Dalam senario penjanaan video, menggunakan Transformer sebagai tulang belakang denoising model penyebaran telah dibuktikan boleh dilaksanakan oleh penyelidik seperti Li Feifei. Ini boleh dianggap sebagai kejayaan besar Transformer dalam bidang penjanaan video.
Baru-baru ini, penyelidikan penjanaan video telah menerima banyak pujian, malah telah dinilai sebagai "penghujung Hollywood" oleh seorang netizen X. Adakah ia sangat bagus? Jom kita lihat kesannya dahulu: 
Jelas sekali, video ini bukan sahaja hampir tiada artifak, tetapi juga sangat koheren dan penuh dengan butiran Nampaknya walaupun beberapa bingkai ditambahkan pada filem blockbuster, ia tidak akan menjadi tidak konsisten. Pengarang video ini ialah Window Attention Latent Transformer yang dicadangkan oleh penyelidik dari Universiti Stanford, Google dan Georgia Institute of Technology, iaitu Window Attention Latent Transformer, yang dirujuk sebagai W.A.L.T. Kaedah ini berjaya menyepadukan seni bina Transformer ke dalam model penyebaran video terpendam. Profesor Feifei Li dari Universiti Stanford juga merupakan salah seorang pengarang kertas kerja.
- Tapak web projek: https://walt-video-diffusion.github.io/
- Alamat kertas: https://walt-video-diffusion.github.io/assets/W.A.L.T.
Sebelum ini, seni bina Transformer telah mencapai kejayaan besar dalam pelbagai bidang, tetapi bidang pemodelan imej dan video adalah pengecualian Paradigma yang dominan dalam bidang ini ialah model penyebaran.
Dalam bidang penjanaan imej dan video, model penyebaran telah menjadi paradigma utama. Walau bagaimanapun, di antara semua kaedah penyebaran video, rangkaian tulang belakang yang dominan ialah seni bina U-Net yang terdiri daripada satu siri lapisan konvolusi dan perhatian kendiri. U-Net diutamakan kerana keperluan memori bagi mekanisme perhatian penuh dalam Transformer berkembang secara kuadratik dengan panjang jujukan input. Apabila memproses isyarat berdimensi tinggi seperti video, corak pertumbuhan ini menjadikan kos pengiraan sangat tinggi.
Model resapan terpendam (LDM) beroperasi dalam ruang terpendam berdimensi rendah yang diperoleh daripada pengekod automatik, sekali gus mengurangkan keperluan pengiraan. Dalam kes ini, pilihan reka bentuk utama ialah jenis ruang terpendam: pemampatan ruang berbanding pemampatan ruang-masa.
Orang ramai selalunya memilih pemampatan ruang kerana ia membolehkan penggunaan pengekod automatik imej terlatih dan LDM, yang dilatih menggunakan set data teks imej berpasangan yang besar. Walau bagaimanapun, memilih pemampatan spatial meningkatkan kerumitan rangkaian dan menjadikan Transformer sukar digunakan sebagai tulang belakang rangkaian (disebabkan oleh kekangan memori), terutamanya apabila menjana video resolusi tinggi. Sebaliknya, sementara pemampatan spatiotemporal boleh mengurangkan masalah ini, ia tidak sesuai untuk bekerja dengan set data teks imej berpasangan, yang cenderung lebih besar dan lebih pelbagai daripada set data teks video.
W.A.L.T ialah kaedah Transformer untuk model penyebaran video terpendam (LVDM). Kaedah ini terdiri daripada dua peringkat.
Pada peringkat pertama, pengekod automatik digunakan untuk memetakan video dan imej ke dalam ruang terpendam berdimensi rendah bersatu. Ini membolehkan model generatif tunggal dilatih bersama mengenai set data imej dan video dan dengan ketara mengurangkan kos pengiraan untuk menjana video resolusi tinggi.
