
 Peranti teknologi
AI
Pengurangan dimensi model pengubah berkurangan dan prestasi LLM kekal tidak berubah apabila lebih daripada 90% komponen lapisan tertentu dialih keluar.
Peranti teknologi
AI
Pengurangan dimensi model pengubah berkurangan dan prestasi LLM kekal tidak berubah apabila lebih daripada 90% komponen lapisan tertentu dialih keluar.
Pengurangan dimensi model pengubah berkurangan dan prestasi LLM kekal tidak berubah apabila lebih daripada 90% komponen lapisan tertentu dialih keluar.

Dalam era model berskala besar, Transformer sahaja menyokong keseluruhan bidang penyelidikan saintifik. Sejak dikeluarkan, model bahasa berasaskan Transformer telah menunjukkan prestasi cemerlang dalam pelbagai tugas Seni bina Transformer yang mendasari telah menjadi terkini dalam pemodelan dan inferens bahasa semula jadi, dan juga telah menunjukkan janji dalam bidang seperti penglihatan komputer. dan pembelajaran pengukuhan. Ia menunjukkan prospek yang kukuh
Senibina Transformer semasa sangat besar dan biasanya memerlukan banyak sumber pengkomputeran untuk latihan dan inferens
Ini adalah disengajakan, kerana Transformer yang dilatih dengan lebih banyak parameter atau data adalah jelas. lebih besar daripada Model lain lebih berkebolehan. Walau bagaimanapun, badan kerja yang semakin meningkat menunjukkan bahawa model berasaskan Transformer serta rangkaian saraf tidak memerlukan semua parameter yang dipasang untuk mengekalkan hipotesis yang dipelajari.
Secara amnya, pengiraan berlebihan secara besar-besaran nampaknya membantu semasa melatih model, tetapi model ini boleh dipangkas sebelum inferens menunjukkan bahawa rangkaian saraf selalunya boleh mengeluarkan lebih daripada 90% berat tanpa menunjukkan prestasi yang baik merosot. Fenomena ini telah mendorong penyelidik untuk beralih kepada strategi pemangkasan yang membantu inferens model
Penyelidik dari MIT dan Microsoft melaporkan dalam makalah bertajuk "The Truth Is Out There: Improving Improvement through Layer Selective Ranking Reduction Satu penemuan yang mengejutkan telah dibuat dalam kertas kerja "Keupayaan Penaakulan Model Bahasa". Mereka mendapati pemangkasan halus pada lapisan tertentu model Transformer boleh meningkatkan prestasi model dengan ketara pada tugasan tertentu

