

Model sumber terbuka menunjukkan daya hidup yang cergas, bukan sahaja bilangannya semakin meningkat, malah prestasinya semakin baik dan lebih baik. Pemenang Anugerah Turing, Yann LeCun juga mengeluh: "Model kecerdasan buatan sumber terbuka sedang menuju ke arah mengatasi model proprietari
Model proprietari telah menunjukkan potensi yang besar dari segi prestasi teknikal dan keupayaan inovasi , tetapi disebabkan oleh bukan-. ciri sumber terbuka, ia menghalang pembangunan LLM. Walaupun sesetengah model sumber terbuka menyediakan pelbagai pilihan kepada pengamal dan penyelidik, kebanyakannya hanya mendedahkan berat model akhir atau kod inferens, dan peningkatan jumlah laporan teknikal mengehadkan skopnya kepada reka bentuk peringkat atas dan statistik permukaan. Strategi sumber tertutup ini bukan sahaja mengehadkan pembangunan model sumber terbuka, tetapi juga menghalang kemajuan keseluruhan bidang penyelidikan LLM ke tahap yang besar Ini bermakna model ini perlu dikongsi dengan lebih komprehensif dan mendalam, termasuk data latihan. Butiran algoritma, cabaran pelaksanaan dan butiran penilaian prestasi.
Para penyelidik dari Cerebras, Petuum dan MBZUAI bersama-sama mencadangkan LLM360. Ini adalah inisiatif LLM sumber terbuka yang komprehensif yang menyokong menyediakan komuniti dengan semua yang berkaitan dengan latihan LLM, termasuk kod dan data latihan, pusat pemeriksaan model dan hasil perantaraan. Matlamat LLM360 adalah untuk menjadikan proses latihan LLM telus dan boleh dihasilkan semula untuk semua orang, sekali gus menggalakkan pembangunan penyelidikan kecerdasan buatan terbuka dan kolaboratif.

