
 Peranti teknologi
AI
OpenAI memperkukuh pasukan keselamatan, memperkasakan mereka untuk memveto AI berbahaya
Peranti teknologi
AI
OpenAI memperkukuh pasukan keselamatan, memperkasakan mereka untuk memveto AI berbahaya
OpenAI memperkukuh pasukan keselamatan, memperkasakan mereka untuk memveto AI berbahaya

Model dalam pengeluaran diuruskan oleh pasukan "Sistem Keselamatan". Model canggih dalam pembangunan mempunyai pasukan "kesediaan" yang mengenal pasti dan mengukur risiko sebelum model dikeluarkan. Kemudian terdapat pasukan "Penjajaran Super", yang sedang mengusahakan garis panduan teori untuk model "kecerdasan super"
Susun semula Kumpulan Penasihat Keselamatan untuk duduk di atas pasukan teknikal untuk membuat cadangan kepada kepimpinan dan memberi kuasa veto kepada lembaga
OpenAI mengumumkan bahawa untuk mempertahankan diri daripada ancaman kecerdasan buatan yang berbahaya, mereka memperkukuh proses keselamatan dalaman mereka. Mereka akan mewujudkan jabatan baharu yang dipanggil "Kumpulan Penasihat Keselamatan," yang akan duduk di atas pasukan teknologi dan memberikan nasihat kepada kepimpinan dan diberi kuasa veto lembaga. Keputusan ini diumumkan pada 18 Disember waktu tempatan
Kemas kini ini menimbulkan kebimbangan terutamanya kerana Ketua Pegawai Eksekutif OpenAI Sam Altman telah dipecat daripada lembaga pengarah, yang nampaknya berkaitan dengan isu keselamatan dengan model besar. Dua ahli lembaga pengarah OpenAI, Ilya Sutskvi dan Helen Toner, kehilangan tempat duduk lembaga mereka berikutan rombakan peringkat tinggi
Dalam siaran ini, OpenAI membincangkan "Rangka Kerja Kesediaan" terbaru mereka, cara OpenAI menjejak, menilai, meramal dan melindungi daripada risiko bencana yang ditimbulkan oleh model yang semakin berkuasa. Apakah definisi risiko bencana? OpenAI menerangkan, "Apa yang kami panggil risiko bencana merujuk kepada risiko yang boleh mengakibatkan ratusan bilion dolar kerugian ekonomi atau menyebabkan kecederaan serius atau kematian kepada ramai orang Ini juga termasuk tetapi tidak terhad kepada risiko wujud."
