

Dalam Cabaran Audio Antarabangsa ICASSP 2024 ini, Pasukan Audio Penstriman ByteDance bekerjasama dengan Makmal Penyelidikan Pertuturan dan Bahasa Pemprosesan Audio Universiti Politeknik Barat Laut untuk mengusahakan Packet Loss Concealment (PLC) dan Pembaikan Kualiti Bunyi (Pertuturan). jejak Penambahbaikan Isyarat (SSI), ia menunjukkan prestasi yang baik pada pelbagai petunjuk dan masing-masing mencapai tempat pertama dan kedua, mencapai tahap terkemuka antarabangsa.
Cabaran Audio di Sidang Kemuncak ICASSP telah dilancarkan bersama oleh persidangan audio antarabangsa terkemuka ICASSP dan Microsoft, bertujuan untuk merangsang penyelidikan mengenai kesan audio dan peningkatan kualiti bunyi oleh pelbagai institusi penyelidikan Sejak sesi pertama, ia telah menarik perhatian Amazon, Tencent, dan Alibaba Banyak syarikat terkenal dan institut penyelidikan saintifik di seluruh dunia, termasuk Baba, Baidu, Kuaishou, Akademi Sains China dan NPU, mengambil bahagian. Dengan perkembangan teknologi yang berterusan dalam bidang media penstriman, menjadikan bunyi yang jelas dan sahih telah menjadi trend yang tidak dapat dielakkan dalam pembangunan industri teknologi audio. Memfokuskan pada cara menyediakan pengalaman audio yang lebih baik kepada pengguna, berbilang pasukan penyelidikan telah menjalankan pengoptimuman audio secara menyeluruh daripada pengumpulan kepada pemajuan Proses ini termasuk cara menangani kecacatan pengumpulan audio, kecacatan pemprosesan algoritma, kecacatan pengekodan dan penyahkodan , dan kecacatan penghantaran rangkaian Tunggu pembaikan bersepadu. Dalam cabaran ini, pasukan audio penstriman ByteDance mengambil bahagian dalam dua trek cabaran, pampasan kehilangan paket dan pembaikan kualiti bunyi am, berdasarkan senario pelaksanaan perniagaan sebenar.
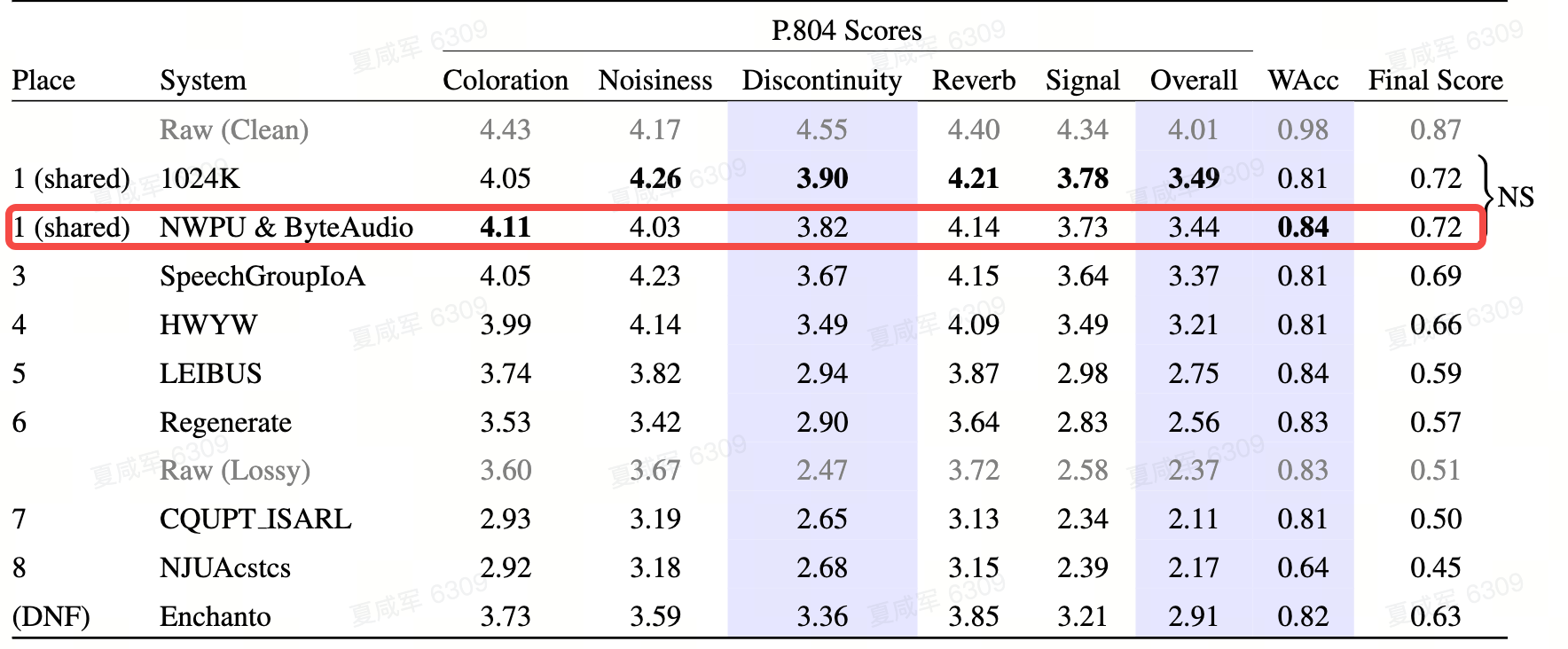
Cabaran PLC ICASSP bertujuan untuk menyelesaikan masalah kehilangan paket selang panjang dan pemprosesan audio jalur penuh (kadar pensampelan 48k Hz) dalam panggilan IP rangkaian. Cabaran ini mempunyai kekangan kependaman yang ketat sambil menyediakan set data yang menuntut yang mencerminkan keadaan rangkaian yang buruk. Penilaian subjektif