


Dalam perusahaan moden, pengurusan pengetahuan adalah pautan yang penting. Ia boleh membantu perusahaan mengatur dan menggunakan sumber pengetahuan dalaman dan luaran dengan berkesan, dengan itu meningkatkan kecekapan dan daya saing perusahaan. Untuk mengurus pengetahuan dengan lebih baik, banyak syarikat telah memperkenalkan konsep pengelola pengetahuan. Pengurus pengetahuan ialah peranan atau sistem yang bertanggungjawab secara khusus untuk mengurus dan menyebarkan pengetahuan perusahaan. Melalui pengelola pengetahuan, perusahaan boleh mengumpul dan mengatur dengan lebih baik
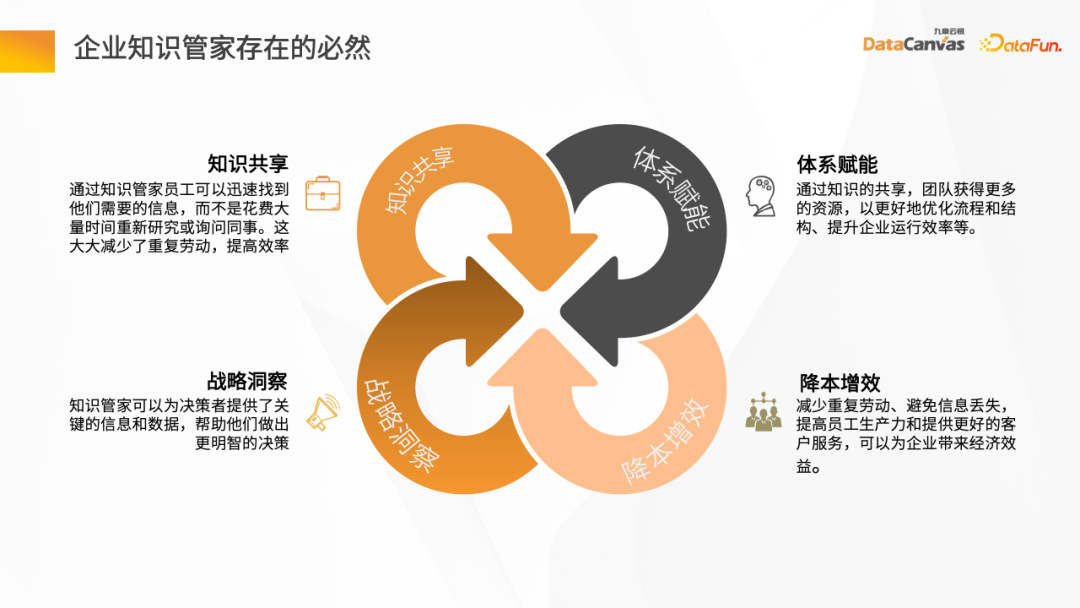
Dengan perkembangan pesat aplikasi Internet dan pertumbuhan pesat pengetahuan, perusahaan berhadapan dengan cabaran untuk berkongsi pengetahuan. Cara memindahkan dan berkongsi pengetahuan dengan berkesan dalam perusahaan telah menjadi isu penting. Melalui perkongsian pengetahuan, syarikat bukan sahaja dapat meningkatkan kecekapan kerja, tetapi juga mengelakkan pertindihan kerja.
Cara lain ialah menggunakan model perkongsian pengetahuan untuk mewujudkan mekanisme yang boleh memperkasakan perusahaan, dengan itu mengoptimumkan proses dan hasil dengan lebih baik, serta meningkatkan kecekapan operasi perusahaan. Model ini membolehkan pekerja dalam perusahaan berkongsi pengetahuan dan pengalaman mereka supaya semua orang dalam pasukan boleh mendapat manfaat. Dengan berkongsi pengetahuan, syarikat boleh mengelakkan pertindihan usaha, mengurangkan kesilapan dan kesilapan, dan lebih mampu bertindak balas terhadap cabaran dan perubahan. Ini
Di samping itu, sebagai penjaga pengetahuan, ia juga boleh memberikan maklumat dan data penting kepada pembuat keputusan untuk membantu mereka membuat keputusan yang lebih termaklum. Butler Pengetahuan mempunyai keupayaan mendapatkan maklumat dan analisis yang hebat, dan boleh mengekstrak maklumat berguna daripada data besar-besaran, menyepadukan dan menganalisisnya. Maklumat dan data ini boleh merangkumi arah aliran pasaran, analisis pesaing, pandangan pengguna, pembangunan teknologi, dsb.
Selain itu, faktor yang sangat penting ialah mengurangkan beban kerja pekerja korporat, mencegah kehilangan maklumat dan meningkatkan produktiviti pekerja . kecekapan kerja dan tahap perkhidmatan pelanggan, dengan itu mencapai matlamat mengurangkan kos dan meningkatkan kecekapan.