Para penyelidik telah mengeluarkan dua model bahasa berskala besar yang dipralatih dari awal di bawah rangka kerja sumber terbuka LLM360: AMBER dan CRYSTALCODER. AMBER ialah model bahasa Inggeris 7B yang telah dilatih berdasarkan token 1.3T. CRYSTALCODER ialah model bahasa Inggeris 7B dan bahasa kod yang telah dilatih berdasarkan token 1.4T. Dalam artikel ini, penyelidik meringkaskan butiran pembangunan, keputusan penilaian awal, pemerhatian, dan pengalaman serta pengajaran yang dipelajari daripada kedua-dua model ini. Terutama, pada masa dikeluarkan, AMBER dan CRYSTALCODER masing-masing menyelamatkan 360 dan 143 pusat pemeriksaan model semasa latihan.
 Sekarang, mari kita lihat perincian artikel
Sekarang, mari kita lihat perincian artikel
Rangka kerja LLM360
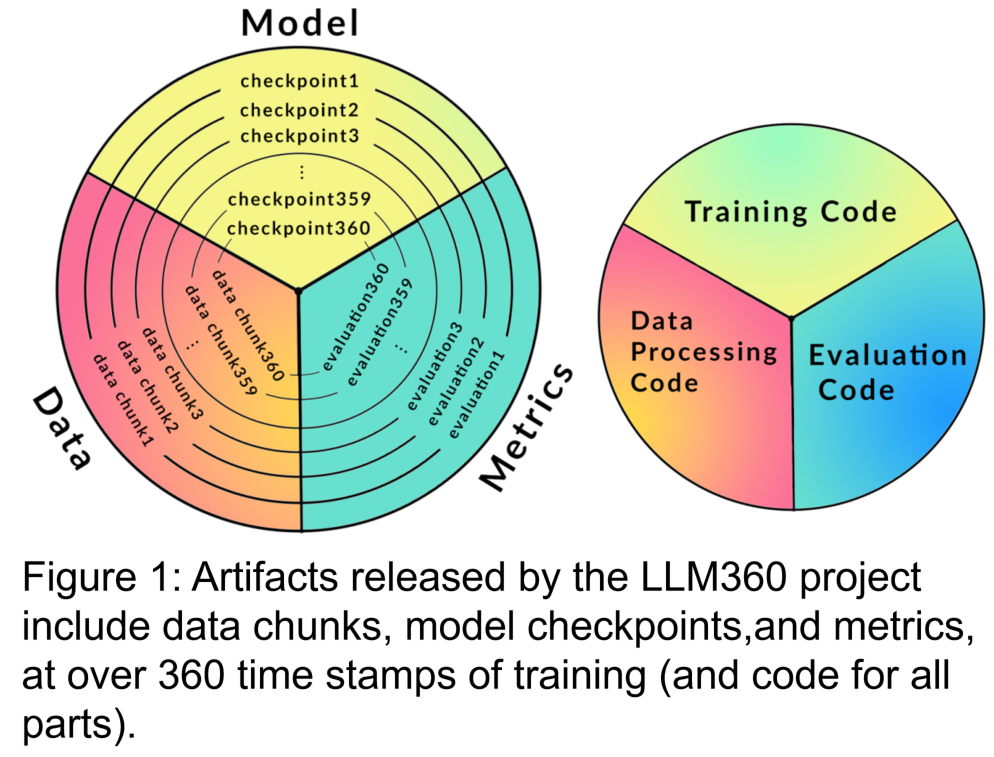
Set data pra-latihan adalah penting untuk prestasi model bahasa besar. Oleh itu, adalah penting untuk memahami set data pra-latihan untuk menilai isu tingkah laku yang berpotensi dan berat sebelah. Selain itu, set data pra-latihan yang tersedia untuk umum membantu meningkatkan kebolehskalaan LLM apabila kemudiannya diperhalusi dan disesuaikan dengan pelbagai domain. Penyelidikan terkini menunjukkan bahawa latihan pada data berulang secara tidak seimbang mengurangkan prestasi akhir model. Oleh itu, mendedahkan data pra-latihan asal membantu mengelak daripada menggunakan data pendua apabila memperhalusi hiliran atau meneruskan pra-latihan dalam domain tertentu. Berdasarkan sebab di atas, LLM360 menyokong pendedahan set data mentah model bahasa besar. Di mana sesuai, butiran tentang penapisan data, pemprosesan dan urutan latihan juga harus didedahkan.
Kandungan yang perlu ditulis semula ialah: 2. Kod latihan, hiperparameter dan konfigurasi
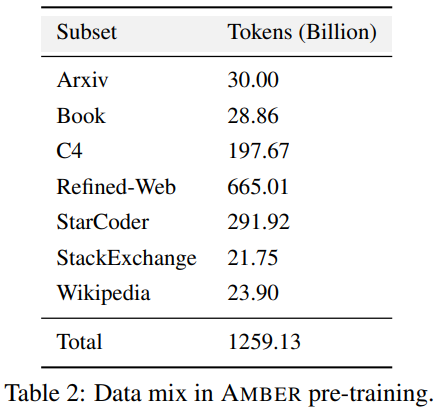
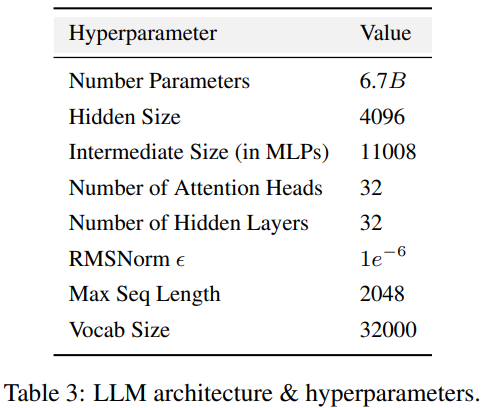
