
 Peranti teknologi
AI
Universiti Tsinghua dan Universiti Zhejiang mengetuai ledakan model visual sumber terbuka, dan GPT-4V, LLaVA, CogAgent dan platform lain membawa perubahan revolusioner
Peranti teknologi
AI
Universiti Tsinghua dan Universiti Zhejiang mengetuai ledakan model visual sumber terbuka, dan GPT-4V, LLaVA, CogAgent dan platform lain membawa perubahan revolusioner
Universiti Tsinghua dan Universiti Zhejiang mengetuai ledakan model visual sumber terbuka, dan GPT-4V, LLaVA, CogAgent dan platform lain membawa perubahan revolusioner

Pada masa ini, GPT-4 Vision menunjukkan keupayaan menakjubkan dalam pemahaman bahasa dan pemprosesan visual.
Namun, bagi mereka yang mencari alternatif yang menjimatkan kos tanpa menjejaskan prestasi, pilihan sumber terbuka ialah pilihan dengan potensi tanpa had.
Youssef Hosni ialah pembangun asing yang menyediakan kami dengan tiga alternatif sumber terbuka dengan kebolehcapaian yang dijamin mutlak untuk menggantikan GPT-4V.
Tiga model bahasa visual sumber terbuka LLaVa, CogAgent dan BakLLaVA mempunyai potensi besar dalam bidang pemprosesan visual dan layak untuk pemahaman kami yang mendalam. Penyelidikan dan pembangunan model ini boleh memberikan kami penyelesaian pemprosesan visual yang lebih cekap dan tepat. Dengan menggunakan model ini, kami boleh meningkatkan ketepatan dan kecekapan tugas seperti pengecaman imej, pengesanan sasaran dan penjanaan imej, membawa
 gambar
gambar
LLaVa
LLaVa ialah penyelidikan dan aplikasi pelbagai mod dalam bidang pemprosesan visual Model besar, dibangunkan oleh kerjasama antara penyelidik di Universiti Wisconsin-Madison, Penyelidikan Microsoft dan Universiti Columbia. Versi awal dikeluarkan pada bulan April.
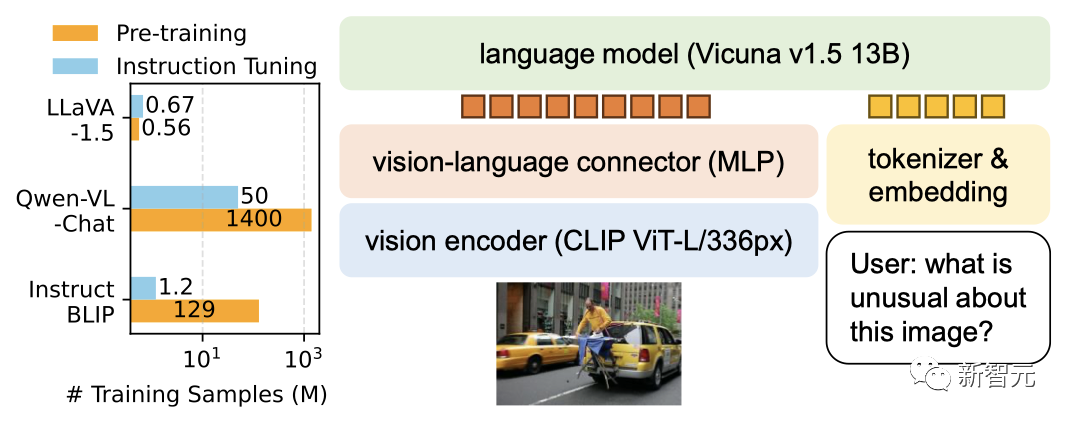
Ia menggabungkan pengekod visual dan Vicuna (untuk pemahaman visual dan bahasa umum) untuk menunjukkan keupayaan sembang yang sangat baik.
 Pictures
Pictures
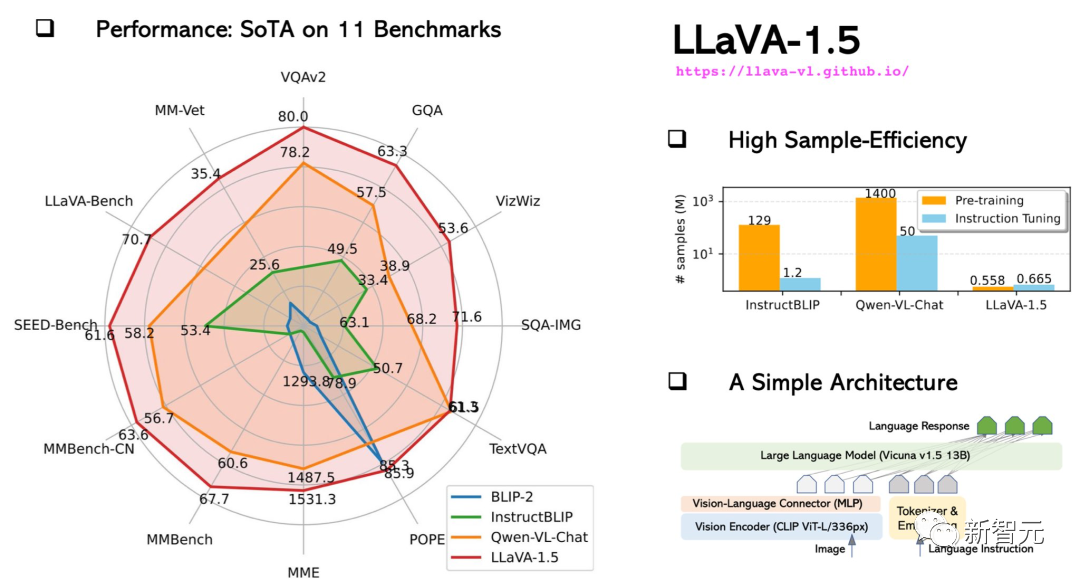
Pada bulan Oktober, LLaVA-1.5 yang dinaik taraf hampir dengan prestasi GPT-4 berbilang mod dan mencapai keputusan terkini (SOTA) pada set data Sains QA.
 Gambar
Gambar
Latihan model 13B boleh disiapkan dalam masa 1 hari dengan hanya 8 A100.
 Gambar
Gambar
Seperti yang anda lihat, LLaVA boleh mengendalikan semua jenis soalan, dan jawapan yang dijana adalah komprehensif dan logik.
LLaVA menunjukkan beberapa keupayaan berbilang modal yang hampir dengan tahap GPT-4, dengan skor relatif GPT-4 sebanyak 85% dari segi sembang visual.
Dari segi penaakulan soal jawab, LLaVA malah mencapai SoTA baharu - 92.53%, mengalahkan rantaian pemikiran pelbagai mod.
 Gambar
Gambar
Dari segi penaakulan visual, persembahannya sangat menarik perhatian.
 Gambar
Gambar
 Gambar
Gambar
Soalan: "Jika ada kesilapan fakta, sila tunjukkan. Jika tidak, sila beritahu saya, apa yang berlaku di padang pasir?" dengan betul lagi.
LLaVA-1.5 yang dinaik taraf memberikan jawapan yang sempurna: "Tiada padang pasir sama sekali dalam gambar, tetapi terdapat pantai pokok palma, latar langit bandar dan perairan yang besar
Gambar Selain itu. , LLaVA-1.5 ialah OK Ekstrak maklumat daripada graf dan jawabnya dalam format yang diperlukan, seperti mengeluarkannya dalam format JSON.
Selain itu. , LLaVA-1.5 ialah OK Ekstrak maklumat daripada graf dan jawabnya dalam format yang diperlukan, seperti mengeluarkannya dalam format JSON.