Sebelum wujudnya model besar, logik untuk membina seorang pelayan ilmu adalah agak rumit. Biasanya, kami menggunakan konsep pangkalan pengetahuan untuk membina pangkalan pengetahuan dengan bantuan graf pengetahuan perusahaan atau data dalaman perusahaan. Walau bagaimanapun, terdapat banyak cabaran yang dihadapi semasa proses pembinaan ini. Pertama, pembinaan pangkalan pengetahuan memerlukan banyak tenaga kerja dan pelaburan masa. Mengumpul, menyusun dan meringkaskan pengetahuan dan maklumat dalam perusahaan adalah tugas yang membosankan dan memakan masa. Pasukan profesional diperlukan untuk memproses dan mengurus data ini dan memastikan bahawa ia
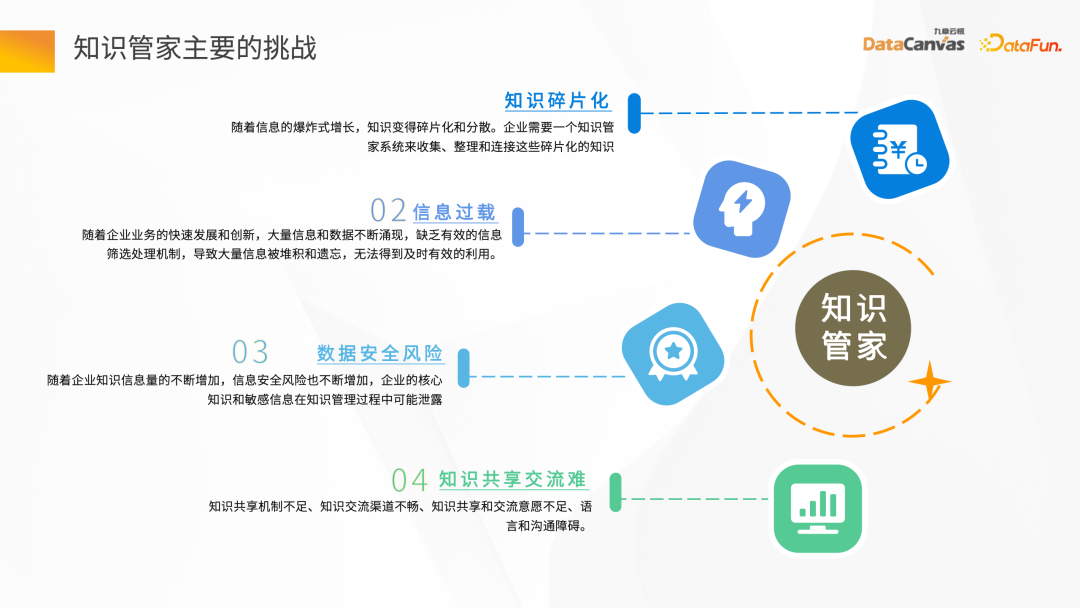
Pemeriksaan pengetahuan adalah dua aspek yang paling mencerminkan perusahaan bertaburan , Sebagai contoh, data sistem OA dimiliki oleh jabatan yang berbeza dan pasukan yang berbeza. Sebaliknya, data ini pada asasnya disediakan dalam bentuk tidak berstruktur, seperti Word, PDF, gambar, video, dll. Dalam proses membina pengelola pengetahuan, cara cepat memusatkan pengetahuan yang berpecah-belah ini adalah cabaran pertama.
Dengan perkembangan pesat perniagaan korporat dan kemunculan berterusan sejumlah besar maklumat dan data, bagaimana untuk mewujudkan mekanisme penapisan dalam data besar-besaran untuk memastikan ketepatan dan ketepatan masa. juga merupakan satu cabaran besar.
Perkongsian pengetahuan dan komunikasi adalah sukar
Butler Pengetahuan Perusahaan adalah serupa dengan otak seseorang untuk membantu dalam penyimpanan keseluruhan pengetahuan, dan untuk memahami dan mencipta pengetahuan.