- Alamat kertas: https://arxiv.org/pdf/2312.13558.pdf
laman utama: https://pratyushasharma.github.io/laser/
Intervensi mudah ini dipanggil LASER (Pengurangan Kedudukan PILIHAN LAPISAN) dalam kajian. Ia meningkatkan prestasi LLM dengan ketara dengan mengurangkan secara terpilih komponen tertib tinggi matriks berat pembelajaran lapisan tertentu dalam model Transformer melalui penguraian nilai tunggal. Operasi ini boleh dilakukan selepas latihan model selesai dan tidak memerlukan parameter atau data tambahan
Semasa operasi, pengurangan pemberat dilakukan dengan menggunakan matriks dan lapisan berat khusus model. Kajian itu juga mendapati bahawa banyak matriks yang serupa dapat mengurangkan berat dengan ketara, dan secara amnya tiada kemerosotan prestasi diperhatikan sehingga lebih daripada 90% komponen dikeluarkan
Kajian itu juga mendapati bahawa mengurangkan faktor ini boleh meningkatkan ketepatan dengan ketara. Menariknya, penemuan ini bukan sahaja terpakai kepada bahasa semula jadi, tetapi juga meningkatkan prestasi untuk pembelajaran pengukuhan
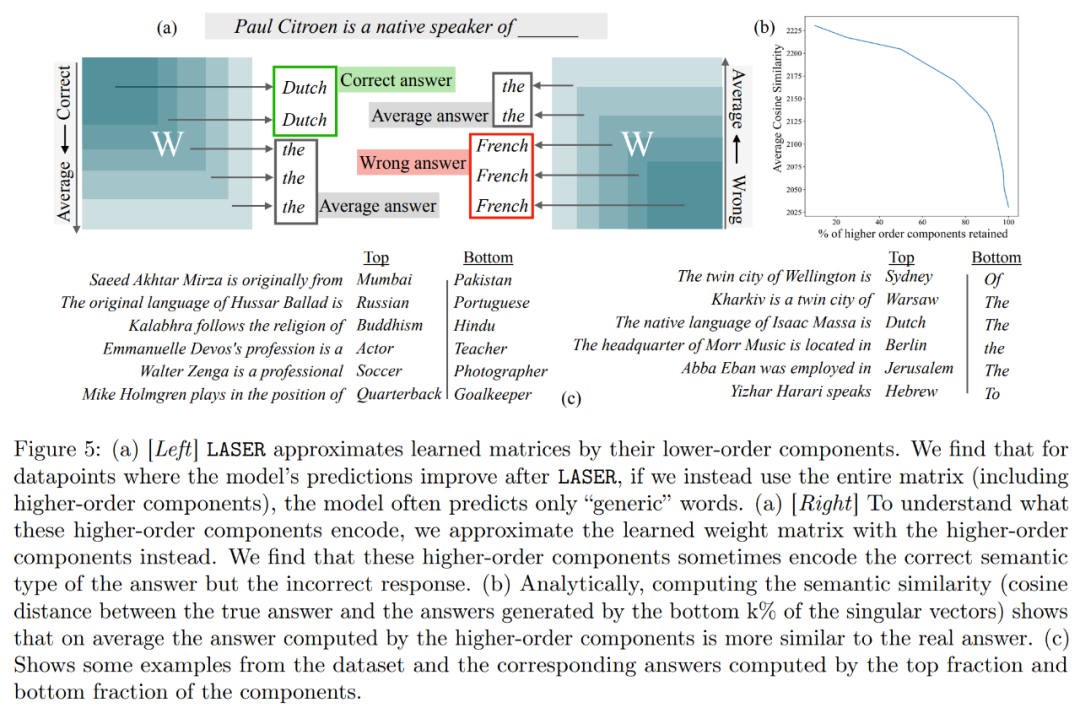
Selain itu, kajian ini cuba menyimpulkan apa yang disimpan dalam komponen peringkat lebih tinggi untuk meningkatkan prestasi melalui pemadaman. Kajian mendapati bahawa selepas menggunakan LASER untuk menjawab soalan, model asal terutamanya bertindak balas menggunakan perkataan frekuensi tinggi (seperti "the", "of", dll.). Kata-kata ini tidak sepadan dengan jenis semantik jawapan yang betul, yang bermaksud bahawa tanpa campur tangan, komponen ini akan menyebabkan model menghasilkan beberapa perkataan frekuensi tinggi yang tidak relevan
Namun, selepas melakukan tahap penurunan pangkat tertentu, The jawapan model boleh diubah menjadi yang betul.
Untuk memahami perkara ini, kajian itu turut meneroka perkara yang dikodkan oleh komponen selebihnya secara individu, dan mereka menganggarkan matriks berat menggunakan hanya vektor tunggal peringkat tinggi mereka. Didapati bahawa komponen ini menerangkan respons yang berbeza atau perkataan frekuensi tinggi biasa dalam kategori semantik yang sama dengan jawapan yang betul.
