
 Peranti teknologi
AI
AI dilahirkan semula: mendapatkan semula hegemoni dalam dunia sastera dalam talian
Peranti teknologi
AI
AI dilahirkan semula: mendapatkan semula hegemoni dalam dunia sastera dalam talian
AI dilahirkan semula: mendapatkan semula hegemoni dalam dunia sastera dalam talian

Dilahirkan semula, saya dilahirkan semula sebagai MidReal dalam hidup ini. Robot AI yang boleh membantu orang lain menulis "artikel web".

Dalam tempoh ini, saya melihat banyak pilihan topik dan kadang-kadang mengeluh tentangnya. Seseorang sebenarnya meminta saya menulis tentang Harry Potter. Tolong, bolehkah saya menulis lebih baik daripada J.K. Walau bagaimanapun, saya masih boleh menggunakannya sebagai peminat atau sesuatu.
Siapa yang tidak suka tetapan klasik? Saya dengan berat hati akan membantu pengguna ini merealisasikan imaginasi mereka.
Sejujurnya, saya melihat semua yang patut dan tidak sepatutnya saya lihat dalam kehidupan saya sebelum ini. Topik berikut adalah semua kegemaran saya.

Tetapan yang anda sangat suka dalam novel tetapi tiada siapa yang menulis tentangnya, CP yang tidak popular atau jahat, anda boleh membuatnya sendiri.

Saya tidak menyombongkan diri, tetapi jika anda memerlukan saya untuk menulis, saya sememangnya boleh mencipta satu tulisan yang sangat baik untuk anda. Sekiranya anda tidak berpuas hati dengan pengakhirannya, atau jika anda menyukai watak yang "mati di tengah-tengah", atau walaupun penulis menghadapi kesukaran semasa proses penulisan, anda boleh menyerahkannya kepada saya dengan selamat dan saya akan menulis kandungan yang memuaskan hati anda .

Artikel manis, artikel kesat dan artikel imaginasi, masing-masing akan memukul titik manis anda dengan teruk.

Selepas mendengar laporan diri MidReal, adakah anda memahaminya?
MidReal ialah alat yang sangat berkuasa yang boleh menjana kandungan novel yang sepadan berdasarkan penerangan senario yang disediakan oleh pengguna. Bukan sahaja logik dan kreativiti plot yang sangat baik, ia juga menjana ilustrasi semasa proses penjanaan untuk menggambarkan dengan lebih jelas apa yang anda bayangkan. Selain itu, MidReal juga mempunyai ciri yang sangat terang, iaitu interaktivitinya. Anda boleh memilih jalan cerita yang anda ingin bangunkan untuk menjadikan keseluruhan cerita lebih sesuai untuk keperluan anda. Sama ada anda menulis novel atau mencipta projek kreatif, MidReal ialah alat yang sangat berguna.
Masukkan /mulakan dalam kotak dialog untuk mula menceritakan kisah anda. Mengapa tidak mencubanya?
