
 Peranti teknologi
AI
Teknologi TF-T2V yang dibangunkan bersama oleh Huake, Ali dan syarikat lain mengurangkan kos pengeluaran video AI!
Peranti teknologi
AI
Teknologi TF-T2V yang dibangunkan bersama oleh Huake, Ali dan syarikat lain mengurangkan kos pengeluaran video AI!
Teknologi TF-T2V yang dibangunkan bersama oleh Huake, Ali dan syarikat lain mengurangkan kos pengeluaran video AI!

Dalam dua tahun yang lalu, dengan pembukaan set data imej dan teks berskala besar seperti LAION-5B, satu siri kaedah dengan kesan yang menakjubkan telah muncul dalam bidang penjanaan imej, seperti Stable Diffusion, DALL-E 2, ControlNet dan Komposer. Kemunculan kaedah ini telah membuat terobosan dan kemajuan yang besar dalam bidang penjanaan imej. Bidang penjanaan imej telah berkembang pesat dalam tempoh dua tahun yang lalu.
Walau bagaimanapun, penjanaan video masih menghadapi cabaran besar. Pertama, berbanding dengan penjanaan imej, penjanaan video perlu memproses data berdimensi lebih tinggi dan perlu mengambil kira dimensi masa tambahan, yang membawa masalah pemodelan masa. Untuk memacu pembelajaran dinamik temporal, kami memerlukan lebih banyak data pasangan teks video. Walau bagaimanapun, anotasi temporal video yang tepat adalah sangat mahal, yang mengehadkan saiz set data teks video. Pada masa ini, set data video WebVid10M sedia ada hanya mengandungi 10.7M pasangan teks video Berbanding dengan set data imej LAION-5B, saiz data adalah jauh berbeza. Ini sangat mengehadkan kemungkinan pengembangan model penjanaan video secara besar-besaran.
Untuk menyelesaikan masalah di atas, pasukan penyelidik bersama Universiti Sains dan Teknologi Huazhong, Alibaba Group, Zhejiang University dan Ant Group baru-baru ini mengeluarkan penyelesaian video TF-T2V:

alamat: https: //arxiv.org/abs/2312.15770
Laman utama projek: https://tf-t2v.github.io/
Kod sumber akan dikeluarkan tidak lama lagi: https://github.com /ali-vilab/i2vgen -xl (projek VGen).
