

Kedua-dua
OpenAI GPT-4V dan Google Gemini telah menunjukkan keupayaan pemahaman pelbagai mod yang sangat kukuh dan menggalakkan pembangunan pesat model besar berbilang modal (MLLM) telah menjadi hala tuju penyelidikan yang paling hangat dalam industri.
MLLM telah mencapai arahan cemerlang mengikut kebolehan dalam pelbagai tugasan terbuka visual-linguistik. Walaupun penyelidikan terdahulu mengenai pembelajaran multimodal telah menunjukkan bahawa modaliti yang berbeza boleh bekerjasama dan mempromosikan satu sama lain, penyelidikan MLLM sedia ada tertumpu terutamanya pada peningkatan keupayaan tugas multimodal dan cara mengimbangi faedah kerjasama modal dan kesan gangguan modal kekal sebagai isu penting yang perlu ditangani.

Sila klik pautan berikut untuk melihat kertas: https://arxiv.org/pdf/2311.04257.pdf
Sila lihat alamat kod berikut: https://github.com/X -PLUG/mPLUG -Owl/tree/main/mPLUG-Owl2
Alamat pengalaman ModelScope: https://modelscope.cn/studios/damo/mPLUG-Owl2/summary
HuggingFace address experience link: https://modelscope.cn/studios/damo/mPLUG-Owl2/summary
//huggingface. co/spaces/MAGAer13/mPLUG-Owl2
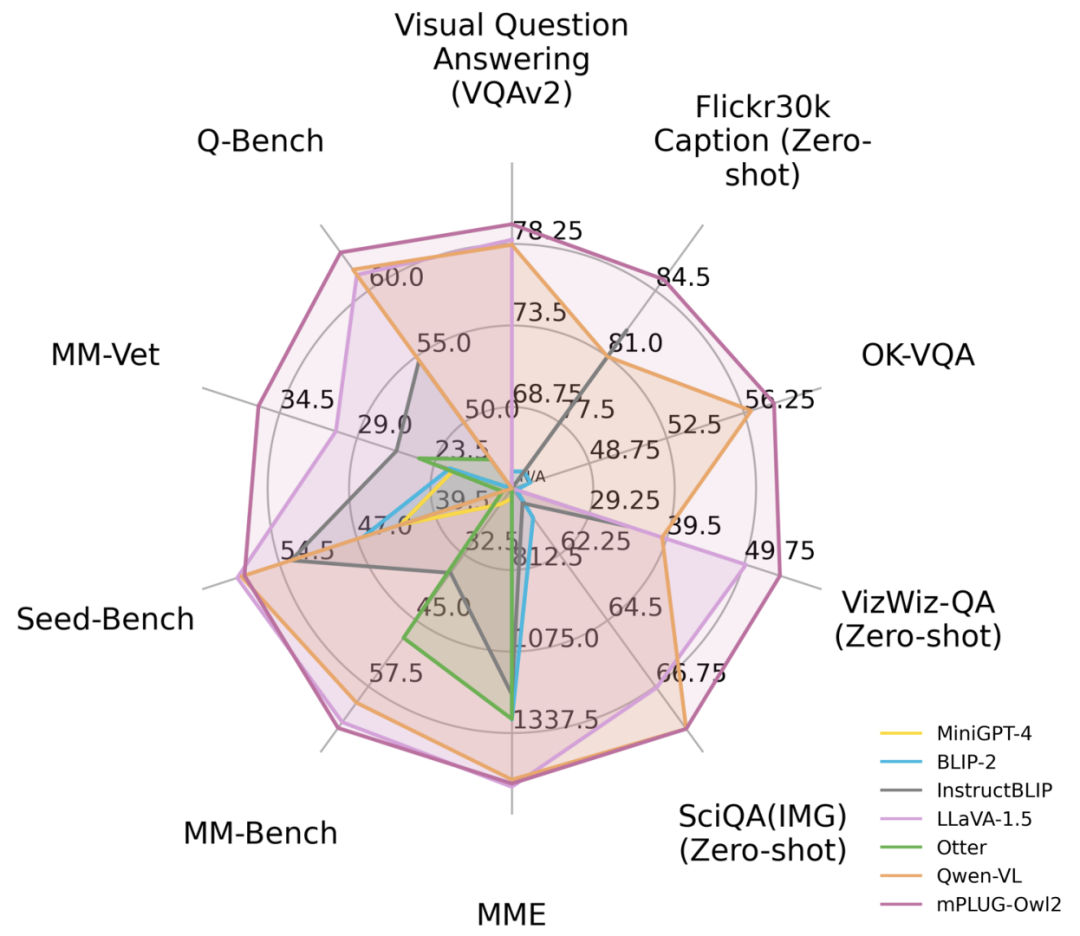
Rajah 1 Perbandingan prestasi dengan model MLLM sedia ada
Pengenalan kaedah Untuk mencapai tujuan untuk tidak mengubah maksud asal, kandungan perlu ditulis semula ke dalam bahasa CinamPLUG-Owl2 model terutamanya terdiri daripada tiga bahagian:
Pengekod Visual: Menggunakan ViT-L/14 sebagai visual pengekod, resolusi input Imej dengan kadar H x W ditukar kepada jujukan token visual H/14 x W/14 dan dimasukkan ke dalam Abstraktor Visual.