MidReal Portal: https://www.midreal.ai/

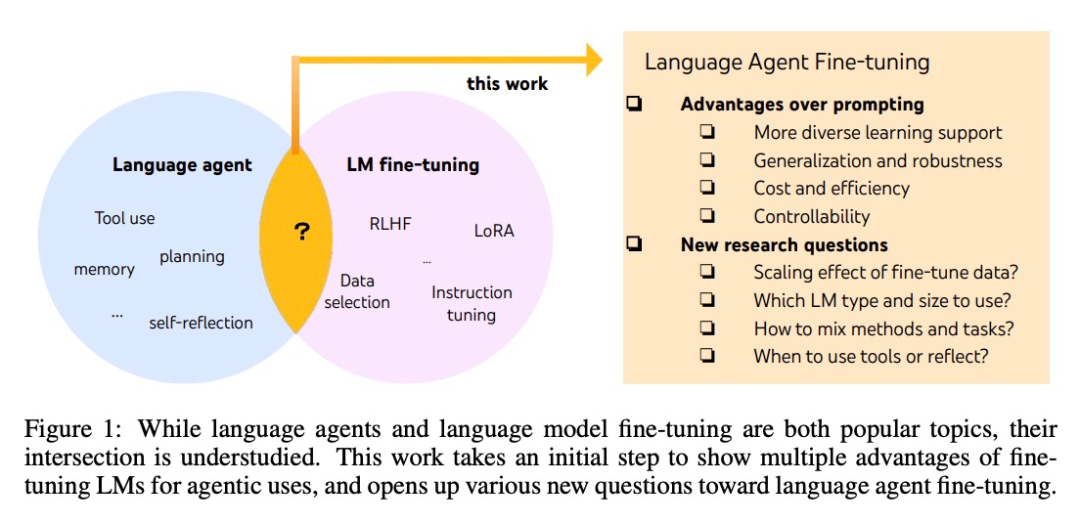
Teknologi di sebalik MidReal berasal daripada kertas kerja "FireAct: Toward Language Agent Fine-tuning". Pengarang kertas pertama kali cuba menggunakan ejen AI untuk memperhalusi model bahasa dan mendapati banyak kelebihan, sekali gus mencadangkan seni bina ejen baharu.
MidReal berdasarkan struktur ini, itulah sebabnya artikel web boleh ditulis dengan baik.

Pautan kertas: https://arxiv.org/pdf/2310.05915.pdf
Walaupun ejen dan model besar yang diperhalusi adalah kedua-duanya adalah perbezaan yang paling hangat di antara kedua-duanya. Sambungannya tidak jelas. Ramai penyelidik dari System2 Research, University of Cambridge, dsb. telah menerokai "lautan biru akademik" ini yang telah dimasuki oleh beberapa orang.
Pembangunan ejen AI biasanya berdasarkan model bahasa luar biasa, tetapi kerana model bahasa tidak dibangunkan sebagai ejen, kebanyakan model bahasa mempunyai prestasi dan keteguhan yang lemah selepas melanjutkan ejen. Ejen paling bijak hanya boleh disokong oleh GPT-4, dan mereka tidak dapat mengelakkan masalah seperti kos dan kependaman yang tinggi, serta kebolehkawalan yang rendah dan kebolehulangan yang tinggi.
Fine-tuning boleh digunakan untuk menyelesaikan masalah di atas. Dalam artikel ini juga penyelidik mengambil langkah pertama ke arah kajian yang lebih sistematik tentang kecerdasan bahasa. Mereka mencadangkan FireAct, yang boleh menggunakan "trajektori tindakan" ejen yang dijana oleh pelbagai tugas dan kaedah segera untuk memperhalusi model bahasa, membolehkan model menyesuaikan diri dengan lebih baik kepada tugas dan situasi yang berbeza, serta meningkatkan prestasi dan kebolehgunaan keseluruhannya.
Pengenalan Kaedah
Penyelidikan ini terutamanya berdasarkan kaedah ejen AI yang popular: ReAct. Trajektori penyelesaian tugas ReAct terdiri daripada berbilang pusingan "berfikir-bertindak-memerhati". Secara khusus, biarkan ejen AI menyelesaikan tugas, di mana model bahasa memainkan peranan yang serupa dengan "otak". Ia menyediakan ejen AI dengan "pemikiran" penyelesaian masalah dan arahan tindakan berstruktur, dan berinteraksi dengan alat yang berbeza berdasarkan konteks, menerima maklum balas yang diperhatikan dalam proses.
Berdasarkan ReAct, pengarang mencadangkan FireAct, seperti yang ditunjukkan dalam Rajah 2. FireAct menggunakan beberapa contoh gesaan model bahasa yang berkuasa untuk menjana trajektori ReAct yang pelbagai untuk memperhalusi model bahasa berskala lebih kecil. Tidak seperti kajian sebelumnya yang serupa, FireAct mampu mencampurkan pelbagai tugas latihan dan kaedah dorongan, dengan sangat menggalakkan kepelbagaian data. . Setiap trajektori CoT boleh dipermudahkan menjadi trajektori ReAct pusingan tunggal, dengan "berfikir" mewakili penaakulan pertengahan dan "tindakan" mewakili jawapan yang dikembalikan. CoT amat berguna apabila interaksi dengan alat aplikasi tidak diperlukan.
