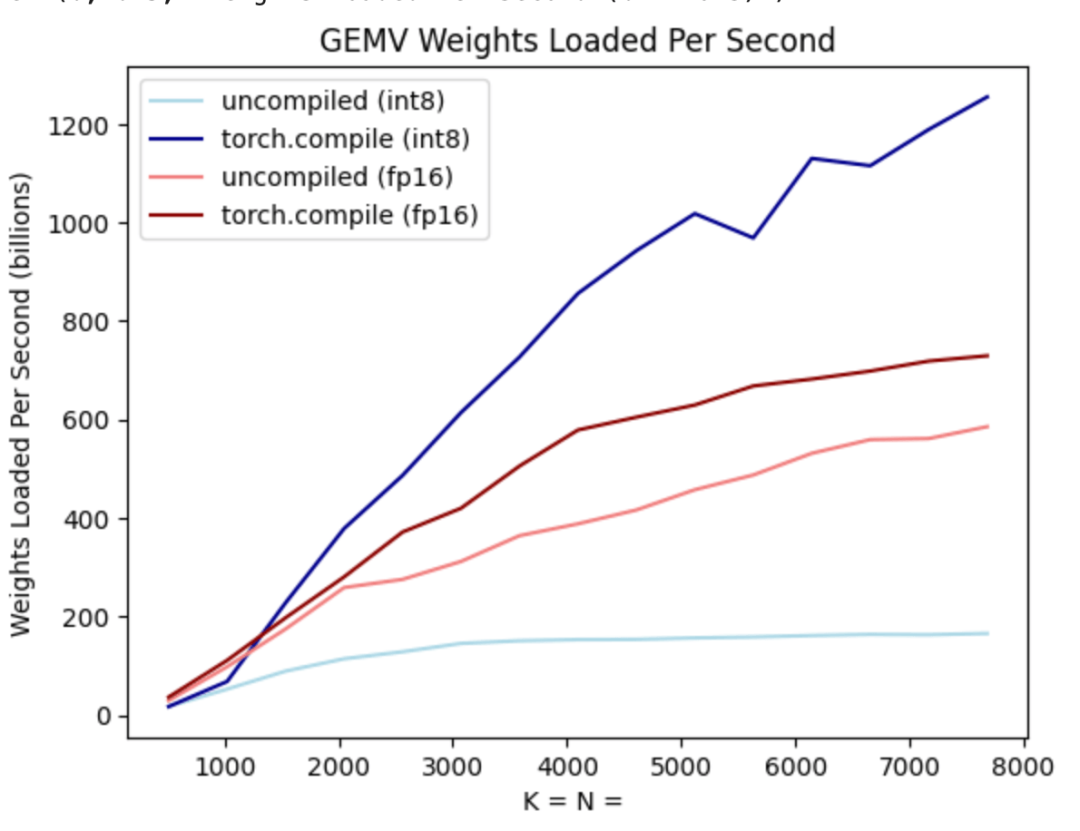
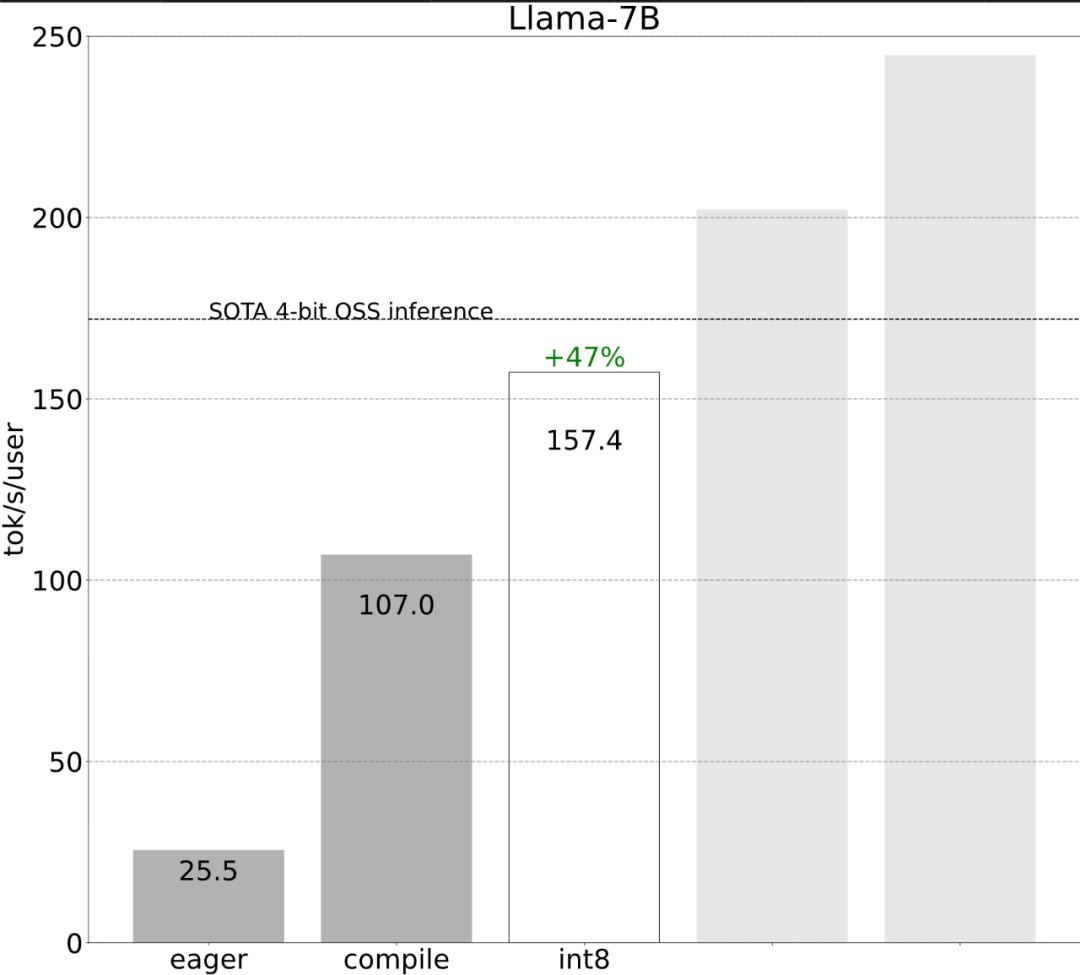
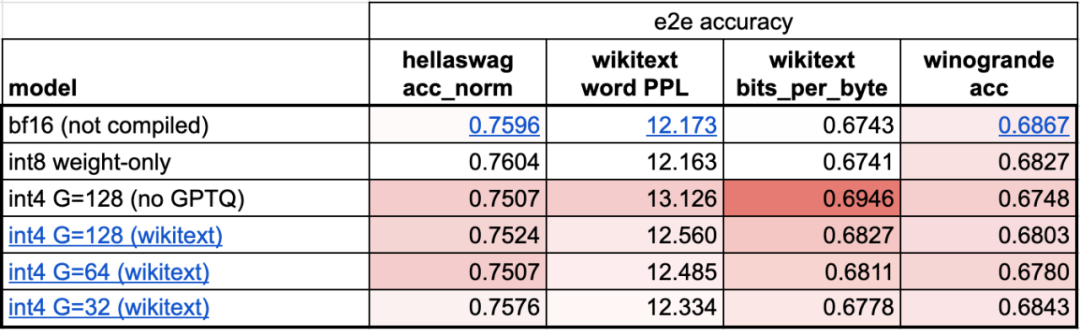
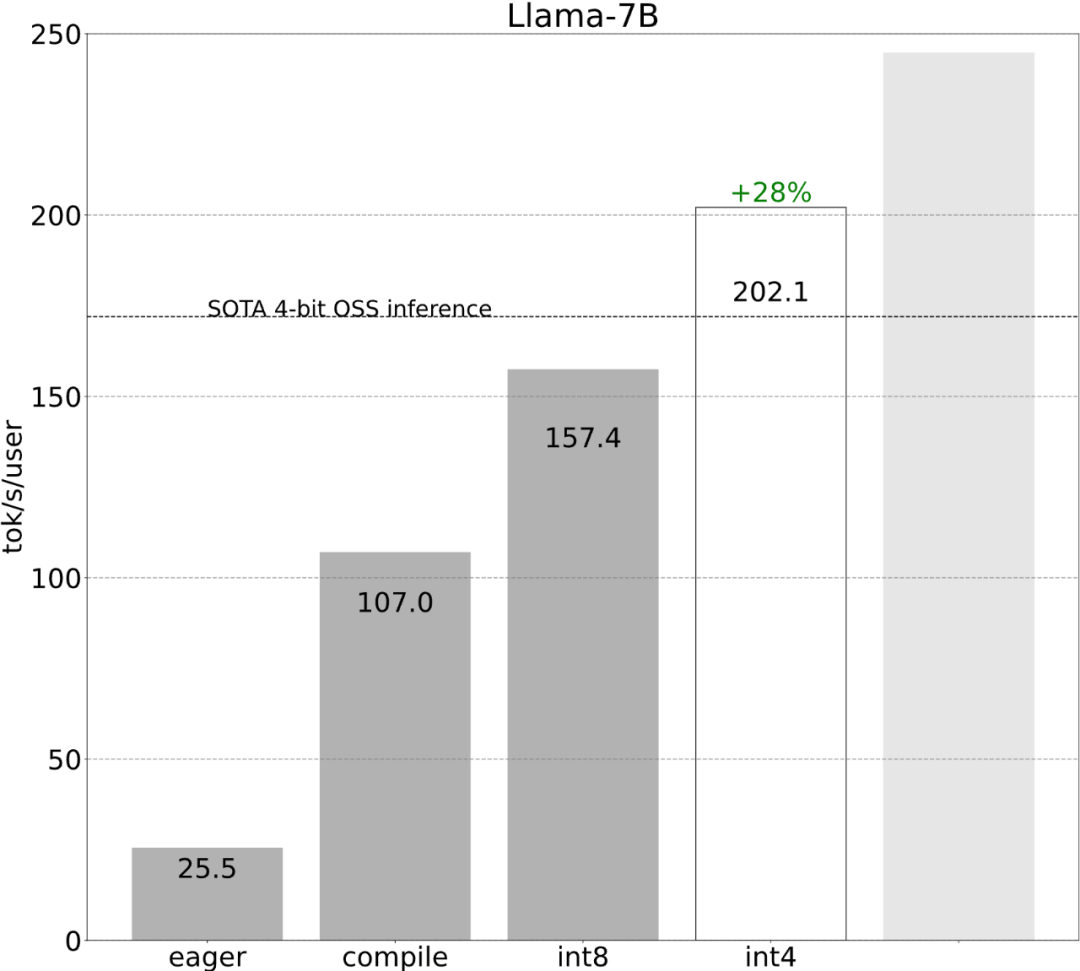
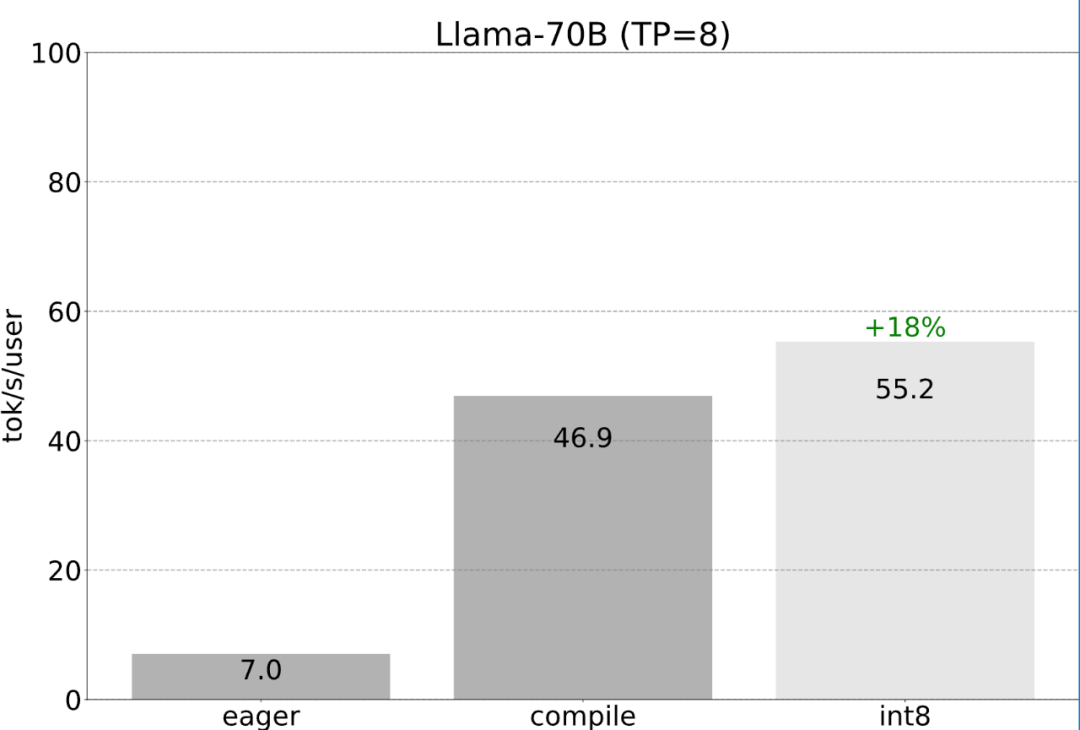
Semua pengoptimuman yang dinyatakan sebelum ini boleh terus digabungkan dengan keselarian tensor, yang bersama-sama menyediakan kuantisasi int8 untuk model Llama-70B pada 55 token/s.