Untuk fasa kedua, pasukan mereka bentuk blok Transformer baharu untuk model penyebaran video terpendam, yang terdiri daripada lapisan perhatian kendiri yang beroperasi dalam ruang dan masa yang tidak bertindih, terhad kepada tingkap Bergantian antara perhatian. Terdapat dua faedah utama reka bentuk ini: Pertama, ia menggunakan perhatian tetingkap tempatan, yang boleh mengurangkan keperluan pengiraan dengan ketara. Kedua, ia memudahkan latihan bersama, di mana lapisan spatial boleh memproses imej dan bingkai video secara bebas, manakala lapisan spatiotemporal digunakan untuk memodelkan hubungan temporal dalam video.
Walaupun secara konsepnya mudah, kajian ini adalah yang pertama menunjukkan secara eksperimen kualiti penjanaan unggul Transformer dan kecekapan parameter dalam penyebaran video terpendam pada penanda aras awam. Akhir sekali, untuk menunjukkan kebolehskalaan dan kecekapan kaedah baharu, pasukan itu juga bereksperimen dengan tugas penjanaan imej-ke-video fotorealistik yang sukar. Mereka melatih tiga model yang dilantun bersama. Ini termasuk model resapan video terpendam asas dan dua model resapan resolusi super video. Hasilnya ialah video dengan resolusi 512×896 pada 8 bingkai sesaat. Pendekatan ini mencapai skor FVD sifar tangkapan terkini pada penanda aras UCF-101.
Selain itu, model ini boleh digunakan untuk menjana video dengan gerakan kamera 3D yang konsisten.
Dalam bidang pemodelan generatif video, keputusan reka bentuk utama ialah pilihan perwakilan ruang terpendam. Sebaik-baiknya, kami ingin mempunyai perwakilan visual mampat yang dikongsi dan disatukan yang boleh digunakan untuk pemodelan generatif kedua-dua imej dan video. Secara khusus, berdasarkan jujukan video x, matlamatnya ialah untuk mempelajari perwakilan dimensi rendah z yang melakukan pemampatan spatio-temporal pada skala temporal dan spatial tertentu. Untuk mendapatkan perwakilan bersatu video dan imej pegun, adalah perlu untuk mengekod bingkai pertama video secara berasingan daripada bingkai yang tinggal. Ini membolehkan anda menganggap imej pegun seolah-olah ia hanya satu bingkai video. Berdasarkan idea ini, reka bentuk sebenar pasukan menggunakan seni bina penyahkod-pengekod CNN 3D penyebab tokenizer MAGVIT-v2. Selepas peringkat ini, input kepada model menjadi satu kelompok tensor pendam, yang mewakili satu video atau timbunan imej diskret (Rajah 2). Dan perwakilan tersirat di sini adalah bernilai sebenar dan tidak diukur. Belajar menjana imej dan video Patchify (Patchify). Mengikut reka bentuk ViT asal, pasukan itu menjubinkan setiap bingkai tersembunyi secara individu dengan menukarnya menjadi urutan jubin tidak bertindih. Mereka juga menggunakan benam kedudukan yang boleh dipelajari, yang merupakan jumlah benam kedudukan spatial dan temporal. Benam kedudukan