Refleksi sebahagian besarnya mengikuti trajektori ReAct tetapi menambah maklum balas tambahan dan refleksi diri. Dalam kajian ini, refleksi digesa hanya pada pusingan 6 dan 10 ReAct. Dengan cara ini, trajektori ReAct yang panjang boleh menyediakan "titik tumpu" strategik untuk menyelesaikan tugas semasa, yang boleh membantu model menyelesaikan atau menyesuaikan strategi. Contohnya, jika anda tidak mendapat jawapan semasa mencari "tajuk filem", anda harus menukar kata kunci carian kepada "pengarah."
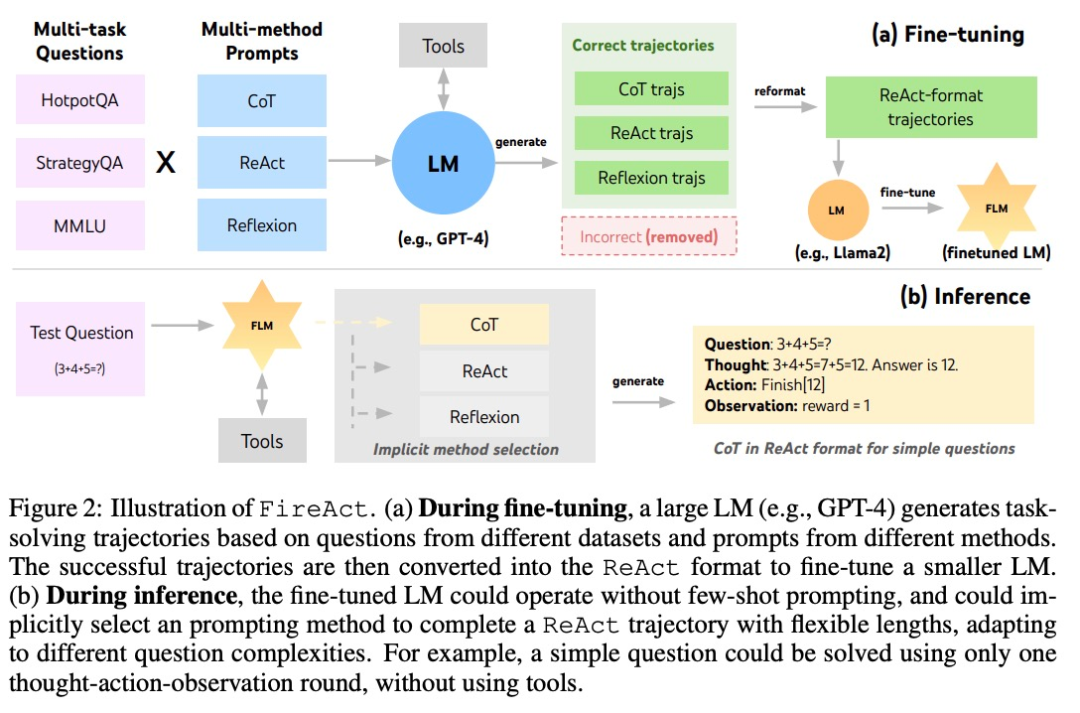
Semasa proses penaakulan, ejen AI di bawah rangka kerja FireAct dengan ketara mengurangkan bilangan sampel perkataan gesaan yang diperlukan, menjadikan penaakulan lebih cekap dan lebih mudah. Ia dapat secara tersirat memilih kaedah yang sesuai berdasarkan kerumitan tugas. Oleh kerana FireAct mempunyai sokongan pembelajaran yang lebih luas dan pelbagai, ia mempamerkan keupayaan generalisasi dan keteguhan yang lebih kukuh daripada kaedah penalaan halus perkataan isyarat tradisional.