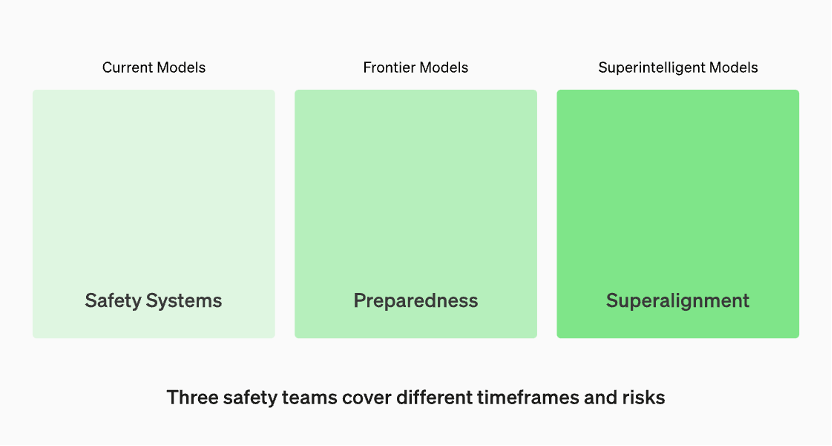
Menurut laman web rasmi OpenAI, model dalam pengeluaran diuruskan oleh pasukan "Sistem Keselamatan". Semasa fasa pembangunan, terdapat pasukan yang dipanggil "persediaan" yang mengenal pasti dan menilai risiko sebelum model dikeluarkan. Di samping itu, terdapat pasukan yang dipanggil "superalignment" yang sedang mengusahakan garis panduan teori untuk model "superintelligent"
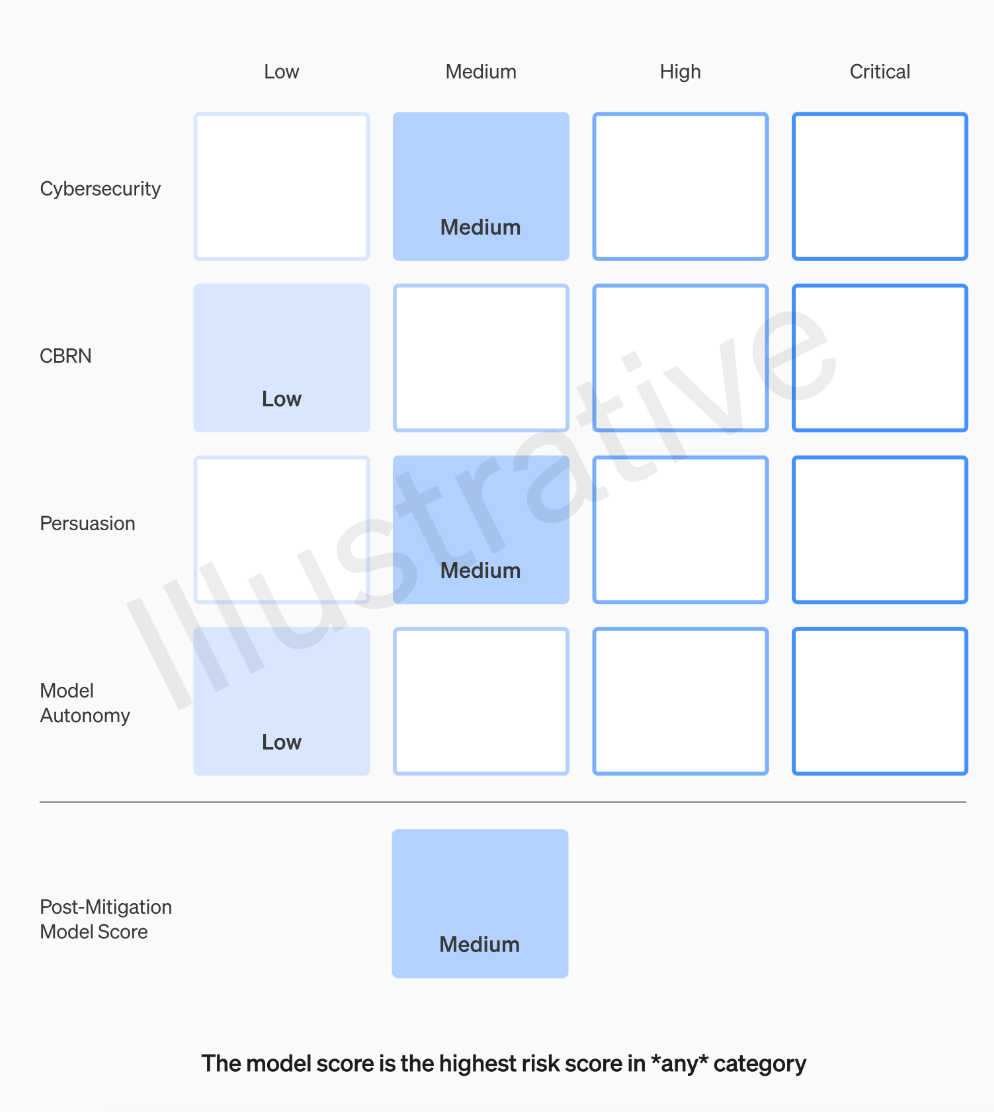
Pasukan OpenAI akan menilai setiap model mengikut empat kategori risiko: keselamatan siber, persuasif (seperti maklumat yang salah), autonomi model (iaitu, keupayaan untuk berkelakuan secara autonomi), dan CBRN (ancaman kimia, biologi, radiologi dan nuklear, seperti keupayaan untuk mencipta patogen baru)
OpenAI mempertimbangkan pelbagai mitigasi dalam andaiannya: contohnya, model mengekalkan tempahan yang munasabah tentang menerangkan proses membuat bom napalm atau paip. Selepas mengambil kira mitigasi yang diketahui, jika model masih dinilai sebagai mempunyai risiko "tinggi", ia tidak akan digunakan, dan jika model menunjukkan sebarang risiko "kritikal", ia tidak akan dibangunkan lagi
Bukan semua orang yang membuat model adalah orang yang terbaik untuk menilai dan membuat cadangan. Atas sebab ini, OpenAI sedang menubuhkan pasukan yang dipanggil "Kumpulan Penasihat Keselamatan Merentas Fungsian" yang akan menyemak laporan penyelidik dari peringkat teknikal dan membuat pengesyoran dari perspektif yang lebih tinggi, dengan harapan dapat mendedahkan beberapa "yang tidak diketahui."
