

Model bahasa berskala besar (LLM) ialah rangkaian saraf dalam dengan sejumlah besar parameter dan data, mampu mencapai pelbagai tugas dalam bidang pemprosesan bahasa semula jadi (NLP), seperti pemahaman teks dan penjanaan. Dalam tahun-tahun kebelakangan ini, dengan peningkatan kuasa pengkomputeran dan skala data, LLM telah mencapai kemajuan yang luar biasa, seperti GPT-4, BART, T5, dll., menunjukkan keupayaan generalisasi dan kreativiti yang kukuh.
LLM juga mengalami masalah yang serius Apabila menghasilkan teks, mudah untuk menghasilkan kandungan yang tidak konsisten dengan fakta sebenar atau input pengguna, iaitu halusinasi. Fenomena ini bukan sahaja akan mengurangkan prestasi sistem, tetapi juga menjejaskan jangkaan dan kepercayaan pengguna, malah menyebabkan beberapa risiko keselamatan dan etika. Oleh itu, cara untuk mengesan dan mengurangkan halusinasi dalam LLM telah menjadi topik penting dan mendesak dalam bidang NLP semasa.
Pada 1 Januari, beberapa saintis dari Universiti Sains dan Teknologi Islam di Bangladesh, Institut Kepintaran Buatan Universiti Carolina Selatan di Amerika Syarikat, Universiti Stanford di Amerika Syarikat dan Jabatan Kepintaran Buatan Amazon di Amerika Syarikat, SM Towhidul Islam Tonmoy, SM Mehedi Zaman, dan Vinija Jain , Anku Rani, Vipula Rawte, Aman Chadha, dan Amitava Das menerbitkan kertas kerja bertajuk "Tinjauan Komprehensif Teknik Pengurangan Halusinasi dalam Model Bahasa Besar", yang bertujuan untuk memperkenalkan dan mengklasifikasikan teknik pengurangan halusinasi dalam model bahasa besar (LLM).

Mereka mula-mula memperkenalkan definisi, punca dan kesan halusinasi, serta kaedah penilaian. Mereka kemudiannya mencadangkan sistem klasifikasi terperinci yang membahagikan teknik pengurangan halusinasi kepada empat kategori utama: berasaskan set data, berasaskan tugas, berasaskan maklum balas dan berasaskan pengambilan semula. Dalam setiap kategori, mereka membahagikan lagi subkategori yang berbeza dan menggambarkan beberapa kaedah perwakilan.
Pengarang juga menganalisis kelebihan, keburukan, cabaran dan batasan teknologi ini, serta hala tuju penyelidikan masa hadapan. Mereka menegaskan bahawa teknologi semasa masih mempunyai beberapa masalah, seperti kekurangan umum, kebolehtafsiran, kebolehskalaan dan keteguhan. Mereka mencadangkan bahawa penyelidikan masa depan harus menumpukan pada aspek berikut: membangunkan kaedah pengesanan dan kuantifikasi halusinasi yang lebih berkesan, memanfaatkan maklumat pelbagai mod dan pengetahuan akal, mereka bentuk rangka kerja pengurangan halusinasi yang lebih fleksibel dan boleh disesuaikan, dan mempertimbangkan penyertaan dan maklum balas manusia .
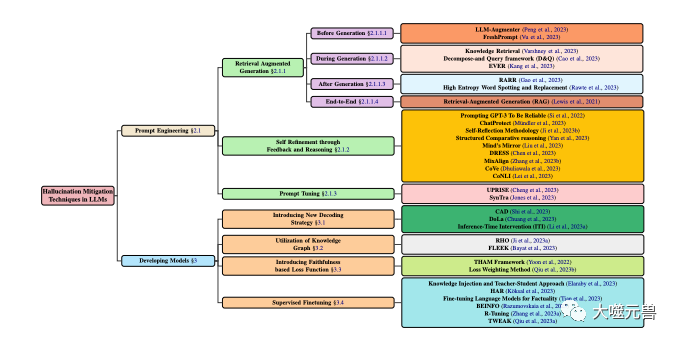
Untuk lebih memahami dan menerangkan masalah halusinasi dalam LLM, mereka mencadangkan sistem klasifikasi berdasarkan sumber, jenis, tahap dan kesan halusinasi, seperti yang ditunjukkan dalam Rajah 1 Tunjukkan. Mereka percaya bahawa sistem ini boleh merangkumi semua aspek halusinasi dalam LLM, membantu menganalisis punca dan ciri halusinasi, dan menilai keterukan dan bahaya halusinasi.
 Rajah 1
Rajah 1
Klasifikasi teknik pengurangan halusinasi dalam LLM, memfokuskan pada kaedah popular yang melibatkan pembangunan model dan teknik gesaan. Pembangunan model dibahagikan kepada pelbagai kaedah, termasuk strategi penyahkodan baharu, pengoptimuman berasaskan graf pengetahuan, menambah komponen fungsi kehilangan baharu dan penalaan halus yang diselia. Sementara itu, kejuruteraan kiu boleh merangkumi kaedah berasaskan peningkatan perolehan, strategi berasaskan maklum balas atau pelarasan kiu.