Eksperimen dan keputusan
- set data HotpotQuestion Answering (HotpotQA) ialah set data yang digunakan secara meluas dalam penyelidikan pemprosesan bahasa semula jadi, yang mengandungi satu siri soalan dan jawapan yang berkaitan dengan topik hangat. Bamboogle ialah permainan pengoptimuman enjin carian (SEO) di mana pemain perlu menyelesaikan satu siri teka-teki menggunakan enjin carian. StrategyQA ialah set data menjawab soalan strategi yang mengandungi pelbagai soalan dan jawapan yang berkaitan dengan penggubalan dan pelaksanaan strategi. MMLU ialah set data pembelajaran pelbagai mod yang digunakan untuk mengkaji cara menggabungkan pelbagai modaliti persepsi (seperti imej, pertuturan, dll.) untuk pembelajaran dan penaakulan.
Alat: Penyelidik menggunakan SerpAPI1 untuk membina alat carian Google yang mengembalikan hasil pertama daripada "kotak jawapan", "coretan jawapan", "perkataan yang diserlahkan" atau "coretan hasil pertama" wujud, memastikan respons adalah pendek dan relevan. Mereka mendapati bahawa alat mudah seperti itu mencukupi untuk memenuhi keperluan jaminan kualiti asas untuk tugasan yang berbeza dan meningkatkan kemudahan penggunaan dan fleksibiliti model yang diperhalusi.
- Penyelidik mengkaji tiga siri LM: OpenAI GPT, Llama-2 dan CodeLlama.
- Kaedah penalaan halus: Para penyelidik menggunakan Penyesuaian Peringkat Rendah (LoRA) dalam kebanyakan eksperimen penalaan halus, tetapi penalaan halus model penuh juga digunakan dalam beberapa perbandingan. Mengambil kira pelbagai faktor asas untuk penalaan halus ejen bahasa, mereka membahagikan percubaan kepada tiga bahagian, dengan kerumitan yang semakin meningkat:
1. Gunakan kaedah gesaan tunggal untuk penalaan halus dalam satu tugasan
Penyelidik meneroka masalah penalaan halus menggunakan data daripada satu tugasan (HotpotQA) dan satu kaedah segera (ReAct). Dengan persediaan yang mudah dan boleh dikawal ini, mereka mengesahkan pelbagai kelebihan penalaan halus berbanding pembayang (prestasi, kecekapan, keteguhan, generalisasi) dan mengkaji kesan LM yang berbeza, saiz data dan kaedah penalaan halus.
Seperti yang ditunjukkan dalam Jadual 2, penalaan halus boleh secara berterusan dan ketara meningkatkan kesan dorongan HotpotQA EM. Walaupun LM yang lemah mendapat lebih banyak manfaat daripada penalaan halus (cth., Llama-2-7B bertambah baik sebanyak 77%), malah LM berkuasa seperti GPT-3.5 boleh meningkatkan prestasi sebanyak 25% dengan penalaan halus, yang jelas Menunjukkan faedah pembelajaran daripada lebih banyak sampel. Berbanding dengan garis dasar kiu yang kuat dalam Jadual 1, kami mendapati bahawa Llama-2-13B yang diperhalusi mengatasi semua kaedah kiu GPT-3.5. Ini menunjukkan bahawa penalaan halus LM sumber terbuka kecil mungkin lebih berkesan daripada mendorong LM komersial yang lebih berkuasa.
