

Teroka laluan baharu - Alat diagnostik untuk menunggu IO

| Pengenalan | Baru-baru ini, saya telah melakukan penyegerakan log masa nyata Sebelum pergi ke dalam talian, saya melakukan satu ujian tekanan log dalam talian Tidak ada masalah dengan baris gilir mesej, pelanggan dan mesin tempatan jangkakan selepas log kedua dimuat naik, masalah datang |

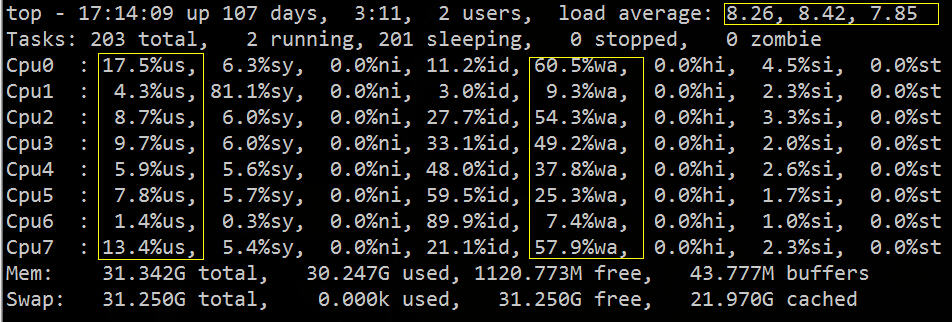
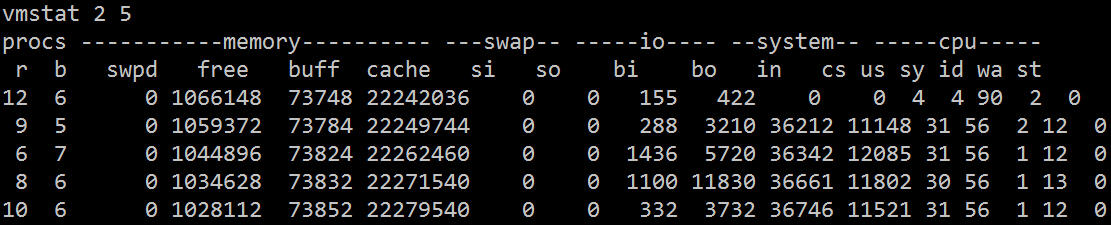
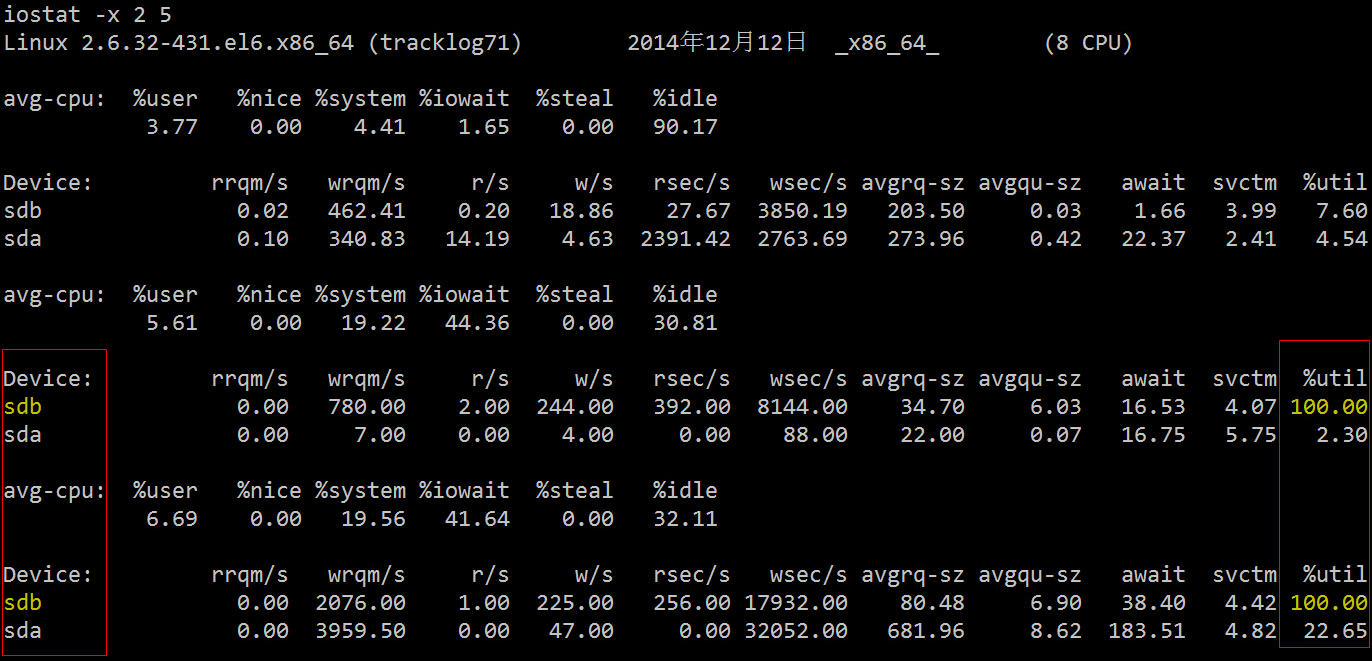