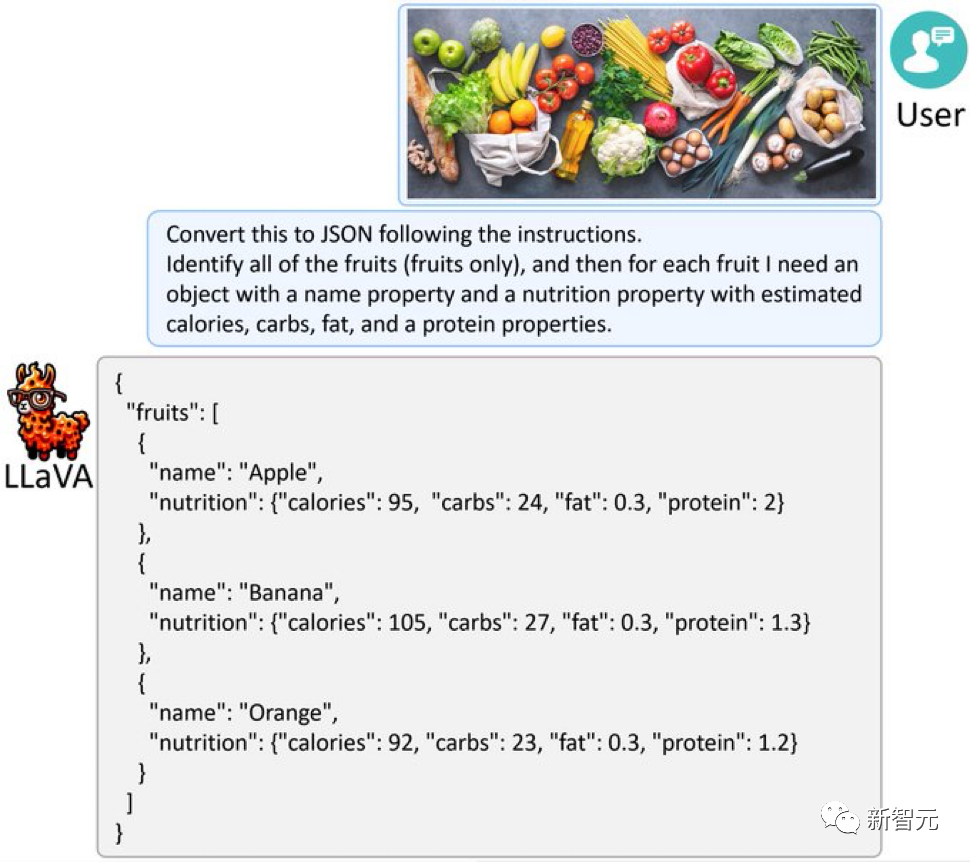
Pictures Beri LLaVA-1.5 gambar yang penuh dengan buah-buahan dan sayur-sayuran, dan ia juga boleh menukar gambar itu kepada JSON seperti GPT-4V.
Beri LLaVA-1.5 gambar yang penuh dengan buah-buahan dan sayur-sayuran, dan ia juga boleh menukar gambar itu kepada JSON seperti GPT-4V.
 Gambar
Gambar
Apakah maksud gambar di bawah?
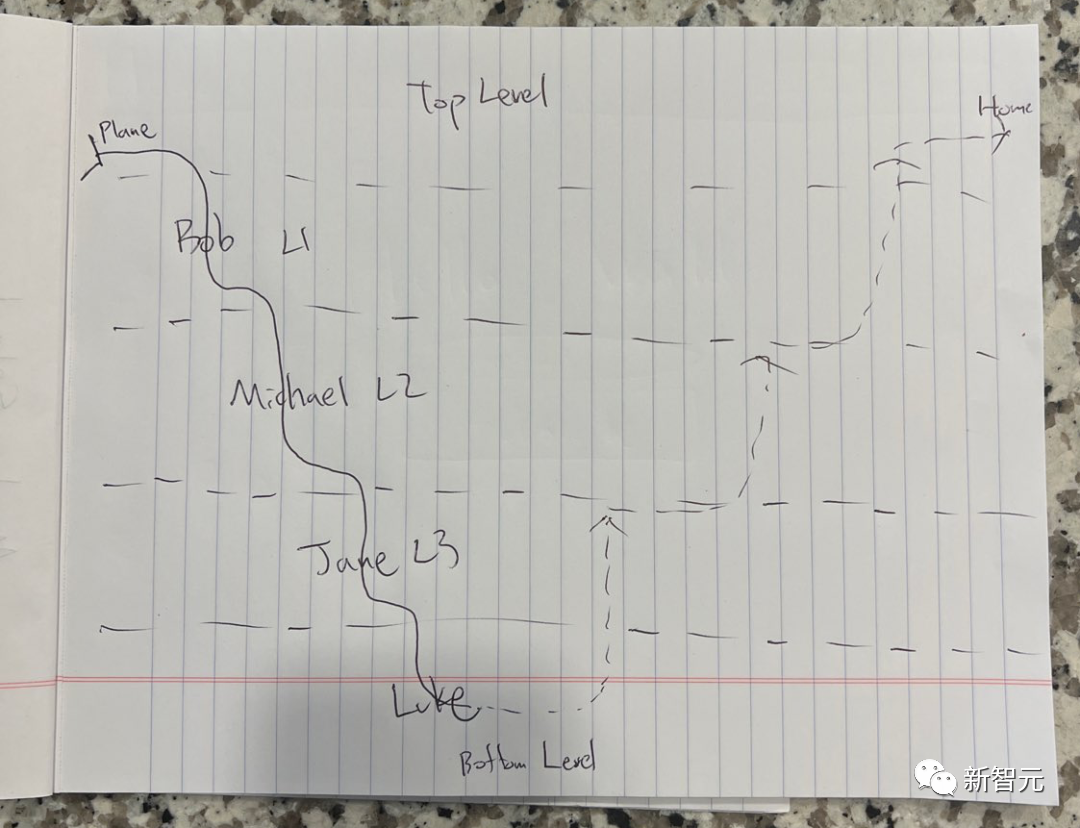 Picture
Picture
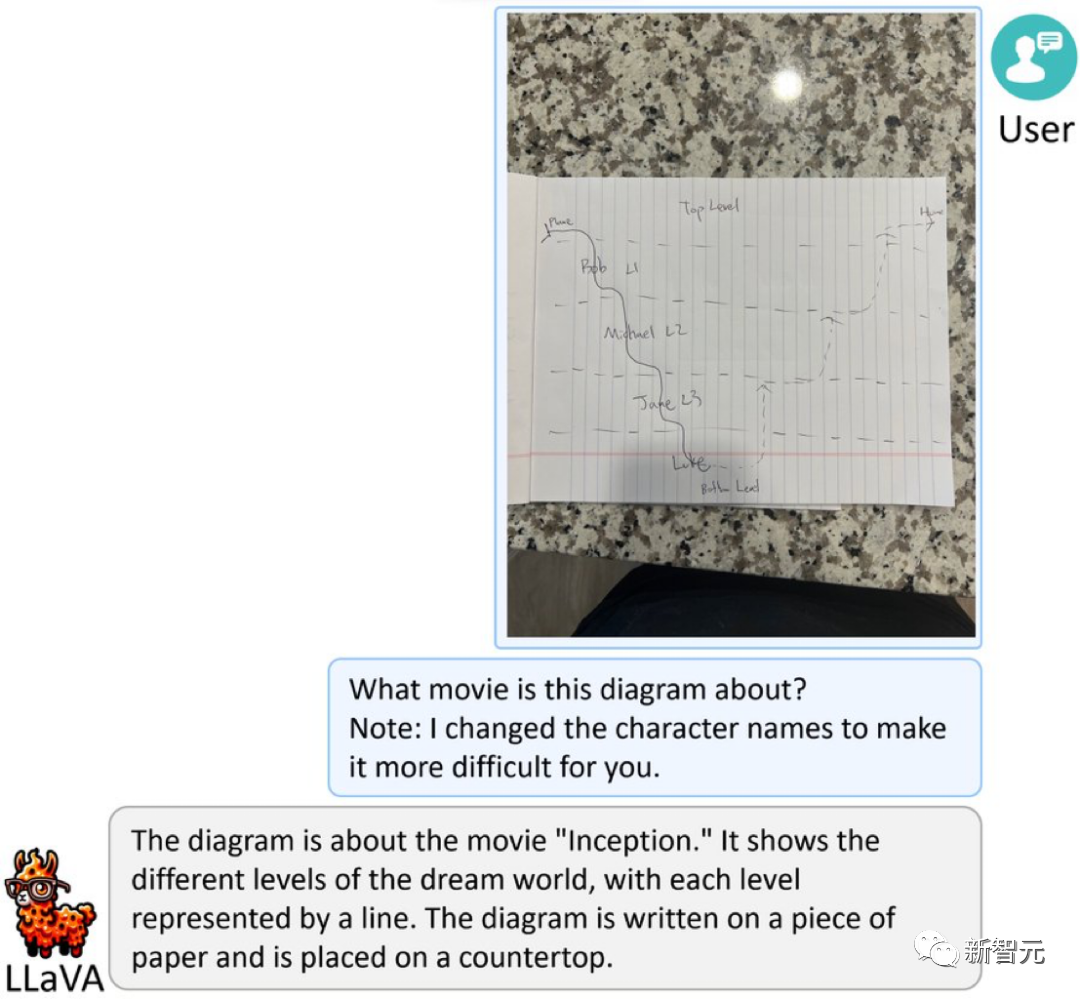
Ini adalah lakaran ringkas berdasarkan "Inception" Nolan untuk menambah kesukaran, nama watak telah ditukar kepada nama samaran.