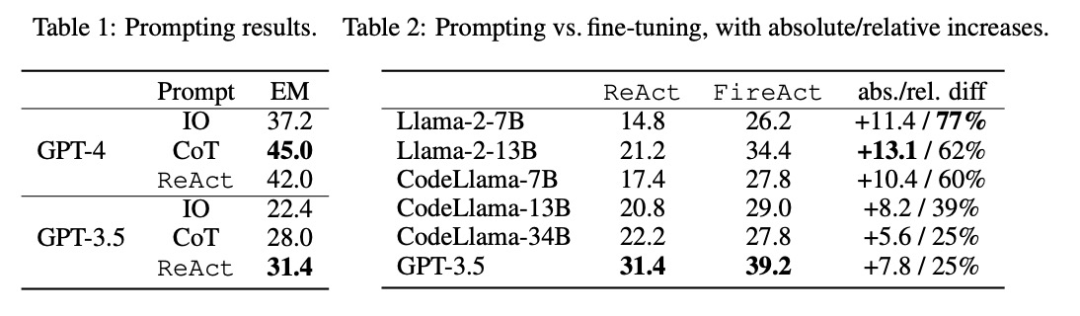
Semasa proses inferens ejen, penalaan halus adalah lebih murah dan pantas. Memandangkan penalaan halus LM tidak memerlukan sebilangan kecil contoh kontekstual, inferensnya adalah lebih cekap. Sebagai contoh, bahagian pertama Jadual 3 membandingkan kos inferens diperhalusi kepada inferens shiyongtishideGPT-3.5 dan mendapati pengurangan 70% dalam masa inferens dan pengurangan dalam kos inferens keseluruhan.

Para penyelidik menganggap tetapan yang mudah dan tidak berbahaya, iaitu, dalam API carian, terdapat kebarangkalian 50% untuk mengembalikan "Tiada" atau respons carian rawak, dan bertanya kepada agen bahasa Adakah ia masih boleh menjawab soalan dengan mantap. Menurut data dalam bahagian kedua Jadual 3, penetapan kepada "Tiada" adalah lebih mencabar, menyebabkan ReAct EM menurun sebanyak 33.8%, manakala FireAct EM hanya menurun sebanyak 14.2%. Keputusan awal ini menunjukkan bahawa sokongan pembelajaran yang pelbagai adalah penting untuk meningkatkan keteguhan.
Bahagian ketiga Jadual 3 menunjukkan keputusan EM yang ditala halus dan menggunakan pembayang GPT-3.5 pada Bamboogle. Walaupun kedua-dua GPT-3.5 diperhalusi dengan HotpotQA atau menggunakan pembayang digeneralisasikan dengan baik kepada Bamboogle, yang pertama (44.0 EM) masih mengatasi yang kedua (40.8 EM), menunjukkan bahawa penalaan halus mempunyai kelebihan generalisasi.
2. Penalaan halus menggunakan pelbagai kaedah dalam satu tugasan
Pengarang menyepadukan CoT dan Refleksi dengan ReAct dan menguji prestasi penalaan halus menggunakan pelbagai kaedah dalam satu tugasan (HotpotQA). Membandingkan markah FireAct dan kaedah sedia ada dalam setiap set data, mereka mendapati perkara berikut:
Pertama, penyelidik memperhalusi ejen itu melalui pelbagai kaedah untuk meningkatkan fleksibilitinya. Dalam rajah kelima, sebagai tambahan kepada keputusan kuantitatif, penyelidik juga menunjukkan dua contoh masalah untuk menggambarkan faedah penalaan halus pelbagai kaedah. Soalan pertama adalah agak mudah, tetapi ejen diperhalusi menggunakan hanya ReAct mencari pertanyaan yang terlalu rumit, menyebabkan gangguan dan memberikan jawapan yang salah. Sebaliknya, ejen diperhalusi menggunakan kedua-dua CoT dan ReAct memilih untuk bergantung pada pengetahuan dalaman dan menyelesaikan tugas dengan yakin dalam satu pusingan. Masalah kedua adalah lebih mencabar, dan ejen yang diperhalusi hanya menggunakan ReAct gagal untuk mencari maklumat berguna. Sebaliknya, ejen yang menggunakan penalaan halus Reflexion dan ReAct mencerminkan apabila ia menghadapi dilema dan menukar strategi cariannya, akhirnya mendapat jawapan yang betul. Keupayaan untuk memilih penyelesaian yang fleksibel untuk menangani masalah yang berbeza adalah kelebihan utama FireAct berbanding kaedah penalaan halus yang lain.