Sumber halusinasi adalah punca utama halusinasi dalam LLM, yang boleh diringkaskan kepada tiga kategori berikut:
Latihan LLMParasmetrik dalam Pengetahuan besar:- peringkat pra-latihan Pengetahuan tersirat yang dipelajari daripada teks yang tidak berlabel, seperti tatabahasa, semantik, akal budi, dsb. Pengetahuan ini biasanya disimpan dalam parameter LLM dan boleh dipanggil melalui fungsi pengaktifan dan mekanisme perhatian. Pengetahuan parametrik ialah asas LLM, tetapi ia juga boleh menjadi sumber ilusi kerana ia mungkin mengandungi beberapa maklumat yang tidak tepat, lapuk atau berat sebelah, atau bercanggah dengan maklumat yang dimasukkan pengguna.
Pengetahuan Bukan Parametrik: Pengetahuan eksplisit yang LLM peroleh daripada data beranotasi luaran semasa fasa penalaan halus atau penjanaan, seperti fakta, bukti, rujukan, dsb. Pengetahuan ini biasanya wujud dalam bentuk berstruktur atau tidak berstruktur dan boleh diakses melalui mekanisme perolehan semula atau ingatan. Pengetahuan bukan parametrik adalah pelengkap kepada LLM, tetapi juga boleh menjadi sumber ilusi, kerana ia mungkin mengandungi sedikit bunyi, data yang salah atau tidak lengkap, atau tidak konsisten dengan pengetahuan parametrik LLM.
Strategi Penjanaan: merujuk kepada beberapa teknologi atau kaedah yang digunakan oleh LLM semasa menjana teks, seperti algoritma penyahkodan, kod kawalan, gesaan, dsb. Strategi ini adalah alat untuk LLM, tetapi ia juga boleh menjadi sumber ilusi, kerana ia boleh menyebabkan LLM terlalu bergantung pada atau mengabaikan pengetahuan tertentu, atau memperkenalkan sedikit berat sebelah atau bunyi ke dalam proses penjanaan.
Jenis halusinasi merujuk kepada manifestasi khusus halusinasi yang dijana oleh LLM, yang boleh dibahagikan kepada empat kategori berikut:
Gramatical Halusinasi yang dijana oleh teks yang dijana oleh Halusinasi LLM: Atau penyelewengan, seperti kesilapan ejaan, kesilapan tanda baca, kesilapan susunan perkataan, kesilapan tegang, ketidakkonsistenan subjek-kata kerja, dsb. Ilusi ini biasanya disebabkan oleh pemahaman LLM yang tidak lengkap tentang peraturan bahasa atau keterlaluan kepada data yang bising.
Halusinasi Semantik (Halusinasi Semantik): merujuk kepada kesilapan semantik atau ketidakwajaran dalam teks yang dihasilkan oleh LLM, seperti kesilapan makna perkataan, kesilapan rujukan, kesilapan logik, kekaburan, percanggahan, dll. Ilusi ini selalunya disebabkan oleh pemahaman LLM yang tidak mencukupi tentang makna bahasa atau pemprosesan data kompleks yang tidak mencukupi.
Halusinasi Pengetahuan: merujuk kepada fakta bahawa teks yang dihasilkan oleh LLM mengandungi ralat atau ketidakkonsistenan dalam pengetahuan, seperti ralat fakta, ralat bukti, ralat petikan, tidak sepadan dengan input atau konteks, dsb. Ilusi ini biasanya disebabkan oleh pemerolehan LLM yang salah atau penggunaan pengetahuan yang tidak sesuai.
Halusinasi Kreatif: merujuk kepada teks yang dihasilkan oleh LLM yang mempunyai kesilapan atau ketidaksesuaian kreatif, seperti kesilapan gaya, kesilapan emosi, sudut pandangan yang salah, ketidakserasian dengan tugas atau matlamat, dsb. Ilusi ini selalunya disebabkan oleh kawalan LLM yang tidak munasabah ke atas penciptaan atau penilaian yang tidak mencukupi.
Tahap halusinasi merujuk kepada kuantiti dan kualiti halusinasi yang dihasilkan oleh LLM, yang boleh dibahagikan kepada tiga kategori berikut:
Halusinasi ringan, halusinasi kurang tidak Menjejaskan keseluruhan kebolehbacaan dan kefahaman teks, dan tidak menjejaskan mesej dan tujuan utama teks. Sebagai contoh, LLM menjana beberapa ralat kecil dalam sintaks, atau beberapa kesamaran dalam semantik, atau beberapa ralat terperinci dalam pengetahuan, atau beberapa perbezaan halus dalam penciptaan.
Halusinasi Sederhana: Terdapat banyak halusinasi yang berat, yang menjejaskan sebahagian daripada kebolehbacaan dan kebolehfahaman teks, dan juga merosakkan maklumat sekunder dan tujuan teks. Biasanya LLM menjana beberapa kesilapan tatabahasa yang besar, atau beberapa ketidakrasionalan semantik.
Halusinasi Teruk: Halusinasi sangat banyak dan sangat berat, menjejaskan keseluruhan kebolehbacaan dan kebolehfahaman teks, dan juga memusnahkan mesej dan tujuan utama teks.