Penyelesaian ini mengambil pendekatan baharu dan mencadangkan penjanaan video berdasarkan data video beranotasi tanpa teks berskala besar, yang boleh mempelajari dinamik gerakan yang kaya.
Mula-mula, mari kita lihat kesan penjanaan video TF-T2V:
Tugasan Video Vincent
Kata-kata gesaan: Cipta video yang besar seperti salji tanah berbumbung. 
Kata gesaan: Hasilkan video animasi lebah kartun. 
Kata gesaan: Hasilkan video yang mengandungi motosikal fantasi futuristik. 
Kata gesaan: Hasilkan video budak kecil tersenyum gembira. 
Kata gesaan: Hasilkan video seorang lelaki tua berasa sakit kepala. Tugas penjanaan video 
combined
given teks dan peta kedalaman atau teks dan lakaran lakaran, TF-T2V mampu generasi video yang dapat dikawal: 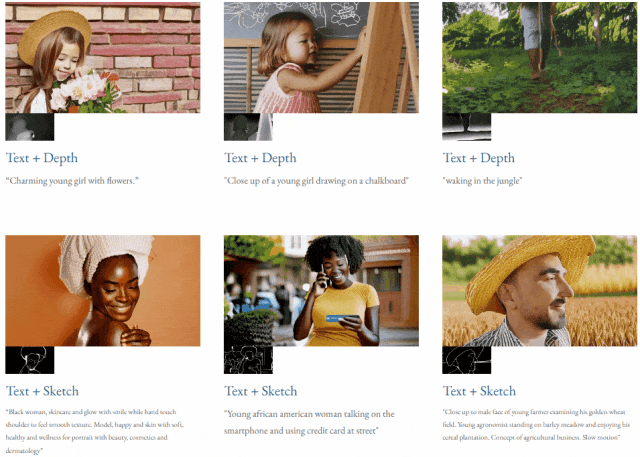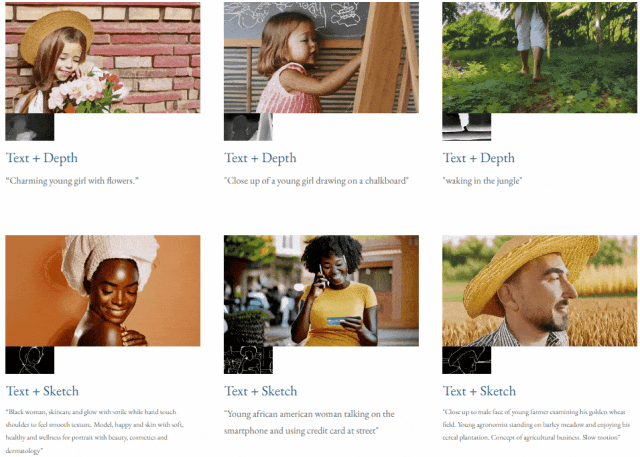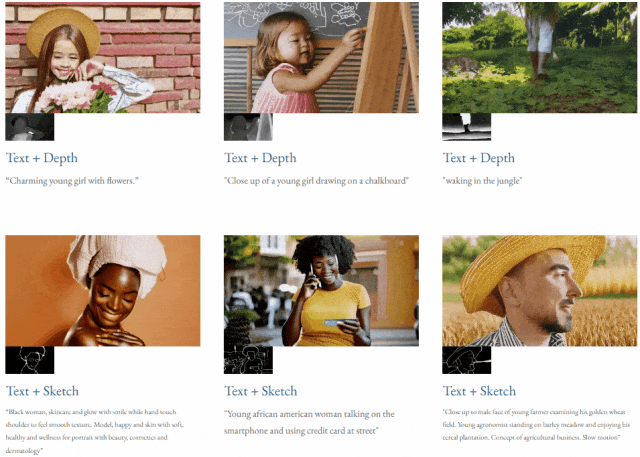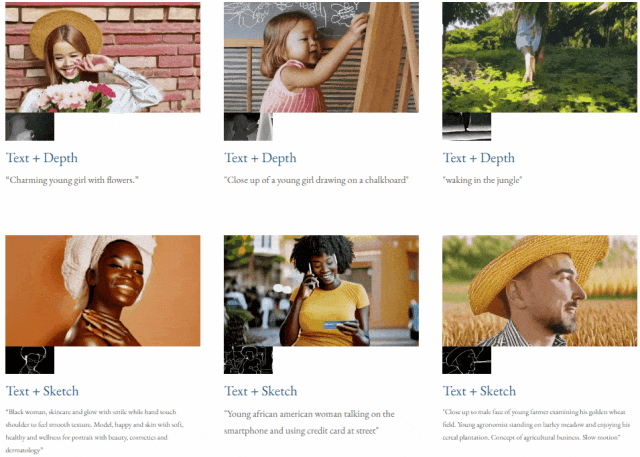
juga tersedia membuat tinggi- sintesis video resolusi: 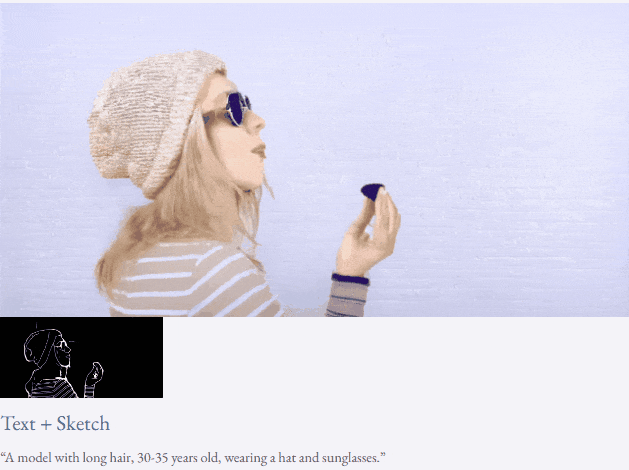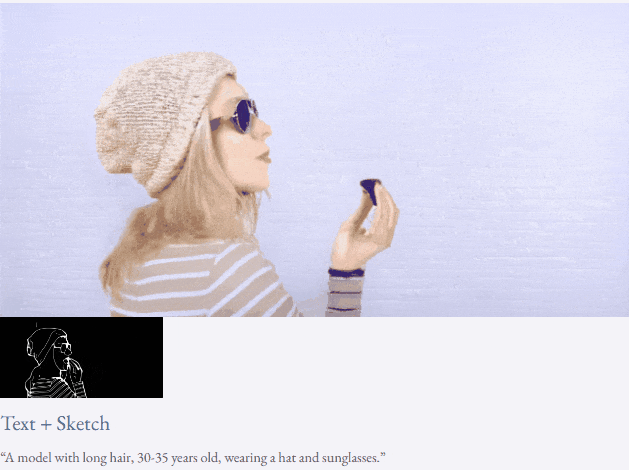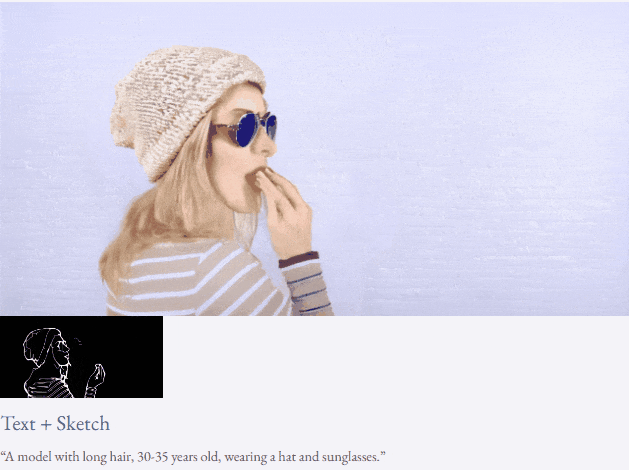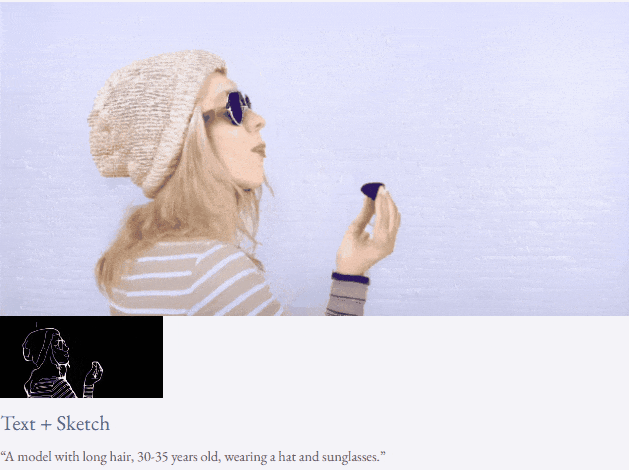