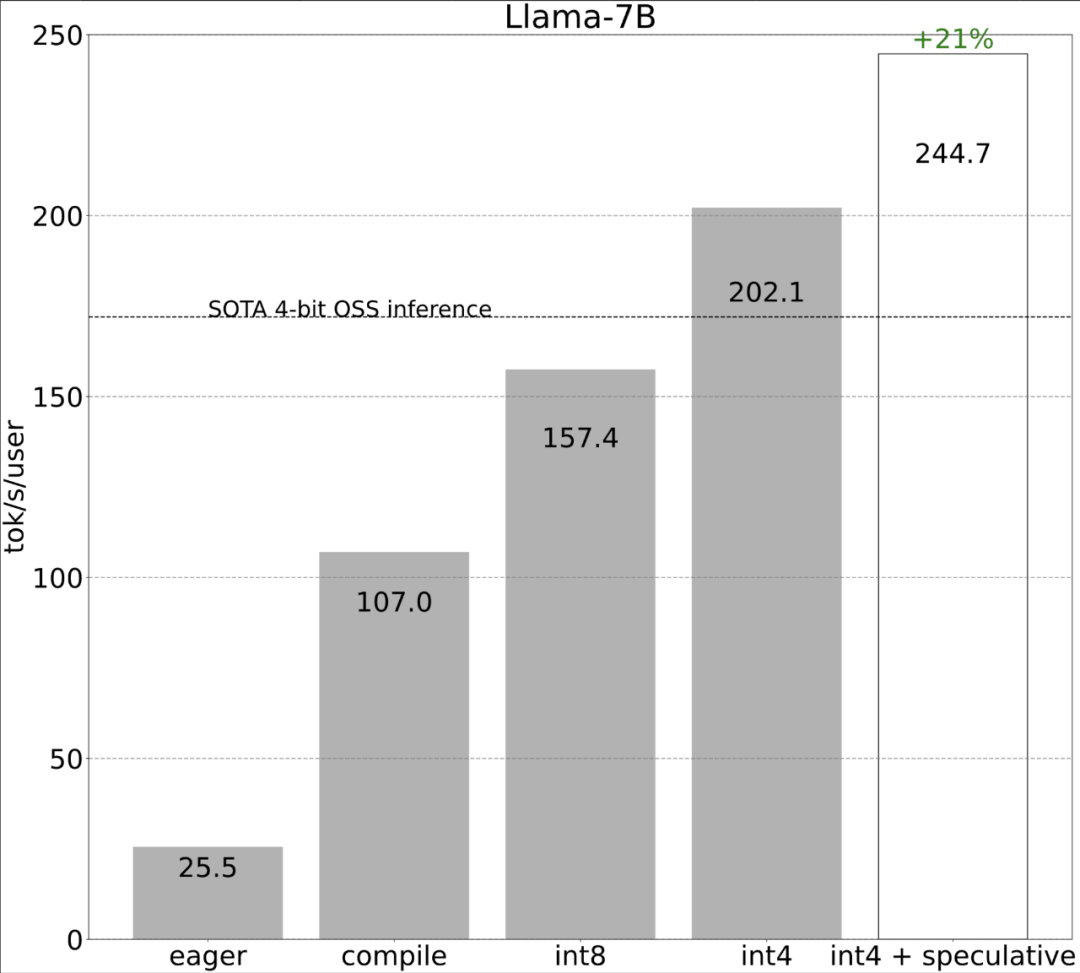
Akhir sekali, rumuskan secara ringkas isi utama artikel. Pada Llama-7B, artikel ini menggunakan gabungan "kompilasi + kuantiti int4 + penyahkodan spekulatif" untuk mencapai 240+ tok/s. Pada Llama-70B, kertas kerja ini juga memperkenalkan keselarian tensor untuk mencapai kira-kira 80 tok/s, yang hampir dengan atau melebihi prestasi SOTA.