Visual Extractor: Mengekstrak ciri semantik peringkat tinggi dengan mempelajari set pertanyaan yang tersedia sambil mengurangkan panjang jujukan visual model bahasa input
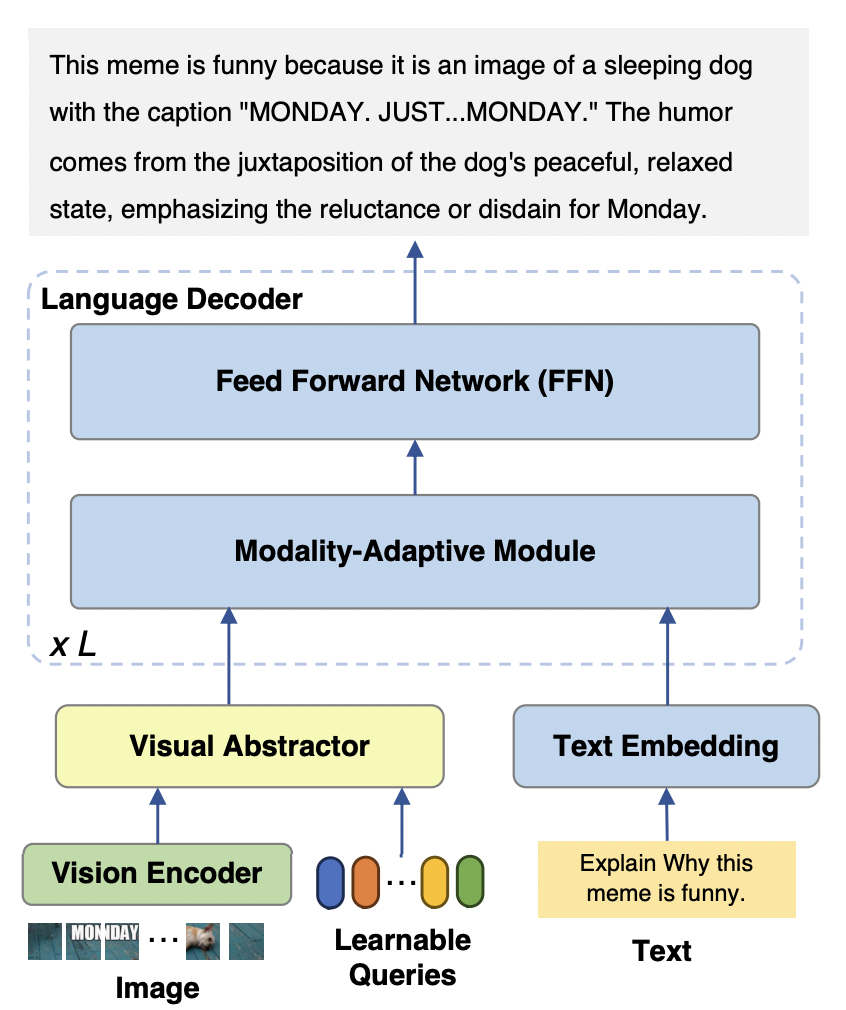
Figure 2 MPLUG-OWL2 MODEL STRUKTUR maklumat visual dan teks boleh menjejaskan prestasi model disebabkan oleh ketidakpadanan kebutiran semantik. Untuk menyelesaikan masalah ini, kertas kerja ini mencadangkan modul penyesuaian modaliti (MAM) untuk memetakan ciri visual dan teks ke dalam ruang semantik yang dikongsi, sambil menyahgandingkan perwakilan visual-linguistik untuk mengekalkan sifat unik setiap modaliti. . Dalam fasa input dan output modul, operasi LayerNorm dilakukan pada modaliti visual dan bahasa masing-masing untuk menyesuaikan diri dengan pengedaran ciri masing-masing bagi kedua-dua modaliti.