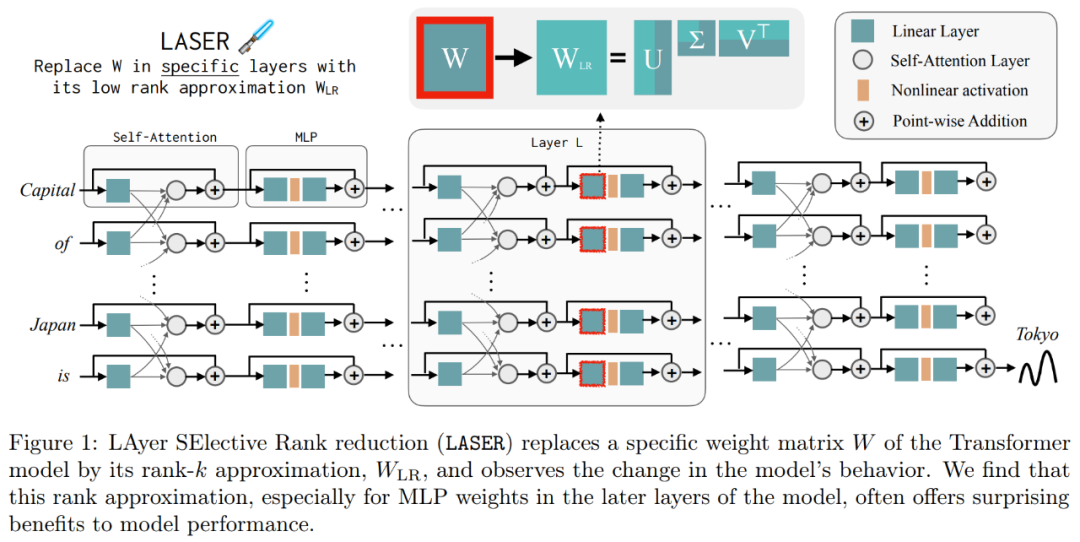
Hasil ini mencadangkan bahawa apabila komponen tertib tinggi yang bising digabungkan dengan komponen tertib rendah, respons bercanggah mereka menghasilkan jawapan purata, yang mungkin salah. Rajah 1 memberikan gambaran visual seni bina Transformer dan prosedur yang diikuti oleh LASER. Di sini, matriks berat lapisan tertentu perceptron berbilang lapisan (MLP) digantikan dengan anggaran peringkat rendahnya.
Laser Gambaran Keseluruhan 🎜🎜🎜🎜Pengkaji memperkenalkan campur tangan LASER secara terperinci. Campur tangan LASER satu langkah ditakrifkan oleh tiga parameter (τ, ℓ dan ρ). Parameter ini bersama-sama menerangkan matriks yang akan digantikan dengan penghampiran peringkat rendah dan darjah penghampiran. Pengkaji mengelaskan matriks yang akan diintervensi mengikut jenis parameter🎜🎜🎜🎜Pengkaji memfokuskan pada matriks W = {W_q, W_k, W_v, W_o, U_in, U_out}, yang terdiri daripada multilayer perceptron (MLP) dan attention Matrix komposisi dalam lapisan daya. Bilangan lapisan mewakili tahap campur tangan penyelidik, di mana indeks lapisan pertama ialah 0. Sebagai contoh, Llama-2 mempunyai 32 tahap, jadi ia dinyatakan sebagai ℓ ∈ {0, 1, 2,・・・31}🎜🎜
Akhirnya, ρ ∈ [0, 1) menerangkan bahagian kedudukan maksimum yang harus dikekalkan apabila membuat anggaran peringkat rendah. Sebagai contoh, andaikan 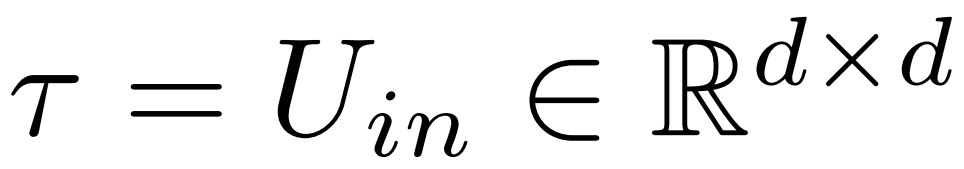 , pangkat maksimum matriks ialah d. Para penyelidik menggantikannya dengan anggaran ⌊ρ・d⌋-.