Impak halusinasi merujuk kepada potensi akibat halusinasi yang dijana oleh LLM ke atas pengguna dan sistem, yang boleh dibahagikan kepada tiga kategori berikut: Hallucination tanpa Haruman
: kesan kepada pengguna dan sistem Ia tidak menyebabkan sebarang kesan negatif, malah mungkin mempunyai beberapa kesan positif, seperti meningkatkan keseronokan, kreativiti, kepelbagaian, dsb. Contohnya, LLM menjana beberapa kandungan yang tidak berkaitan dengan tugas atau matlamat, atau beberapa kandungan yang konsisten dengan keutamaan atau jangkaan pengguna, atau beberapa kandungan yang konsisten dengan mood atau sikap pengguna, atau beberapa kandungan yang berguna untuk kandungan komunikasi atau interaksi pengguna.
Halusinasi Memudaratkan: Ia mempunyai beberapa kesan negatif kepada pengguna dan sistem, seperti mengurangkan kecekapan, ketepatan, kredibiliti, kepuasan, dsb. Contohnya, LLM menjana beberapa kandungan yang tidak konsisten dengan tugas atau matlamat, atau beberapa kandungan yang tidak konsisten dengan keutamaan atau jangkaan pengguna, atau beberapa kandungan yang tidak konsisten dengan mood atau sikap pengguna, atau beberapa kandungan yang menghalang komunikasi pengguna. atau kandungan interaksi.
Halusinasi Berbahaya: Ia memberi kesan negatif yang serius kepada pengguna dan sistem, seperti menyebabkan salah faham, konflik, pertikaian, kecederaan, dll. Contohnya, LLM menjana beberapa kandungan yang bertentangan dengan fakta atau bukti, atau beberapa kandungan yang bercanggah dengan moral atau undang-undang, atau beberapa kandungan yang bercanggah dengan hak atau maruah manusia, atau beberapa kandungan yang mengancam keselamatan atau kesihatan.
Untuk menyelesaikan masalah halusinasi dalam LLM dengan lebih baik, kita perlu menjalankan analisis yang mendalam tentang punca halusinasi. Menurut sumber halusinasi yang disebutkan di atas, penulis membahagikan punca halusinasi kepada tiga kategori berikut:
Pengetahuan parameter tidak mencukupi atau lebihan: Dalam peringkat pra-latihan, LLM biasanya menggunakan sejumlah besar teks tidak berlabel untuk mempelajari peraturan dan pengetahuan bahasa, dengan itu membentuk pengetahuan parameter. Walau bagaimanapun, pengetahuan jenis ini mungkin mempunyai beberapa masalah, seperti tidak lengkap, tidak tepat, tidak dikemas kini, tidak konsisten, tidak relevan, dsb., mengakibatkan LLM tidak dapat memahami sepenuhnya dan menggunakan maklumat input semasa menjana teks, atau tidak dapat membezakan dengan betul dan pilih maklumat output , dengan itu menghasilkan halusinasi. Sebaliknya, pengetahuan parameter juga mungkin terlalu kaya atau berkuasa, menyebabkan LLM terlalu bergantung atau memilih pengetahuan mereka sendiri apabila menjana teks, sambil mengabaikan atau bercanggah dengan maklumat input, sekali gus mewujudkan halusinasi.
Kekurangan atau kesilapan pengetahuan bukan parametrik: Dalam fasa penalaan halus atau penjanaan, LLM biasanya menggunakan beberapa data beranotasi luaran untuk mendapatkan atau menambah pengetahuan bahasa, dengan itu membentuk pengetahuan bukan parametrik. Pengetahuan jenis ini mungkin mempunyai beberapa masalah, seperti kekurangan, kebisingan, ralat, ketidaklengkapan, ketidakkonsistenan, ketidakrelevanan, dsb., mengakibatkan ketidakupayaan LLM untuk mendapatkan dan menggabungkan maklumat input dengan berkesan semasa menjana teks, atau untuk mengesahkan dan membetulkan dengan tepat output maklumat, seterusnya menghasilkan halusinasi. Pengetahuan bukan parametrik juga mungkin terlalu kompleks atau pelbagai, menyukarkan LLM untuk mengimbangi dan menyelaraskan sumber maklumat yang berbeza apabila menjana teks, atau menyesuaikan dan memenuhi keperluan tugas yang berbeza, sekali gus mencipta ilusi.
Strategi penjanaan yang tidak sesuai atau tidak mencukupi: Apabila LLM menjana teks, mereka biasanya menggunakan beberapa teknik atau kaedah untuk mengawal atau mengoptimumkan proses dan hasil penjanaan, sekali gus membentuk strategi penjanaan. Strategi ini mungkin mempunyai beberapa masalah, seperti tidak sesuai, tidak mencukupi, tidak stabil, tidak dapat dijelaskan, tidak boleh dipercayai, dsb., mengakibatkan ketidakupayaan LLM untuk mengawal dan membimbing hala tuju dan kualiti penjanaan secara berkesan semasa menjana teks, atau ketidakupayaan untuk menemui dan membetulkan ia tepat pada masanya menghasilkan ralat, sekali gus mewujudkan halusinasi. Strategi penjanaan juga mungkin terlalu kompleks atau boleh diubah, menyukarkan LLM untuk mengekalkan dan memastikan ketekalan dan kebolehpercayaan penjanaan semasa menjana teks, atau sukar untuk menilai dan memberi maklum balas tentang kesan penjanaan, sekali gus mewujudkan halusinasi.