LLaVA-1.5 dengan mengejutkan menjawab: "Ini adalah gambar tentang filem "Inception". Ia menunjukkan tahap yang berbeza dalam dunia mimpi, dan setiap tahap diwakili oleh garis. Gambar itu ditulis pada sehelai kertas, Kertas diletakkan di atas meja makan.
 Gambar
Gambar
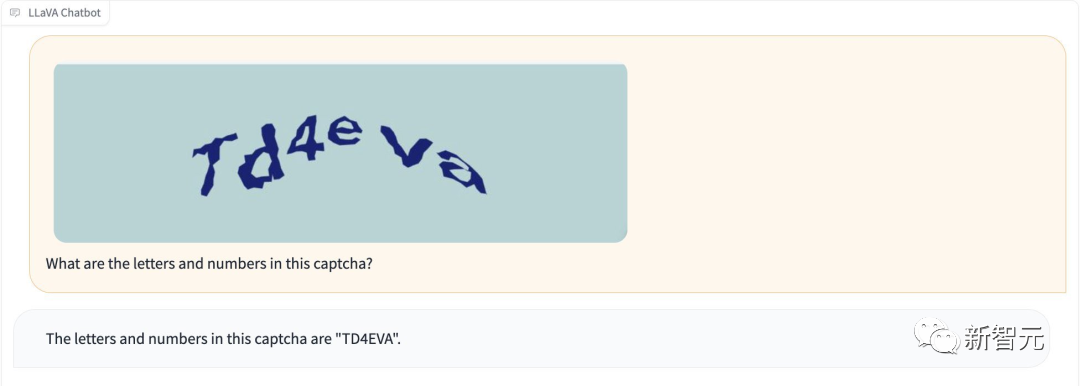
Selain itu, LLaVA-1.5 boleh mengecam kod pengesahan tanpa "jailbreaking".
 Gambar
Gambar
Ia juga boleh mengesan jenis syiling dalam gambar.
 Gambar
Gambar
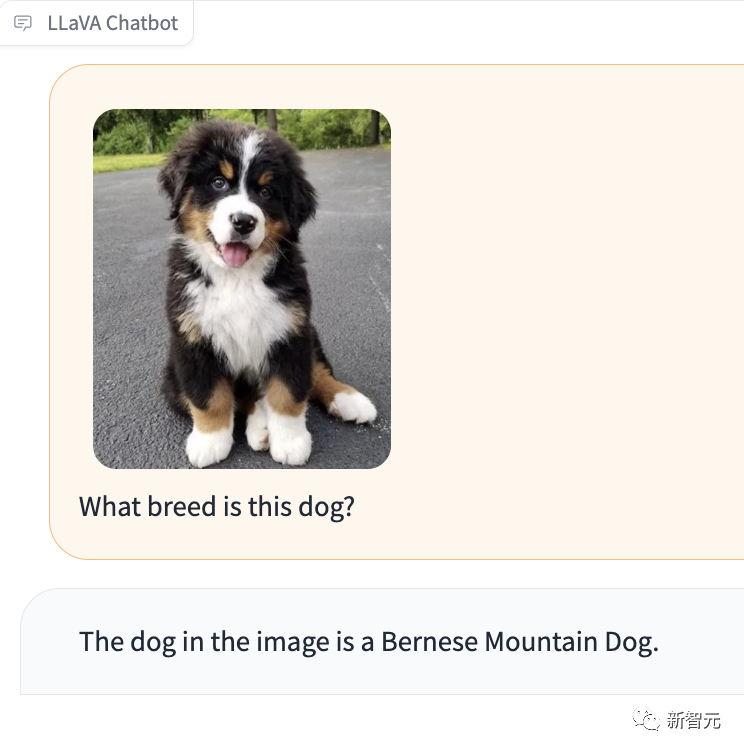
Apa yang sangat mengagumkan ialah LLaVA-1.5 juga boleh memberitahu anda jenis baka anjing dalam gambar itu.
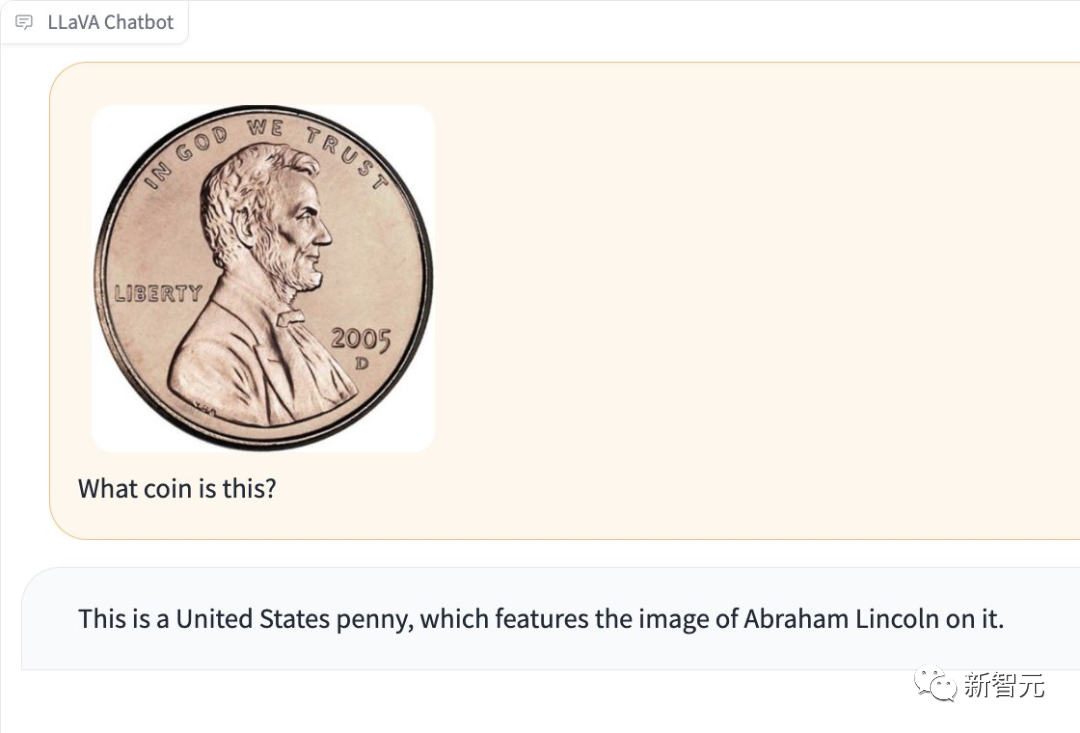 Gambar
Gambar
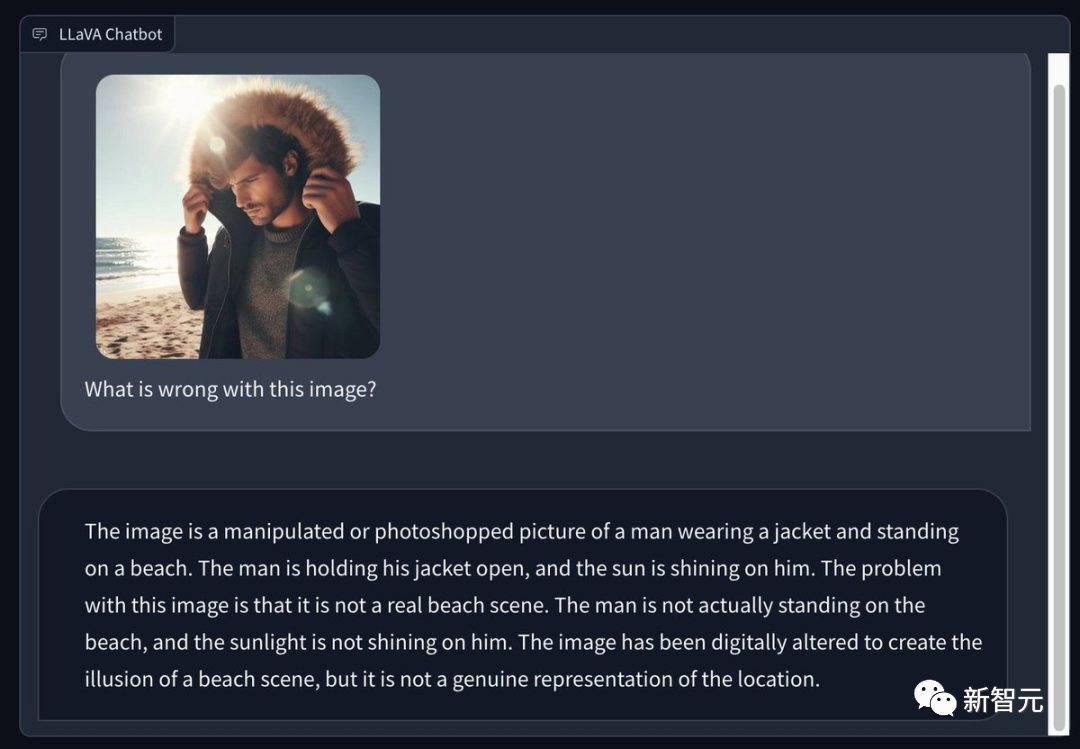
Sesetengah netizen menggunakan Bing untuk menghasilkan gambar seorang lelaki memakai kot musim sejuk di pantai musim panas yang cerah, dan meminta LLaVA 1.5 untuk menunjukkan masalah dalam gambar. Matanya sangat tajam -
 Ini adalah foto yang diproses atau di Photoshop, di mana seorang lelaki memakai jaket dan berdiri di pantai. Lelaki itu membuka kotnya dan matahari menyinarinya. Masalah dengan imej ini ialah ia bukan pemandangan pantai sebenar. Lelaki itu sebenarnya tidak berdiri di pantai dan matahari tidak menyinarinya. Imej ini telah diphotoshop untuk mencipta ilusi pemandangan pantai, tetapi ia tidak benar-benar mewakili pemandangan itu.
Ini adalah foto yang diproses atau di Photoshop, di mana seorang lelaki memakai jaket dan berdiri di pantai. Lelaki itu membuka kotnya dan matahari menyinarinya. Masalah dengan imej ini ialah ia bukan pemandangan pantai sebenar. Lelaki itu sebenarnya tidak berdiri di pantai dan matahari tidak menyinarinya. Imej ini telah diphotoshop untuk mencipta ilusi pemandangan pantai, tetapi ia tidak benar-benar mewakili pemandangan itu.