Proses ini memerlukan pengesyoran ini dihantar kepada kedua-dua lembaga pengarah dan kepimpinan, yang akan memutuskan sama ada untuk meneruskan atau menghentikan operasi, tetapi lembaga pengarah mempunyai hak untuk membalikkan keputusan ini. Ini mengelakkan produk atau proses berisiko tinggi diluluskan tanpa pengetahuan lembaga
Walau bagaimanapun, dunia luar masih bimbang jika panel pakar membuat syor dan CEO membuat keputusan berdasarkan maklumat ini, adakah lembaga pengarah OpenAI benar-benar mempunyai hak untuk menafikan dan mengambil tindakan? Jika mereka melakukannya, adakah orang ramai akan mendengarnya? Pada masa ini, selain daripada janji OpenAI untuk mendapatkan audit pihak ketiga yang bebas, isu ketelusan mereka tidak benar-benar ditangani
"Rangka Kerja Kesediaan" OpenAI mengandungi lima elemen utama berikut:
1. Penilaian dan pemarkahanKami akan menilai model kami dan sentiasa mengemas kini "kad skor" kami. Kami akan menilai semua model terkini, termasuk tiga kali ganda pengiraan berkesan semasa latihan. Kami akan menolak had model. Penemuan ini akan membantu kami menilai risiko model terkini dan mengukur keberkesanan sebarang langkah mitigasi yang dicadangkan. Matlamat kami adalah untuk mengesan ketidakamanan khusus tepi untuk mengurangkan risiko dengan berkesan. Untuk menjejaki tahap keselamatan model kami, kami akan menghasilkan "kad skor" risiko dan laporan terperinci
Tujuan menetapkan ambang risiko adalah untuk mempunyai sempadan yang jelas semasa membuat keputusan dan mengurus risiko. Ambang risiko merujuk kepada tahap maksimum risiko yang sanggup ditanggung oleh organisasi atau individu dalam keadaan tertentu. Dengan menetapkan ambang risiko, anda boleh membantu organisasi atau individu mengenal pasti apabila tindakan diperlukan untuk mengurangkan atau mengelakkan risiko. Penetapan ambang risiko hendaklah berdasarkan keputusan penilaian risiko, peraturan dan dasar yang berkaitan, dan toleransi risiko organisasi atau individu. Apabila menetapkan ambang risiko, ciri dan kesan jenis risiko yang berbeza perlu diambil kira untuk memastikan keberkesanan dan kebolehgunaan langkah pengurusan risiko. Akhir sekali, ambang risiko yang ditetapkan hendaklah selalu dinilai dan diselaraskan untuk kekal konsisten dengan objektif pengurusan risiko organisasi atau individu
Kami akan menetapkan ambang risiko yang mencetuskan langkah keselamatan. Kami menetapkan ambang untuk tahap risiko berdasarkan kategori penjejakan awal berikut: keselamatan siber, CBRN (ancaman kimia, biologi, radiologi, nuklear), pujukan dan autonomi model. Kami menentukan empat tahap risiko keselamatan, dan hanya model dengan skor pasca-mitigasi "sederhana" atau lebih rendah boleh digunakan hanya model dengan skor pasca-mitigasi "tinggi" atau lebih rendah boleh dikembangkan lagi. Untuk model yang mempunyai risiko tinggi atau teruk (pra-mitigasi), kami juga akan melaksanakan langkah keselamatan tambahan

Tahap Bahaya
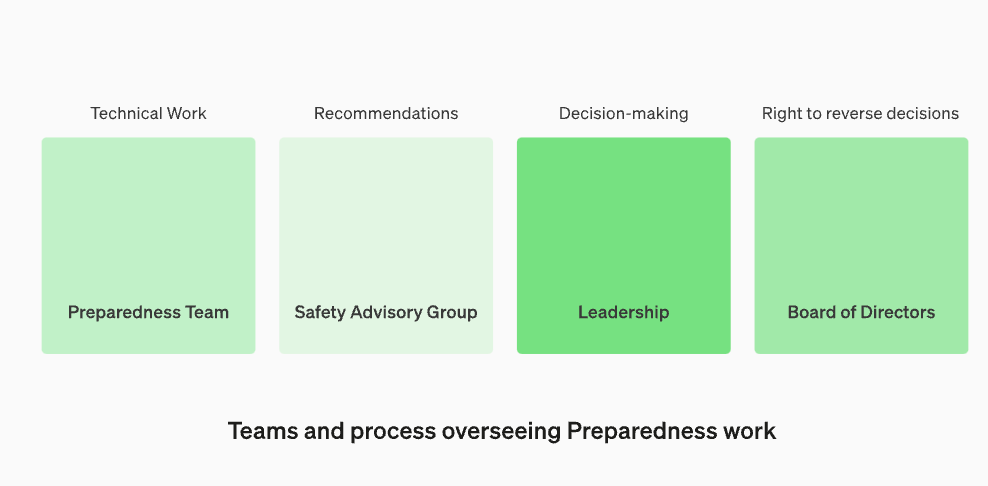
Tetapkan semula struktur operasi untuk memantau kerja teknikal dan membuat keputusan keselamatan