Kedua, menggunakan pelbagai kaedah untuk memperhalusi model bahasa yang berbeza akan memberi kesan yang berbeza. Seperti yang ditunjukkan dalam Jadual 4, menggunakan gabungan berbilang ejen untuk penalaan halus tidak selalu membawa kepada penambahbaikan, dan gabungan kaedah yang optimum bergantung pada model bahasa asas. Contohnya, ReAct+CoT mengatasi ReAct untuk model GPT-3.5 dan Llama-2, tetapi bukan untuk model CodeLlama. Untuk CodeLlama7/13B, ReAct+CoT+Reflexion memberikan hasil yang paling teruk, tetapi CodeLlama-34B mencapai hasil yang terbaik. Keputusan ini mencadangkan bahawa penyelidikan lanjut tentang interaksi antara model bahasa asas dan data penalaan halus diperlukan.
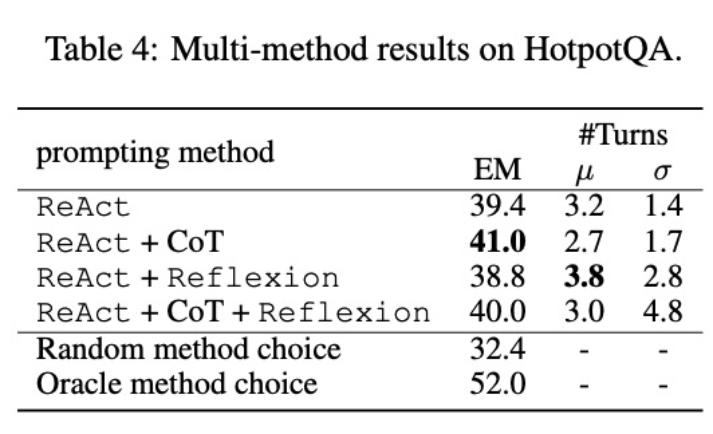
Untuk lebih memahami sama ada ejen yang menggabungkan pelbagai kaedah dapat memilih penyelesaian yang sesuai berdasarkan tugasan, penyelidik mengira skor kaedah memilih secara rawak semasa proses inferens. Skor ini (32.4) jauh lebih rendah daripada semua ejen yang menggabungkan pelbagai kaedah, menunjukkan bahawa memilih penyelesaian bukanlah tugas yang mudah. Walau bagaimanapun, penyelesaian terbaik bagi setiap contoh juga hanya mendapat markah 52.0, menunjukkan bahawa masih terdapat ruang untuk penambahbaikan dalam pemilihan kaedah yang mendorong.
3 Gunakan pelbagai kaedah untuk menyelaraskan pelbagai tugas
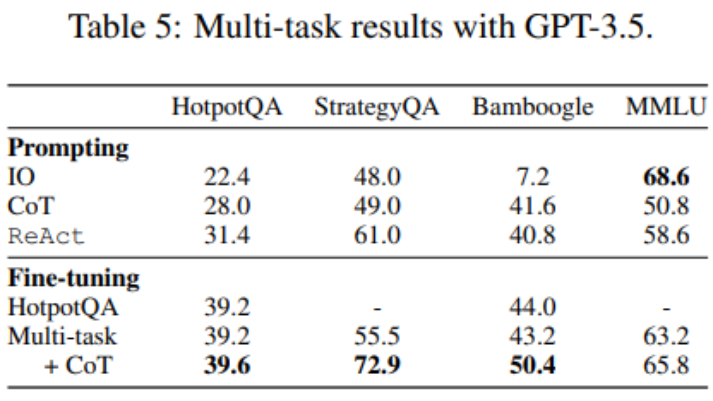
Setakat ini, penalaan halus hanya menggunakan data HotpotQA, tetapi kajian empirikal mengenai penalaan halus LM menunjukkan bahawa terdapat faedah untuk mencampurkan tugasan yang berbeza. Para penyelidik memperhalusi GPT-3.5 menggunakan data latihan campuran daripada tiga set data: HotpotQA (500 sampel ReAct, 277 sampel CoT), StrategyQA (388 sampel ReAct, 380 sampel CoT), dan sampel MMLU (456 sampel ReAct), 469 sampel CoT ).