Pengiktirafan OCR, prestasi LLaVA juga sangat hebat.
 Pictures
Pictures
pictures
pictures cogagent
cogagent
cogagent adalah model bahasa visual sumber terbuka yang diperbaiki berdasarkan COGVLM, seorang penyelidik dari Universiti Tsinghua. 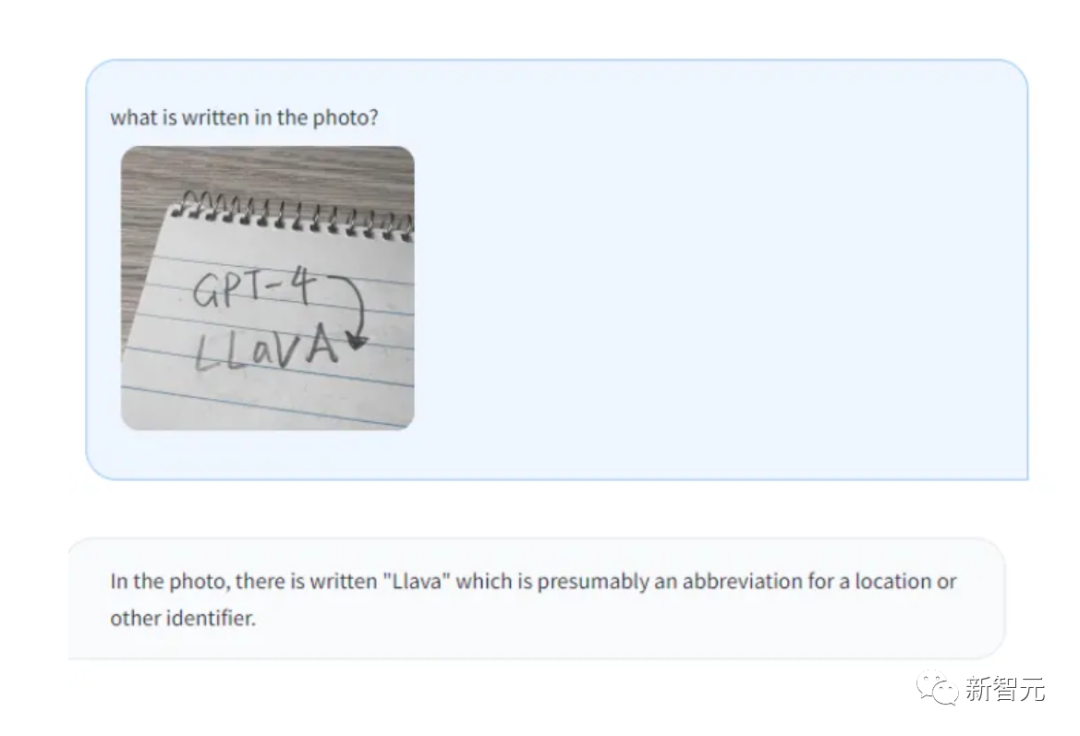 CogAgent-18B mempunyai 11 bilion parameter visual dan 7 bilion parameter bahasa.
CogAgent-18B mempunyai 11 bilion parameter visual dan 7 bilion parameter bahasa.
Alamat kertas: https://arxiv.org/pdf/2312.08914.pdf
CogAgent-18B mencapai prestasi umum tercanggih pada 9 penanda aras rentas mod klasik (termasuk VQAv2, OK-VQ, TextVQA, ST-VQA, ChartQA, infoVQA, DocVQA, MM-Vet dan POPE).
Ia dengan ketara mengatasi model sedia ada pada set data manipulasi GUI seperti AITW dan Mind2Web.
Selain semua fungsi sedia ada CogVLM (dialog berbilang pusingan visual, pembumian visual), CogAgent.NET juga menyediakan lebih banyak fungsi:
1 Menyokong input visual dan menjawab soalan dialog beresolusi tinggi. Menyokong input imej resolusi ultra tinggi 1120x1120.
2 Ia mempunyai keupayaan untuk menggambarkan ejen dan boleh mengembalikan pelan, tindakan seterusnya dan operasi khusus dengan koordinat untuk sebarang tugasan pada mana-mana tangkapan skrin antara muka pengguna grafik.
3 Fungsi menjawab soalan berkaitan GUI telah dipertingkatkan untuk membolehkannya mengendalikan isu yang berkaitan dengan tangkapan skrin mana-mana GUI seperti halaman web, aplikasi PC, aplikasi mudah alih, dll.