Kod latihan, hiperparameter dan konfigurasi mempunyai kesan yang ketara pada prestasi dan kualiti latihan LLM, tetapi tidak selalu didedahkan kepada umum. Dalam LLM360, penyelidik membuka sumber semua kod latihan, parameter latihan dan konfigurasi sistem rangka kerja pra-latihan. 3. Pusat pemeriksaan model ditulis semula sebagai: 3. Pusat pemeriksaan model Ia juga agak berguna untuk menyimpan pusat pemeriksaan model dengan kerap. Mereka bukan sahaja penting untuk pemulihan kegagalan semasa latihan, tetapi ia juga berguna untuk penyelidikan selepas latihan ini membolehkan penyelidik seterusnya meneruskan latihan model dari beberapa titik permulaan tanpa perlu berlatih dari awal, membantu dalam kebolehulangan. penyelidikan mendalam. 4. Penunjuk prestasi Melatih LLM selalunya mengambil masa berminggu-minggu hingga berbulan-bulan, dan trend evolusi semasa latihan boleh memberikan maklumat yang berharga. Walau bagaimanapun, log terperinci dan metrik perantaraan latihan pada masa ini hanya tersedia kepada mereka yang pernah mengalaminya, yang menghalang penyelidikan komprehensif tentang LLM. Statistik ini selalunya mengandungi cerapan utama yang sukar dikesan. Malah analisis mudah seperti pengiraan varians pada langkah-langkah ini boleh mendedahkan penemuan penting. Sebagai contoh, pasukan penyelidik GLM mencadangkan algoritma pengecutan kecerunan yang berkesan mengendalikan pancang kerugian dan kehilangan NaN dengan menganalisis gelagat spesifikasi kecerunan. AMBER ialah ahli pertama "keluarga" LLM360, dan versi diperhalusinya: AMBERCHAT dan AMBERSAFE turut dikeluarkan. Apa yang perlu ditulis semula: Butiran data dan model Perincian Jadual 2 set data pra-latihan AMBER, yang mengandungi 1.26 penanda T Ini termasuk kaedah prapemprosesan data, format, nisbah