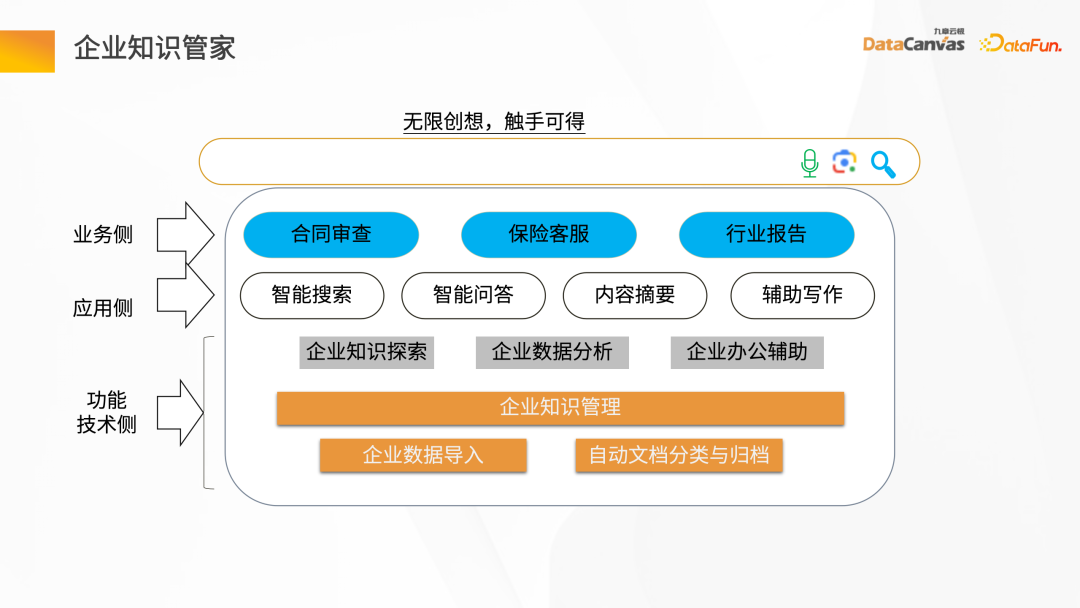
Pengurus pengetahuan perusahaan secara amnya dibahagikan kepada tiga peringkat: Peringkat pertama ialah keperluan fungsian dan teknikal, terutamanya bertanggungjawab untuk pengurusan pengetahuan perusahaan, termasuk import data perusahaan, pengelasan automatik dan pengarkiban dokumen, dan lain-lain Keperluan fungsi asas; lapisan tengah adalah keperluan bahagian aplikasi, termasuk menyediakan beberapa soalan dan jawapan pintar, carian pintar, penjanaan ringkasan, penulisan tambahan dan fungsi lain adalah keperluan bahagian perniagaan; termasuk semakan kontrak, perkhidmatan pelanggan insurans dan penjanaan laporan industri .
Secara amnya terdapat tiga mod antara muka yang dibentangkan oleh Butler Pengetahuan: antara muka pertama adalah serupa dengan kotak teks, menyediakan penerokaan dan analisis pengetahuan; yang lain ialah menggunakan token API untuk menyepadukan ejen pintar yang terlibat dalam senario aplikasi yang berbeza ia ke dalam Token API untuk disepadukan dengan sistem perniagaan perusahaan, cara ketiga ialah Ejen pintar, yang meneroka dan menganalisis pengetahuan melalui mod perbualan.
Pengurus pengetahuan perusahaan bertanggungjawab terutamanya untuk pengurusan dan penciptaan pengetahuan khusus perusahaan, termasuk senario perniagaan berikut:

soalan dan jawapan pintar
kombinasi Data domain peribadi perusahaan divektorkan dan disimpan dalam pangkalan data vektor Ia menggunakan mod soal jawab untuk mencipta senario soalan dan jawapan yang bijak Melalui senario ini, banyak lagi keperluan perniagaan yang khusus boleh diperolehi.Lakukan penerokaan dan analisis melalui dokumen, seperti meneroka kertas, anda boleh bertanya soalan tentang kandungan kertas, anda juga boleh melakukan analisis bebas terhadap dokumen, menyediakan keseluruhan dokumen Pratonton bersegmen, pengambilan semula kontekstual, ringkasan ringkasan dan keupayaan lain. . Minit mesyuarat, dsb.
menggunakan mod dialog manusia-mesin untuk menyemak beberapa maklumat klausa utama pelbagai kontrak perusahaan untuk melihat sama ada maklumat yang sepadan adalah tepat.
Soal jawab pintar: gabungkan soalan khusus dan dapatkan jawapan berasaskan sumber dengan mendapatkan semula konteks.
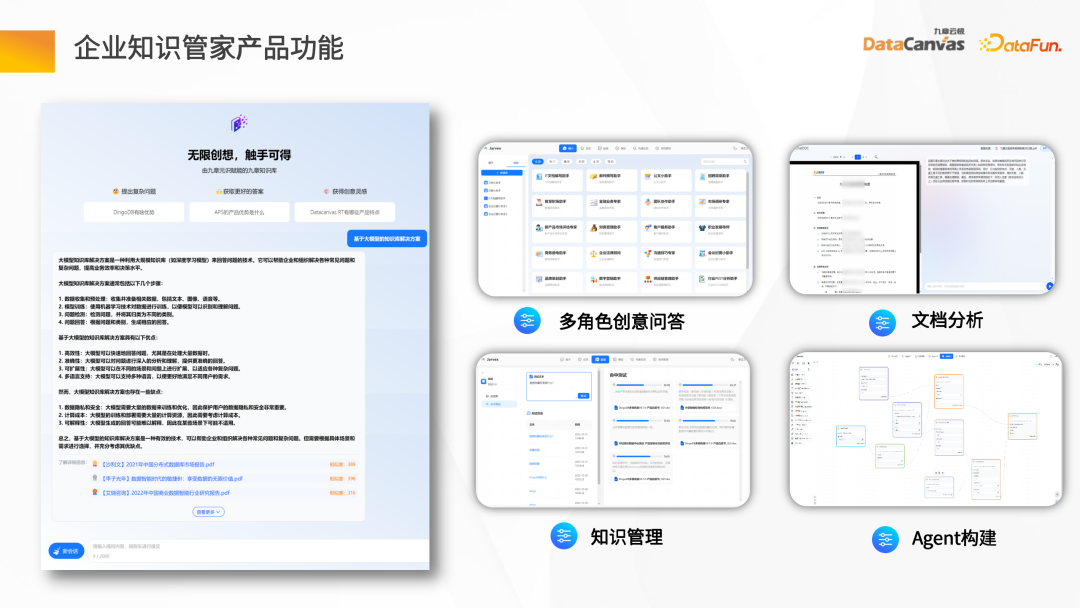
Yang teratas ialah keperluan berasaskan senario perniagaan Dalam Soal Jawab pintar, anda boleh menyesuaikan beberapa dialog peranan, Soal Jawab QA standard dan ejen untuk aplikasi pintar, bacaan tambahan berasaskan dokumen, semakan kontrak dan pembantu peribadi insurans. .