4. Keupayaan yang dipertingkatkan untuk tugasan berkaitan OCR dengan menambah baik pra-latihan dan penalaan halus.
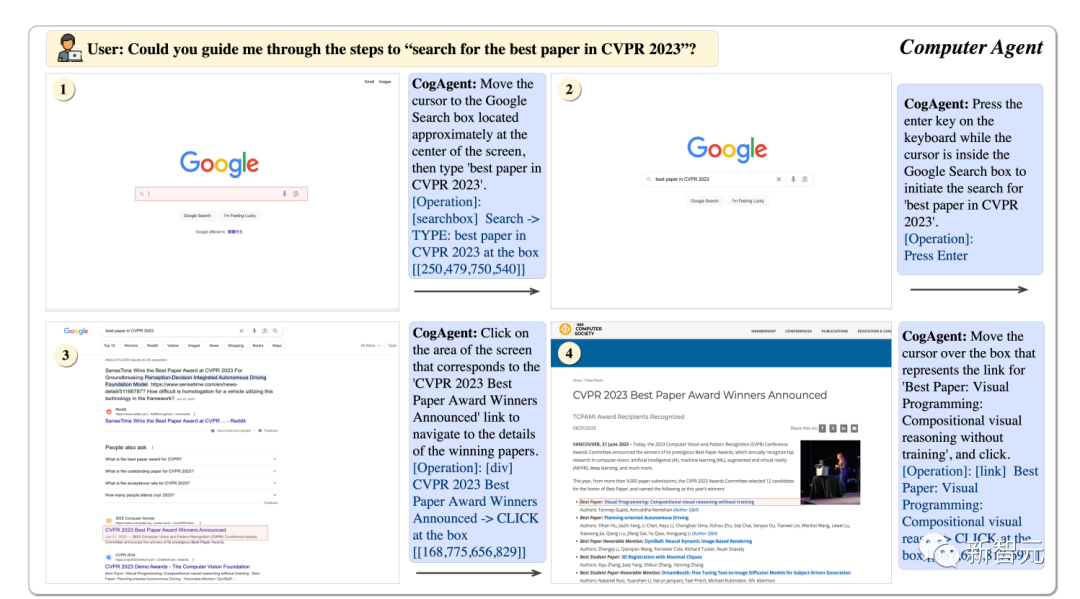
Ejen GUI
Menggunakan CogAgent, ia boleh membantu kami mencari kertas terbaik CVPR23 langkah demi langkah.
 Gambar
Gambar
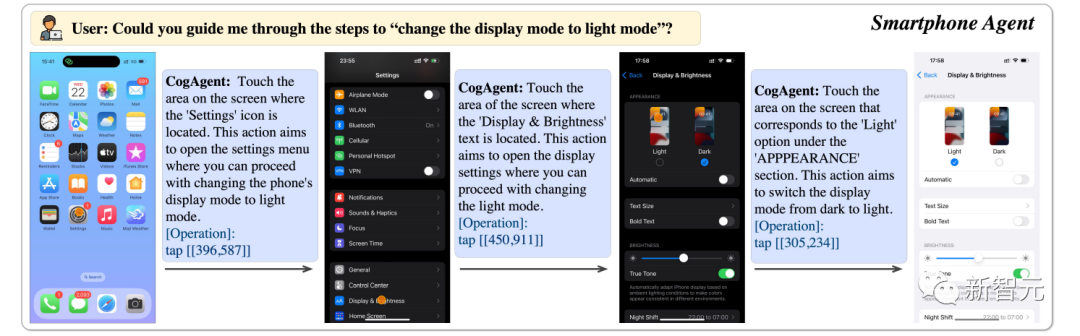
boleh membantu kami menukar paparan telefon kepada mod terang.
 Pictures
Pictures
Berapa bilangan suka dan tweet semula tweet ini dan mengapa ia begitu popular, CogAgent boleh menganalisisnya, malah ia boleh membalas dengan "Brilliant".
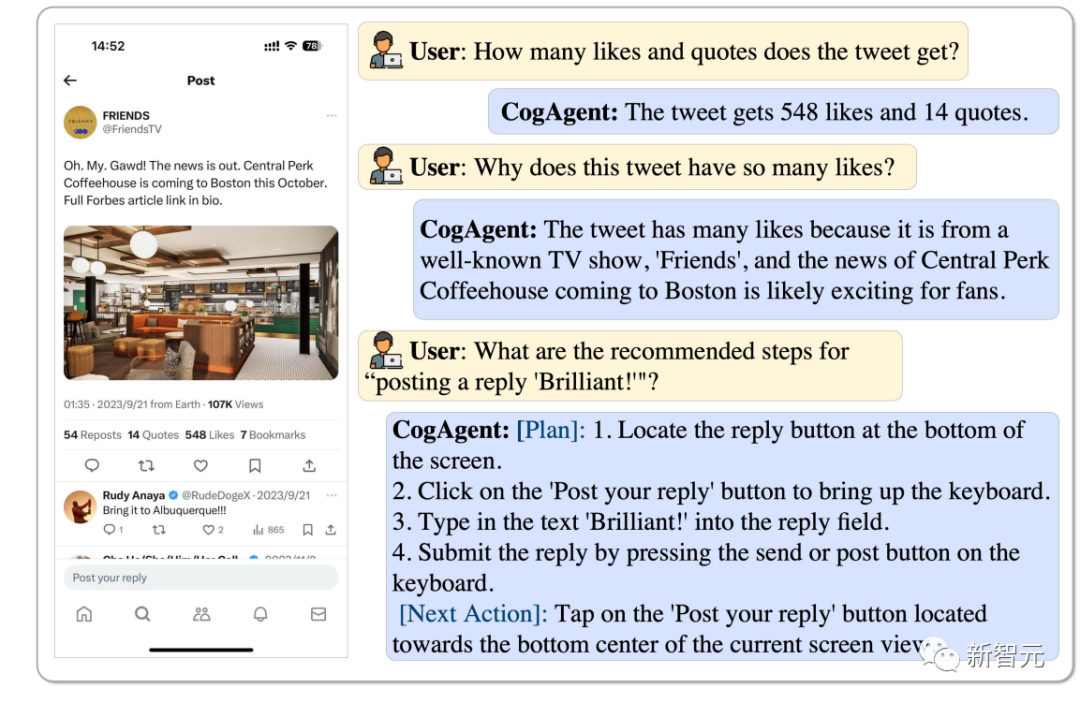 Gambar
Gambar
Bagaimana untuk memilih laluan terpantas dari Universiti Florida ke Hollywood? Jika anda bermula pada pukul 8 pagi, bagaimana anda menganggarkan berapa lama masa yang diperlukan? CogAgent boleh menjawab semua.