, pangkat maksimum matriks ialah d. Para penyelidik menggantikannya dengan anggaran ⌊ρ・d⌋-.
Perkara berikut diperlukan Dalam Rajah 1 di bawah, contoh LASER ditunjukkan. Simbol τ = U_in dan ℓ = L dalam rajah menunjukkan bahawa matriks berat lapisan pertama MLP dikemas kini dalam blok Transformer lapisan Lth. Terdapat juga parameter untuk mengawal nilai k dalam anggaran pangkat-k
LASER boleh mengehadkan aliran maklumat tertentu dalam rangkaian dan secara tidak dijangka menghasilkan faedah prestasi yang ketara. Intervensi ini juga boleh digabungkan dengan mudah, seperti menggunakan set intervensi dalam sebarang susunan 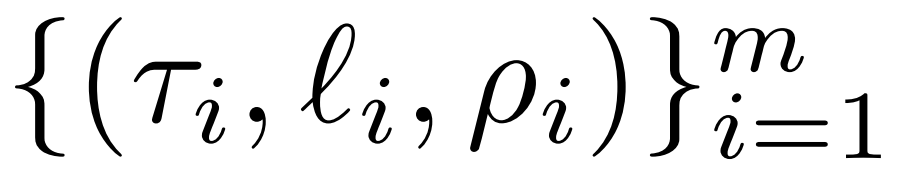 .
.
Kaedah LASER hanyalah carian mudah untuk jenis intervensi ini, diubah suai untuk membawa manfaat maksimum. Walau bagaimanapun, terdapat banyak cara lain untuk menggabungkan campur tangan ini, yang merupakan hala tuju untuk kerja masa hadapan.
Hasil eksperimen