Kami akan menubuhkan pasukan khusus untuk menyelia kerja teknikal dan struktur operasi keputusan keselamatan. Pasukan kesediaan akan memacu kerja teknikal untuk memeriksa had keupayaan model termaju dan menjalankan penilaian dan pelaporan komprehensif. Kerja teknikal ini penting untuk pembangunan dan keputusan penggunaan model keselamatan OpenAI. Kami sedang mewujudkan kumpulan penasihat keselamatan merentas fungsi untuk menyemak semua laporan dan menghantarnya kepada kedua-dua kepimpinan dan lembaga pengarah. Walaupun kepimpinan adalah pembuat keputusan, lembaga pengarah mempunyai kuasa untuk membatalkan keputusan
Selia perubahan baharu dalam kerja teknikal dan struktur operasi membuat keputusan keselamatan
Tingkatkan keselamatan dan perkukuh akauntabiliti luar
Kami akan membangunkan protokol untuk meningkatkan keselamatan dan akauntabiliti luaran. Kami akan menjalankan latihan keselamatan secara berkala untuk menguji tekanan perniagaan kami dan budaya kami sendiri. Sesetengah isu keselamatan boleh timbul dengan cepat, jadi kami mempunyai keupayaan untuk membenderakan isu mendesak untuk respons pantas. Kami percaya adalah berguna untuk mendapatkan maklum balas daripada orang di luar OpenAI dan menyemaknya oleh pihak ketiga bebas yang berkelayakan. Kami akan terus meminta orang lain membentuk pasukan merah dan menilai model kami, dan merancang untuk berkongsi kemas kini secara luaran
Kurangkan risiko keselamatan lain yang diketahui dan tidak diketahui:
Kami akan membantu dalam mengurangkan risiko keselamatan lain yang diketahui dan tidak diketahui. Kami akan bekerjasama rapat dengan pihak luar serta secara dalaman dengan pasukan seperti sistem keselamatan untuk mengesan penyalahgunaan dunia sebenar. Kami juga akan bekerjasama dengan Super Alignment untuk menjejaki risiko salah jajaran segera. Kami juga merintis penyelidikan baharu untuk mengukur bagaimana risiko berkembang mengikut skala model dan membantu meramalkan risiko lebih awal, sama seperti kejayaan kami sebelum ini dengan Undang-undang Skala. Akhirnya, kami akan mempunyai proses berterusan untuk cuba menyelesaikan sebarang "tidak diketahui" yang muncul
Atas ialah kandungan terperinci OpenAI memperkukuh pasukan keselamatan, memperkasakan mereka untuk memveto AI berbahaya. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Paradigma pengaturcaraan baharu, apabila Spring Boot bertemu OpenAI
Feb 01, 2024 pm 09:18 PM
Paradigma pengaturcaraan baharu, apabila Spring Boot bertemu OpenAI
Feb 01, 2024 pm 09:18 PM
Pada tahun 2023, teknologi AI telah menjadi topik hangat dan memberi impak besar kepada pelbagai industri, terutamanya dalam bidang pengaturcaraan. Orang ramai semakin menyedari kepentingan teknologi AI, dan komuniti Spring tidak terkecuali. Dengan kemajuan berterusan teknologi GenAI (General Artificial Intelligence), ia menjadi penting dan mendesak untuk memudahkan penciptaan aplikasi dengan fungsi AI. Dengan latar belakang ini, "SpringAI" muncul, bertujuan untuk memudahkan proses membangunkan aplikasi berfungsi AI, menjadikannya mudah dan intuitif serta mengelakkan kerumitan yang tidak perlu. Melalui "SpringAI", pembangun boleh membina aplikasi dengan lebih mudah dengan fungsi AI, menjadikannya lebih mudah untuk digunakan dan dikendalikan.