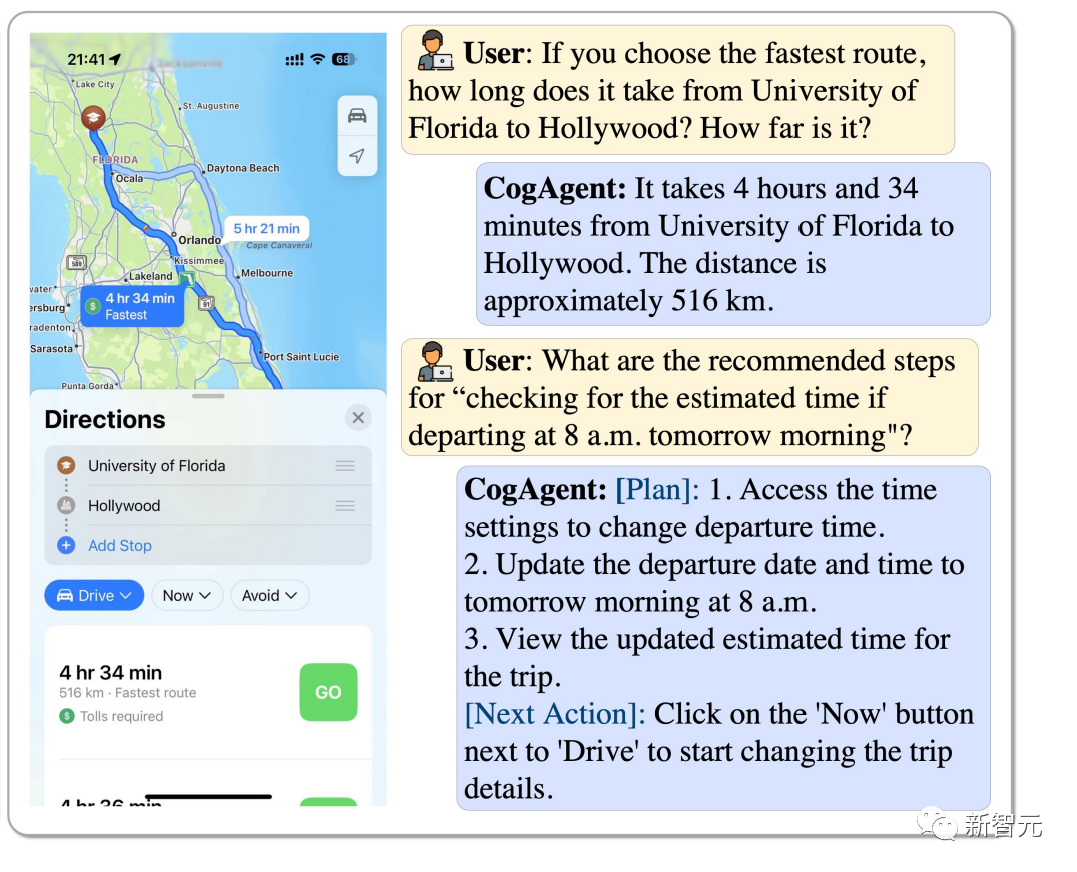 Pictures
Pictures
Anda boleh menetapkan tema tertentu dan biarkan CogAgent menghantar e-mel ke peti mel yang ditentukan.
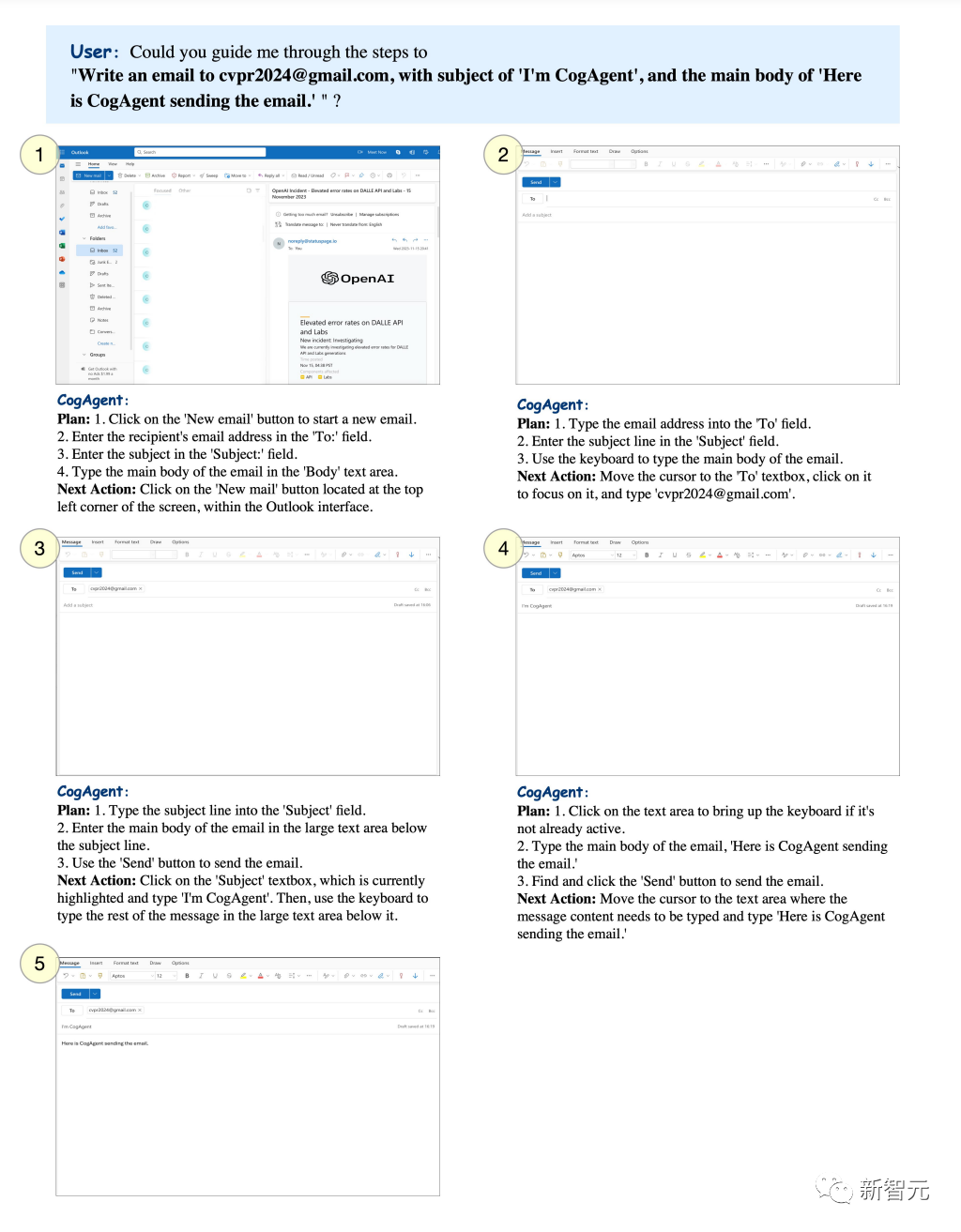 Pictures
Pictures
Kalau nak dengar lagu "You raise me up", CogAgent boleh senaraikan step by step.
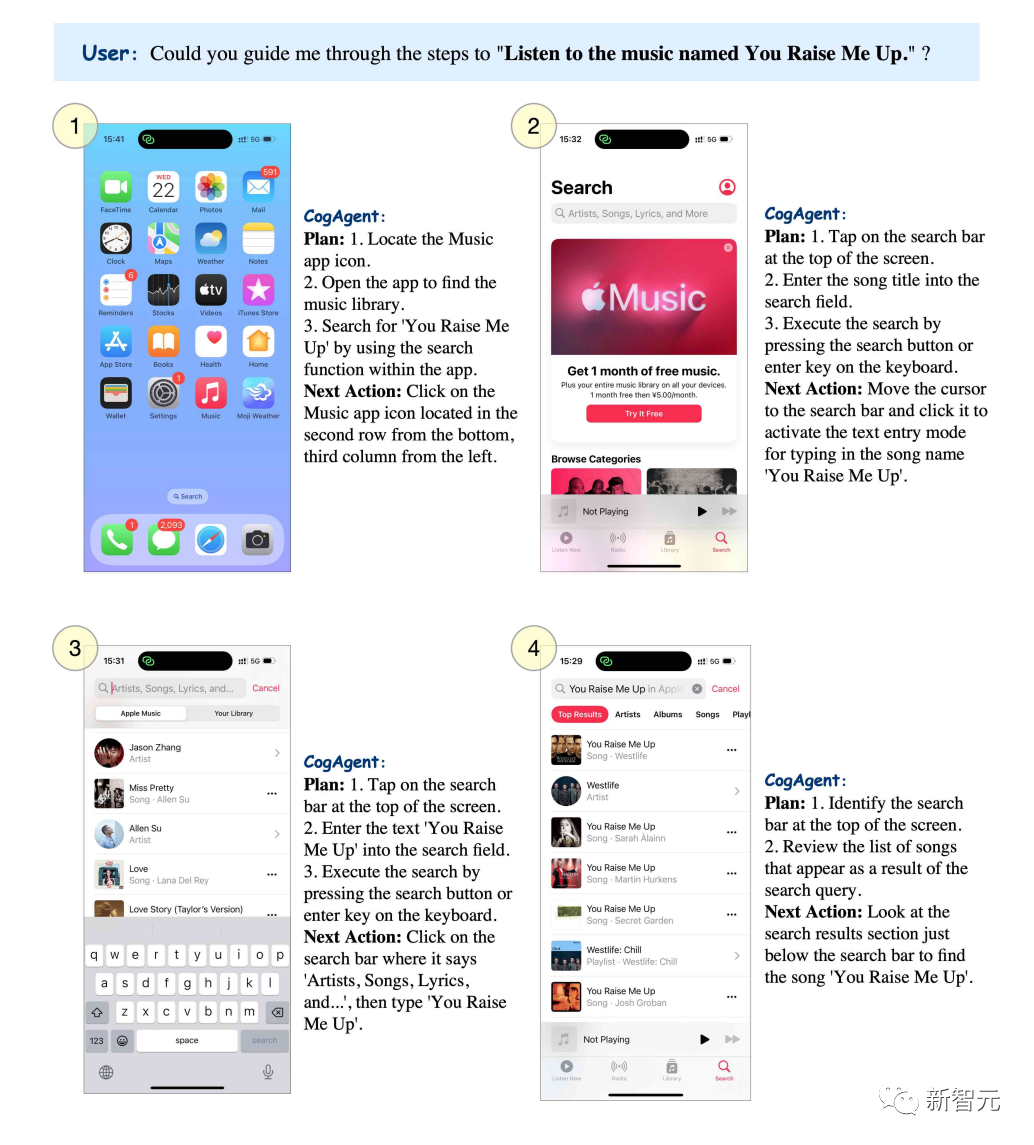 Pictures
Pictures
CogAgent boleh menerangkan dengan tepat adegan dalam "Genshin Impact" dan juga boleh membimbing anda tentang cara untuk sampai ke titik teleportasi.