ditambah pada unjuran linear jubin. Ambil perhatian bahawa untuk imej, cuma tambahkan benam kedudukan temporal yang sepadan dengan bingkai tersembunyi pertama. Perhatian tingkap. Model Transformer yang terdiri sepenuhnya daripada modul perhatian kendiri global secara pengiraan dan memori mahal, terutamanya untuk tugasan video. Untuk kecekapan dan pemprosesan bersama imej dan video, pasukan mengira perhatian kendiri secara tetingkap berdasarkan dua jenis konfigurasi tidak bertindih: ruang (S) dan ruang-masa (ST), lihat Rajah 2. Perhatian tingkap spatial (SW) memfokuskan pada semua token dalam bingkai tersembunyi. SW memodelkan hubungan spatial dalam imej dan video. Skop perhatian tetingkap spatiotemporal (STW) ialah tetingkap 3D yang memodelkan hubungan temporal antara bingkai tersembunyi video. Akhir sekali, sebagai tambahan kepada pembenaman kedudukan mutlak, mereka juga menggunakan pembenaman kedudukan relatif. Menurut laporan, walaupun reka bentuk ini ringkas, ia sangat cekap dari segi pengiraan dan boleh dilatih bersama mengenai set data imej dan video. Tidak seperti kaedah berdasarkan pengekod auto peringkat bingkai, kaedah baharu tidak menghasilkan artifak berkelip, masalah biasa dengan kaedah yang mengekod dan menyahkod bingkai video secara berasingan. Untuk mencapai penjanaan video yang boleh dikawal, sebagai tambahan kepada langkah masa t sebagai keadaan, model penyebaran juga sering menggunakan maklumat bersyarat tambahan c, seperti label kategori, bahasa semula jadi, bingkai masa lalu atau video resolusi rendah. Dalam rangkaian tulang belakang Transformer yang baru dicadangkan, pasukan menyepadukan tiga jenis mekanisme bersyarat, seperti yang diterangkan di bawah:
Perhatian silang. Selain menggunakan lapisan perhatian kendiri dalam blok Transformer bertingkap, mereka juga menambah lapisan perhatian silang untuk penjanaan bersyarat teks. Apabila melatih model dengan hanya video, lapisan perhatian silang menggunakan perhatian terhad tetingkap yang sama seperti lapisan perhatian diri, yang bermaksud bahawa S/ST akan mempunyai lapisan perhatian silang SW/STW (Rajah 2). Walau bagaimanapun, untuk latihan bersama, hanya lapisan perhatian silang SW digunakan. Untuk perhatian silang, pendekatan pasukan adalah untuk menggabungkan isyarat input (pertanyaan) dan isyarat bersyarat (kunci, nilai).
AdaLN-LoRA. Lapisan normalisasi suai adalah komponen penting dalam banyak model sintesis generatif dan visual. Untuk menggabungkan lapisan normalisasi penyesuaian, pendekatan mudah ialah memasukkan lapisan MLP untuk setiap lapisan i yang mundur pada vektor parameter bersyarat. Bilangan parameter untuk lapisan MLP tambahan ini berkembang secara linear dengan bilangan lapisan dan secara kuadratik dengan dimensi model. Diilhamkan oleh LoRA, penyelidik mencadangkan penyelesaian mudah untuk mengurangkan parameter model: AdaLN-LoRA.