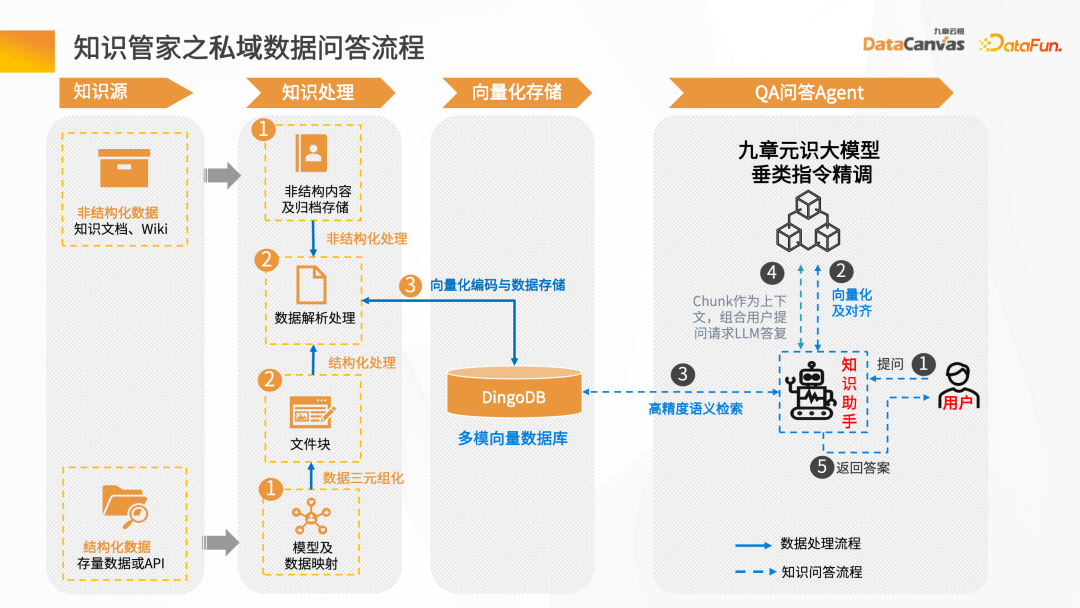
Mula-mula anda memerlukan sumber data, yang mungkin termasuk data berstruktur dan tidak berstruktur Secara umumnya, pembinaan pangkalan pengetahuan terutamanya berdasarkan data tidak berstruktur, seperti Word, PDF, Excel dan sistem perusahaan , Jira. , platform pengurusan pengetahuan, dsb.
Proses interaksi soalan dan jawapan pintar: Selepas pengguna mengemukakan soalan, soalan itu terlebih dahulu divektorkan dengan bantuan pembantu pintar, dan kemudian pangkalan data digunakan untuk mendapatkan semula semantik untuk mendapatkan konteks artikel dengan semantik yang serupa. Konteks digabungkan dengan kata-kata gesaan, dan selepas sejumlah besar penaakulan model akhirnya menghasilkan pulangan jawapan.