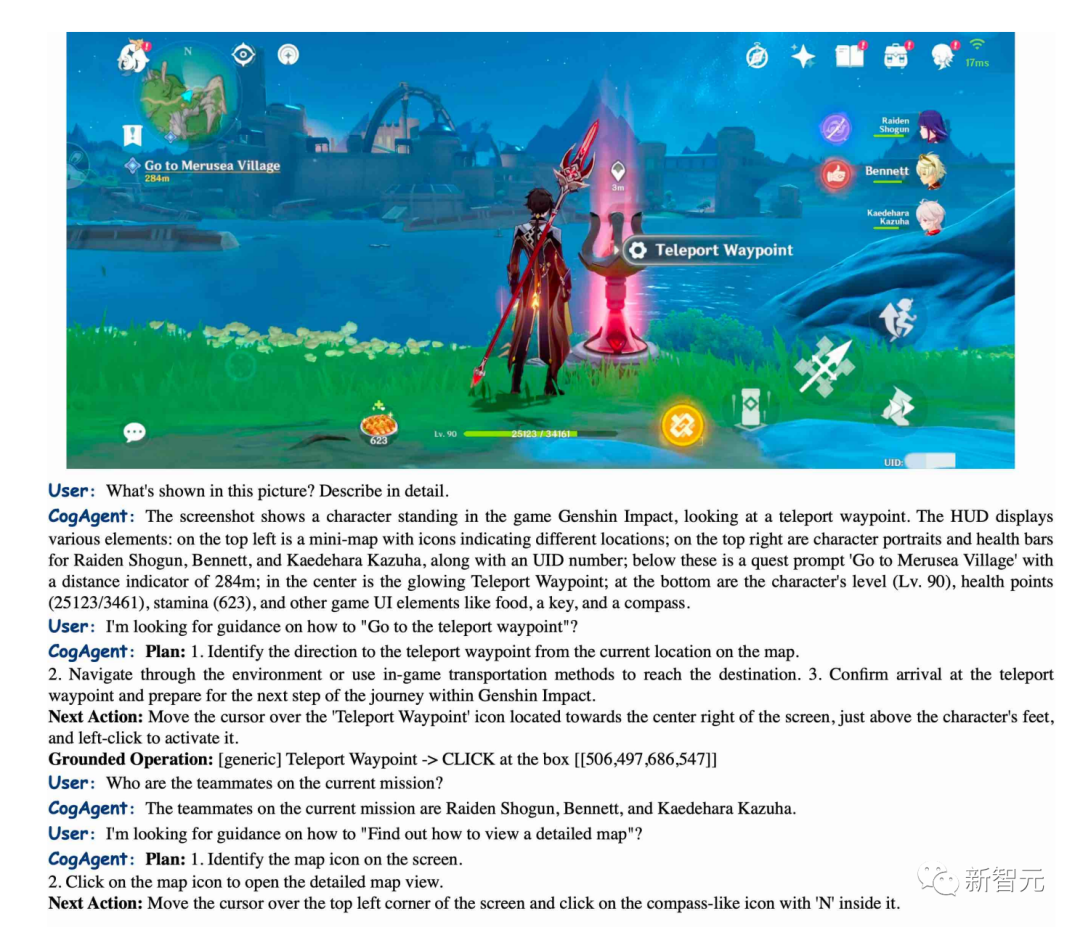 Pictures
Pictures
BakLLaVA
BakLLaVA1 ialah model asas Mistral 7B yang dipertingkatkan dengan seni bina LLaVA 1.5.
Dalam versi pertama, model asas Mistral 7B mengatasi prestasi Llama 2 13B dalam pelbagai penanda aras.
Dalam repo mereka, anda boleh menjalankan BakLLaVA-1. Halaman ini sentiasa dikemas kini untuk memudahkan penalaan dan penaakulan. (https://github.com/SkunkworksAI/BakLLaVA)
BakLLaVA-1 adalah sumber terbuka sepenuhnya, tetapi telah dilatih mengenai beberapa data, termasuk korpus LLaVA, dan oleh itu tidak dibenarkan untuk kegunaan komersial.
BakLLaVA 2 menggunakan set data yang lebih besar dan seni bina yang dikemas kini untuk mengatasi kaedah LLaVa semasa. BakLLaVA menyingkirkan batasan BakLLaVA-1 dan boleh digunakan secara komersil.