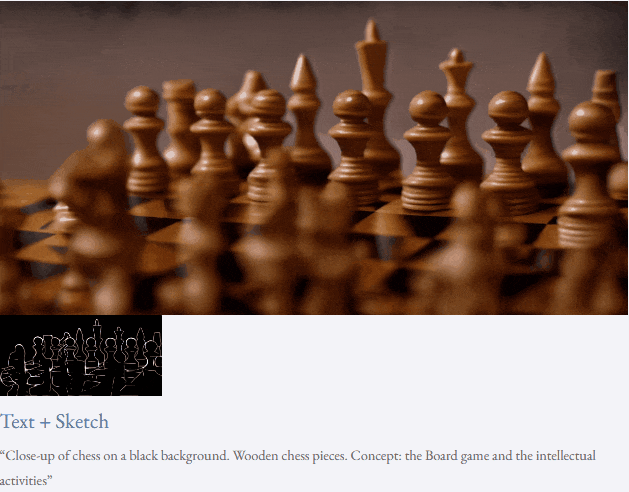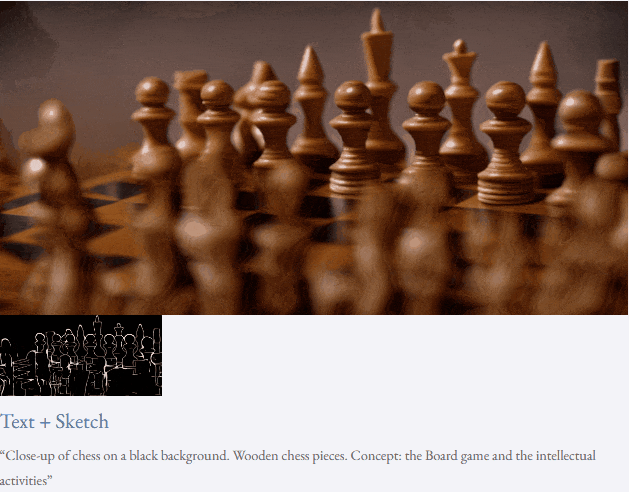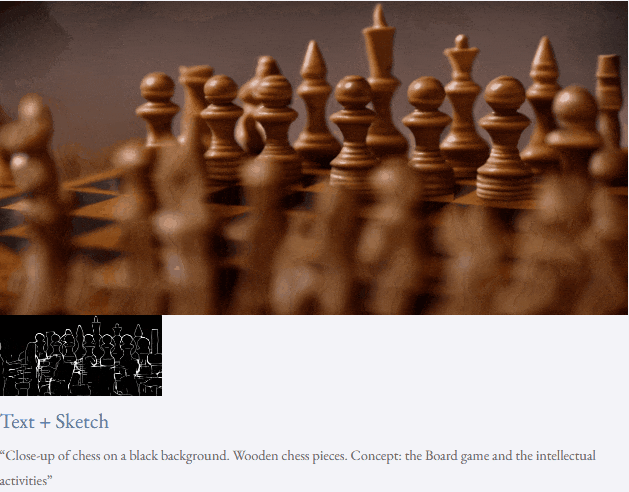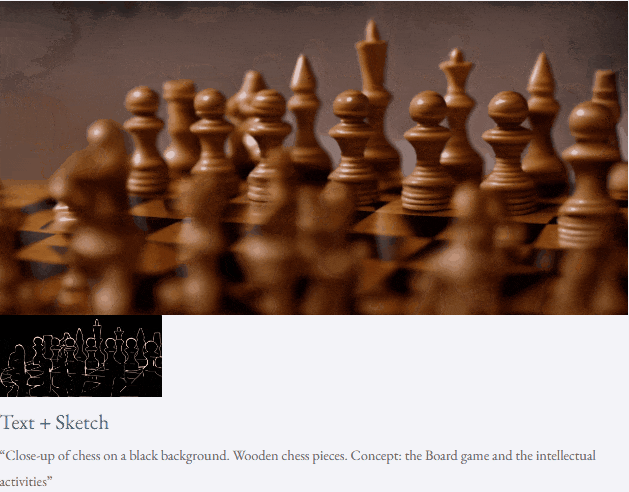
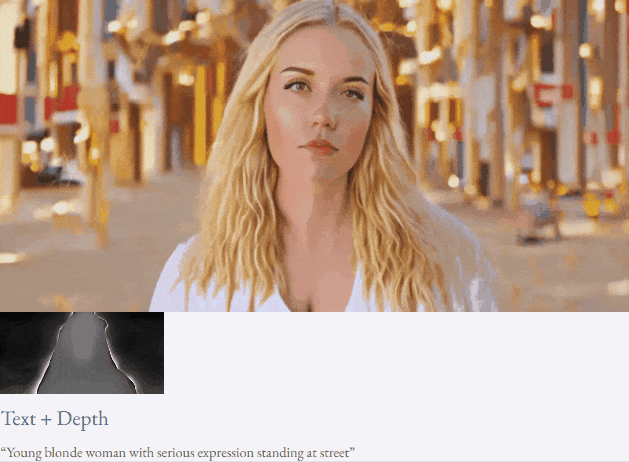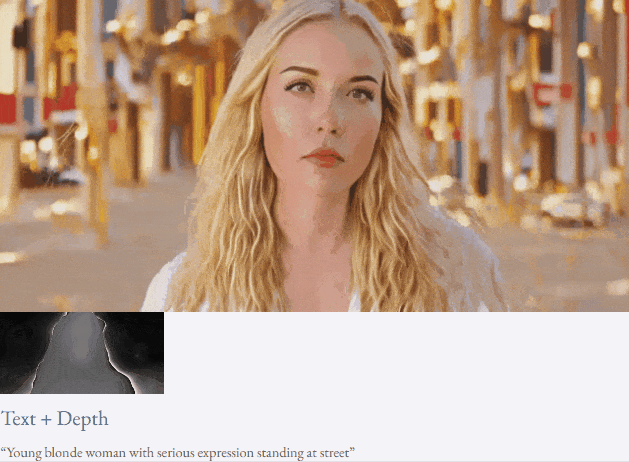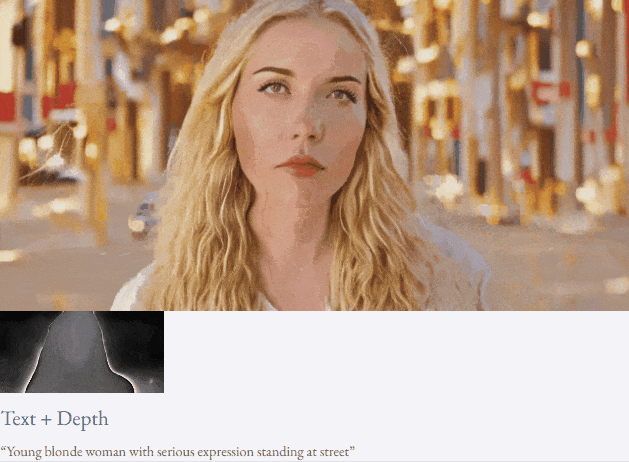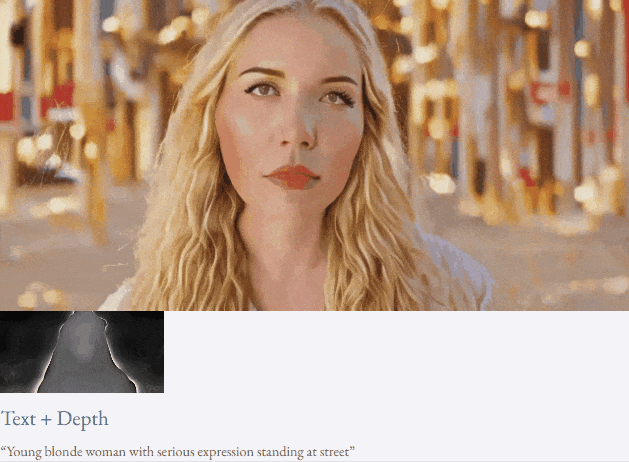
Tetapan separuh seliaan
Kaedah TF-T2V di bawah tetapan separa seliaan juga boleh menjana video yang sepadan dengan perihalan teks gerakan, seperti "Orang ramai berlari dari kanan ke kiri."


Pengenalan kaedah
Idea teras TF-T2V adalah untuk membahagikan model kepada cabang gerakan dan cabang penampilan, model dan gerakan digunakan cabang rupa digunakan untuk mempelajari maklumat yang jelas. Kedua-dua cabang ini dilatih secara bersama, dan akhirnya boleh mencapai penjanaan video dipacu teks.
Untuk meningkatkan ketekalan temporal video yang dijana, pasukan pengarang juga mencadangkan kehilangan ketekalan temporal untuk mempelajari secara jelas kesinambungan antara bingkai video.