Atas ialah kandungan terperinci Dengan kurang daripada 1,000 baris kod, pasukan PyTorch membuat Llama 7B 10 kali lebih pantas. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Tutorial Model Penyebaran Bernilai Masa Anda, dari Universiti Purdue
Apr 07, 2024 am 09:01 AM
Tutorial Model Penyebaran Bernilai Masa Anda, dari Universiti Purdue
Apr 07, 2024 am 09:01 AM
Penyebaran bukan sahaja boleh meniru lebih baik, tetapi juga "mencipta". Model resapan (DiffusionModel) ialah model penjanaan imej. Berbanding dengan algoritma yang terkenal seperti GAN dan VAE dalam bidang AI, model resapan mengambil pendekatan yang berbeza. Idea utamanya ialah proses menambah hingar pada imej dan kemudian secara beransur-ansur menolaknya. Cara mengecilkan dan memulihkan imej asal adalah bahagian teras algoritma. Algoritma akhir mampu menghasilkan imej daripada imej bising rawak. Dalam beberapa tahun kebelakangan ini, pertumbuhan luar biasa AI generatif telah membolehkan banyak aplikasi menarik dalam penjanaan teks ke imej, penjanaan video dan banyak lagi. Prinsip asas di sebalik alat generatif ini ialah konsep resapan, mekanisme pensampelan khas yang mengatasi batasan kaedah sebelumnya.