akan dijalankan menggunakan kaedah penilaian kualiti audio berbilang dimensi P.804, manakala WER juga digunakan untuk menilai kebolehfahaman pertuturan yang dihasilkan oleh sistem yang mengambil bahagian. Pasukan teknologi audio penstriman berkesan mengurangkan kerumitan model pampasan kehilangan paket dengan mengoptimumkan struktur model. Pada masa yang sama, melalui latihan lawan pelbagai diskriminasi dan pembelajaran pelbagai tugas, model pampasan kehilangan paket boleh memulihkan serpihan kehilangan paket dengan kualiti tinggi dan kebolehfahaman yang tinggi, dan akhirnya mencapai tempat pertama.
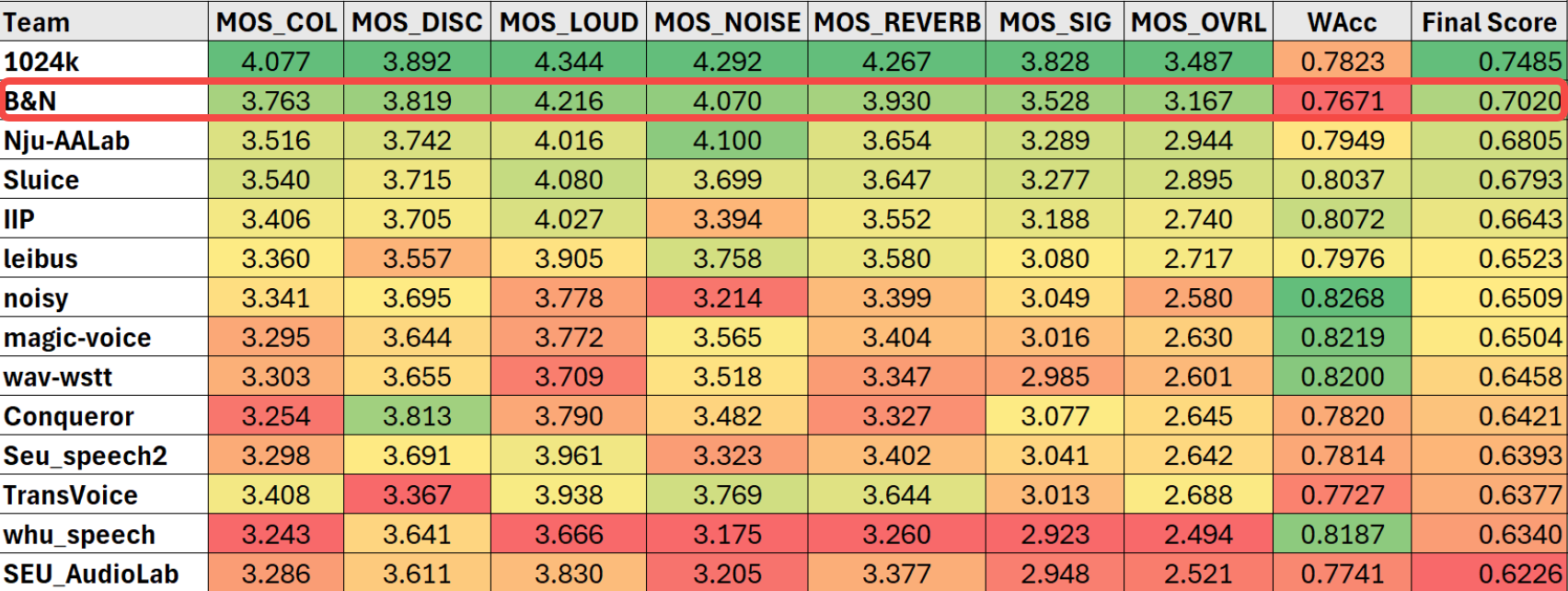
Cabaran SSI ICASSP bertujuan untuk menyelesaikan lima jenis masalah yang dihadapi oleh isyarat pertuturan dalam sistem komunikasi: herotan tindak balas frekuensi, herotan ketakselanjaran, herotan kenyaringan, bunyi dan dengung. Cabaran ini menggunakan skor pendapat subjektif dan kadar pengecaman pertuturan di bawah piawaian ITU-TP.804 untuk menilai secara menyeluruh kedudukan di bawah premis menetapkan kelewatan model dan sebab akibat dengan ketat. Pasukan teknologi penstriman menggunakan struktur model dua peringkat untuk memudahkan masalah pembaikan yang kompleks kepada berbilang subtugas. Pada peringkat pertama, ia terutamanya membaiki herotan tindak balas frekuensi, herotan ketakselanjaran dan herotan kenyaringan, dan melakukan pengurangan hingar awal dan de-getaran; peringkat kedua Peringkat ini membuang lagi artifak yang dihasilkan pada peringkat pertama serta bunyi sisa. Akhirnya, pasukan itu mencapai tempat kedua di trek masa nyata.
Sistem pampasan kehilangan paket
Untuk menyelesaikan masalah kerumitan pemprosesan audio jalur penuh 48kHz, model domain frekuensi digunakan dalam sistem pampasan kehilangan paket, dan audio dibahagikan kepada 0-8kHz , 8- Dua subband 24kHz diproses secara selari. Jumlah pengiraan utama tertumpu pada jalur frekuensi 0-8kHz yang mempunyai kesan yang lebih besar pada deria pendengaran, mencapai pampasan kehilangan paket yang kerumitan rendah dan berkualiti tinggi. Untuk menangani masalah kehilangan paket selang panjang, modul konvolusi diluaskan frekuensi masa (TFDCM) ditambah selepas setiap lapisan codec Walaupun mengekalkan saiz kecil kernel lilitan, ia menangkap jangka panjang melalui sebab lilitan diluaskan lapisan demi lapisan dalam dimensi masa dan kekerapan maklumat sejarah masa dan korelasi kekerapan.