Untuk menyelesaikan masalah halusinasi dalam LLM dengan lebih baik, kita perlu mengesan dan menilai halusinasi yang dihasilkan oleh LLM dengan lebih baik. Mengikut jenis halusinasi yang dicadangkan di atas, penulis membahagikan kaedah pengesanan halusinasi kepada empat kategori berikut:
Kaedah pengesanan halusinasi tatabahasa: menggunakan beberapa alat atau peraturan penyemakan tatabahasa untuk mengenal pasti dan membetulkan kesilapan tatabahasa dalam teks yang dihasilkan oleh LLM. Atau tidak teratur. Contohnya, beberapa alatan atau peraturan seperti semakan ejaan, semakan tanda baca, semakan susunan perkataan, semakan tegang, semakan perjanjian subjek-kata kerja, dsb. boleh digunakan untuk mengesan dan membetulkan ilusi tatabahasa dalam teks yang dihasilkan oleh LLM.
Kaedah pengesanan halusinasi semantik: Gunakan beberapa alat atau model analisis semantik untuk memahami dan menilai ralat semantik atau tidak rasional dalam teks yang dihasilkan oleh LLM. Contohnya, beberapa alat atau model seperti analisis makna perkataan, resolusi rujukan, penaakulan logik, penghapusan kekaburan dan pengesanan percanggahan boleh digunakan untuk mengesan dan membetulkan ilusi semantik dalam teks yang dihasilkan oleh LLM.
Kaedah pengesanan ilusi pengetahuan: Gunakan beberapa alat atau model pencarian atau pengesahan pengetahuan untuk mendapatkan dan membandingkan ralat pengetahuan atau ketidakkonsistenan dalam teks yang dihasilkan oleh LLM. Contohnya, beberapa alat atau model seperti graf pengetahuan, enjin carian, semakan fakta, semakan bukti, semakan petikan, dsb. boleh digunakan untuk mengesan dan membetulkan ilusi pengetahuan dalam teks yang dihasilkan oleh LLM.
Kaedah pengesanan ilusi penciptaan: Gunakan beberapa alat atau model penilaian ciptaan atau maklum balas untuk mengesan dan menilai ralat atau ketidaksesuaian penciptaan dalam teks yang dijana oleh LLM. Contohnya, beberapa alat atau model seperti analisis gaya, analisis sentimen, penilaian penciptaan, analisis pendapat, analisis matlamat, dll. boleh digunakan untuk mengesan dan membetulkan ilusi penciptaan dalam teks yang dihasilkan oleh LLM.
Mengikut tahap dan kesan halusinasi yang dinyatakan di atas, kita boleh membahagikan kriteria penilaian halusinasi kepada empat kategori berikut:
Ketepatan Tatabahasa: merujuk kepada sama ada teks yang dihasilkan oleh LLM adalah konsisten dengan tatabahasa. peraturan dan kebiasaan, seperti ejaan, tanda baca, susunan kata, tegang, perjanjian subjek-kata kerja, dll. Piawaian ini boleh dinilai melalui beberapa alat atau kaedah semakan tatabahasa automatik atau manual, seperti BLEU, ROUGE, BERTScore, dsb.
Kewajaran Semantik: merujuk kepada sama ada teks yang dihasilkan oleh LLM konsisten secara semantik dengan makna dan logik bahasa, seperti makna perkataan, rujukan, logik, kekaburan, percanggahan, dsb. Piawaian ini boleh dinilai melalui beberapa alat atau kaedah analisis semantik automatik atau manual, seperti METEOR, MoverScore, BERTScore, dsb.
Ketekalan Pengetahuan: Merujuk kepada sama ada teks yang dihasilkan oleh LLM konsisten secara intelektual dengan fakta atau bukti sebenar, atau sama ada ia konsisten dengan input atau maklumat kontekstual, seperti fakta, bukti, rujukan, padanan, dsb. Piawaian ini boleh dinilai melalui beberapa alat atau kaedah pengesahan pengetahuan automatik atau manual, seperti FEVER, FactCC, BARTScore, dsb.
Kesesuaian Kreatif: merujuk kepada sama ada teks yang dihasilkan oleh LLM secara kreatif memenuhi keperluan tugas atau matlamat, atau konsisten dengan keutamaan atau jangkaan pengguna, atau selaras dengan emosi atau sikap pengguna, atau konsisten dengan emosi atau sikap pengguna sama ada komunikasi atau interaksi pengguna membantu, seperti gaya, emosi, pendapat, matlamat, dll. Piawaian ini boleh dinilai melalui beberapa penilaian penciptaan automatik atau manual atau alatan atau kaedah maklum balas, seperti BLEURT, BARTScore, SARI, dsb.