 Hasilkan PPT dengan satu klik! Kimi: Biarlah 'pekerja migran PPT' menjadi popular dahulu
Aug 01, 2024 pm 03:28 PM
Hasilkan PPT dengan satu klik! Kimi: Biarlah 'pekerja migran PPT' menjadi popular dahulu
Aug 01, 2024 pm 03:28 PM
Kimi: Hanya dalam satu ayat, dalam sepuluh saat sahaja, PPT akan siap. PPT sangat menjengkelkan! Untuk mengadakan mesyuarat, anda perlu mempunyai PPT; untuk menulis laporan mingguan, anda perlu mempunyai PPT untuk membuat pelaburan, anda perlu menunjukkan PPT walaupun anda menuduh seseorang menipu, anda perlu menghantar PPT. Kolej lebih seperti belajar jurusan PPT Anda menonton PPT di dalam kelas dan melakukan PPT selepas kelas. Mungkin, apabila Dennis Austin mencipta PPT 37 tahun lalu, dia tidak menyangka satu hari nanti PPT akan berleluasa. Bercakap tentang pengalaman sukar kami membuat PPT membuatkan kami menitiskan air mata. "Ia mengambil masa tiga bulan untuk membuat PPT lebih daripada 20 muka surat, dan saya menyemaknya berpuluh-puluh kali. Saya rasa ingin muntah apabila saya melihat PPT itu." ialah PPT." Jika anda mengadakan mesyuarat dadakan, anda harus melakukannya
 Gabungan sempurna PyCharm dan PyTorch: langkah pemasangan dan konfigurasi terperinci
Feb 21, 2024 pm 12:00 PM
Gabungan sempurna PyCharm dan PyTorch: langkah pemasangan dan konfigurasi terperinci
Feb 21, 2024 pm 12:00 PM
PyCharm ialah persekitaran pembangunan bersepadu (IDE) yang berkuasa dan PyTorch ialah rangka kerja sumber terbuka yang popular dalam bidang pembelajaran mendalam. Dalam bidang pembelajaran mesin dan pembelajaran mendalam, menggunakan PyCharm dan PyTorch untuk pembangunan boleh meningkatkan kecekapan pembangunan dan kualiti kod. Artikel ini akan memperkenalkan secara terperinci cara memasang dan mengkonfigurasi PyTorch dalam PyCharm, dan melampirkan contoh kod khusus untuk membantu pembaca menggunakan fungsi berkuasa kedua-dua ini dengan lebih baik. Langkah 1: Pasang PyCharm dan Python
 Pengenalan kepada lima kaedah pensampelan dalam tugas penjanaan bahasa semula jadi dan pelaksanaan kod Pytorch
Feb 20, 2024 am 08:50 AM
Pengenalan kepada lima kaedah pensampelan dalam tugas penjanaan bahasa semula jadi dan pelaksanaan kod Pytorch
Feb 20, 2024 am 08:50 AM
Dalam tugas penjanaan bahasa semula jadi, kaedah pensampelan ialah teknik untuk mendapatkan output teks daripada model generatif. Artikel ini akan membincangkan 5 kaedah biasa dan melaksanakannya menggunakan PyTorch. 1. GreedyDecoding Dalam penyahkodan tamak, model generatif meramalkan perkataan urutan keluaran berdasarkan urutan input masa langkah demi masa. Pada setiap langkah masa, model mengira taburan kebarangkalian bersyarat bagi setiap perkataan, dan kemudian memilih perkataan dengan kebarangkalian bersyarat tertinggi sebagai output langkah masa semasa. Perkataan ini menjadi input kepada langkah masa seterusnya, dan proses penjanaan diteruskan sehingga beberapa syarat penamatan dipenuhi, seperti urutan panjang tertentu atau penanda akhir khas. Ciri GreedyDecoding ialah setiap kali kebarangkalian bersyarat semasa adalah yang terbaik
 Tutorial memasang PyCharm dengan PyTorch
Feb 24, 2024 am 10:09 AM
Tutorial memasang PyCharm dengan PyTorch
Feb 24, 2024 am 10:09 AM
Sebagai rangka kerja pembelajaran mendalam yang berkuasa, PyTorch digunakan secara meluas dalam pelbagai projek pembelajaran mesin. Sebagai persekitaran pembangunan bersepadu Python yang berkuasa, PyCharm juga boleh memberikan sokongan yang baik apabila melaksanakan tugas pembelajaran mendalam. Artikel ini akan memperkenalkan secara terperinci cara memasang PyTorch dalam PyCharm dan menyediakan contoh kod khusus untuk membantu pembaca mula menggunakan PyTorch dengan cepat untuk tugasan pembelajaran mendalam. Langkah 1: Pasang PyCharm Mula-mula, kita perlu pastikan kita ada