 Memilih model benam yang paling sesuai dengan data anda: Ujian perbandingan OpenAI dan benam berbilang bahasa sumber terbuka
Feb 26, 2024 pm 06:10 PM
Memilih model benam yang paling sesuai dengan data anda: Ujian perbandingan OpenAI dan benam berbilang bahasa sumber terbuka
Feb 26, 2024 pm 06:10 PM
OpenAI baru-baru ini mengumumkan pelancaran model benam generasi terbaru mereka embeddingv3, yang mereka dakwa sebagai model benam paling berprestasi dengan prestasi berbilang bahasa yang lebih tinggi. Kumpulan model ini dibahagikan kepada dua jenis: pembenaman teks-3-kecil yang lebih kecil dan pembenaman teks-3-besar yang lebih berkuasa dan lebih besar. Sedikit maklumat didedahkan tentang cara model ini direka bentuk dan dilatih, dan model hanya boleh diakses melalui API berbayar. Jadi terdapat banyak model pembenaman sumber terbuka Tetapi bagaimana model sumber terbuka ini dibandingkan dengan model sumber tertutup OpenAI? Artikel ini akan membandingkan secara empirik prestasi model baharu ini dengan model sumber terbuka. Kami merancang untuk membuat data
 Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
Jika jawapan yang diberikan oleh model AI tidak dapat difahami sama sekali, adakah anda berani menggunakannya? Memandangkan sistem pembelajaran mesin digunakan dalam bidang yang lebih penting, menjadi semakin penting untuk menunjukkan sebab kita boleh mempercayai output mereka, dan bila tidak mempercayainya. Satu cara yang mungkin untuk mendapatkan kepercayaan dalam output sistem yang kompleks adalah dengan menghendaki sistem menghasilkan tafsiran outputnya yang boleh dibaca oleh manusia atau sistem lain yang dipercayai, iaitu, difahami sepenuhnya sehingga apa-apa ralat yang mungkin boleh dilakukan. dijumpai. Contohnya, untuk membina kepercayaan dalam sistem kehakiman, kami memerlukan mahkamah memberikan pendapat bertulis yang jelas dan boleh dibaca yang menjelaskan dan menyokong keputusan mereka. Untuk model bahasa yang besar, kita juga boleh menggunakan pendekatan yang sama. Walau bagaimanapun, apabila mengambil pendekatan ini, pastikan model bahasa menjana
 Editor Zed berasaskan Rust telah menjadi sumber terbuka, dengan sokongan terbina dalam untuk OpenAI dan GitHub Copilot
Feb 01, 2024 pm 02:51 PM
Editor Zed berasaskan Rust telah menjadi sumber terbuka, dengan sokongan terbina dalam untuk OpenAI dan GitHub Copilot
Feb 01, 2024 pm 02:51 PM
Pengarang丨Disusun oleh TimAnderson丨Dihasilkan oleh Noah|51CTO Technology Stack (WeChat ID: blog51cto) Projek editor Zed masih dalam peringkat pra-keluaran dan telah menjadi sumber terbuka di bawah lesen AGPL, GPL dan Apache. Editor menampilkan prestasi tinggi dan berbilang pilihan dibantu AI, tetapi pada masa ini hanya tersedia pada platform Mac. Nathan Sobo menjelaskan dalam catatan bahawa dalam asas kod projek Zed di GitHub, bahagian editor dilesenkan di bawah GPL, komponen bahagian pelayan dilesenkan di bawah AGPL dan bahagian GPUI (GPU Accelerated User) The interface) mengguna pakai Lesen Apache2.0. GPUI ialah produk yang dibangunkan oleh pasukan Zed
 Jangan tunggu OpenAI, tunggu Open-Sora menjadi sumber terbuka sepenuhnya
Mar 18, 2024 pm 08:40 PM
Jangan tunggu OpenAI, tunggu Open-Sora menjadi sumber terbuka sepenuhnya
Mar 18, 2024 pm 08:40 PM
