
 Tutorial sistem
LINUX
Adakah pembelajaran mesin akan menyebabkan pengendali sistem pengurusan pangkalan data tidak bekerja?
Tutorial sistem
LINUX
Adakah pembelajaran mesin akan menyebabkan pengendali sistem pengurusan pangkalan data tidak bekerja?
Adakah pembelajaran mesin akan menyebabkan pengendali sistem pengurusan pangkalan data tidak bekerja?

| Pengenalan | Sistem Pengurusan Pangkalan Data (DBMS) ialah bahagian paling penting dalam mana-mana sistem aplikasi intensif data. Mereka boleh mengendalikan sejumlah besar data dan beban kerja yang kompleks. Tetapi mereka sukar untuk diurus kerana mereka mempunyai ratusan atau ribuan "tombol" konfigurasi yang mengawal faktor seperti jumlah memori yang digunakan untuk caching dan kekerapan data ditulis ke peranti storan. Organisasi sering mengupah pakar untuk membantu memperhalusi kempen mereka, tetapi pakar sangat mahal untuk banyak perniagaan. |
Artikel ini ditulis bersama oleh tiga tetamu dari Universiti Carnegie Mellon: artikel Dana Van Aken, Andy Pavlo dan Geoff Gordon. Projek ini menunjukkan cara penyelidik akademik boleh menggunakan AWS Cloud Credits for Research Program (https://aws.amazon.com/research-credits/) untuk menyokong kejayaan saintifik mereka.
OtterTune ialah alat baharu yang dibangunkan oleh pelajar dan penyelidik daripada Kumpulan Pangkalan Data Universiti Carnegie Mellon (http://db.cs.cmu.edu/projects/autotune/) yang mengautomasikan konfigurasi butang DBMS untuk mencari tetapan yang sesuai. Matlamatnya adalah untuk memudahkan sesiapa sahaja untuk menggunakan DBMS, walaupun mereka yang tidak mempunyai kepakaran dalam pentadbiran pangkalan data.
OtterTune berbeza daripada alatan konfigurasi DBMS yang lain kerana ia memanfaatkan sepenuhnya pengetahuan yang diperoleh daripada menala DBMS yang digunakan sebelum ini untuk menala DBMS yang baru digunakan. Ini dengan ketara mengurangkan masa dan sumber yang diperlukan untuk menala DBMS yang baru digunakan. Untuk tujuan ini, OtterTune mengekalkan pangkalan data yang mengandungi data penalaan yang dikumpul daripada sesi penalaan sebelumnya. Ia menggunakan data ini untuk membina model pembelajaran mesin yang menangkap maklumat tentang cara DBMS bertindak balas terhadap konfigurasi yang berbeza. OtterTune menggunakan model ini untuk membimbing pengguna apabila mencuba aplikasi baharu, mencadangkan tetapan yang meningkatkan matlamat tertentu, seperti mengurangkan kependaman atau meningkatkan daya pengeluaran.
Dalam artikel ini, kami meneroka setiap komponen saluran pembelajaran mesin OtterTune dan menunjukkan cara ia berkait antara satu sama lain untuk menyesuaikan konfigurasi DBMS anda. Kami kemudiannya menilai prestasi OtterTune pada MySQL dan Postgres dengan membandingkan prestasi konfigurasi optimumnya dengan konfigurasi yang dipilih oleh pentadbir pangkalan data (DBA) dan alat penalaan automatik yang lain.
OtterTune ialah alat sumber terbuka yang dibangunkan oleh pelajar dan penyelidik dalam Kumpulan Pangkalan Data di Universiti Carnegie Mellon. Semua kod diletakkan pada GitHub (https://github.com/cmu-db/ottertune) dan dikeluarkan di bawah Lesen Apache 2.0.
Cara ia berfungsiGambar di bawah menunjukkan komponen dan aliran kerja OtterTune.