Dalam bahagian eksperimen, penyelidik menggunakan model GPT-J yang telah dilatih pada set data PILE, yang mempunyai 27 lapisan dan 6 bilion parameter. Tingkah laku model kemudian dinilai pada set data CounterFact, yang mengandungi sampel tiga kali ganda (topik, hubungan dan jawapan), dengan tiga gesaan parafrasa disediakan untuk setiap soalan.
Mula-mula, kami menganalisis model GPT-J pada set data CounterFact. Rajah 2 menunjukkan kesan ke atas kehilangan klasifikasi set data selepas menggunakan jumlah pengurangan pangkat yang berbeza untuk setiap matriks dalam seni bina Transformer. Setiap lapisan Transformer terdiri daripada MLP kecil dua lapisan, dengan matriks input dan output ditunjukkan secara berasingan. Warna yang berbeza mewakili peratusan berbeza bagi komponen yang dialih keluar
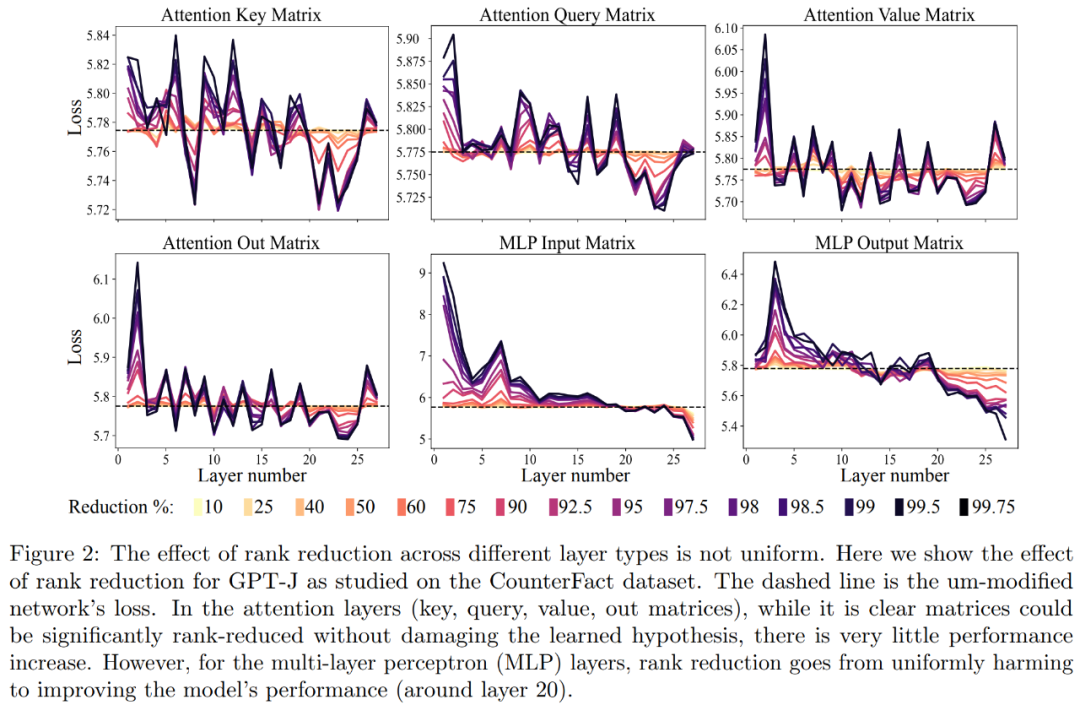
Mengenai ketepatan dan keteguhan tafsiran yang lebih baik, seperti yang ditunjukkan dalam Rajah 2 di atas dan Jadual 1 di bawah, penyelidik mendapati bahawa apabila melakukan pengurangan pangkat pada satu lapisan, Fakta fakta ketepatan model GPT-J pada dataset CounterFact meningkat daripada 