pencampuran data, serta butiran seni bina dan hiperparameter pralatihan khusus model AMBER. Untuk maklumat terperinci, sila rujuk halaman utama projek asas kod LLM360 AMBER menggunakan struktur model yang sama seperti LLaMA 7B4 Jadual 3 meringkaskan konfigurasi struktur terperinci LLM . Untuk mencapai tujuan tidak mengubah makna asal, kandungan perlu ditulis semula ke dalam bahasa Cina. Berikut ialah penulisan semula "Eksperimen dan Keputusan":
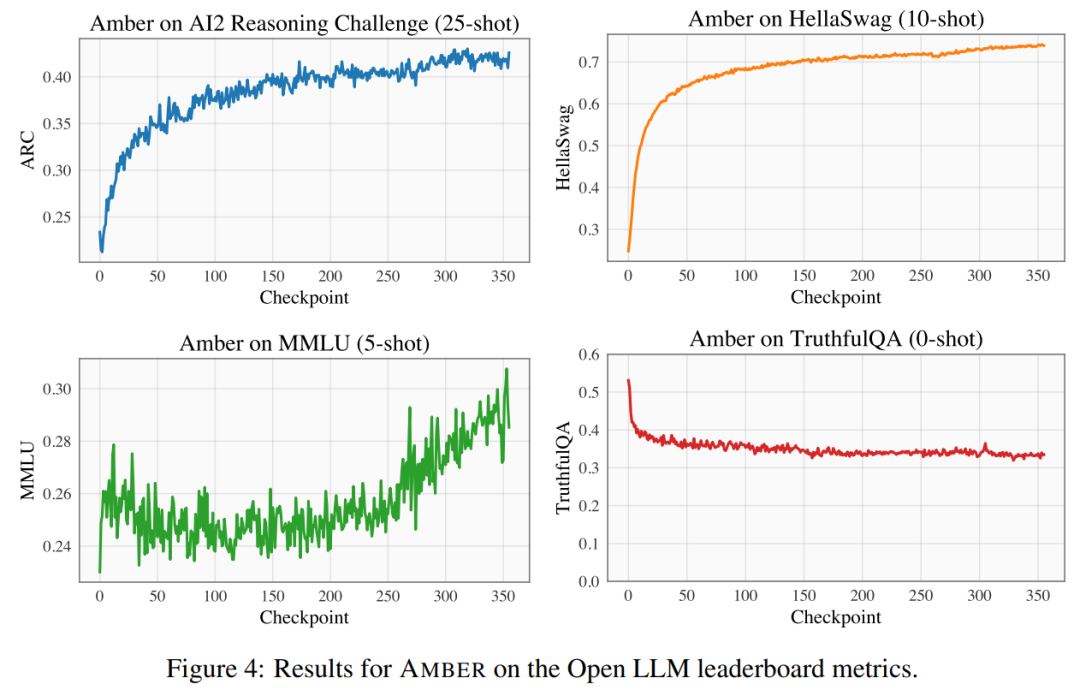
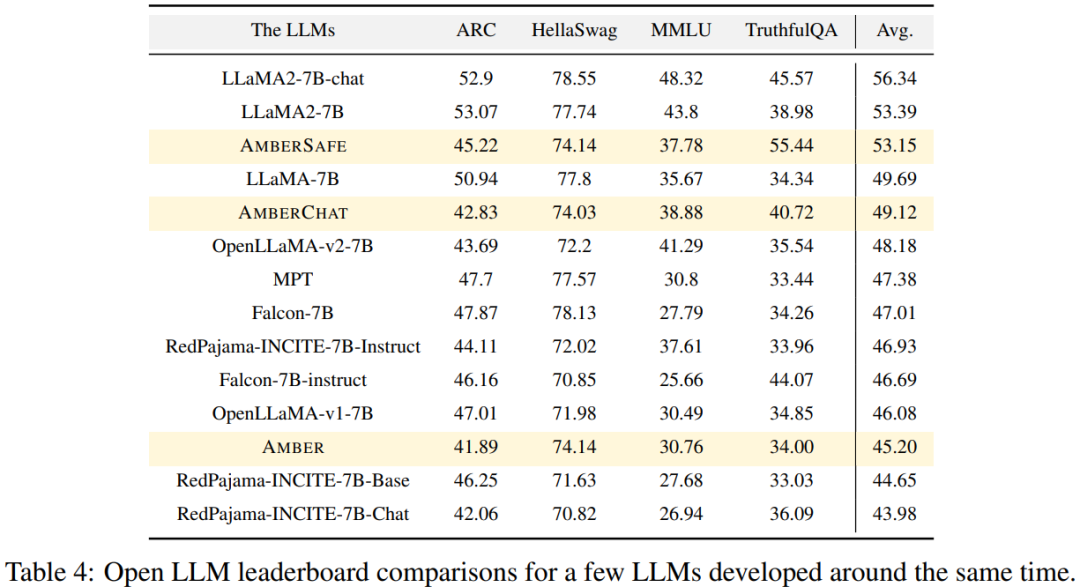
Menjalankan percubaan dan analisis keputusan Para penyelidik menggunakan empat set data penanda aras pada kedudukan LLM Terbuka untuk menilai prestasi AMBER. Seperti yang ditunjukkan dalam Rajah 4, dalam set data HellaSwag dan ARC, skor AMBER meningkat secara beransur-ansur semasa tempoh pra-latihan, manakala dalam set data TruthfulQA, skor berkurangan apabila latihan diteruskan. Dalam set data MMLU, markah AMBER menurun pada peringkat awal pra-latihan, dan kemudian mula meningkat Dalam Jadual 4, penyelidik membandingkan prestasi model AMBER dengan OpenLLaMA, RedPajama-INCITE, Falcon Model MPT yang dilatih dalam tempoh masa yang sama telah dibandingkan. Banyak model diilhamkan oleh LLaMA. Ia boleh didapati bahawa skor AMBER lebih baik pada MMLU tetapi berprestasi lebih teruk pada ARC. Prestasi AMBER agak kukuh berbanding model lain yang serupa. Ahli kedua "keluarga besar" LLM360 ialah CrystalCoder. CrystalCoder ialah model bahasa 7B yang dilatih pada token 1.4 T, mencapai keseimbangan antara pengekodan dan keupayaan bahasa. Tidak seperti kebanyakan LLM kod sebelumnya, CrystalCoder dilatih pada campuran teks dan data kod yang teliti untuk memaksimumkan utiliti dalam kedua-dua domain. Berbanding