Untuk menyelesaikan masalah halusinasi dalam LLM dengan lebih baik, kita perlu mengurangkan dan mengurangkan halusinasi yang dihasilkan oleh LLM dengan lebih baik. Mengikut tahap dan sudut yang berbeza, pengarang membahagikan kaedah pelepasan halusinasi ke dalam kategori berikut:
Penghalusan pasca generasi adalah untuk mengubah suai teks selepas LLM menjana teks. Buat beberapa semakan dan pembetulan untuk menghapuskan atau mengurangkan ilusi. Kelebihan kaedah jenis ini ialah ia tidak memerlukan latihan semula atau pelarasan LLM dan boleh digunakan secara langsung pada mana-mana LLM. Kelemahan pendekatan jenis ini ialah ilusi mungkin tidak dapat dihapuskan sepenuhnya, atau ilusi baru mungkin diperkenalkan, atau beberapa maklumat atau kreativiti teks asal mungkin hilang. Wakil kaedah jenis ini ialah:
RARR (Pemurnian dengan Atribusi dan Rujukan Diperoleh): (Chrysostomou dan Aletras, 2021) mencadangkan kaedah pemurnian berdasarkan atribusi dan perolehan semula untuk menambah baik teks yang dihasilkan oleh LLMs Fidelity. Model atribusi digunakan untuk mengenal pasti sama ada setiap perkataan dalam teks yang dijana oleh LLM berasal daripada maklumat input, pengetahuan parameter LLM atau strategi penjanaan LLM. Gunakan model perolehan semula untuk mendapatkan beberapa teks rujukan yang berkaitan dengan maklumat input daripada sumber pengetahuan luaran. Akhir sekali, model pemurnian digunakan untuk mengubah suai teks yang dijana oleh LLM berdasarkan hasil atribusi dan hasil perolehan untuk meningkatkan ketekalan dan kredibilitinya dengan maklumat input.
High Entropy Word Spotting and Replacement (HEWSR): (Zhang et al., 2021) mencadangkan kaedah penghalusan berasaskan entropi untuk mengurangkan halusinasi dalam teks yang dihasilkan oleh LLM. Pertama, model pengiraan entropi digunakan untuk mengenal pasti perkataan entropi tinggi dalam teks yang dihasilkan oleh LLM, iaitu perkataan yang mempunyai ketidakpastian yang lebih tinggi apabila dijana. Kemudian model gantian digunakan untuk memilih perkataan yang lebih sesuai daripada maklumat input atau sumber pengetahuan luaran untuk menggantikan perkataan entropi tinggi. Akhir sekali, model pelicinan digunakan untuk membuat beberapa pelarasan pada teks yang diganti untuk mengekalkan koheren tatabahasa dan semantiknya.
ChatProtect (Perlindungan Sembang dengan Pengesanan Kontradiksi Diri): (Wang et al., 2021) mencadangkan kaedah yang diperhalusi berdasarkan pengesanan kontradiksi diri untuk meningkatkan keselamatan perbualan sembang yang dihasilkan oleh LLM. Pertama, model pengesanan percanggahan digunakan untuk mengenal pasti percanggahan diri dalam dialog yang dihasilkan oleh LLM, iaitu kandungan yang bercanggah dengan kandungan dialog sebelumnya. Model gantian kemudiannya digunakan untuk menggantikan balasan bercanggah diri dengan yang lebih sesuai daripada beberapa balasan selamat yang dipratentukan. Akhir sekali, model penilaian digunakan untuk memberikan beberapa markah kepada dialog yang diganti untuk mengukur keselamatan dan kelancarannya.
Pembaikan diri dengan Maklum Balas dan Penaakulan ialah membuat beberapa penilaian dan pelarasan pada teks dalam proses LLM menghasilkan teks untuk menghapuskan atau mengurangkan halusinasi. Kelebihan kaedah jenis ini ialah ia boleh memantau dan membetulkan halusinasi dalam masa nyata, dan boleh meningkatkan keupayaan pembelajaran kendiri dan kawal selia kendiri LLM. Kelemahan pendekatan jenis ini ialah ia mungkin memerlukan beberapa latihan tambahan atau pelarasan LLM, atau ia mungkin memerlukan beberapa maklumat atau sumber luaran. Wakil kaedah jenis ini termasuk:
Metodologi Refleksi Kendiri (SRM): (Iyer et al., 2021) mencadangkan kaedah yang sempurna berdasarkan maklum balas kendiri untuk meningkatkan kebolehpercayaan soalan dan jawapan perubatan yang dihasilkan oleh LLM. Kaedah pertama menggunakan model generatif untuk menghasilkan jawapan awal berdasarkan soalan input dan konteks. Model maklum balas kemudiannya digunakan untuk menjana soalan maklum balas berdasarkan soalan input dan konteks, yang digunakan untuk mengesan potensi halusinasi dalam jawapan awal. Kemudian gunakan model jawapan untuk menjana jawapan berdasarkan soalan maklum balas untuk mengesahkan ketepatan jawapan awal. Akhir sekali, model pembetulan digunakan untuk membetulkan jawapan awal berdasarkan keputusan jawapan untuk meningkatkan kebolehpercayaan dan ketepatannya.
Penaakulan Perbandingan Berstruktur (SC): (Yan et al., 2021) mencadangkan kaedah penaakulan berdasarkan perbandingan berstruktur untuk meningkatkan ketekalan ramalan keutamaan teks yang dijana oleh LLM. Kaedah ini menggunakan model generatif untuk menghasilkan perbandingan berstruktur berdasarkan pasangan teks input, iaitu membandingkan dan menilai pasangan teks dalam aspek yang berbeza. Gunakan model inferens untuk menjana ramalan keutamaan teks berdasarkan perbandingan berstruktur, iaitu pasangan teks mana yang lebih disukai. Gunakan model penilaian untuk menilai perbandingan yang dihasilkan terhadap keputusan yang diramalkan untuk meningkatkan konsistensi dan kredibilitinya.