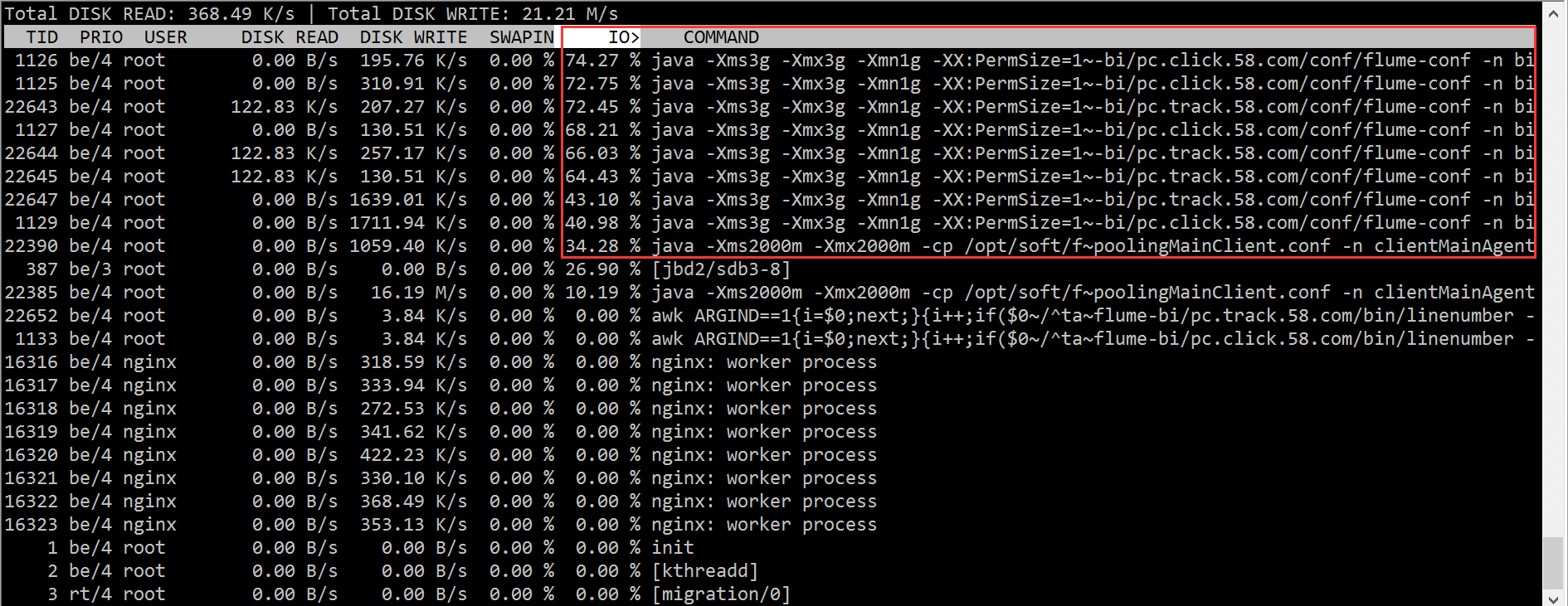
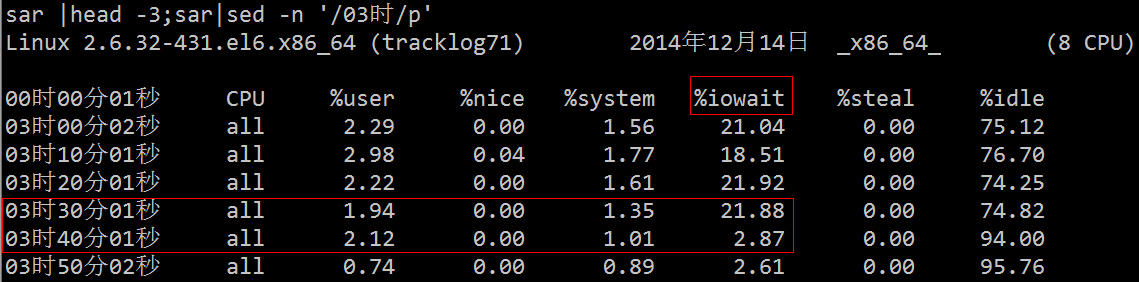
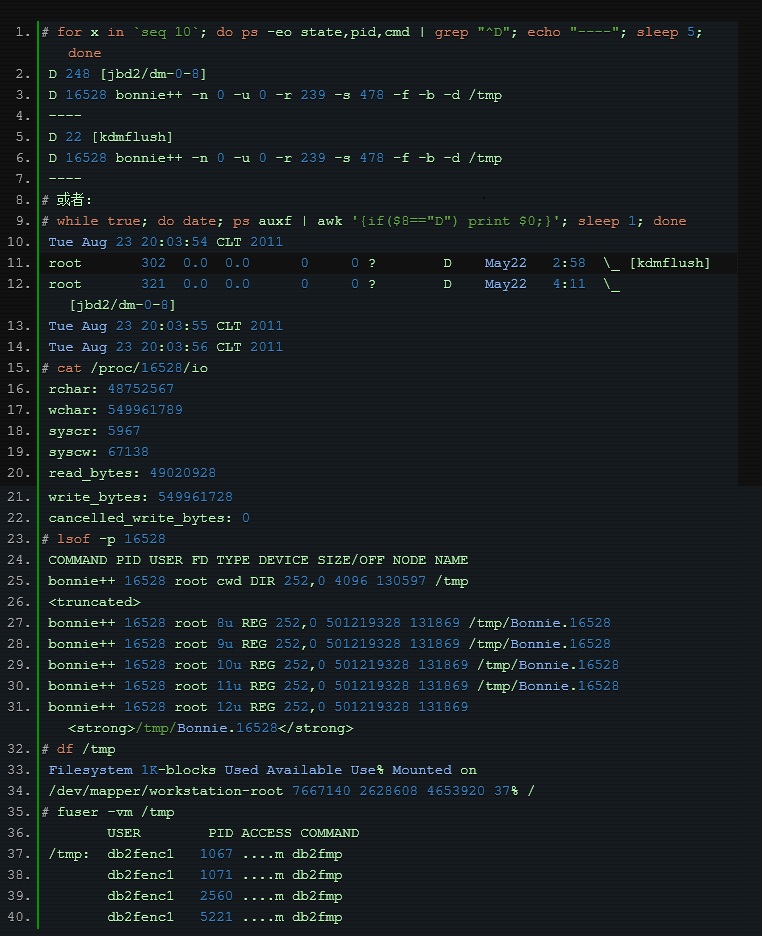
Atas ialah kandungan terperinci Teroka laluan baharu - Alat diagnostik untuk menunggu IO. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Tidak dapat log masuk ke mysql sebagai akar
Apr 08, 2025 pm 04:54 PM
Tidak dapat log masuk ke mysql sebagai akar
Apr 08, 2025 pm 04:54 PM
Sebab utama mengapa anda tidak boleh log masuk ke MySQL sebagai akar adalah masalah kebenaran, ralat fail konfigurasi, kata laluan tidak konsisten, masalah fail soket, atau pemintasan firewall. Penyelesaiannya termasuk: periksa sama ada parameter pengikat di dalam fail konfigurasi dikonfigurasi dengan betul. Semak sama ada kebenaran pengguna root telah diubahsuai atau dipadam dan ditetapkan semula. Sahkan bahawa kata laluan adalah tepat, termasuk kes dan aksara khas. Semak tetapan dan laluan kebenaran fail soket. Semak bahawa firewall menyekat sambungan ke pelayan MySQL.