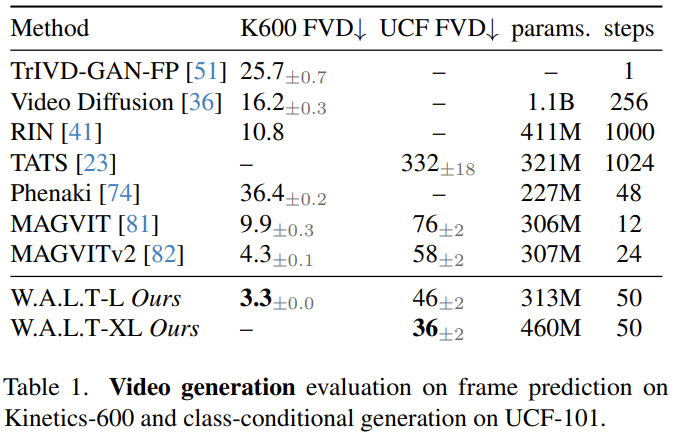
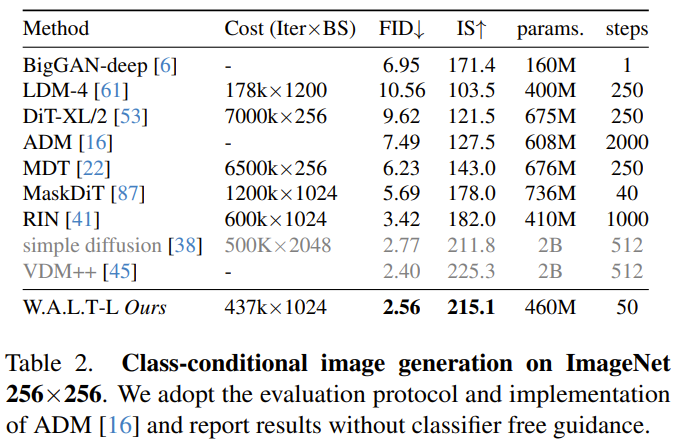
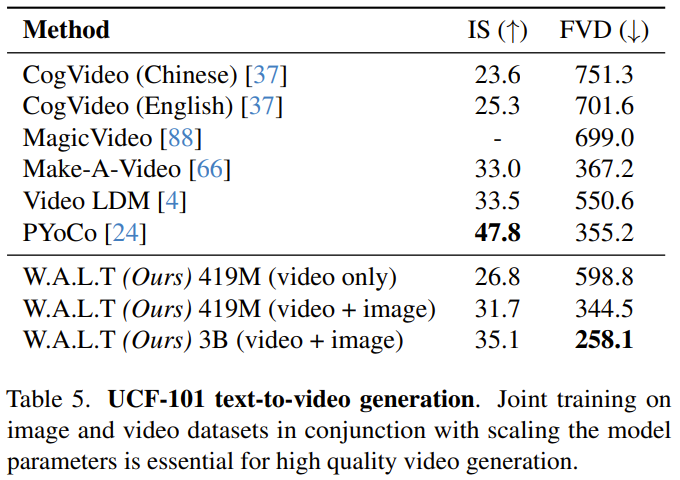
Penyamanan diri. Selain dikondisikan pada input luaran, algoritma penjanaan lelaran juga boleh dikondisikan pada sampel yang dijana semasa inferens. Secara khusus, Chen et al mengubahsuai proses latihan model resapan dalam kertas "Bit analog: Menjana data diskret menggunakan model resapan dengan penyaman diri" supaya model mempunyai kebarangkalian tertentu p_sc untuk menjana sampel, dan kemudian berdasarkan kepada. sampel awal ini , gunakan hantaran hadapan yang lain untuk memperhalusi anggaran ini. Terdapat juga kebarangkalian tertentu bahawa 1-p_sc hanya melengkapkan satu hantaran ke hadapan.Pasukan itu menggabungkan anggaran model ini dengan input di sepanjang dimensi saluran dan mendapati bahawa teknik mudah ini berfungsi dengan baik dalam kombinasi dengan ramalan-v. Untuk menjana video panjang melalui ramalan autoregresif, pasukan itu juga bersama-sama melatih model berkenaan tugas ramalan bingkai. Ini dicapai dengan memberikan model kebarangkalian tertentu p_fp yang dikondisikan pada bingkai lalu semasa proses latihan. Syaratnya ialah sama ada 1 bingkai tersembunyi (penjanaan imej-ke-video) atau 2 bingkai tersembunyi (ramalan video). Keadaan ini disepadukan ke dalam model mengikut dimensi saluran sepanjang input tersirat yang bising. Bootstrapping bebas pengelas standard digunakan semasa inferens, dengan c_fp sebagai isyarat bersyarat. Kos pengiraan menggunakan model tunggal untuk menjana video resolusi tinggi adalah sangat tinggi dan pada asasnya sukar untuk dicapai. Para penyelidik merujuk kepada kertas "Model penyebaran berlatarkan untuk penjanaan imej kesetiaan tinggi" dan menggunakan kaedah lata untuk melata ketiga-tiga model, dan ia beroperasi pada resolusi yang semakin tinggi. di mana model asas menjana video pada resolusi 128×128, yang kemudiannya dipersampel dua kali melalui dua peringkat resolusi super. Input peleraian rendah (video atau imej) mula-mula ditingkatkan secara spatial menggunakan operasi lilitan mendalam-ke-angkasa. Ambil perhatian bahawa tidak seperti latihan (di mana input resolusi rendah kebenaran asas disediakan), inferens bergantung pada perwakilan tersirat yang dijana dalam peringkat sebelumnya. Untuk mengurangkan perbezaan ini dan mengendalikan artifak yang dihasilkan dalam peringkat resolusi rendah dengan lebih mantap dalam peringkat resolusi super, pasukan juga menggunakan peningkatan keadaan bunyi. Penalaan halus nisbah aspek. Untuk memudahkan latihan dan mengeksploitasi lebih banyak sumber data dengan nisbah aspek yang berbeza, mereka menggunakan nisbah aspek segi empat sama dalam peringkat asas. Mereka kemudian