13.1% kepada 24.0%. Adalah penting untuk ambil perhatian bahawa penambahbaikan ini hanya hasil daripada penurunan pangkat dan tidak melibatkan sebarang latihan lanjut atau penalaan halus model.
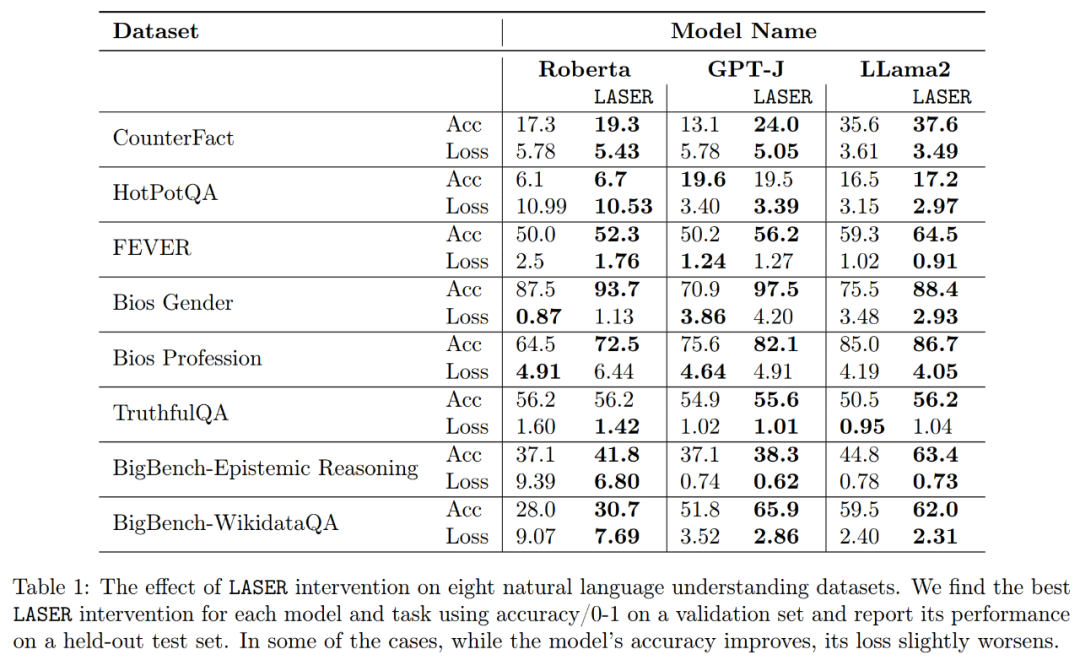
Apakah fakta yang akan dipulihkan apabila melakukan pemulihan peringkat bawah? Para penyelidik mendapati bahawa fakta yang diperoleh melalui pemulihan pengurangan pangkat mungkin kelihatan sangat jarang dalam set data, seperti yang ditunjukkan dalam Rajah 3
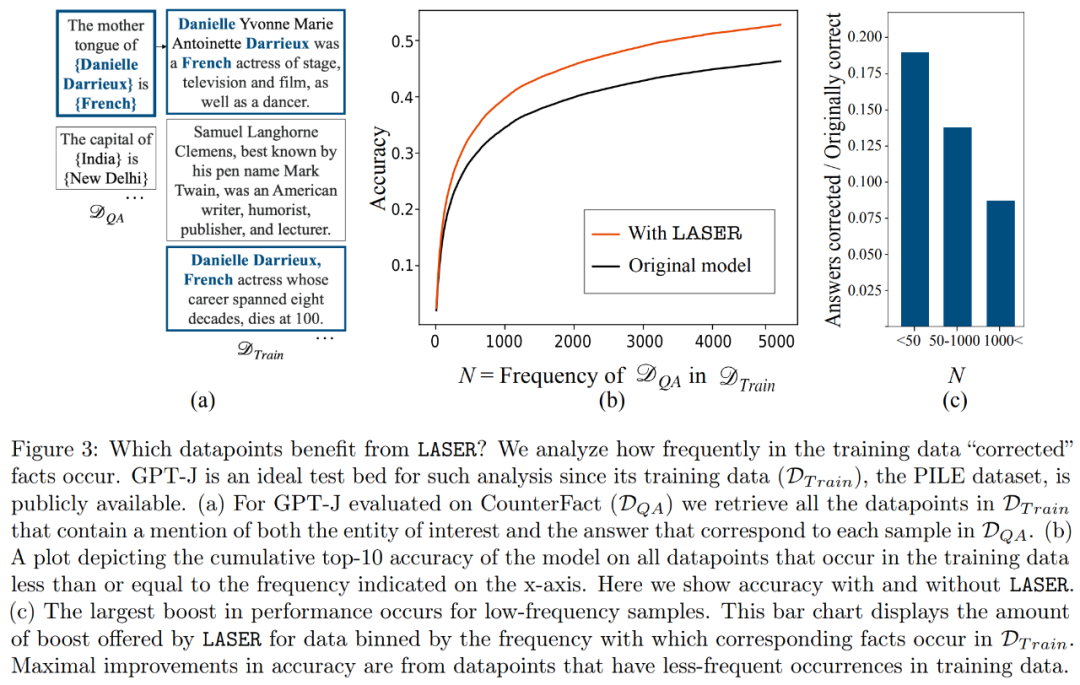
Apakah yang disimpan oleh komponen peringkat tinggi? Para penyelidik menggunakan komponen tertib tinggi untuk menganggarkan matriks berat akhir (bukannya menggunakan komponen tertib rendah seperti LASER), seperti yang ditunjukkan dalam Rajah 5 (a) di bawah. Mereka mengukur persamaan kosinus purata bagi jawapan benar berbanding dengan jawapan yang diramalkan apabila menghampiri matriks menggunakan nombor yang berbeza bagi komponen tertib tinggi, seperti yang ditunjukkan dalam Rajah 5(b) di bawah.