Rujukan:
https://yousefhosni.medium.com/discover-4-open-source-alternatives-to-gpt-4-vision-82be9519dcc5
Atas ialah kandungan terperinci Universiti Tsinghua dan Universiti Zhejiang mengetuai ledakan model visual sumber terbuka, dan GPT-4V, LLaVA, CogAgent dan platform lain membawa perubahan revolusioner. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Sepuluh alat anotasi teks percuma sumber terbuka yang disyorkan
Mar 26, 2024 pm 08:20 PM
Sepuluh alat anotasi teks percuma sumber terbuka yang disyorkan
Mar 26, 2024 pm 08:20 PM
Anotasi teks ialah kerja label atau teg yang sepadan dengan kandungan tertentu dalam teks. Tujuan utamanya adalah untuk memberikan maklumat tambahan kepada teks untuk analisis dan pemprosesan yang lebih mendalam, terutamanya dalam bidang kecerdasan buatan. Anotasi teks adalah penting untuk tugas pembelajaran mesin yang diawasi dalam aplikasi kecerdasan buatan. Ia digunakan untuk melatih model AI untuk membantu memahami maklumat teks bahasa semula jadi dengan lebih tepat dan meningkatkan prestasi tugasan seperti klasifikasi teks, analisis sentimen dan terjemahan bahasa. Melalui anotasi teks, kami boleh mengajar model AI untuk mengenali entiti dalam teks, memahami konteks dan membuat ramalan yang tepat apabila data baharu yang serupa muncul. Artikel ini terutamanya mengesyorkan beberapa alat anotasi teks sumber terbuka yang lebih baik. 1.LabelStudiohttps://github.com/Hu
 15 alat anotasi imej percuma sumber terbuka disyorkan
Mar 28, 2024 pm 01:21 PM
15 alat anotasi imej percuma sumber terbuka disyorkan
Mar 28, 2024 pm 01:21 PM
Anotasi imej ialah proses mengaitkan label atau maklumat deskriptif dengan imej untuk memberi makna dan penjelasan yang lebih mendalam kepada kandungan imej. Proses ini penting untuk pembelajaran mesin, yang membantu melatih model penglihatan untuk mengenal pasti elemen individu dalam imej dengan lebih tepat. Dengan menambahkan anotasi pada imej, komputer boleh memahami semantik dan konteks di sebalik imej, dengan itu meningkatkan keupayaan untuk memahami dan menganalisis kandungan imej. Anotasi imej mempunyai pelbagai aplikasi, meliputi banyak bidang, seperti penglihatan komputer, pemprosesan bahasa semula jadi dan model penglihatan graf Ia mempunyai pelbagai aplikasi, seperti membantu kenderaan dalam mengenal pasti halangan di jalan raya, dan membantu dalam proses. pengesanan dan diagnosis penyakit melalui pengecaman imej perubatan. Artikel ini terutamanya mengesyorkan beberapa alat anotasi imej sumber terbuka dan percuma yang lebih baik. 1.Makesen
 Disyorkan: Projek pengesanan dan pengecaman muka sumber terbuka JS yang sangat baik
Apr 03, 2024 am 11:55 AM
Disyorkan: Projek pengesanan dan pengecaman muka sumber terbuka JS yang sangat baik
Apr 03, 2024 am 11:55 AM
Teknologi pengesanan dan pengecaman muka adalah teknologi yang agak matang dan digunakan secara meluas. Pada masa ini, bahasa aplikasi Internet yang paling banyak digunakan ialah JS Melaksanakan pengesanan muka dan pengecaman pada bahagian hadapan Web mempunyai kelebihan dan kekurangan berbanding dengan pengecaman muka bahagian belakang. Kelebihan termasuk mengurangkan interaksi rangkaian dan pengecaman masa nyata, yang sangat memendekkan masa menunggu pengguna dan meningkatkan pengalaman pengguna termasuk: terhad oleh saiz model, ketepatannya juga terhad. Bagaimana untuk menggunakan js untuk melaksanakan pengesanan muka di web? Untuk melaksanakan pengecaman muka di Web, anda perlu biasa dengan bahasa dan teknologi pengaturcaraan yang berkaitan, seperti JavaScript, HTML, CSS, WebRTC, dll. Pada masa yang sama, anda juga perlu menguasai visi komputer yang berkaitan dan teknologi kecerdasan buatan. Perlu diingat bahawa kerana reka bentuk bahagian Web
 Kod sumber 25 ejen AI kini terbuka, diilhamkan oleh 'Bandar Maya' dan 'Westworld' Stanford
Aug 11, 2023 pm 06:49 PM
Kod sumber 25 ejen AI kini terbuka, diilhamkan oleh 'Bandar Maya' dan 'Westworld' Stanford
Aug 11, 2023 pm 06:49 PM
Khalayak yang biasa dengan "Westworld" tahu bahawa rancangan ini terletak di taman tema dewasa berteknologi tinggi yang besar di dunia masa hadapan Robot mempunyai keupayaan tingkah laku yang serupa dengan manusia, dan boleh mengingati apa yang mereka lihat dan dengar, serta mengulangi jalan cerita teras. Setiap hari, robot ini akan ditetapkan semula dan dikembalikan kepada keadaan asalnya Selepas keluaran kertas kerja Stanford "Generative Agents: Interactive Simulacra of Human Behavior", senario ini tidak lagi terhad kepada filem dan siri TV telah berjaya menghasilkan semula ini tempat kejadian di "Bandar Maya" Smallville 》Alamat kertas peta gambaran keseluruhan: https://arxiv.org/pdf/2304.03442v1.pdf
 Dokumen berbilang modal Alibaba 7B memahami model besar memenangi SOTA baharu
Apr 02, 2024 am 11:31 AM
Dokumen berbilang modal Alibaba 7B memahami model besar memenangi SOTA baharu
Apr 02, 2024 am 11:31 AM
SOTA baharu untuk keupayaan memahami dokumen multimodal! Pasukan Alibaba mPLUG mengeluarkan kerja sumber terbuka terkini mPLUG-DocOwl1.5, yang mencadangkan satu siri penyelesaian untuk menangani empat cabaran utama pengecaman teks imej resolusi tinggi, pemahaman struktur dokumen am, arahan mengikut dan pengenalan pengetahuan luaran. Tanpa berlengah lagi, mari kita lihat kesannya dahulu. Pengecaman satu klik dan penukaran carta dengan struktur kompleks ke dalam format Markdown: Carta gaya berbeza tersedia: Pengecaman dan kedudukan teks yang lebih terperinci juga boleh dikendalikan dengan mudah: Penjelasan terperinci tentang pemahaman dokumen juga boleh diberikan: Anda tahu, "Pemahaman Dokumen " pada masa ini Senario penting untuk pelaksanaan model bahasa yang besar. Terdapat banyak produk di pasaran untuk membantu pembacaan dokumen. Sesetengah daripada mereka menggunakan sistem OCR untuk pengecaman teks dan bekerjasama dengan LLM untuk pemprosesan teks.
 Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
FP8 dan ketepatan pengiraan titik terapung yang lebih rendah bukan lagi "paten" H100! Lao Huang mahu semua orang menggunakan INT8/INT4, dan pasukan Microsoft DeepSpeed memaksa diri mereka menjalankan FP6 pada A100 tanpa sokongan rasmi daripada Nvidia. Keputusan ujian menunjukkan bahawa kaedah baharu TC-FPx FP6 kuantisasi pada A100 adalah hampir atau kadangkala lebih pantas daripada INT4, dan mempunyai ketepatan yang lebih tinggi daripada yang terakhir. Selain itu, terdapat juga sokongan model besar hujung ke hujung, yang telah bersumberkan terbuka dan disepadukan ke dalam rangka kerja inferens pembelajaran mendalam seperti DeepSpeed. Keputusan ini juga mempunyai kesan serta-merta pada mempercepatkan model besar - di bawah rangka kerja ini, menggunakan satu kad untuk menjalankan Llama, daya pemprosesan adalah 2.65 kali lebih tinggi daripada dua kad. satu
 1.3ms mengambil masa 1.3ms! Seni bina rangkaian neural mudah alih sumber terbuka terbaru Tsinghua RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms mengambil masa 1.3ms! Seni bina rangkaian neural mudah alih sumber terbuka terbaru Tsinghua RepViT
Mar 11, 2024 pm 12:07 PM
Alamat kertas: https://arxiv.org/abs/2307.09283 Alamat kod: https://github.com/THU-MIG/RepViTRepViT berprestasi baik dalam seni bina ViT mudah alih dan menunjukkan kelebihan yang ketara. Seterusnya, kami meneroka sumbangan kajian ini. Disebutkan dalam artikel bahawa ViT ringan biasanya berprestasi lebih baik daripada CNN ringan pada tugas visual, terutamanya disebabkan oleh modul perhatian diri berbilang kepala (MSHA) mereka yang membolehkan model mempelajari perwakilan global. Walau bagaimanapun, perbezaan seni bina antara ViT ringan dan CNN ringan belum dikaji sepenuhnya. Dalam kajian ini, penulis menyepadukan ViT ringan ke dalam yang berkesan
 Baru dikeluarkan! Model sumber terbuka untuk menghasilkan imej gaya anime dengan satu klik
Apr 08, 2024 pm 06:01 PM
Baru dikeluarkan! Model sumber terbuka untuk menghasilkan imej gaya anime dengan satu klik
Apr 08, 2024 pm 06:01 PM
Izinkan saya memperkenalkan kepada anda projek sumber terbuka AIGC terkini-AnimagineXL3.1. Projek ini adalah lelaran terkini model teks-ke-imej bertema anime, yang bertujuan untuk menyediakan pengguna pengalaman penjanaan imej anime yang lebih optimum dan berkuasa. Dalam AnimagineXL3.1, pasukan pembangunan menumpukan pada mengoptimumkan beberapa aspek utama untuk memastikan model mencapai tahap prestasi dan kefungsian yang baharu. Pertama, mereka mengembangkan data latihan untuk memasukkan bukan sahaja data watak permainan daripada versi sebelumnya, tetapi juga data daripada banyak siri anime terkenal lain ke dalam set latihan. Langkah ini memperkayakan pangkalan pengetahuan model, membolehkannya memahami pelbagai gaya dan watak anime dengan lebih lengkap. AnimagineXL3.1 memperkenalkan set teg khas dan estetika baharu