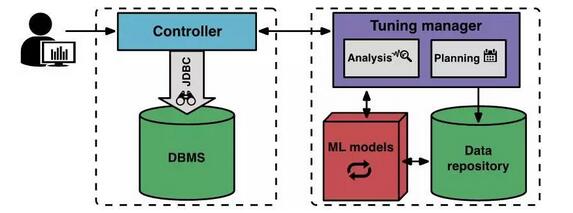
Pada permulaan sesi penalaan baharu, pengguna memberitahu OtterTune matlamat khusus yang hendak dioptimumkan (seperti kependaman atau daya pemprosesan). Pengawal klien menyambung kepada DBMS sasaran dan mengumpul jenis contoh Amazon EC2 dan sasaran semasa.
Pengawal kemudian memulakan tempoh pemerhatian pertama, di mana ia memerhati DBMS dan merekodkan sasaran tertentu. Selepas tempoh pemerhatian tamat, pengawal mengumpul metrik dalaman daripada DBMS, seperti kiraan MySQL halaman yang dibaca daripada cakera dan halaman yang ditulis ke cakera. Pengawal mengembalikan kedua-dua matlamat khusus dan metrik dalaman kepada pengurus penalaan.
Selepas pengurus penalaan OtterTune menerima metrik, ia menyimpannya dalam repositori. OtterTune menggunakan keputusan untuk mengira konfigurasi seterusnya yang harus dipasang oleh pengawal pada DBMS sasaran. Pengurus penalaan mengembalikan konfigurasi ini kepada pengawal dan menganggarkan peningkatan yang dijangkakan melalui larian sebenar. Pengguna boleh memutuskan untuk meneruskan sesi penalaan atau menamatkannya.
ArahanOtterTune mengekalkan senarai hitam butang untuk setiap versi DBMS yang disokongnya. Senarai hitam termasuk butang yang tidak perlu ditala (seperti nama laluan fail storan DBMS), atau butang yang mungkin mempunyai akibat yang serius atau tersembunyi (seperti yang boleh menyebabkan DBMS kehilangan data). Pada permulaan setiap sesi penalaan, OtterTune menyediakan senarai hitam kepada pengguna supaya mereka boleh menambah sebarang butang lain yang mereka mahu OtterTune mengelakkan penalaan.
OtterTune membuat andaian tertentu yang mungkin mengehadkan kegunaannya kepada sesetengah pengguna. Sebagai contoh, ia menganggap bahawa pengguna mempunyai hak pentadbir, membenarkan pengawal untuk mengubah suai konfigurasi DBMS. Jika pengguna tidak mempunyai hak pentadbir, mereka boleh menggunakan salinan kedua pangkalan data ke perkakasan lain untuk eksperimen penalaan OtterTune. Ini memerlukan pengguna memainkan semula surih beban kerja atau memajukan pertanyaan daripada DBMS gred pengeluaran. Untuk perbincangan lengkap tentang andaian dan had, lihat kertas kerja kami (http://db.cs.cmu.edu/papers/2017/tuning-sigmod2017.pdf).
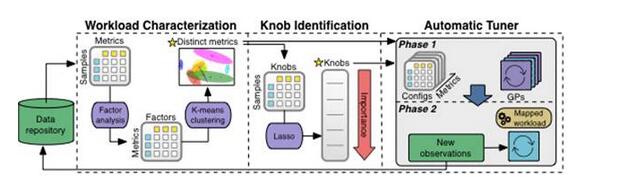
Saluran Paip Pembelajaran MesinImej di bawah menunjukkan cara data diproses semasa ia melalui saluran paip pembelajaran mesin OtterTune. Semua pemerhatian diletakkan dalam pangkalan data OtterTune.
OtterTune mula-mula menghantar hasil pemerhatian ke komponen Pencirian Beban Kerja. Komponen ini mengenal pasti set kecil metrik DBMS yang paling tepat menangkap perubahan prestasi dan ciri unik beban kerja yang berbeza.
Seterusnya, komponen Pengenalpastian Tombol menjana senarai pengisihan butang, menyenaraikan butang yang mempunyai kesan paling besar terhadap prestasi DBMS. OtterTune kemudian menyuapkan semua maklumat ini ke Automatic Tuner. Komponen ini memetakan beban kerja DBMS sasaran kepada beban kerja yang paling serupa dalam repositori data dan menggunakan semula data beban kerja untuk menjana konfigurasi yang lebih sesuai.