Untuk mengimbangi audio berkualiti tinggi, diskriminator berbilang resolusi domain frekuensi, diskriminator berbilang tempoh domain masa dan MetricGAN digunakan dalam kombinasi untuk menjalankan latihan lawan generatif, menjadikan bunyi audio yang dihasilkan sangat baik. Untuk masalah kehilangan paket dan kebolehfahaman jangka panjang, rangka kerja pembelajaran pelbagai tugas digunakan. Sebagai tambahan kepada pembelajaran persamaan isyarat pertuturan yang biasa, ramalan kekerapan asas dan fungsi kehilangan pemahaman semantik berasaskan bisikan juga diperkenalkan. Model ini boleh memulihkan serpihan kehilangan paket yang lebih lama daripada 100ms dengan kualiti tinggi, dan audio yang dipulihkan sangat mudah difahami Penunjuk kadar ketepatan perkataan (WAcc) mendahului semua pasukan yang mengambil bahagian, dan skor penilaian keseluruhan terikat untuk tempat pertama.
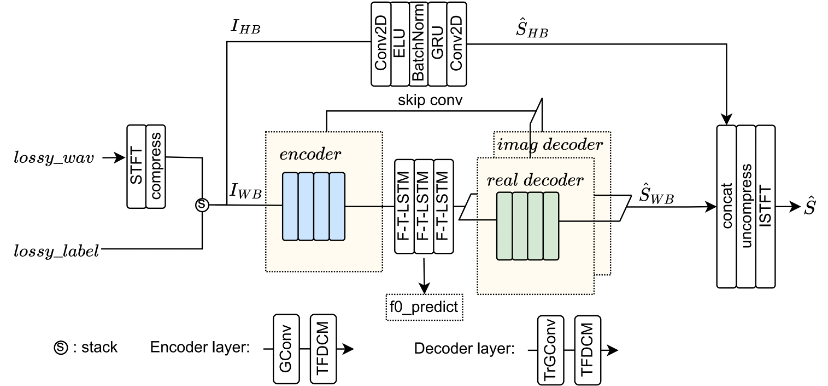
Rajah struktur model pampasan kehilangan paket
Sistem pembaikan kualiti bunyi
Untuk membaiki audio yang dipengaruhi oleh berbilang herotan pada masa yang sama, seni bina model dua peringkat digunakan dalam sistem pembinaan, memfokuskan pada memproses herotan berbeza pada peringkat yang berbeza. Model peringkat pertama menggunakan pemetaan untuk meramalkan secara langsung spektrum kompleks audio yang dibaiki, supaya model mempunyai keupayaan untuk menjana komponen audio yang hilang dan menghapuskan isyarat gangguan pada masa yang sama Untuk meningkatkan keupayaan model untuk menangkap maklumat lama, pengekod The Time-Frequency Convlution Module (TFCM) diperkenalkan ke dalam penyahkod disebabkan ketidakstabilan kaedah pemetaan, artifak mungkin berlaku, jadi model dua peringkat menggunakan masking (Topeng) diperkenalkan, dan sub - Kaedah pemodelan jalur ke jalur penuh melaksanakan pemodelan halus jalur frekuensi untuk menghapuskan lagi artifak dan sisa hingar yang dijana oleh model peringkat pertama.