2. Penerokaan teknologi teras pembinaan steward pengetahuan
Pemprosesan data tidak berstruktur
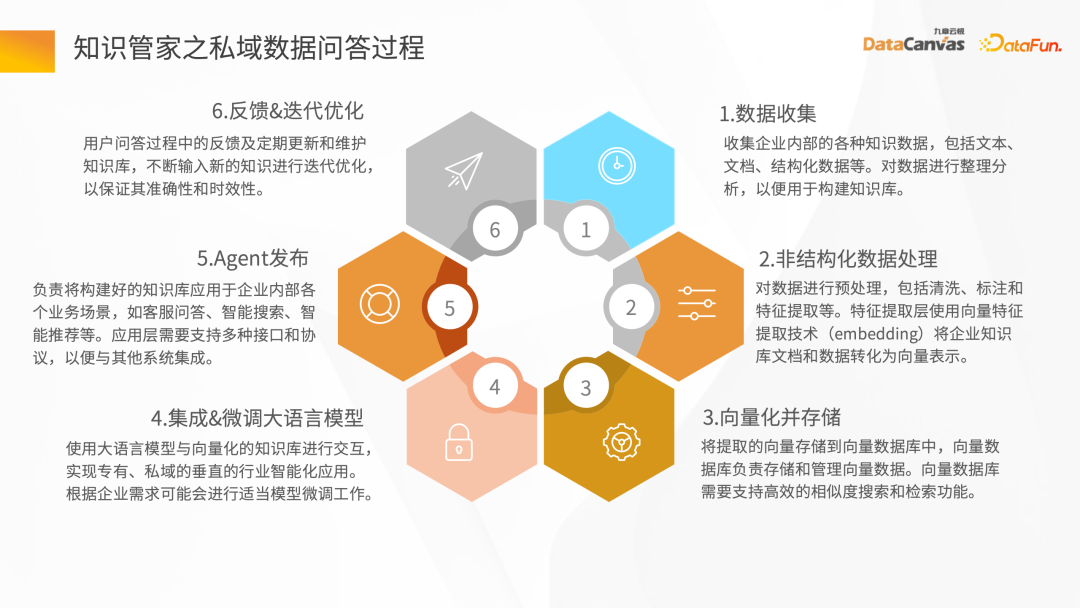
Dengan menghuraikan pelbagai fail (seperti penghurai PDF), dan kemudian melalui Operator Hab senario aplikasi berbeza yang sepadan dengan lapisan tengah, Hab Saluran Paip boleh dibina dengan cepat, dan kemudian data dibersihkan dan ditukar , dan akhirnya disimpan dalam pangkalan data vektor. 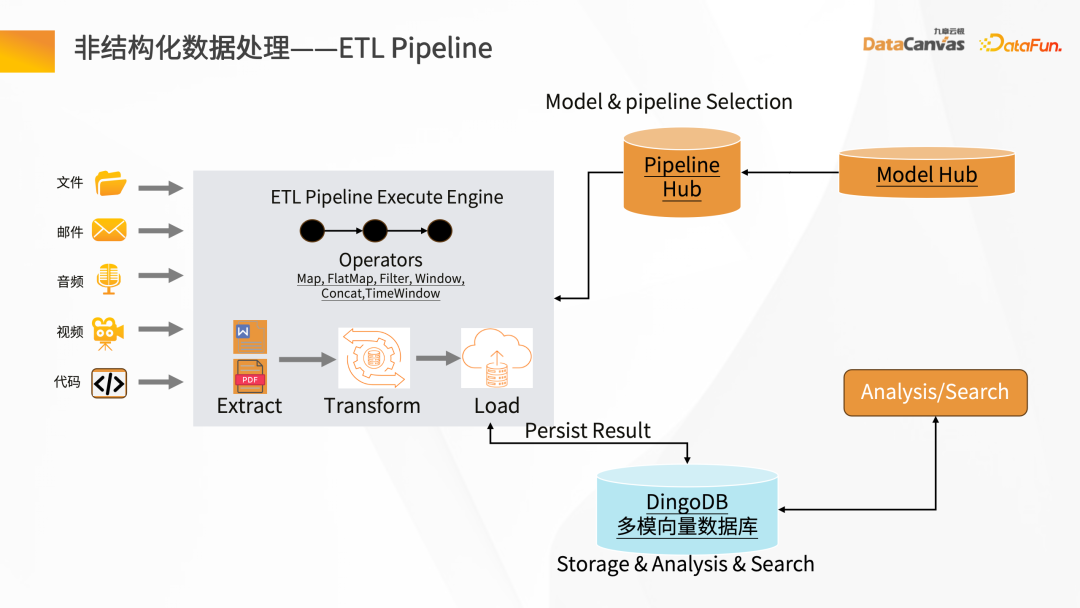
Jaminan Data Ketepatan dan Integriti - Analisis Data Tanpa Rugi
Membina pengambilan data tradisional adalah sangat mudah, tetapi pengetahuan sebenar lebih rumit Selain maklumat dalam teks itu sendiri, terdapat juga gambar, data jadual, maklumat perenggan, dll. Dalam hal ini, Jiuzhang Yunji DataCanvas menyediakan mod penghuraian Layout, yang boleh merealisasikan storan penuh data berbilang modal seperti maklumat Layout, jadual dan gambar, dan secara menyeluruh meningkatkan kualiti proses penghuraian data.