memperhalusi model pada subset data untuk menjana video dengan nisbah bidang 9:16 melalui interpolasi pembenaman kedudukan. Para penyelidik menilai kaedah yang baru dicadangkan pada pelbagai tugas: penjanaan imej dan video bersyarat kategori, ramalan bingkai, penjanaan video berasaskan teks. Mereka juga meneroka kesan pilihan reka bentuk yang berbeza melalui kajian ablasi. Penjanaan video: Pada kedua-dua set data UCF-101 dan Kinetics-600, W.A.L.T mengatasi semua kaedah sebelumnya pada metrik FVD., lihat metrik Jadual 1. Penjanaan imej: Jadual 2 membandingkan keputusan W.A.L.T dengan kaedah terbaik semasa yang lain untuk menjana imej resolusi 256×256. Model yang baru dicadangkan mengatasi kaedah sebelumnya dan tidak memerlukan penjadualan khusus, bias aruhan konvolusi, kehilangan resapan yang lebih baik dan bimbingan tanpa pengelas. Walaupun VDM++ mempunyai skor FID yang lebih tinggi sedikit, ia mempunyai lebih banyak parameter model (2B). Untuk memahami sumbangan keputusan reka bentuk yang berbeza, pasukan juga menjalankan kajian ablasi. Jadual 3 membentangkan hasil kajian ablasi dari segi saiz tampalan, perhatian tetingkap, penyaman diri, AdaLN-LoRA, dan pengekod auto. Pasukan melatih bersama keupayaan penjanaan teks-ke-video W.A.L.T pada pasangan teks-imej dan teks-video. Mereka menggunakan set data daripada internet awam dan sumber dalaman yang mengandungi ~970J pasangan imej teks dan ~89J pasangan teks-video. Leraian model asas (3B) ialah 17×128×128, dan dua model peleraian super lata ialah 17×128×224 → 17×256×448 (L, 1.3B, p = 2 ) dan 17× 256×448→ 17×512×896 (L, 419M, p = 2). Mereka juga memperhalusi nisbah bidang dalam peringkat asas untuk menghasilkan video pada resolusi 128×224. Semua hasil penjanaan teks-ke-video menggunakan pendekatan bootstrap tanpa pengelas. Di bawah adalah beberapa contoh video yang dijana, untuk lebih lanjut sila lawati tapak web projek: Teks: Tupai makan burger.
Menilai penjanaan video berasaskan teks secara saintifik kekal sebagai cabaran, sebahagiannya disebabkan oleh kekurangan set data latihan piawai dan penanda aras. Setakat ini, eksperimen dan analisis penyelidik telah memfokuskan pada penanda aras akademik standard, yang menggunakan data latihan yang sama untuk memastikan perbandingan yang saksama. Namun begitu, untuk perbandingan dengan kajian penjanaan teks-ke-video sebelum ini, pasukan melaporkan keputusan pada set data UCF-101 dalam tetapan penilaian sifar tangkapan. Nampak jelas kelebihan W.A.L.T. Sila rujuk kertas asal untuk butiran lanjut. Atas ialah kandungan terperinci Menggunakan Transformer untuk model penyebaran, video yang dijana AI mencapai fotorealisme. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!





























![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