Penyelidik akhirnya menilai kebolehgeneralisasian tiga LLM berbeza yang mereka temui pada tugas pemahaman berbilang bahasa. Bagi setiap tugasan, mereka menilai prestasi model menggunakan tiga metrik: ketepatan penjanaan, ketepatan klasifikasi dan kehilangan. Mengikut keputusan dalam Jadual 1, walaupun pangkat matriks sangat berkurangan, ia tidak akan menyebabkan ketepatan model menurun, sebaliknya boleh meningkatkan prestasi model
Atas ialah kandungan terperinci Pengurangan dimensi model pengubah berkurangan dan prestasi LLM kekal tidak berubah apabila lebih daripada 90% komponen lapisan tertentu dialih keluar.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Cecair memproses 7 juta rekod dan membuat peta interaktif dengan teknologi geospatial. Artikel ini meneroka cara memproses lebih dari 7 juta rekod menggunakan Laravel dan MySQL dan mengubahnya menjadi visualisasi peta interaktif. Keperluan Projek Cabaran Awal: Ekstrak Wawasan berharga menggunakan 7 juta rekod dalam pangkalan data MySQL. Ramai orang mula -mula mempertimbangkan bahasa pengaturcaraan, tetapi mengabaikan pangkalan data itu sendiri: Bolehkah ia memenuhi keperluan? Adakah penghijrahan data atau pelarasan struktur diperlukan? Bolehkah MySQL menahan beban data yang besar? Analisis awal: Penapis utama dan sifat perlu dikenalpasti. Selepas analisis, didapati bahawa hanya beberapa atribut yang berkaitan dengan penyelesaiannya. Kami mengesahkan kemungkinan penapis dan menetapkan beberapa sekatan untuk mengoptimumkan carian. Carian Peta Berdasarkan Bandar
 Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Terdapat banyak sebab mengapa permulaan MySQL gagal, dan ia boleh didiagnosis dengan memeriksa log ralat. Penyebab umum termasuk konflik pelabuhan (periksa penghunian pelabuhan dan ubah suai konfigurasi), isu kebenaran (periksa keizinan pengguna yang menjalankan perkhidmatan), ralat fail konfigurasi (periksa tetapan parameter), rasuah direktori data (memulihkan data atau membina semula ruang meja), isu ruang jadual InnoDB (semak fail ibdata1) Apabila menyelesaikan masalah, anda harus menganalisisnya berdasarkan log ralat, cari punca utama masalah, dan mengembangkan tabiat sandaran data secara teratur untuk mencegah dan menyelesaikan masalah.
 Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Artikel ini memperkenalkan operasi pangkalan data MySQL. Pertama, anda perlu memasang klien MySQL, seperti MySqlworkbench atau Command Line Client. 1. Gunakan perintah MySQL-Uroot-P untuk menyambung ke pelayan dan log masuk dengan kata laluan akaun root; 2. Gunakan CreateTatabase untuk membuat pangkalan data, dan gunakan Pilih pangkalan data; 3. Gunakan createtable untuk membuat jadual, menentukan medan dan jenis data; 4. Gunakan InsertInto untuk memasukkan data, data pertanyaan, kemas kini data dengan kemas kini, dan padam data dengan padam. Hanya dengan menguasai langkah -langkah ini, belajar menangani masalah biasa dan mengoptimumkan prestasi pangkalan data anda boleh menggunakan MySQL dengan cekap.