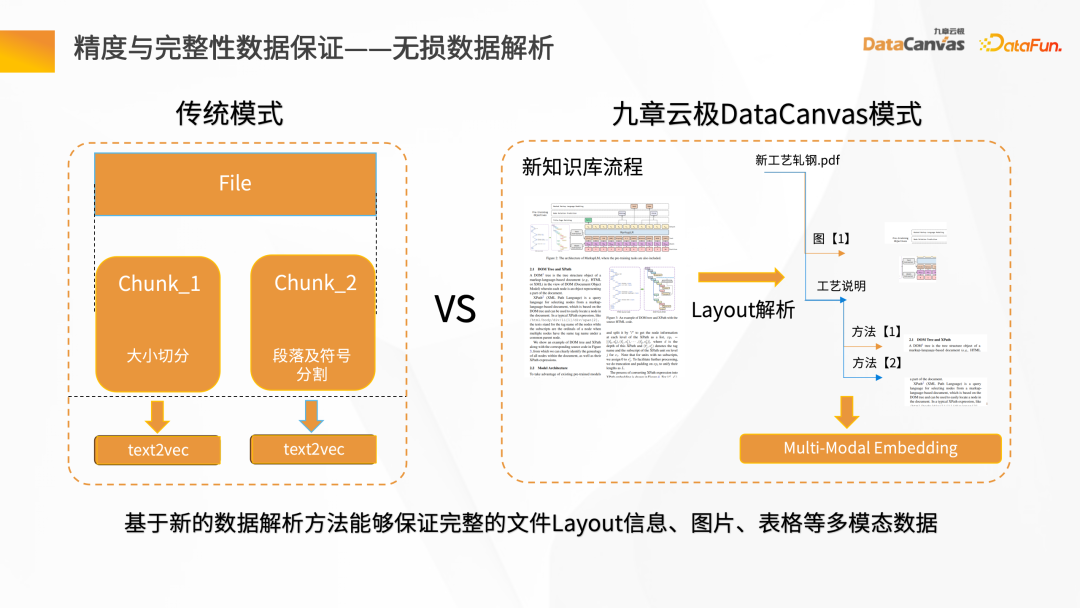
Semasa saringan sekunder Penarafan Semula, Potongan Retrieval dan Pertanyaan yang sepadan perlu dianalisis untuk semantik korelasi, termasuk mencari padanan semantik yang paling hampir, dan kemudian menapis semula Pungutan model bahasa yang besar.
. model pertuturan besar, yang sesuai untuk diingat semula Data digunakan untuk mengehadkan kata-kata segera, dan model besar diperhalusi dengan pengetahuan menegak berdasarkan data domain peribadi syarikat, ditambah dengan mekanisme kawalan arah angin untuk memastikan ketepatan yang tinggi dalam penjanaan jawapan.
DingoDB boleh menyediakan pelbagai API, menyokong pertanyaan data melalui SQL dan Python juga menyediakan kit alatan berstruktur, dan pertanyaan kesatuan tidak berstruktur. Untuk senario masa nyata, DingoDB menyediakan keupayaan untuk membuat pertanyaan dalam masa nyata dengan menulis dalam masa nyata, dan boleh melakukan pengambilan masa nyata semasa mengimport data. 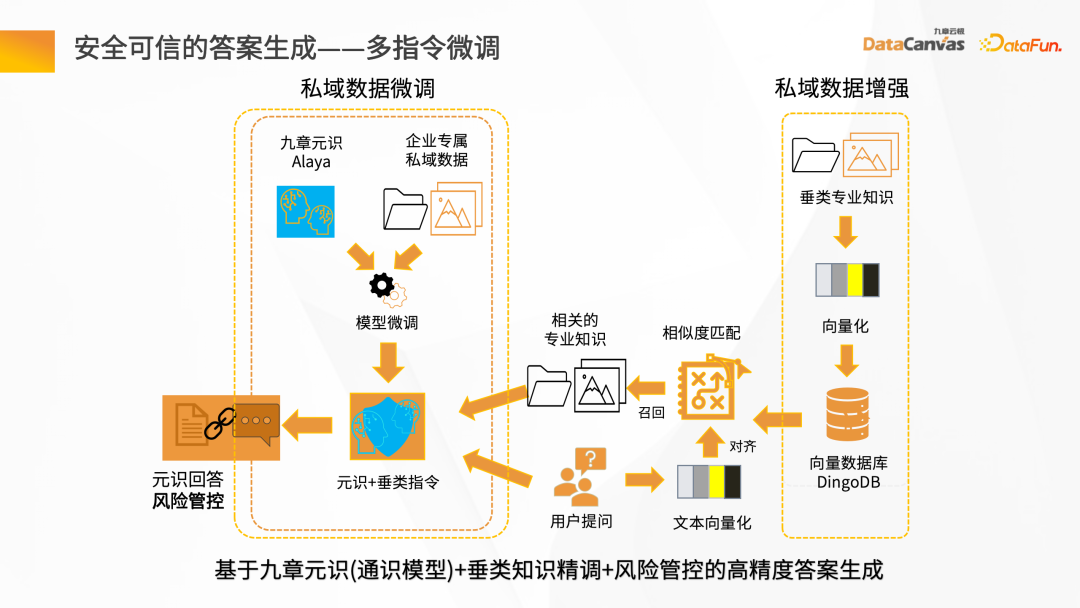
Paip penalaan halus LLM eksklusif yang selamat dan boleh dipercayai
Pada data domain persendirian perusahaan, penalaan halus diperlukan untuk senario biasa untuk membina model bahasa khusus perusahaan yang besar tertentu. Pengurus pengetahuan meringkaskan titik kesakitan dalam keseluruhan proses penalaan halus dan menyediakan pendekatan berasaskan alat dalam produk Data tentang semua masalah boleh diperoleh dengan memuat