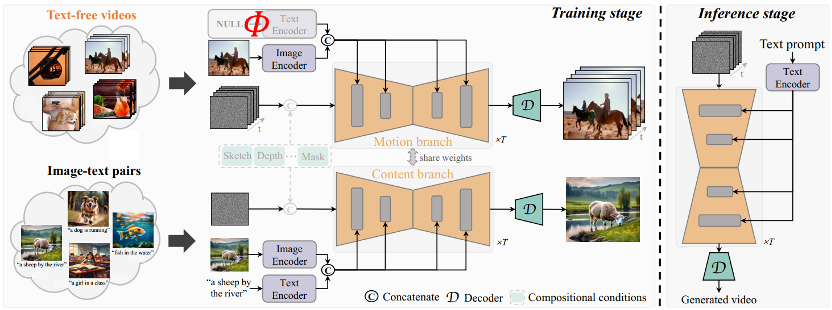
Perlu dinyatakan bahawa TF-T2V ialah rangka kerja umum yang bukan sahaja sesuai untuk tugasan video Vincent, tetapi juga untuk tugas penjanaan video gabungan, seperti lakaran-ke-video, lukisan video, bingkai pertama -ke-video dll.
Untuk butiran khusus dan lebih banyak hasil percubaan, sila rujuk kertas asal atau halaman utama projek.
Selain itu, pasukan pengarang juga menggunakan TF-T2V sebagai model guru dan menggunakan teknologi penyulingan yang konsisten untuk mendapatkan model VideoLCM:

Alamat kertas: https://arxiv.org/abs/ 2312.09109
Laman utama projek: https://tf-t2v.github.io/
Kod sumber akan dikeluarkan tidak lama lagi: https://github.com/ali-vilab/i2vgen-xl (projek VGen) .
Berbeza dengan kaedah penjanaan video sebelum ini yang memerlukan kira-kira 50 langkah denoising DDIM, kaedah VideoLCM berdasarkan TF-T2V boleh menjana video berkesetiaan tinggi dengan hanya kira-kira 4 langkah denoising inferens, yang sangat meningkatkan kecekapan penjanaan video. kecekapan.