Sekarang mari kita menyelami setiap komponen saluran paip pembelajaran mesin.
Pencirian Beban Kerja: OtterTune menggunakan metrik masa jalan dalaman DBMS untuk menerangkan ciri tingkah laku beban kerja. Metrik ini mewakili beban kerja dengan tepat kerana ia menangkap banyak aspek tingkah laku masa jalan. Walau bagaimanapun, banyak metrik adalah berlebihan: sesetengahnya adalah metrik yang sama direkodkan dalam unit yang berbeza, dan yang lain mewakili bahagian bebas DBMS yang sangat berkorelasi secara berangka. Memperkemas metrik berlebihan adalah penting kerana ia mengurangkan kerumitan model pembelajaran mesin yang menggunakannya. Untuk tujuan ini, kami membahagikan metrik DBMS kepada kelompok berdasarkan corak korelasi. Kami kemudian memilih metrik perwakilan daripada setiap kluster, khususnya yang paling hampir dengan pusat kluster. Komponen seterusnya dalam saluran paip pembelajaran mesin menggunakan metrik ini.
Pengenalan Tombol: DBMS mungkin mempunyai beratus-ratus butang, tetapi hanya sebilangan kecil butang yang mempengaruhi prestasi DBMS. OtterTune menggunakan teknik pemilihan ciri popular yang dipanggil Lasso untuk menentukan butang yang mempengaruhi prestasi keseluruhan sistem anda dengan ketara. Dengan menggunakan teknik ini pada data dalam pangkalan data, OtterTune boleh mengenal pasti kepentingan susunan butang DBMS.
OtterTune kemudiannya perlu memutuskan berapa banyak butang untuk digunakan dalam konfigurasi yang dicadangkan. Menggunakan terlalu banyak butang meningkatkan masa pengoptimuman OtterTune. Menggunakan terlalu sedikit butang menghalang OtterTune daripada mencari konfigurasi optimum. Untuk mengautomasikan proses ini, OtterTune menggunakan pendekatan tambahan. Ia secara beransur-ansur meningkatkan bilangan butang yang digunakan dalam sesi penalaan. Pendekatan ini membolehkan OtterTune meneroka dan mengoptimumkan konfigurasi untuk set kecil butang yang paling penting, dan kemudian mengembangkan skop untuk mempertimbangkan butang tambahan.
Penala Automatik: Komponen Penalaan Automatik menentukan konfigurasi yang OtterTune patut cadangkan dengan melakukan analisis dua langkah selepas setiap tempoh pemerhatian.
Pertama, sistem mengenal pasti beban kerja daripada sesi penalaan sebelumnya yang paling mewakili beban kerja DBMS sasaran menggunakan data prestasi berbanding metrik yang dikenal pasti dalam komponen Pencirian Beban Kerja. Ia membandingkan metrik sesi dengan metrik daripada beban kerja sebelumnya untuk melihat mana yang bertindak balas serupa kepada tetapan butang yang berbeza.
Kemudian, OtterTune memilih konfigurasi butang lain untuk mencubanya. Ia sesuai dengan model statistik dengan data yang telah dikumpul, serta data daripada beban kerja yang paling serupa dalam repositori. Model ini membolehkan OtterTune meramalkan prestasi DBMS menggunakan setiap konfigurasi yang mungkin. OtterTune mengoptimumkan konfigurasi seterusnya untuk mencapai keseimbangan antara penerokaan (mengumpul maklumat untuk menambah baik model) dan eksploitasi (berprestasi sebaik mungkin pada metrik tertentu).
TercapaiOtterTune ditulis dalam Python.
Mengenai Pencirian Beban Kerja dan Pengenalpastian Tombol, prestasi masa jalan bukanlah isu utama yang perlu dibimbangkan, jadi kami menggunakan scikit-lear untuk melaksanakan algoritma pembelajaran mesin yang sepadan. Algoritma ini berjalan dalam proses latar belakang dan akan menyepadukan data baharu sebaik sahaja ia tersedia dalam pangkalan data OtterTune.