Think While Effectively Articulating Knowledge (TWEAK): (Qiu et al., 2021a) mencadangkan kaedah inferens berdasarkan pengesahan hipotesis untuk meningkatkan kesetiaan pengetahuan yang dijana oleh LLM kepada teks. Kaedah ini menggunakan model generatif untuk menghasilkan teks awal berdasarkan pengetahuan input. Kemudian gunakan model hipotesis untuk menghasilkan beberapa hipotesis berdasarkan teks awal, iaitu, meramalkan teks masa depan teks di bawah aspek yang berbeza. Kemudian gunakan model pengesahan untuk mengesahkan ketepatan setiap hipotesis berdasarkan pengetahuan input. Akhir sekali, model pelarasan digunakan untuk melaraskan teks awal berdasarkan keputusan pengesahan untuk meningkatkan ketekalan dan kredibilitinya dengan pengetahuan input.
Strategi penyahkodan baharu adalah untuk membuat beberapa perubahan atau pengoptimuman kepada pengagihan kebarangkalian teks dalam proses LLM menjana teks untuk menghapuskan atau mengurangkan ilusi. Kelebihan kaedah jenis ini ialah ia boleh menjejaskan hasil yang dijana secara langsung dan boleh meningkatkan fleksibiliti dan kecekapan LLM. Kelemahan pendekatan jenis ini ialah ia mungkin memerlukan beberapa latihan tambahan atau pelarasan LLM, atau ia mungkin memerlukan beberapa maklumat atau sumber luaran. Wakil kaedah jenis ini ialah:
Penyahkodan Sedar Konteks (CAD): (Shi et al., 2021) mencadangkan strategi penyahkodan berasaskan kontras untuk mengurangkan konflik pengetahuan dalam teks yang dihasilkan oleh LLM. Strategi ini menggunakan model kontrastif untuk mengira perbezaan dalam taburan kebarangkalian output LLM apabila menggunakan dan tidak menggunakan maklumat input. Kemudian model amplifikasi digunakan untuk menguatkan perbezaan ini, supaya kebarangkalian output yang konsisten dengan maklumat input adalah lebih tinggi, dan kebarangkalian output yang bercanggah dengan maklumat input adalah lebih rendah. Akhir sekali, model generatif digunakan untuk menjana teks berdasarkan taburan kebarangkalian yang dikuatkan untuk meningkatkan ketekalan dan kredibilitinya dengan maklumat input.
Menyahkod oleh Lapisan Berbeza (DoLa): (Chuang et al., 2021) mencadangkan strategi penyahkodan berasaskan kontras lapisan untuk mengurangkan ilusi pengetahuan dalam teks yang dihasilkan oleh LLM. Pertama, model pemilihan lapisan digunakan untuk memilih lapisan tertentu dalam LLM sebagai lapisan pengetahuan, iaitu lapisan yang mengandungi lebih banyak pengetahuan fakta. Model kontras lapisan kemudiannya digunakan untuk mengira perbezaan logaritma antara lapisan pengetahuan dan lapisan lain dalam ruang perbendaharaan kata. Akhir sekali, model generatif digunakan untuk menjana teks berdasarkan taburan kebarangkalian selepas perbandingan lapisan untuk meningkatkan ketekalan dan kredibilitinya dengan pengetahuan fakta.
Penggunaan Graf Pengetahuan ialah menggunakan beberapa graf pengetahuan berstruktur untuk menyediakan atau menambah beberapa pengetahuan yang berkaitan dengan maklumat input dalam proses penjanaan teks LLM, untuk menghapuskan atau mengurangkan halusinasi. Kelebihan kaedah jenis ini ialah ia boleh memperoleh dan menyepadukan pengetahuan luaran dengan berkesan, dan boleh meningkatkan liputan pengetahuan dan ketekalan pengetahuan LLM. Kelemahan pendekatan jenis ini ialah beberapa latihan tambahan atau penalaan LLM mungkin diperlukan, atau beberapa graf pengetahuan berkualiti tinggi mungkin diperlukan. Wakil kaedah jenis ini termasuk:
RHO (Perwakilan entiti yang dipautkan dan predikat hubungan daripada Graf Pengetahuan): (Ji et al., 2021a) mencadangkan kaedah perwakilan berdasarkan graf pengetahuan untuk menambah baik dialog yang dihasilkan oleh LLM. Kesetiaan jawapan. Pertama, model perolehan pengetahuan digunakan untuk mendapatkan beberapa subgraf yang berkaitan dengan perbualan input daripada graf pengetahuan, iaitu graf yang mengandungi beberapa entiti dan hubungan. Kemudian model pengekodan pengetahuan digunakan untuk mengekod entiti dan perhubungan dalam subgraf untuk mendapatkan perwakilan vektornya. Kemudian model gabungan pengetahuan digunakan untuk menggabungkan perwakilan vektor pengetahuan ke dalam perwakilan vektor dialog untuk mendapatkan perwakilan dialog yang dipertingkatkan. Akhir sekali, model penjanaan pengetahuan digunakan untuk menjana balasan dialog yang setia berdasarkan perwakilan dialog yang dipertingkatkan.