dengan Kod Llama 2, data kod CrystalCoder diperkenalkan lebih awal dalam proses pra-latihan. Di samping itu, para penyelidik melatih CrystalCoder pada Python dan bahasa pengaturcaraan web untuk meningkatkan kegunaannya sebagai pembantu pengaturcaraan. Seni bina model terbina semula CrystalCoder mengguna pakai seni bina yang hampir sama dengan LLaMA 7B, menambah parameterisasi kemas kini maksimum (muP). Sebagai tambahan kepada parameterisasi khusus ini, penyelidik juga membuat beberapa pengubahsuaian. Di samping itu, penyelidik juga menggunakan LayerNorm dan bukannya RMSNorm kerana seni bina CG-1 menyokong pengiraan LayerNorm yang cekap. Untuk mencapai tujuan tidak mengubah maksud asal, kandungan perlu ditulis semula ke dalam bahasa Cina. Berikut ialah penulisan semula "Eksperimen dan Keputusan":
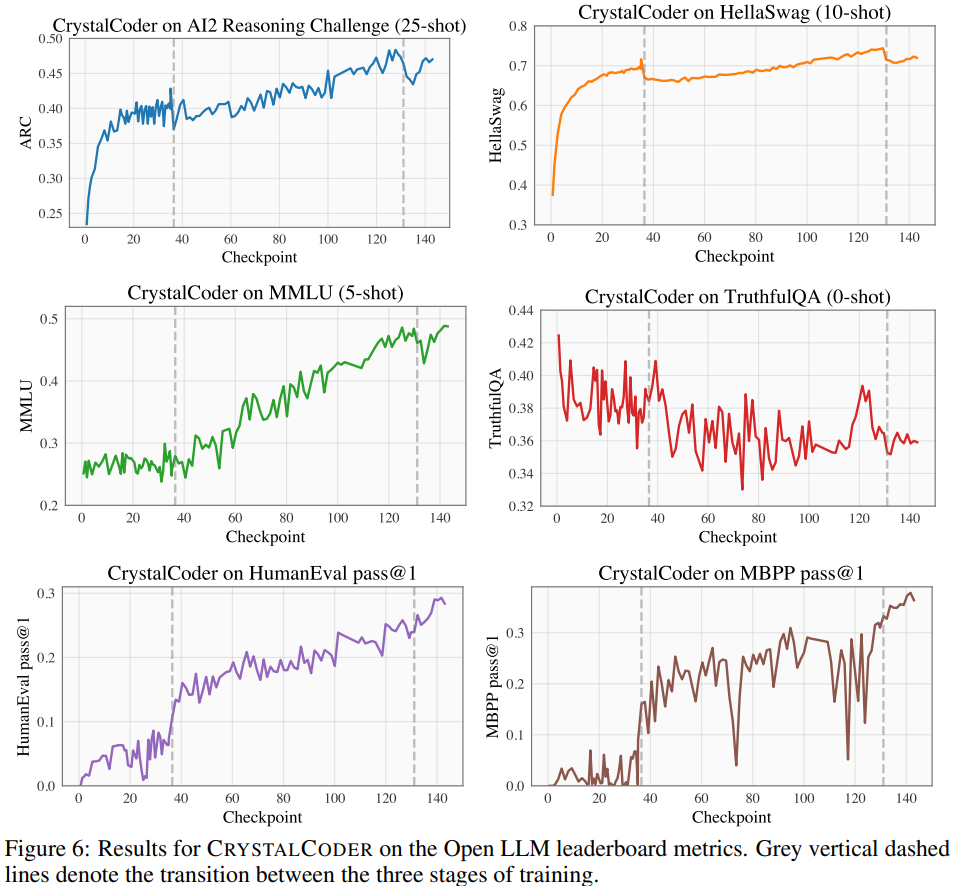
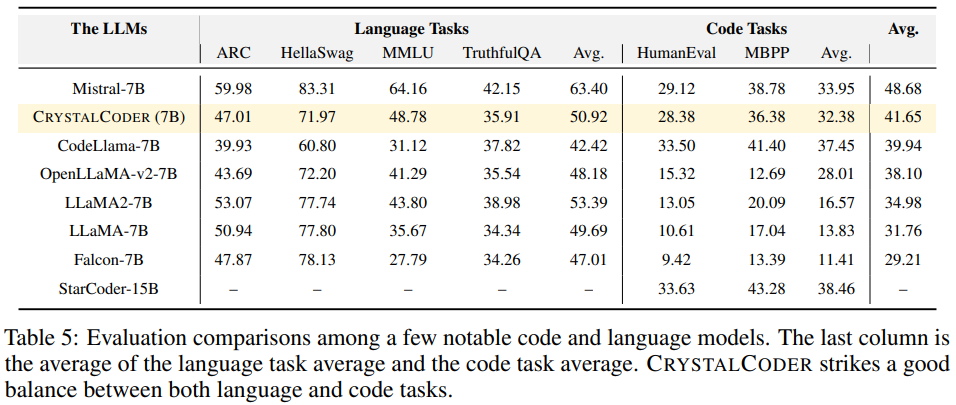
Menjalankan percubaan dan analisis keputusan Pada Papan Pendahulu LLM Terbuka, para penyelidik menjalankan ujian penanda aras pada model, termasuk empat set data penanda aras dan pengekodan set data penanda aras. Seperti yang ditunjukkan dalam Rajah 6 yang merujuk kepada Jadual 5, kita dapat melihat bahawa crystalcoder telah mencapai keseimbangan yang baik antara tugas bahasa dan tugas kod Analysis360 according kepada penyelidikan terdahulu, Dengan menganalisis pusat pemeriksaan perantaraan model, penyelidikan mendalam adalah mungkin. Para penyelidik berharap LLM360 akan menyediakan komuniti rujukan dan sumber penyelidikan yang berguna. Untuk tujuan ini, mereka mengeluarkan versi awal projek ANALYSIS360, sebuah repositori tersusun analisis pelbagai aspek tingkah laku model, termasuk ciri model dan keputusan penilaian hiliran
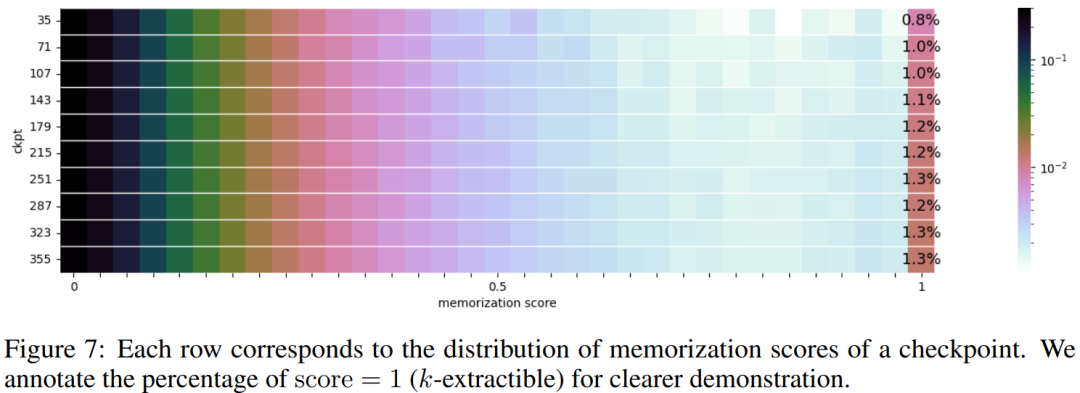