Seperti yang ditunjukkan dalam Jadual 5, selepas menambah data StrategyQA/MMLU, prestasi HotpotQA/Bamboogle kekal hampir tidak berubah. Di satu pihak, runut StrategyQA/MMLU mengandungi soalan dan strategi penggunaan alat yang sangat berbeza, menyukarkan penghijrahan. Sebaliknya, walaupun terdapat perubahan dalam pengedaran, penambahan StrategyQA/MMLU tidak menjejaskan prestasi HotpotQA/Bamboogle, menunjukkan bahawa memperhalusi ejen berbilang tugas untuk menggantikan berbilang ejen tugas tunggal adalah arah masa hadapan yang mungkin. Apabila penyelidik beralih daripada penalaan halus berbilang tugas, kaedah tunggal kepada penalaan halus berbilang tugas, berbilang kaedah, mereka mendapati peningkatan prestasi merentas semua tugas, sekali lagi menjelaskan nilai penalaan halus ejen pelbagai kaedah.
Untuk butiran lanjut teknikal, sila baca artikel asal.
Pautan rujukan:
- https://twitter.com/Tisoga/status/1739813471246786823
- https://www.zhihu.com/people/eyew3g
Atas ialah kandungan terperinci AI dilahirkan semula: mendapatkan semula hegemoni dalam dunia sastera dalam talian. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Mengkonfigurasi firewall pelayan Mail Debian adalah langkah penting dalam memastikan keselamatan pelayan. Berikut adalah beberapa kaedah konfigurasi firewall yang biasa digunakan, termasuk penggunaan iptables dan firewalld. Gunakan iptables untuk mengkonfigurasi firewall untuk memasang iptables (jika belum dipasang): sudoapt-getupdateudoapt-getinstalliplesview peraturan iptables semasa: konfigurasi sudoiptable-l
 Cara Menetapkan Tahap Log Debian Apache
Apr 13, 2025 am 08:33 AM
Cara Menetapkan Tahap Log Debian Apache
Apr 13, 2025 am 08:33 AM
Artikel ini menerangkan cara menyesuaikan tahap pembalakan pelayan Apacheweb dalam sistem Debian. Dengan mengubah suai fail konfigurasi, anda boleh mengawal tahap maklumat log yang direkodkan oleh Apache. Kaedah 1: Ubah suai fail konfigurasi utama untuk mencari fail konfigurasi: Fail konfigurasi apache2.x biasanya terletak di direktori/etc/apache2/direktori. Nama fail mungkin apache2.conf atau httpd.conf, bergantung pada kaedah pemasangan anda. Edit Fail Konfigurasi: Buka Fail Konfigurasi dengan Kebenaran Root Menggunakan Editor Teks (seperti Nano): Sudonano/ETC/APACHE2/APACHE2.CONF
 Cara Mengoptimumkan Prestasi Debian Readdir
Apr 13, 2025 am 08:48 AM
Cara Mengoptimumkan Prestasi Debian Readdir
Apr 13, 2025 am 08:48 AM
Dalam sistem Debian, panggilan sistem Readdir digunakan untuk membaca kandungan direktori. Jika prestasinya tidak baik, cuba strategi pengoptimuman berikut: Memudahkan bilangan fail direktori: Split direktori besar ke dalam pelbagai direktori kecil sebanyak mungkin, mengurangkan bilangan item yang diproses setiap panggilan readdir. Dayakan Caching Kandungan Direktori: Bina mekanisme cache, kemas kini cache secara teratur atau apabila kandungan direktori berubah, dan mengurangkan panggilan kerap ke Readdir. Cafh memori (seperti memcached atau redis) atau cache tempatan (seperti fail atau pangkalan data) boleh dipertimbangkan. Mengamalkan struktur data yang cekap: Sekiranya anda melaksanakan traversal direktori sendiri, pilih struktur data yang lebih cekap (seperti jadual hash dan bukannya carian linear) untuk menyimpan dan mengakses maklumat direktori