naik dokumen. Selepas mempunyai data, penalaan halus boleh dilakukan secara langsung pada antara muka dengan mengkonfigurasi parameter Pada masa yang sama, produk juga menyediakan beberapa penunjuk data penalaan halus untuk menilai hasil penalaan halus. 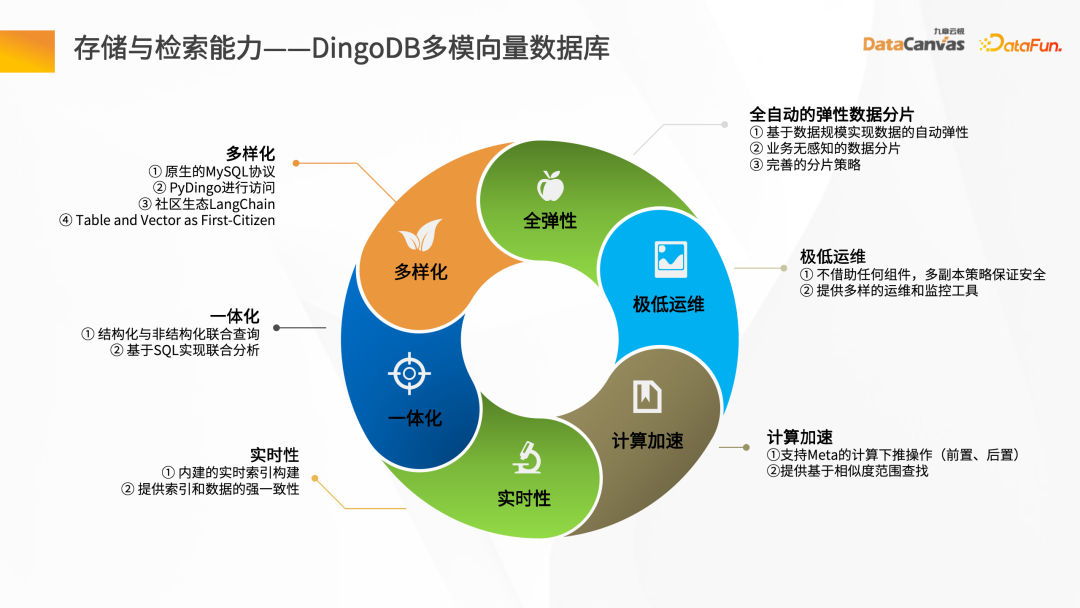
Aplikasi model besar tradisional selalunya rumit untuk dibina. Aplikasi uji FS Pengetahuan Butler yang dibina berasaskan kebolehan uji FS Pengetahuan Butler sendiri DataCanvas Model IDE boleh menyediakan pelbagai komponen dan alatan, dan menerbitkan templat yang dibina ke dalam ejen aplikasi pintar melalui kaedah pembinaan aplikasi yang mudah.

Nilai teras Knowledge Butler termasuk: menyediakan keupayaan asas pengurusan pengetahuan dan inspirasi pintar, dan menyediakan kaedah penggunaan penswastaan aplikasi yang selamat dan boleh dipercayai, termasuk semua data perusahaan, membolehkan realisasi gabungan pengetahuan dan interaksi pintar. Sebagai pangkalan pintar, ia menyediakan keupayaan pengembangan yang fleksibel dan boleh membangunkan Ejen baharu berdasarkan model besar pada Pengurus Pengetahuan. 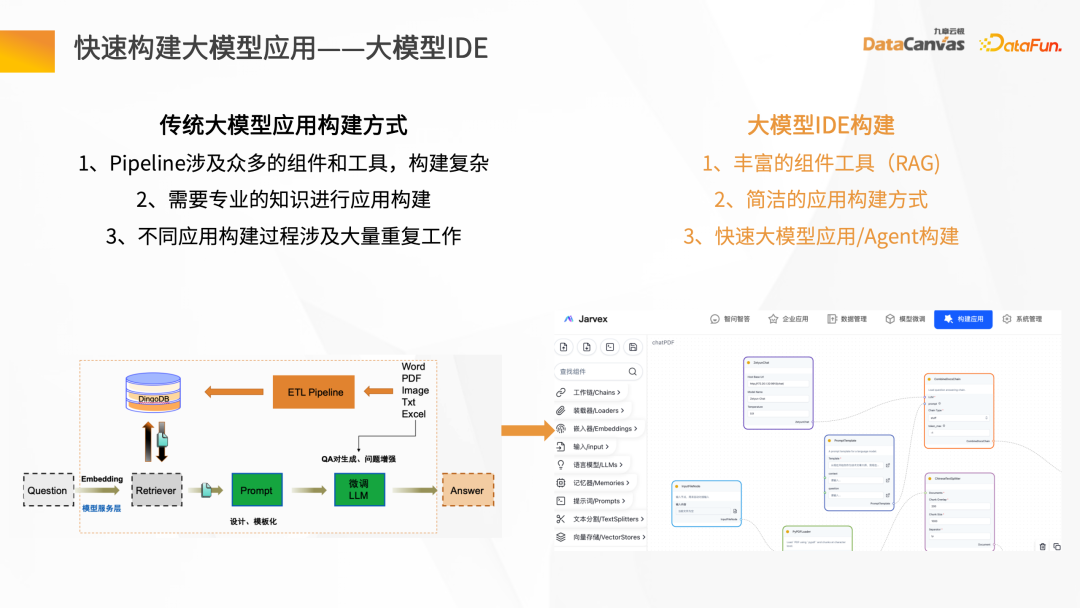
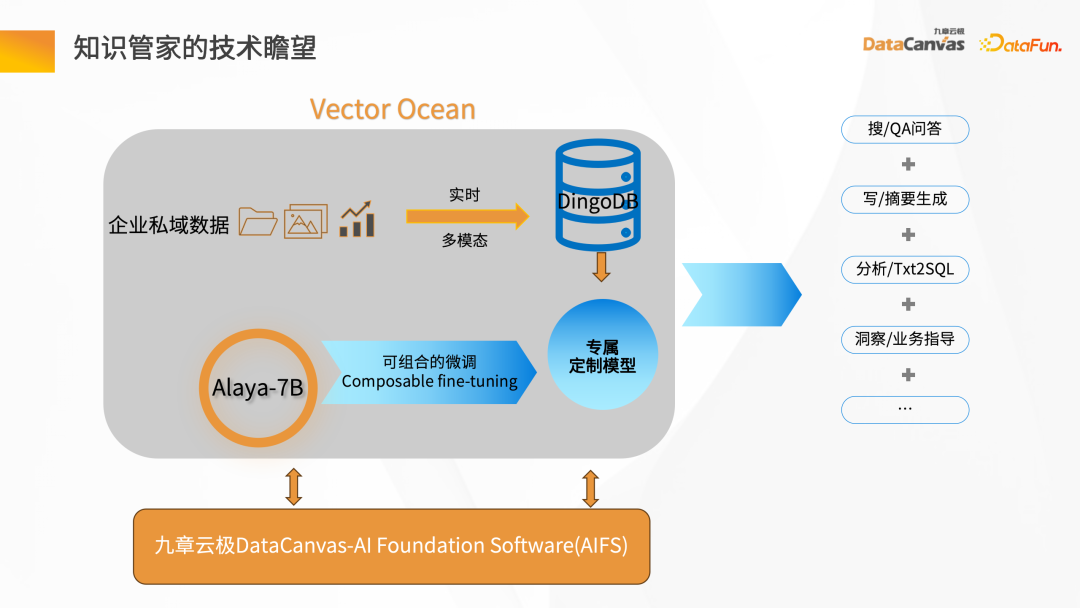
Pengurus Pengetahuan ialah AIFS berdasarkan Jiuzhang Yunji DataCanvas, yang menyediakan set lengkap mod Pipeline daripada logam kosong kepada kuasa pengkomputeran GPU dan penjadualan model, serta melaksanakan penalaan halus model. Ia menggunakan model