Bagi Penala Automatik, algoritma pembelajaran mesin berada di laluan kritikal. Ia dijalankan selepas setiap tempoh pemerhatian, menyepadukan data baharu supaya OtterTune boleh memilih konfigurasi butang untuk mencuba seterusnya. Memandangkan prestasi adalah pertimbangan, kami melaksanakan algoritma ini menggunakan TensorFlow.
Untuk mengumpul data tentang perkakasan DBMS, konfigurasi butang dan metrik prestasi masa jalan, kami menyepadukan pengawal OtterTune dengan rangka kerja penanda aras OLTP-Bench.
PenilaianUntuk menilai, kami membandingkan konfigurasi terbaik yang dipilih oleh OtterTune dengan konfigurasi berikut untuk prestasi MySQL dan Postgres:
- Lalai: Konfigurasi disediakan oleh DBMS
- Skrip penalaan: Konfigurasi yang dihasilkan oleh alat nasihat penalaan sumber terbuka
- DBA: Konfigurasi yang dijana oleh pentadbir pangkalan data
- RDS: Konfigurasi disesuaikan untuk DBMS, diurus oleh Amazon RD, digunakan pada jenis contoh EC2 yang sama.
Kami menjalankan semua percubaan di Amazon EC2 Spot Instances. Kami menjalankan setiap percubaan pada dua keadaan: satu untuk pengawal OtterTune dan satu lagi untuk sistem DBMS sasaran yang digunakan. Kami menggunakan jenis contoh m4.large dan m3.xlarge masing-masing. Kami menggunakan pengurus penalaan dan pustaka data OtterTune pada pelayan tempatan yang dilengkapi dengan 20 teras dan memori 128GB.
Kami menggunakan beban kerja TPC-C, yang merupakan piawaian industri untuk menilai prestasi sistem pemprosesan transaksi dalam talian (OLTP).
Kami mengukur kependaman dan daya pemprosesan terhadap setiap pangkalan data yang kami gunakan dalam eksperimen kami: MySQL dan Postgres. Angka berikut menunjukkan keputusan. Graf pertama menunjukkan jumlah kependaman persentil ke-99, yang mewakili masa "kes terburuk" yang diperlukan untuk transaksi selesai. Graf kedua menunjukkan keputusan untuk pemprosesan, diukur sebagai purata bilangan urus niaga yang diselesaikan sesaat.
Hasil MySQL:
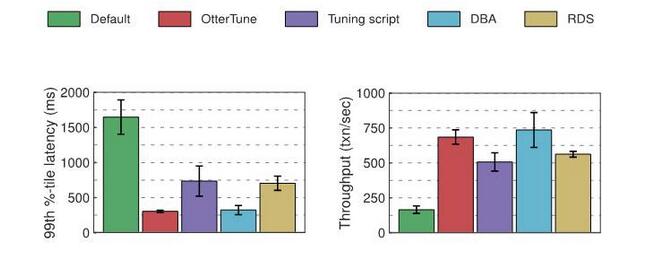
Membandingkan konfigurasi optimum yang dijana oleh OtterTune dengan konfigurasi yang dijana oleh skrip penalaan dan RDS, anda akan mendapati bahawa jika anda menggunakan konfigurasi OtterTune, kependaman MySQL dikurangkan sebanyak kira-kira 60% dan daya pemprosesan meningkat sebanyak 35%. OtterTune juga menghasilkan konfigurasi dengan hasil yang sebaik yang dipilih oleh pentadbir pangkalan data.
Beberapa butang MySQL mempunyai impak yang ketara pada prestasi beban kerja TPC-C. Konfigurasi yang dijana oleh OtterTune dan pentadbir pangkalan data menyediakan tetapan yang baik untuk setiap butang ini. RDS berprestasi sedikit kurang baik kerana menyediakan tetapan sub-optimum untuk satu butang. Konfigurasi skrip penalaan melakukan yang paling teruk kerana hanya satu butang diubah suai.