 C Language Compilation Compilation: Panduan terperinci untuk pemula ke aplikasi praktikal
Apr 04, 2025 am 10:48 AM
C Language Compilation Compilation: Panduan terperinci untuk pemula ke aplikasi praktikal
Apr 04, 2025 am 10:48 AM
C Language Conditional Compilation adalah mekanisme untuk selektif menyusun blok kod berdasarkan keadaan kompilasi masa. Kaedah pengenalan termasuk: menggunakan arahan #if dan #Else untuk memilih blok kod berdasarkan syarat. Ekspresi bersyarat yang biasa digunakan termasuk STDC, _WIN32 dan LINUX. Kes praktikal: Cetak mesej yang berbeza mengikut sistem operasi. Gunakan jenis data yang berbeza mengikut bilangan digit sistem. Fail header yang berbeza disokong mengikut pengkompil. Penyusunan bersyarat meningkatkan kebolehgunaan dan fleksibiliti kod, menjadikannya boleh disesuaikan dengan pengkompil, sistem operasi, dan perubahan seni bina CPU.
 【Rust Sendiri belajar】 Pengenalan
Apr 04, 2025 am 08:03 AM
【Rust Sendiri belajar】 Pengenalan
Apr 04, 2025 am 08:03 AM
1.0.1 Preface Projek ini (termasuk kod dan komen) telah direkodkan semasa karat saya yang diajar sendiri. Mungkin ada kenyataan yang tidak tepat atau tidak jelas, sila minta maaf. Jika anda mendapat manfaat daripadanya, ia lebih baik. 1.0.2 Mengapa Rustrust boleh dipercayai dan cekap? Karat boleh menggantikan C dan C, dengan prestasi yang sama tetapi keselamatan yang lebih tinggi, dan tidak memerlukan rekompilasi yang kerap untuk memeriksa kesilapan seperti C dan C. Kelebihan utama termasuk: Keselamatan Memori (mencegah penunjuk null dari dereferences, penunjuk menggantung, dan perbalahan data). Thread-safe (pastikan kod multi-threaded selamat sebelum pelaksanaan). Elakkan tingkah laku yang tidak ditentukan (mis., Arus dari batas, pembolehubah yang tidak diinisialisasi, atau akses kepada memori yang dibebaskan). Karat menyediakan ciri bahasa moden seperti generik
 Apakah 5 komponen asas Linux?
Apr 06, 2025 am 12:05 AM
Apakah 5 komponen asas Linux?
Apr 06, 2025 am 12:05 AM
Lima komponen asas Linux adalah: 1. Kernel, menguruskan sumber perkakasan; 2. Perpustakaan sistem, menyediakan fungsi dan perkhidmatan; 3. Shell, antara muka pengguna untuk berinteraksi dengan sistem; 4. Sistem fail, menyimpan dan menganjurkan data; 5. Aplikasi, menggunakan sumber sistem untuk melaksanakan fungsi.
 Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Terdapat banyak sebab mengapa permulaan MySQL gagal, dan ia boleh didiagnosis dengan memeriksa log ralat. Penyebab umum termasuk konflik pelabuhan (periksa penghunian pelabuhan dan ubah suai konfigurasi), isu kebenaran (periksa keizinan pengguna yang menjalankan perkhidmatan), ralat fail konfigurasi (periksa tetapan parameter), rasuah direktori data (memulihkan data atau membina semula ruang meja), isu ruang jadual InnoDB (semak fail ibdata1) Apabila menyelesaikan masalah, anda harus menganalisisnya berdasarkan log ralat, cari punca utama masalah, dan mengembangkan tabiat sandaran data secara teratur untuk mencegah dan menyelesaikan masalah.
 Penyelesaian kepada kesilapan yang dilaporkan oleh MySQL pada versi sistem tertentu
Apr 08, 2025 am 11:54 AM
Penyelesaian kepada kesilapan yang dilaporkan oleh MySQL pada versi sistem tertentu
Apr 08, 2025 am 11:54 AM
Penyelesaian kepada ralat pemasangan MySQL adalah: 1. Berhati -hati memeriksa persekitaran sistem untuk memastikan keperluan perpustakaan ketergantungan MySQL dipenuhi. Sistem operasi dan keperluan versi yang berbeza adalah berbeza; 2. Berhati -hati membaca mesej ralat dan mengambil langkah -langkah yang sepadan mengikut arahan (seperti fail perpustakaan yang hilang atau kebenaran yang tidak mencukupi), seperti memasang kebergantungan atau menggunakan arahan sudo; 3 Jika perlu, cuba pasang kod sumber dan periksa dengan teliti log kompilasi, tetapi ini memerlukan pengetahuan dan pengalaman Linux tertentu. Kunci untuk menyelesaikan masalah akhirnya adalah dengan teliti memeriksa persekitaran sistem dan maklumat ralat, dan merujuk kepada dokumen rasmi.
 Bolehkah mysql berjalan di Android
Apr 08, 2025 pm 05:03 PM
Bolehkah mysql berjalan di Android
Apr 08, 2025 pm 05:03 PM
MySQL tidak boleh berjalan secara langsung di Android, tetapi ia boleh dilaksanakan secara tidak langsung dengan menggunakan kaedah berikut: menggunakan pangkalan data ringan SQLite, yang dibina di atas sistem Android, tidak memerlukan pelayan yang berasingan, dan mempunyai penggunaan sumber kecil, yang sangat sesuai untuk aplikasi peranti mudah alih. Sambungkan jauh ke pelayan MySQL dan sambungkan ke pangkalan data MySQL pada pelayan jauh melalui rangkaian untuk membaca dan menulis data, tetapi terdapat kelemahan seperti kebergantungan rangkaian yang kuat, isu keselamatan dan kos pelayan.
 Di manakah perpustakaan fungsi bahasa C? Bagaimana untuk menambah perpustakaan fungsi bahasa C?
Apr 03, 2025 pm 11:39 PM
Di manakah perpustakaan fungsi bahasa C? Bagaimana untuk menambah perpustakaan fungsi bahasa C?
Apr 03, 2025 pm 11:39 PM
Perpustakaan Fungsi Bahasa C adalah kotak alat yang mengandungi pelbagai fungsi, yang dianjurkan dalam fail perpustakaan yang berbeza. Menambah perpustakaan memerlukan menyatakannya melalui pilihan baris perintah pengkompil, contohnya, pengkompil GCC menggunakan pilihan -L diikuti dengan singkatan nama perpustakaan. Jika fail perpustakaan tidak berada di bawah laluan carian lalai, anda perlu menggunakan pilihan -L untuk menentukan laluan fail perpustakaan. Perpustakaan boleh dibahagikan kepada perpustakaan statik dan perpustakaan dinamik. Perpustakaan statik secara langsung dikaitkan dengan program pada masa kompilasi, manakala perpustakaan dinamik dimuatkan semasa runtime.