Untuk meningkatkan keaslian komponen audio yang dijana, rangka kerja rangkaian musuh generatif diperkenalkan, dan diskriminator berbilang resolusi dan diskriminator berbilang resolusi jalur molekul digunakan untuk membantu latihan model. Pada masa yang sama, untuk menjadikan model berbilang peringkat bertumpu dengan lebih mudah semasa latihan, model dua peringkat terlebih dahulu dilatih mengenai tugas pengurangan hingar dan deverberasi, dan kemudian parameter model satu peringkat terlatih ialah dibekukan dan dibandingkan dengan model peringkat kedua yang dilatih terlebih dahulu untuk latihan bersama, dengan itu mempercepatkan penumpuan model.
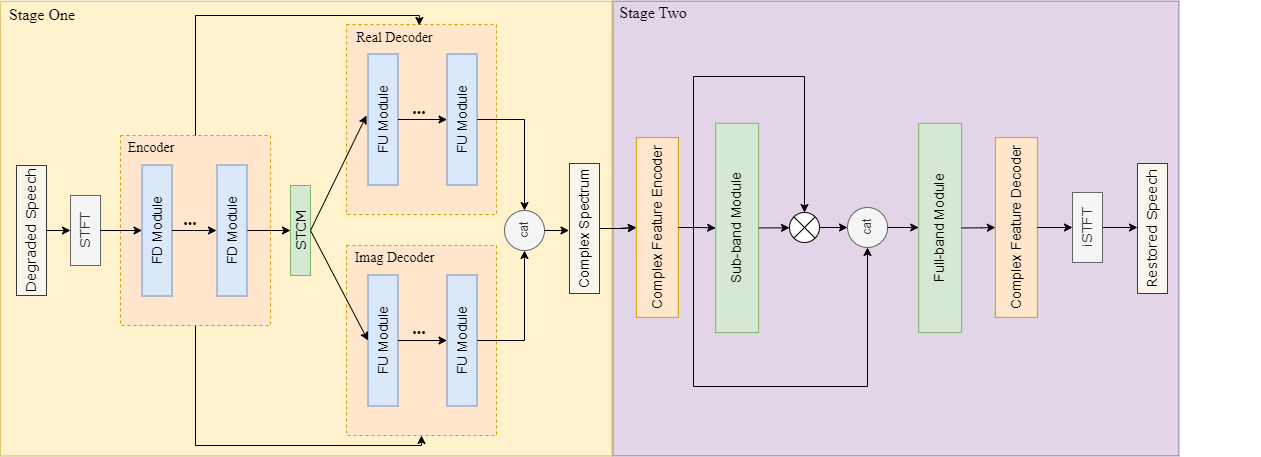
Gambar rajah skema struktur model pembaikan kualiti bunyi
Pengenalan pasukan
Pasukan audio penstriman Bytedance komited untuk menyediakan keupayaan audio dan video masa nyata masa nyata yang berkualiti tinggi dan rendah kependaman merentas Internet global membantu pembangun dengan cepat Ia telah membina fungsi senario yang kaya seperti panggilan suara, panggilan video, siaran langsung interaktif, siaran langsung tweet semula, dll. Pada masa ini, ia meliputi senario interaktif audio dan video masa nyata seperti hiburan interaktif, pendidikan, persidangan, permainan, kereta , kewangan dan IoT, memberi perkhidmatan kepada ratusan juta pengguna.
Atas ialah kandungan terperinci 2024 ICASSP|Penyelesaian inovatif daripada pasukan audio penstriman ByteDance: menyelesaikan pampasan kehilangan paket dan isu pembaikan kualiti bunyi am. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