bahasa umum dan data domain peribadi syarikat untuk melakukan gabungan dan penalaan halus untuk membentuk model bahasa besar syarikat itu sendiri. Berdasarkan skalabiliti model bahasa yang besar dan digabungkan dengan pangkalan data vektor pelbagai mod DingoDB, ia boleh merealisasikan Soal Jawab carian, penjanaan ringkasan dan aplikasi lain dalam perusahaan, dan menjalankan pengurusan pengetahuan perusahaan.
Atas ialah kandungan terperinci Penerokaan Aplikasi Model Besar—Pengurus Pengetahuan Perusahaan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Pangkalan data tiga paradigma
Pangkalan data tiga paradigma
 Bagaimana untuk memadam pangkalan data
Bagaimana untuk memadam pangkalan data
 Bagaimana untuk menyambung ke pangkalan data dalam vb
Bagaimana untuk menyambung ke pangkalan data dalam vb
 pangkalan data pemulihan MySQL
pangkalan data pemulihan MySQL
 Bagaimana untuk menyambung ke pangkalan data dalam vb
Bagaimana untuk menyambung ke pangkalan data dalam vb
 Bagaimana untuk menyelesaikan masalah nama objek pangkalan data tidak sah
Bagaimana untuk menyelesaikan masalah nama objek pangkalan data tidak sah
 Bagaimana untuk menyambung vb untuk mengakses pangkalan data
Bagaimana untuk menyambung vb untuk mengakses pangkalan data
 Bagaimana untuk menyambung ke pangkalan data menggunakan vb
Bagaimana untuk menyambung ke pangkalan data menggunakan vb








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