Mari kita lihat keputusan inferens denoising 4-langkah VideoLCM:

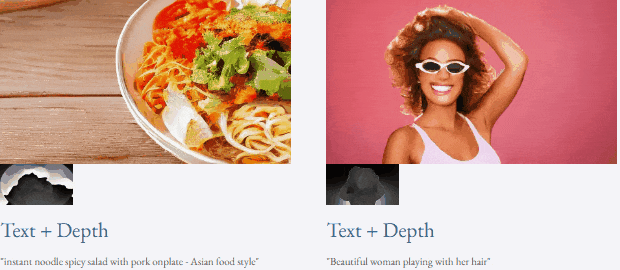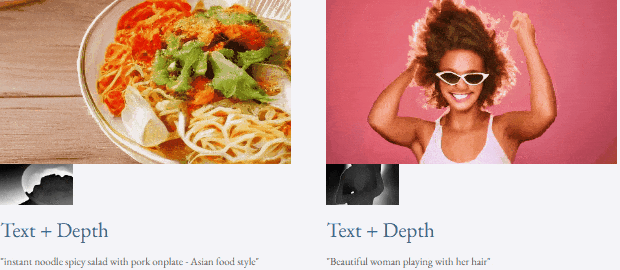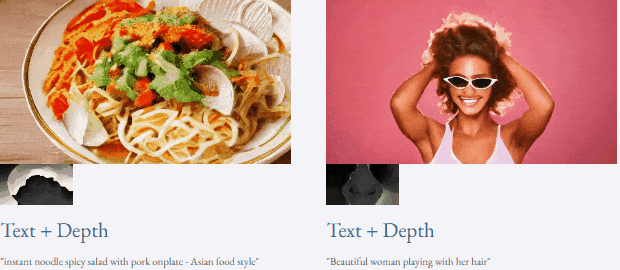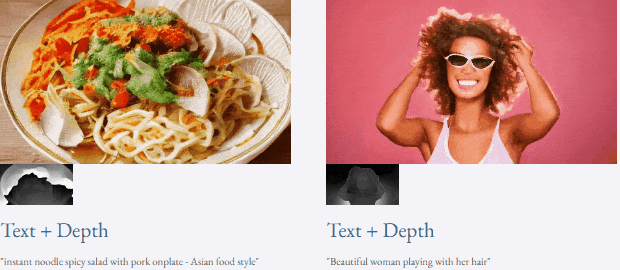

untuk keputusan projek yang asli dan lebih lanjut sila rujuk kepada kertas kerja LC laman utama.
Secara keseluruhannya, penyelesaian TF-T2V membawa idea baharu kepada bidang penjanaan video dan mengatasi cabaran yang disebabkan oleh saiz set data dan masalah pelabelan. Memanfaatkan data video anotasi tanpa teks berskala besar, TF-T2V mampu menjana video berkualiti tinggi dan digunakan pada pelbagai tugas penjanaan video. Inovasi ini akan menggalakkan pembangunan teknologi penjanaan video dan membawa senario aplikasi dan peluang perniagaan yang lebih luas kepada semua lapisan masyarakat.
🎜Atas ialah kandungan terperinci Teknologi TF-T2V yang dibangunkan bersama oleh Huake, Ali dan syarikat lain mengurangkan kos pengeluaran video AI!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Adakah ia melanggar untuk menyiarkan video orang lain di Douyin? Bagaimanakah ia mengedit video tanpa pelanggaran?
Mar 21, 2024 pm 05:57 PM
Adakah ia melanggar untuk menyiarkan video orang lain di Douyin? Bagaimanakah ia mengedit video tanpa pelanggaran?