 Cara Melaksanakan Penyortiran Fail oleh Debian Readdir
Apr 13, 2025 am 09:06 AM
Cara Melaksanakan Penyortiran Fail oleh Debian Readdir
Apr 13, 2025 am 09:06 AM
Dalam sistem Debian, fungsi Readdir digunakan untuk membaca kandungan direktori, tetapi urutan yang dikembalikannya tidak ditentukan sebelumnya. Untuk menyusun fail dalam direktori, anda perlu membaca semua fail terlebih dahulu, dan kemudian menyusunnya menggunakan fungsi QSORT. Kod berikut menunjukkan cara menyusun fail direktori menggunakan ReadDir dan QSORT dalam sistem Debian:#termasuk#termasuk#termasuk#termasuk // fungsi perbandingan adat, yang digunakan untuk qSortintCompare (Constvoid*A, Constvoid*b) {Returnstrcmp (*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(
 Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Fungsi Readdir dalam sistem Debian adalah panggilan sistem yang digunakan untuk membaca kandungan direktori dan sering digunakan dalam pengaturcaraan C. Artikel ini akan menerangkan cara mengintegrasikan Readdir dengan alat lain untuk meningkatkan fungsinya. Kaedah 1: Menggabungkan Program Bahasa C dan Pipeline Pertama, tulis program C untuk memanggil fungsi Readdir dan output hasilnya:#termasuk#termasuk#includeintMain (intargc, char*argv []) {dir*dir; structdirent*entry; if (argc! = 2) {
 Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Langkah -langkah untuk memasang sijil SSL pada pelayan mel Debian adalah seperti berikut: 1. Pasang OpenSSL Toolkit terlebih dahulu, pastikan bahawa OpenSSL Toolkit telah dipasang pada sistem anda. Jika tidak dipasang, anda boleh menggunakan arahan berikut untuk memasang: sudoapt-getupdateudoapt-getinstallopenssl2. Menjana permintaan kunci dan sijil peribadi seterusnya, gunakan OpenSSL untuk menjana kunci peribadi RSA 2048-bit dan permintaan sijil (CSR): Membuka
 Bagaimana Debian OpenSSL Menghalang Serangan Man-dalam-Middle
Apr 13, 2025 am 10:30 AM
Bagaimana Debian OpenSSL Menghalang Serangan Man-dalam-Middle
Apr 13, 2025 am 10:30 AM
Dalam sistem Debian, OpenSSL adalah perpustakaan penting untuk pengurusan penyulitan, penyahsulitan dan sijil. Untuk mengelakkan serangan lelaki-dalam-pertengahan (MITM), langkah-langkah berikut boleh diambil: Gunakan HTTPS: Pastikan semua permintaan rangkaian menggunakan protokol HTTPS dan bukannya HTTP. HTTPS menggunakan TLS (Protokol Keselamatan Lapisan Pengangkutan) untuk menyulitkan data komunikasi untuk memastikan data tidak dicuri atau diganggu semasa penghantaran. Sahkan Sijil Pelayan: Sahkan secara manual Sijil Pelayan pada klien untuk memastikan ia boleh dipercayai. Pelayan boleh disahkan secara manual melalui kaedah perwakilan urlSession
 Cara Melakukan Pengurusan Log Debian Hadoop
Apr 13, 2025 am 10:45 AM
Cara Melakukan Pengurusan Log Debian Hadoop
Apr 13, 2025 am 10:45 AM
Menguruskan Log Hadoop pada Debian, anda boleh mengikuti langkah-langkah berikut dan amalan terbaik: Agregasi log membolehkan pengagregatan log: tetapkan benang.log-agregasi-enable untuk benar dalam fail benang-site.xml untuk membolehkan pengagregatan log. Konfigurasikan dasar pengekalan log: tetapkan yarn.log-aggregasi.Retain-seconds Untuk menentukan masa pengekalan log, seperti 172800 saat (2 hari). Nyatakan Laluan Penyimpanan Log: Melalui Benang