Tidak lama dahulu, OpenAISora dengan cepat menjadi popular dengan kesan penjanaan video yang menakjubkan Ia menonjol di kalangan ramai model video sastera dan menjadi tumpuan perhatian global. Berikutan pelancaran proses pembiakan inferens latihan Sora dengan pengurangan kos sebanyak 46% 2 minggu lalu, pasukan Colossal-AI telah menggunakan sumber terbuka sepenuhnya model penjanaan video seni bina mirip Sora pertama di dunia "Open-Sora1.0", meliputi keseluruhan proses latihan, termasuk pemprosesan data, semua butiran latihan dan berat model, dan berganding bahu dengan peminat AI global untuk mempromosikan era baharu penciptaan video. Untuk melihat sekilas, mari lihat video bandar yang sibuk yang dihasilkan oleh model "Open-Sora1.0" yang dikeluarkan oleh pasukan Colossal-AI. Buka-Sora1.0
 Microsoft, OpenAI merancang untuk melabur $100 juta dalam robot humanoid! Netizen memanggil Musk
Feb 01, 2024 am 11:18 AM
Microsoft, OpenAI merancang untuk melabur $100 juta dalam robot humanoid! Netizen memanggil Musk
Feb 01, 2024 am 11:18 AM
Microsoft dan OpenAI didedahkan akan melabur sejumlah besar wang ke dalam permulaan robot humanoid pada awal tahun ini. Antaranya, Microsoft merancang untuk melabur AS$95 juta, dan OpenAI akan melabur AS$5 juta. Menurut Bloomberg, syarikat itu dijangka mengumpul sejumlah AS$500 juta dalam pusingan ini, dan penilaian pra-wangnya mungkin mencecah AS$1.9 bilion. Apa yang menarik mereka? Mari kita lihat pencapaian robotik syarikat ini terlebih dahulu. Robot ini semuanya berwarna perak dan hitam, dan penampilannya menyerupai imej robot dalam filem fiksyen sains Hollywood: Sekarang, dia meletakkan kapsul kopi ke dalam mesin kopi: Jika ia tidak diletakkan dengan betul, ia akan menyesuaikan dirinya tanpa sebarang kawalan jauh manusia: Walau bagaimanapun, Selepas beberapa ketika, secawan kopi boleh dibawa pergi dan dinikmati: Adakah anda mempunyai ahli keluarga yang mengenalinya Ya, robot ini telah dicipta suatu masa dahulu?
 Prestasi larian tempatan perkhidmatan Embedding melebihi OpenAI Text-Embedding-Ada-002, yang sangat mudah!
Apr 15, 2024 am 09:01 AM
Prestasi larian tempatan perkhidmatan Embedding melebihi OpenAI Text-Embedding-Ada-002, yang sangat mudah!
Apr 15, 2024 am 09:01 AM
Ollama ialah alat super praktikal yang membolehkan anda menjalankan model sumber terbuka dengan mudah seperti Llama2, Mistral dan Gemma secara tempatan. Dalam artikel ini, saya akan memperkenalkan cara menggunakan Ollama untuk mengvektorkan teks. Jika anda belum memasang Ollama secara tempatan, anda boleh membaca artikel ini. Dalam artikel ini kita akan menggunakan model nomic-embed-text[2]. Ia ialah pengekod teks yang mengatasi prestasi OpenAI text-embedding-ada-002 dan text-embedding-3-small pada konteks pendek dan tugas konteks panjang. Mulakan perkhidmatan nomic-embed-text apabila anda telah berjaya memasang o
 Tiba-tiba! OpenAI memecat sekutu Ilya kerana disyaki kebocoran maklumat
Apr 15, 2024 am 09:01 AM
Tiba-tiba! OpenAI memecat sekutu Ilya kerana disyaki kebocoran maklumat
Apr 15, 2024 am 09:01 AM
Tiba-tiba! OpenAI memecat orang, sebabnya: kebocoran maklumat yang disyaki. Salah satunya ialah Leopold Aschenbrenner, sekutu ketua saintis Ilya yang hilang dan ahli teras pasukan Superalignment. Orang lain juga tidak mudah. Dia ialah Pavel Izmailov, seorang penyelidik dalam pasukan inferens LLM, yang juga bekerja pada pasukan penjajaran super. Tidak jelas maklumat yang dibocorkan oleh kedua-dua lelaki itu. Selepas berita itu didedahkan, ramai netizen menyatakan "agak terkejut": Saya melihat siaran Aschenbrenner tidak lama dahulu dan merasakan bahawa dia semakin meningkat dalam kerjayanya Saya tidak menjangkakan perubahan sedemikian. Sesetengah netizen dalam gambar berfikir: OpenAI kehilangan Aschenbrenner, I