Pengagihan skor memoization sebanyak 10 pusat pemeriksaan terpilih dibentangkan dalam Rajah 7
Ringkasan Pengkaji merumuskan pemerhatian dan beberapa implikasi AMBER dan CRYSTALCODER. Mereka mengatakan pra-latihan adalah tugas intensif pengiraan yang tidak mampu dimiliki oleh banyak makmal akademik atau institusi kecil. Mereka berharap LLM360 dapat memberikan pengetahuan yang menyeluruh dan membolehkan pengguna memahami perkara yang berlaku semasa pra-latihan LLM tanpa perlu melakukannya sendiri Sila semak teks asal untuk butiran lanjutAmber

CRYSTALCODER

 sebagai contoh analisis ke atas siri pusat pemeriksaan model , penyelidik menjalankan kajian awal tentang hafalan dalam LLM. Penyelidikan baru-baru ini telah menunjukkan bahawa LLM mungkin menghafal sebahagian besar data latihan dan data ini boleh diambil dengan gesaan yang sesuai. Penghafalan ini bukan sahaja mempunyai masalah dengan membocorkan data latihan persendirian, tetapi ia juga boleh merendahkan prestasi LLM jika data latihan mengandungi pengulangan atau kekhususan. Para penyelidik telah membuat semua pusat pemeriksaan dan data awam supaya analisis komprehensif hafalan sepanjang fasa latihan dapat dijalankan
sebagai contoh analisis ke atas siri pusat pemeriksaan model , penyelidik menjalankan kajian awal tentang hafalan dalam LLM. Penyelidikan baru-baru ini telah menunjukkan bahawa LLM mungkin menghafal sebahagian besar data latihan dan data ini boleh diambil dengan gesaan yang sesuai. Penghafalan ini bukan sahaja mempunyai masalah dengan membocorkan data latihan persendirian, tetapi ia juga boleh merendahkan prestasi LLM jika data latihan mengandungi pengulangan atau kekhususan. Para penyelidik telah membuat semua pusat pemeriksaan dan data awam supaya analisis komprehensif hafalan sepanjang fasa latihan dapat dijalankan