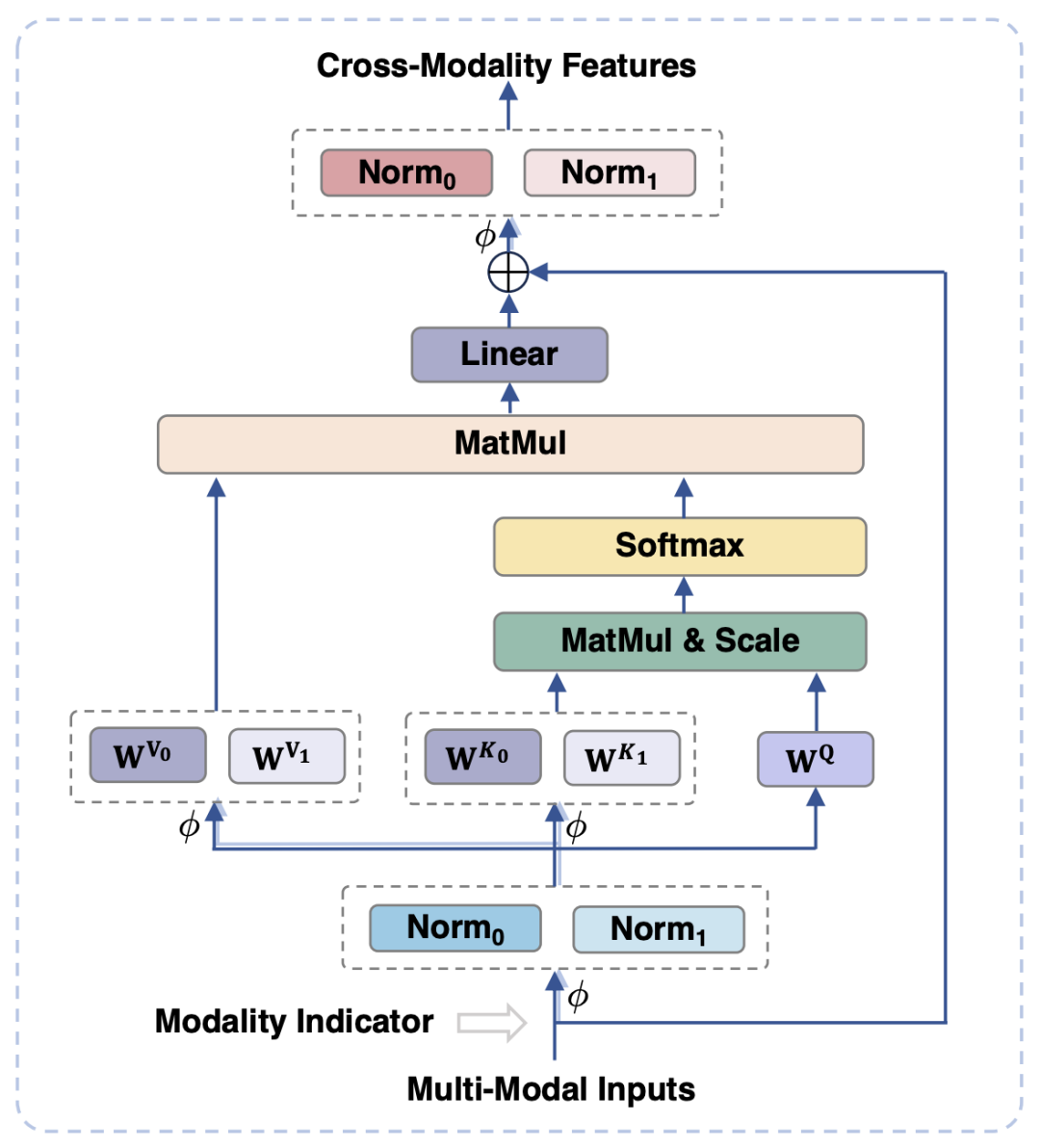
Dengan berkongsi FFN yang sama, kedua-dua modaliti boleh menggalakkan kerjasama antara satu sama lain
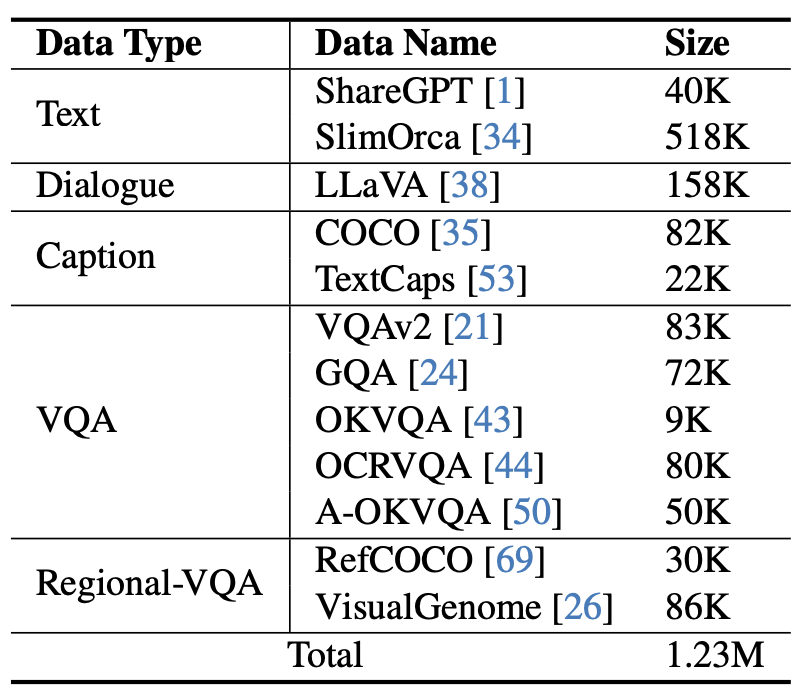
Seperti yang ditunjukkan dalam Rajah 4, latihan mPLUG-Owl2 merangkumi dua peringkat: pra-latihan dan penalaan halus arahan. Peringkat pra-latihan adalah terutamanya untuk mencapai penjajaran pengekod visual dan model bahasa Pada peringkat ini, Pengekod Visual dan Abstraktor Visual boleh dilatih, dan dalam model bahasa, hanya berat model berkaitan visual yang ditambah oleh Modaliti. Modul Adaptif diproses. Dalam peringkat penalaan halus arahan, semua parameter model diperhalusi berdasarkan teks dan data arahan berbilang modal (seperti yang ditunjukkan dalam Rajah 5) untuk meningkatkan keupayaan mengikuti arahan model. .
Gambar 7 Prestasi penanda aras MLLM
ditunjukkan dalam Rajah 6 dan Rajah 7, sama ada perihalan imej tradisional, VQA dan tugasan bahasa visual lain, atau MMBench, Q-Bench dan set data penanda aras lain untuk berbilang modal besar model, mPLUG-Owl2 semuanya mencapai prestasi yang lebih baik daripada kerja sedia ada.