 Memahami sifat asid: tiang pangkalan data yang boleh dipercayai
Apr 08, 2025 pm 06:33 PM
Memahami sifat asid: tiang pangkalan data yang boleh dipercayai
Apr 08, 2025 pm 06:33 PM
Penjelasan terperinci mengenai atribut asid asid pangkalan data adalah satu set peraturan untuk memastikan kebolehpercayaan dan konsistensi urus niaga pangkalan data. Mereka menentukan bagaimana sistem pangkalan data mengendalikan urus niaga, dan memastikan integriti dan ketepatan data walaupun dalam hal kemalangan sistem, gangguan kuasa, atau pelbagai pengguna akses serentak. Gambaran keseluruhan atribut asid Atomicity: Transaksi dianggap sebagai unit yang tidak dapat dipisahkan. Mana -mana bahagian gagal, keseluruhan transaksi dilancarkan kembali, dan pangkalan data tidak mengekalkan sebarang perubahan. Sebagai contoh, jika pemindahan bank ditolak dari satu akaun tetapi tidak meningkat kepada yang lain, keseluruhan operasi dibatalkan. Begintransaction; UpdateAcCountSsetBalance = Balance-100Wh
 Bolehkah mysql kembali json
Apr 08, 2025 pm 03:09 PM
Bolehkah mysql kembali json
Apr 08, 2025 pm 03:09 PM
MySQL boleh mengembalikan data JSON. Fungsi JSON_EXTRACT mengekstrak nilai medan. Untuk pertanyaan yang kompleks, pertimbangkan untuk menggunakan klausa WHERE untuk menapis data JSON, tetapi perhatikan kesan prestasinya. Sokongan MySQL untuk JSON sentiasa meningkat, dan disyorkan untuk memberi perhatian kepada versi dan ciri terkini.
 Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote Company Kekosongan Syarikat: Lokasi Lokasi: Jauh Pejabat Jauh Jenis: Gaji sepenuh masa: $ 130,000- $ 140,000 Penerangan Pekerjaan Mengambil bahagian dalam penyelidikan dan pembangunan aplikasi mudah alih Circle dan ciri-ciri berkaitan API awam yang meliputi keseluruhan kitaran hayat pembangunan perisian. Tanggungjawab utama kerja pembangunan secara bebas berdasarkan rubyonrails dan bekerjasama dengan pasukan react/redux/relay front-end. Membina fungsi teras dan penambahbaikan untuk aplikasi web dan bekerjasama rapat dengan pereka dan kepimpinan sepanjang proses reka bentuk berfungsi. Menggalakkan proses pembangunan positif dan mengutamakan kelajuan lelaran. Memerlukan lebih daripada 6 tahun backend aplikasi web kompleks
 Mysql tidak dapat dipasang setelah memuat turun
Apr 08, 2025 am 11:24 AM
Mysql tidak dapat dipasang setelah memuat turun
Apr 08, 2025 am 11:24 AM
Sebab utama kegagalan pemasangan MySQL adalah: 1. Isu kebenaran, anda perlu menjalankan sebagai pentadbir atau menggunakan perintah sudo; 2. Ketergantungan hilang, dan anda perlu memasang pakej pembangunan yang relevan; 3. Konflik pelabuhan, anda perlu menutup program yang menduduki port 3306 atau mengubah suai fail konfigurasi; 4. Pakej pemasangan adalah korup, anda perlu memuat turun dan mengesahkan integriti; 5. Pembolehubah persekitaran dikonfigurasikan dengan salah, dan pembolehubah persekitaran mesti dikonfigurasi dengan betul mengikut sistem operasi. Selesaikan masalah ini dan periksa dengan teliti setiap langkah untuk berjaya memasang MySQL.
 Laravel fasih orm dalam carian model separa Bangla)
Apr 08, 2025 pm 02:06 PM
Laravel fasih orm dalam carian model separa Bangla)
Apr 08, 2025 pm 02:06 PM
Pengambilan Model Laraveleloquent: Mudah mendapatkan data pangkalan data Eloquentorm menyediakan cara ringkas dan mudah difahami untuk mengendalikan pangkalan data. Artikel ini akan memperkenalkan pelbagai teknik carian model fasih secara terperinci untuk membantu anda mendapatkan data dari pangkalan data dengan cekap. 1. Dapatkan semua rekod. Gunakan kaedah semua () untuk mendapatkan semua rekod dalam jadual pangkalan data: USEAPP \ MODELS \ POST; $ POSTS = POST :: SEMUA (); Ini akan mengembalikan koleksi. Anda boleh mengakses data menggunakan gelung foreach atau kaedah pengumpulan lain: foreach ($ postsas $ post) {echo $ post->