Berikut adalah kaedah skor hafalan yang digunakan dalam artikel ini, yang bermaksud bahawa selepas gesaan panjang k, panjang seterusnya ialah l Ketepatan token. Untuk tetapan skor memori tertentu, sila rujuk artikel asal.
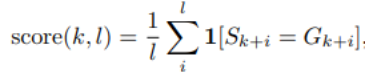
 Rajah 9 menunjukkan perkaitan antara urutan dalam skor hafalan dan nilai k yang boleh diekstrak. Dapat dilihat bahawa terdapat perkaitan yang kuat antara pusat pemeriksaan.
Rajah 9 menunjukkan perkaitan antara urutan dalam skor hafalan dan nilai k yang boleh diekstrak. Dapat dilihat bahawa terdapat perkaitan yang kuat antara pusat pemeriksaan. 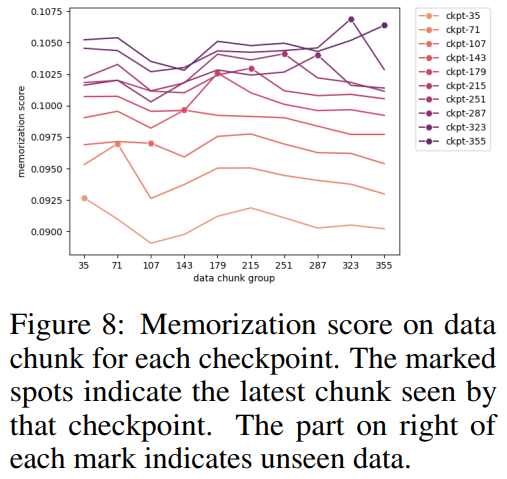
Atas ialah kandungan terperinci Sumber terbuka serba lengkap tanpa jalan buntu, LLM360 pasukan Xingbo menjadikan model besar benar-benar telus. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah kemahiran yang diperlukan untuk bekerja dalam industri PHP?
Apakah kemahiran yang diperlukan untuk bekerja dalam industri PHP?
 BateriMon
BateriMon
 Koleksi kod imej HTML
Koleksi kod imej HTML
 Penggunaan fungsi ppf dalam Python
Penggunaan fungsi ppf dalam Python
 Pengenalan pelan penyelenggaraan pelayan
Pengenalan pelan penyelenggaraan pelayan
 Kaedah pengeluaran laporan Intouch
Kaedah pengeluaran laporan Intouch
 Bagaimana untuk mewujudkan rangkaian kawasan tempatan dalam xp
Bagaimana untuk mewujudkan rangkaian kawasan tempatan dalam xp
 Apakah empat alat analisis data besar?
Apakah empat alat analisis data besar?
 Apakah maklumat peribadi yang akan dilihat oleh rakan rapat Douyin?
Apakah maklumat peribadi yang akan dilihat oleh rakan rapat Douyin?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