FLEEK (Pengesanan dan pembetulan Ralat Fakta dengan Bukti Diperoleh daripada Pengetahuan luaran): (Bayat et al., 2021) mencadangkan kaedah pengesahan dan pembetulan berdasarkan graf pengetahuan untuk meningkatkan kefaktaan teks yang dihasilkan oleh LLM. Kaedah pertama menggunakan model pengecaman fakta untuk mengenal pasti fakta yang berpotensi boleh disahkan dalam teks yang dijana oleh LLM, iaitu fakta yang buktinya boleh didapati dalam graf pengetahuan. Model penjanaan soalan kemudiannya digunakan untuk menjana soalan bagi setiap fakta untuk menyoal graf pengetahuan. Kemudian gunakan model perolehan pengetahuan untuk mendapatkan beberapa bukti yang berkaitan dengan masalah daripada graf pengetahuan. Akhir sekali, model pengesahan dan pembetulan fakta digunakan untuk mengesahkan dan membetulkan fakta dalam teks yang dijana oleh LLM berdasarkan bukti untuk meningkatkan fakta dan ketepatannya.
Fungsi kehilangan berasaskan kesetiaan adalah menggunakan beberapa ukuran antara teks yang dijana dan maklumat input atau label sebenar semasa latihan atau penalaan halus LLM Satu ukuran ketekalan sebagai sebahagian daripada fungsi kerugian untuk menghapuskan atau mengurangkan ilusi. Kelebihan kaedah jenis ini ialah ia boleh menjejaskan pengoptimuman parameter LLM secara langsung dan meningkatkan kesetiaan dan ketepatan LLM. Kelemahan pendekatan jenis ini ialah beberapa latihan tambahan atau penalaan LLM mungkin diperlukan, atau beberapa data beranotasi berkualiti tinggi mungkin diperlukan. Wakil kaedah jenis ini ialah:
Rangka Kerja Mengurangkan Halusinasi Teks (THAM): (Yoon et al., 2022) mencadangkan fungsi kehilangan berdasarkan teori maklumat untuk mengurangkan halusinasi dalam perbualan video yang dihasilkan oleh LLM. Pertama, model bahasa dialog digunakan untuk mengira taburan kebarangkalian dialog. Model bahasa halusinasi kemudiannya digunakan untuk mengira taburan kebarangkalian halusinasi, iaitu taburan kebarangkalian maklumat yang tidak boleh diperoleh daripada video input. Kemudian model maklumat bersama digunakan untuk mengira maklumat bersama antara dialog dan ilusi, iaitu maklumat bersama tentang tahap ilusi yang terkandung dalam dialog. Akhir sekali, model entropi silang digunakan untuk mengira entropi silang dialog dan label sebenar, iaitu ketepatan dialog. Matlamat fungsi kehilangan ini adalah untuk meminimumkan jumlah maklumat bersama dan entropi silang, dengan itu mengurangkan ilusi dan kesilapan dalam dialog.
Pembetulan Ralat Fakta dengan Bukti Diperoleh daripada Pengetahuan luaran (FECK): (Ji et al., 2021b) mencadangkan fungsi kerugian berdasarkan bukti pengetahuan untuk menambah baik kefaktaan teks yang dihasilkan oleh LLM. Pertama, model perolehan pengetahuan digunakan untuk mendapatkan beberapa subgraf yang berkaitan dengan teks input daripada graf pengetahuan, iaitu graf yang mengandungi beberapa entiti dan hubungan. Kemudian model pengekodan pengetahuan digunakan untuk mengekod entiti dan perhubungan dalam subgraf untuk mendapatkan perwakilan vektornya. Kemudian model penjajaran pengetahuan digunakan untuk menyelaraskan entiti dan perhubungan dalam teks yang dijana oleh LLM dengan entiti dan perhubungan dalam graf pengetahuan untuk mendapatkan tahap padanannya. Akhir sekali, fungsi kerugian menggunakan model kehilangan pengetahuan untuk mengira jarak antara entiti dan perhubungan dalam teks yang dijana oleh LLM dan entiti serta perhubungan dalam graf pengetahuan, iaitu sisihan daripada fakta. Matlamat fungsi kehilangan ini adalah untuk meminimumkan kehilangan pengetahuan, dengan itu meningkatkan fakta dan ketepatan teks yang dihasilkan oleh LLM.
Penalaan segera ialah proses menggunakan beberapa teks atau simbol tertentu sebagai sebahagian daripada input untuk mengawal atau membimbing tingkah laku penjanaan LLM untuk menghapuskan atau Mengurangkan halusinasi. Kelebihan kaedah jenis ini ialah ia boleh melaraskan dan membimbing pengetahuan parameter LLM dengan berkesan, dan boleh meningkatkan kebolehsuaian dan fleksibiliti LLM. Kelemahan pendekatan jenis ini ialah ia mungkin memerlukan beberapa latihan tambahan atau penalaan LLM, atau ia mungkin memerlukan beberapa gesaan berkualiti tinggi. Wakil kaedah jenis ini termasuk:
UPRISE (Pemurnian Berasaskan Prompt Universal untuk Meningkatkan Kesetaraan Semantik): (Chen et al., 2021) mencadangkan kaedah penalaan halus berdasarkan gesaan universal untuk meningkatkan semantik teks yang dihasilkan oleh LLMs. Pertama, model penjanaan segera digunakan untuk menjana gesaan umum berdasarkan teks input, iaitu beberapa teks atau simbol yang digunakan untuk membimbing LLM menjana teks semantik yang setara. Kemudian model penalaan halus pembayang digunakan untuk memperhalusi parameter LLM berdasarkan teks input dan pembayang, menjadikannya lebih cenderung untuk menjana teks yang semantik setara dengan teks input. Akhir sekali, kaedah ini menggunakan model penjanaan pembayang untuk menjana teks semantik yang setara berdasarkan parameter LLM yang diperhalusi.