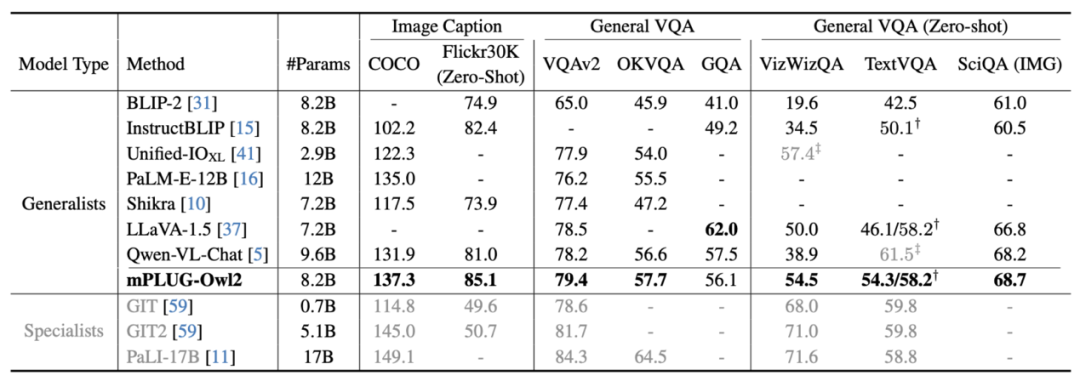
Figure 8 Prestasi Benchmark Teks Tulen Figure 9 Kesan Modul Adaptasi Modal pada Prestasi Tugas Teks Pure Tambahan, untuk menilai kesan kerjasama modal mengenai tugas teks tulen Berkenaan kesan tugasan teks, pengarang juga menguji prestasi mPLUG-Owl2 dalam pemahaman dan penjanaan bahasa semula jadi. Seperti yang ditunjukkan dalam Rajah 8, mPLUG-Owl2 mencapai prestasi yang lebih baik berbanding LLM yang disesuaikan dengan arahan yang lain. Rajah 9 menunjukkan prestasi pada tugasan teks biasa Ia dapat dilihat bahawa sejak modul penyesuaian modal menggalakkan kerjasama modal, pemeriksaan model dan keupayaan pengetahuan telah dipertingkatkan dengan ketara. Penulis menganalisis bahawa ini adalah kerana kerjasama multi-modal membolehkan model menggunakan maklumat visual untuk memahami konsep yang sukar untuk diterangkan dalam bahasa, dan meningkatkan keupayaan penaakulan model melalui maklumat yang kaya dalam imej, dan secara tidak langsung mengukuhkan keupayaan penaakulan teks tersebut. 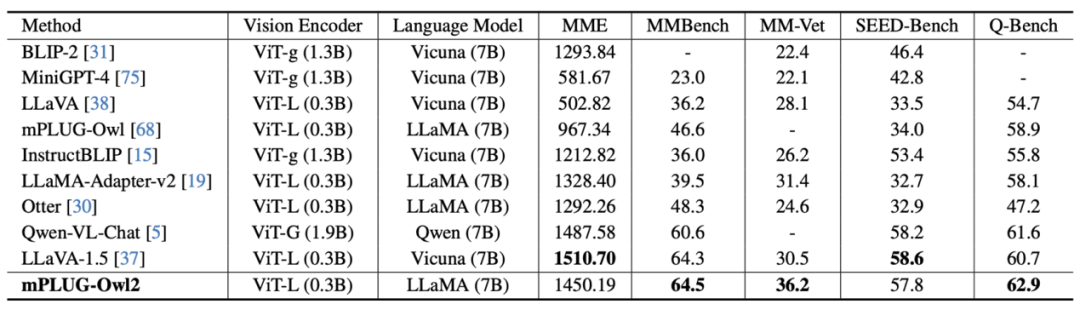
mPLUG-Owl2 menunjukkan keupayaan pemahaman pelbagai mod yang sangat baik dan berjaya mengurangkan halusinasi pelbagai mod. Teknologi pelbagai mod ini telah digunakan pada produk teras Tongyi seperti Tongyi Stardust dan Tongyi Zhiwen, dan telah disahkan dalam demo terbuka ModelScope dan HuggingFace
Atas ialah kandungan terperinci Peningkatan mPLUG-Owl baru Alibaba mempunyai yang terbaik dari kedua-dua dunia, dan kerjasama modal membolehkan SOTA baharu MLLM. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