 Semua anugerah CVPR 2024 diumumkan! Hampir 10,000 orang menghadiri persidangan itu di luar talian dan seorang penyelidik Cina dari Google memenangi anugerah kertas terbaik
Jun 20, 2024 pm 05:43 PM
Semua anugerah CVPR 2024 diumumkan! Hampir 10,000 orang menghadiri persidangan itu di luar talian dan seorang penyelidik Cina dari Google memenangi anugerah kertas terbaik
Jun 20, 2024 pm 05:43 PM
Pada awal pagi 20 Jun, waktu Beijing, CVPR2024, persidangan penglihatan komputer antarabangsa teratas yang diadakan di Seattle, secara rasmi mengumumkan kertas kerja terbaik dan anugerah lain. Pada tahun ini, sebanyak 10 kertas memenangi anugerah, termasuk 2 kertas terbaik dan 2 kertas pelajar terbaik Selain itu, terdapat 2 pencalonan kertas terbaik dan 4 pencalonan kertas pelajar terbaik. Persidangan teratas dalam bidang visi komputer (CV) ialah CVPR, yang menarik sejumlah besar institusi penyelidikan dan universiti setiap tahun. Mengikut statistik, sebanyak 11,532 kertas telah diserahkan tahun ini, 2,719 daripadanya diterima, dengan kadar penerimaan 23.6%. Menurut analisis statistik data CVPR2024 Institut Teknologi Georgia, dari perspektif topik penyelidikan, bilangan kertas terbesar ialah sintesis dan penjanaan imej dan video (Imageandvideosyn
 Lima perisian pengaturcaraan untuk memulakan pembelajaran bahasa C
Feb 19, 2024 pm 04:51 PM
Lima perisian pengaturcaraan untuk memulakan pembelajaran bahasa C
Feb 19, 2024 pm 04:51 PM
Sebagai bahasa pengaturcaraan yang digunakan secara meluas, bahasa C merupakan salah satu bahasa asas yang mesti dipelajari bagi mereka yang ingin melibatkan diri dalam pengaturcaraan komputer. Walau bagaimanapun, bagi pemula, mempelajari bahasa pengaturcaraan baharu boleh menjadi sukar, terutamanya disebabkan kekurangan alat pembelajaran dan bahan pengajaran yang berkaitan. Dalam artikel ini, saya akan memperkenalkan lima perisian pengaturcaraan untuk membantu pemula memulakan bahasa C dan membantu anda bermula dengan cepat. Perisian pengaturcaraan pertama ialah Code::Blocks. Code::Blocks ialah persekitaran pembangunan bersepadu sumber terbuka (IDE) percuma untuk
 Daripada logam kosong kepada model besar dengan 70 bilion parameter, berikut ialah tutorial dan skrip sedia untuk digunakan
Jul 24, 2024 pm 08:13 PM
Daripada logam kosong kepada model besar dengan 70 bilion parameter, berikut ialah tutorial dan skrip sedia untuk digunakan
Jul 24, 2024 pm 08:13 PM
Kami tahu bahawa LLM dilatih pada kelompok komputer berskala besar menggunakan data besar-besaran Tapak ini telah memperkenalkan banyak kaedah dan teknologi yang digunakan untuk membantu dan menambah baik proses latihan LLM. Hari ini, perkara yang ingin kami kongsikan ialah artikel yang mendalami teknologi asas dan memperkenalkan cara menukar sekumpulan "logam kosong" tanpa sistem pengendalian pun menjadi gugusan komputer untuk latihan LLM. Artikel ini datang daripada Imbue, sebuah permulaan AI yang berusaha untuk mencapai kecerdasan am dengan memahami cara mesin berfikir. Sudah tentu, mengubah sekumpulan "logam kosong" tanpa sistem pengendalian menjadi gugusan komputer untuk latihan LLM bukanlah proses yang mudah, penuh dengan penerokaan dan percubaan dan kesilapan, tetapi Imbue akhirnya berjaya melatih LLM dengan 70 bilion parameter proses terkumpul