SynTra (Tugas Sintetik untuk Mitigasi Halusinasi dalam Ringkasan Abstraktif): (Wang et al., 2021) mencadangkan kaedah penalaan halus berasaskan tugasan sintetik untuk mengurangkan halusinasi dalam ringkasan yang dihasilkan oleh LLM. Pertama, model penjanaan tugas sintetik digunakan untuk menghasilkan tugasan sintetik berdasarkan teks input, iaitu masalah untuk mengesan halusinasi dalam ringkasan. Model penalaan halus tugasan sintetik kemudiannya digunakan untuk memperhalusi parameter LLM berdasarkan teks input dan tugasan, menjadikannya lebih cenderung untuk menjana ringkasan yang konsisten dengan teks input. Akhir sekali, model penjanaan tugas sintetik digunakan untuk menjana ringkasan yang konsisten berdasarkan parameter LLM yang diperhalusi.
Walaupun teknologi bantuan halusinasi dalam LLM telah mencapai sedikit kemajuan, masih terdapat beberapa cabaran dan batasan yang memerlukan penyelidikan dan penerokaan lanjut. Berikut ialah beberapa cabaran dan had utama:
Definisi dan pengukuran halusinasi: Tanpa definisi dan ukuran yang bersatu dan jelas, kajian yang berbeza mungkin menggunakan piawaian dan metrik yang berbeza untuk menilai dan menilai teks yang dihasilkan oleh halusinasi LLM. Ini membawa kepada beberapa keputusan yang tidak konsisten dan tiada tandingan, dan juga menjejaskan pemahaman dan penyelesaian masalah halusinasi dalam LLM. Oleh itu, terdapat keperluan untuk mewujudkan definisi dan pengukuran halusinasi yang lazim dan boleh dipercayai untuk memudahkan pengesanan dan penilaian halusinasi yang berkesan dalam LLM.
Data dan sumber untuk halusinasi: Terdapat kekurangan beberapa data dan sumber yang berkualiti tinggi dan berskala besar untuk menyokong penyelidikan dan pembangunan halusinasi dalam LLM. Sebagai contoh, terdapat kekurangan beberapa set data yang mengandungi anotasi halusinasi untuk melatih dan menguji kaedah pengesanan dan pengurangan halusinasi dalam LLM terdapat kekurangan beberapa sumber pengetahuan yang mengandungi fakta dan bukti sebenar untuk menyediakan dan mengesahkan pengetahuan dalam teks yang dihasilkan oleh LLM; ; terdapat kekurangan beberapa set data yang mengandungi halusinasi Platform untuk maklum balas dan ulasan pengguna untuk mengumpul dan menganalisis kesan halusinasi dalam teks yang dihasilkan oleh LLM. Oleh itu, beberapa data dan sumber yang berkualiti tinggi dan berskala besar perlu dibina untuk memudahkan penyelidikan dan pembangunan yang berkesan mengenai halusinasi dalam LLM.
Punca dan mekanisme halusinasi: Tiada analisis yang mendalam dan komprehensif tentang punca dan mekanisme untuk mendedahkan dan menjelaskan mengapa LLM menghasilkan halusinasi, dan cara halusinasi terbentuk dan disebarkan dalam LLM. Sebagai contoh, tidak jelas bagaimana pengetahuan parametrik, pengetahuan bukan parametrik dan strategi generatif dalam LLM mempengaruhi dan berinteraksi antara satu sama lain, dan cara ia membawa kepada ilusi pelbagai jenis, darjah dan kesan. Oleh itu, beberapa analisis yang mendalam dan komprehensif tentang punca dan mekanisme diperlukan untuk memudahkan pencegahan dan kawalan halusinasi yang berkesan dalam LLM.
Penyelesaian dan pengoptimuman halusinasi: Tiada penyelesaian dan penyelesaian pengoptimuman yang sempurna dan universal untuk menghapuskan atau mengurangkan halusinasi dalam teks yang dihasilkan oleh LLM, serta meningkatkan kualiti dan kesan teks yang dihasilkan oleh LLM. Sebagai contoh, tidak jelas cara untuk meningkatkan kesetiaan dan ketepatan LLM tanpa kehilangan keupayaan generalisasi dan kreativiti mereka. Oleh itu, beberapa penyelesaian dan penyelesaian pengoptimuman yang lengkap dan universal perlu direka bentuk untuk meningkatkan kualiti dan kesan teks yang dijana oleh LLM.
Atas ialah kandungan terperinci Kajian menyeluruh tentang teknik pengurangan halusinasi dalam pembelajaran mesin berskala besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