Mar 21, 2024 pm 05:57 PM
Dengan peningkatan platform video pendek, Douyin telah menjadi bahagian yang sangat diperlukan dalam kehidupan seharian setiap orang. Di TikTok, kita boleh melihat video menarik dari seluruh dunia. Sesetengah orang suka menyiarkan video orang lain, yang menimbulkan persoalan: Adakah Douyin melanggar apabila menyiarkan video orang lain? Artikel ini akan membincangkan isu ini dan memberitahu anda cara mengedit video tanpa pelanggaran dan cara mengelakkan isu pelanggaran. 1. Adakah ia melanggar penyiaran video orang lain oleh Douyin? Menurut peruntukan Undang-undang Hak Cipta negara saya, penggunaan tanpa kebenaran karya pemilik hak cipta tanpa kebenaran pemilik hak cipta adalah satu pelanggaran. Oleh itu, menyiarkan video orang lain di Douyin tanpa kebenaran pengarang asal atau pemilik hak cipta adalah satu pelanggaran. 2. Bagaimana untuk mengedit video tanpa pelanggaran? 1. Penggunaan domain awam atau kandungan berlesen: Awam
 Gunakan ddrescue untuk memulihkan data pada Linux
Mar 20, 2024 pm 01:37 PM
Gunakan ddrescue untuk memulihkan data pada Linux
Mar 20, 2024 pm 01:37 PM
DDREASE ialah alat untuk memulihkan data daripada fail atau peranti sekat seperti cakera keras, SSD, cakera RAM, CD, DVD dan peranti storan USB. Ia menyalin data dari satu peranti blok ke peranti lain, meninggalkan blok data yang rosak dan hanya memindahkan blok data yang baik. ddreasue ialah alat pemulihan yang berkuasa yang automatik sepenuhnya kerana ia tidak memerlukan sebarang gangguan semasa operasi pemulihan. Selain itu, terima kasih kepada fail peta ddasue, ia boleh dihentikan dan disambung semula pada bila-bila masa. Ciri-ciri utama lain DDREASE adalah seperti berikut: Ia tidak menimpa data yang dipulihkan tetapi mengisi jurang sekiranya pemulihan berulang. Walau bagaimanapun, ia boleh dipotong jika alat itu diarahkan untuk melakukannya secara eksplisit. Pulihkan data daripada berbilang fail atau blok kepada satu
 Sumber terbuka! Di luar ZoeDepth! DepthFM: Anggaran kedalaman monokular yang cepat dan tepat!
Apr 03, 2024 pm 12:04 PM
Sumber terbuka! Di luar ZoeDepth! DepthFM: Anggaran kedalaman monokular yang cepat dan tepat!
Apr 03, 2024 pm 12:04 PM
0. Apakah fungsi artikel ini? Kami mencadangkan DepthFM: model anggaran kedalaman monokular generatif yang serba boleh dan pantas. Sebagai tambahan kepada tugas anggaran kedalaman tradisional, DepthFM juga menunjukkan keupayaan terkini dalam tugas hiliran seperti mengecat kedalaman. DepthFM cekap dan boleh mensintesis peta kedalaman dalam beberapa langkah inferens. Mari kita baca karya ini bersama-sama ~ 1. Tajuk maklumat kertas: DepthFM: FastMonocularDepthEstimationwithFlowMatching Pengarang: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Bagaimana untuk membuat wang daripada menyiarkan video di Douyin? Bagaimanakah seorang pemula boleh membuat wang di Douyin?
Mar 21, 2024 pm 08:17 PM
Bagaimana untuk membuat wang daripada menyiarkan video di Douyin? Bagaimanakah seorang pemula boleh membuat wang di Douyin?
Mar 21, 2024 pm 08:17 PM
Douyin, platform video pendek kebangsaan, bukan sahaja membolehkan kami menikmati pelbagai video pendek yang menarik dan novel pada masa lapang kami, tetapi juga memberi kami pentas untuk menunjukkan diri kami dan merealisasikan nilai kami. Jadi, bagaimana untuk membuat wang dengan menyiarkan video di Douyin? Artikel ini akan menjawab soalan ini secara terperinci dan membantu anda menjana lebih banyak wang di TikTok. 1. Bagaimana untuk membuat wang daripada menyiarkan video di Douyin? Selepas menyiarkan video dan mendapat jumlah tontonan tertentu pada Douyin, anda akan berpeluang untuk mengambil bahagian dalam pelan perkongsian pengiklanan. Kaedah pendapatan ini adalah salah satu yang paling biasa kepada pengguna Douyin dan juga merupakan sumber pendapatan utama bagi banyak pencipta. Douyin memutuskan sama ada untuk menyediakan peluang perkongsian pengiklanan berdasarkan pelbagai faktor seperti berat akaun, kandungan video dan maklum balas khalayak. Platform TikTok membolehkan penonton menyokong pencipta kegemaran mereka dengan menghantar hadiah,
 Cara menyiarkan video di Weibo tanpa memampatkan kualiti imej_Cara menyiarkan video di Weibo tanpa memampatkan kualiti imej
Mar 30, 2024 pm 12:26 PM
Cara menyiarkan video di Weibo tanpa memampatkan kualiti imej_Cara menyiarkan video di Weibo tanpa memampatkan kualiti imej
Mar 30, 2024 pm 12:26 PM
1. Mula-mula buka Weibo pada telefon mudah alih anda dan klik [Saya] di sudut kanan bawah (seperti yang ditunjukkan dalam gambar). 2. Kemudian klik [Gear] di penjuru kanan sebelah atas untuk membuka tetapan (seperti yang ditunjukkan dalam gambar). 3. Kemudian cari dan buka [Tetapan Umum] (seperti yang ditunjukkan dalam gambar). 4. Kemudian masukkan pilihan [Video Follow] (seperti yang ditunjukkan dalam gambar). 5. Kemudian buka tetapan [Video Upload Resolution] (seperti yang ditunjukkan dalam gambar). 6. Akhir sekali, pilih [Kualiti Imej Asal] untuk mengelakkan pemampatan (seperti yang ditunjukkan dalam gambar).
 Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Prestasi JAX, yang dipromosikan oleh Google, telah mengatasi Pytorch dan TensorFlow dalam ujian penanda aras baru-baru ini, menduduki tempat pertama dalam 7 penunjuk. Dan ujian tidak dilakukan pada TPU dengan prestasi JAX terbaik. Walaupun dalam kalangan pembangun, Pytorch masih lebih popular daripada Tensorflow. Tetapi pada masa hadapan, mungkin lebih banyak model besar akan dilatih dan dijalankan berdasarkan platform JAX. Model Baru-baru ini, pasukan Keras menanda aras tiga hujung belakang (TensorFlow, JAX, PyTorch) dengan pelaksanaan PyTorch asli dan Keras2 dengan TensorFlow. Pertama, mereka memilih satu set arus perdana
 Bagaimana untuk menerbitkan karya video Xiaohongshu? Apakah yang perlu saya perhatikan semasa menyiarkan video?
Mar 23, 2024 pm 08:50 PM
Bagaimana untuk menerbitkan karya video Xiaohongshu? Apakah yang perlu saya perhatikan semasa menyiarkan video?
Mar 23, 2024 pm 08:50 PM
Dengan kemunculan platform video pendek, Xiaohongshu telah menjadi platform untuk ramai orang berkongsi kehidupan mereka, meluahkan perasaan mereka dan mendapatkan trafik. Pada platform ini, menerbitkan karya video ialah cara interaksi yang sangat popular. Jadi, bagaimana untuk menerbitkan karya video Xiaohongshu? 1. Bagaimana untuk menerbitkan karya video Xiaohongshu? Mula-mula, pastikan anda mempunyai kandungan video yang sedia untuk dikongsi. Anda boleh menggunakan telefon bimbit anda atau peralatan kamera lain untuk merakam, tetapi anda perlu memberi perhatian kepada kualiti imej dan kejelasan bunyi. 2. Edit video: Untuk menjadikan kerja lebih menarik, anda boleh mengedit video. Anda boleh menggunakan perisian penyuntingan video profesional, seperti Douyin, Kuaishou, dsb., untuk menambah penapis, muzik, sari kata dan elemen lain. 3. Pilih kulit muka: Kulit adalah kunci untuk menarik pengguna untuk mengklik.
 Kelajuan Internet Data Selular Perlahan pada iPhone: Pembetulan
May 03, 2024 pm 09:01 PM
Kelajuan Internet Data Selular Perlahan pada iPhone: Pembetulan
May 03, 2024 pm 09:01 PM
Menghadapi ketinggalan, sambungan data mudah alih perlahan pada iPhone? Biasanya, kekuatan internet selular pada telefon anda bergantung pada beberapa faktor seperti rantau, jenis rangkaian selular, jenis perayauan, dsb. Terdapat beberapa perkara yang boleh anda lakukan untuk mendapatkan sambungan Internet selular yang lebih pantas dan boleh dipercayai. Betulkan 1 – Paksa Mulakan Semula iPhone Kadangkala, paksa memulakan semula peranti anda hanya menetapkan semula banyak perkara, termasuk sambungan selular. Langkah 1 – Hanya tekan kekunci naikkan kelantangan sekali dan lepaskan. Seterusnya, tekan kekunci Turun Kelantangan dan lepaskannya semula. Langkah 2 - Bahagian seterusnya proses adalah untuk menahan butang di sebelah kanan. Biarkan iPhone selesai dimulakan semula. Dayakan data selular dan semak kelajuan rangkaian. Semak semula Betulkan 2 – Tukar mod data Walaupun 5G menawarkan kelajuan rangkaian yang lebih baik, ia berfungsi lebih baik apabila isyarat lemah