Keputusan untuk Postgres:
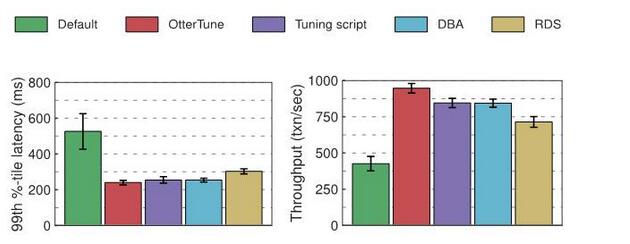
Dari segi kependaman, OtterTune, alat penalaan, pengurusan pangkalan data dan konfigurasi yang dijana RDS semuanya menunjukkan peningkatan yang sama berbanding tetapan lalai Postgres. Kita mungkin boleh mengaitkan ini kepada overhed yang diperlukan untuk perjalanan pergi dan balik antara klien OLTP-Bench dan DBMS melalui rangkaian. Bagi daya pemprosesan, jika anda menggunakan konfigurasi yang disyorkan oleh OtterTune, prestasi Postgres adalah kira-kira 12% lebih tinggi daripada konfigurasi yang dipilih oleh pentadbir pangkalan data dan skrip penalaan, dan kira-kira 32% lebih tinggi daripada RDS.
Sama seperti MySQL, terdapat hanya beberapa butang yang memberi impak ketara kepada prestasi Postgres. OtterTune, pentadbir pangkalan data, skrip penalaan dan konfigurasi yang dijana RDS semuanya mengubah suai butang ini, dan kebanyakannya menyediakan tetapan yang cukup baik.
KesimpulanOtterTune mengautomasikan proses mencari tetapan yang betul untuk butang konfigurasi DBMS. Untuk menala DBMS yang baru digunakan, ia menggunakan semula data latihan yang dikumpul daripada sesi penalaan sebelumnya. Oleh kerana OtterTune tidak memerlukan penjanaan set data awal untuk melatih model pembelajaran mesin, masa penalaan dikurangkan dengan ketara.
Apa seterusnya? Untuk menampung peningkatan populariti penggunaan DBaaS yang tidak mempunyai akses jauh kepada sistem hos DBMS, OtterTune tidak lama lagi akan dapat mengesan secara automatik keupayaan perkakasan DMBS sasaran tanpa memerlukan akses jauh.
Untuk butiran lanjut tentang OtterTune, lihat kertas kami atau kod di GitHub. Sila beri perhatian kepada tapak web ini (http://ottertune.cs.cmu.edu/), kami akan melancarkan OtterTune, perkhidmatan penalaan dalam talian tidak lama lagi.
Mengenai pengarang:
Dana Van Aken ialah pelajar PhD dalam sains komputer di Carnegie Mellon University, dibimbing oleh Dr. Andrew Pavlo.
Andy Pavlo ialah penolong profesor sains pangkalan data di Jabatan Sains Komputer di Universiti Carnegie Mellon.
Geoff Gordon ialah seorang profesor bersekutu dan pengarah pendidikan bersekutu di Jabatan Pembelajaran Mesin di Universiti Carnegie Mellon.
Atas ialah kandungan terperinci Adakah pembelajaran mesin akan menyebabkan pengendali sistem pengurusan pangkalan data tidak bekerja?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Konfigurasi komputer apa yang diperlukan untuk vscode
Apr 15, 2025 pm 09:48 PM
Konfigurasi komputer apa yang diperlukan untuk vscode
Apr 15, 2025 pm 09:48 PM
Keperluan Sistem Kod Vs: Sistem Operasi: Windows 10 dan ke atas, MACOS 10.12 dan ke atas, pemproses pengedaran Linux: minimum 1.6 GHz, disyorkan 2.0 GHz dan ke atas memori: minimum 512 MB, disyorkan 4 GB dan ke atas ruang penyimpanan: minimum 250 mb, disyorkan 1 GB dan di atas keperluan lain:
 Apr 16, 2025 pm 07:39 PM
Apr 16, 2025 pm 07:39 PM
Walaupun Notepad tidak dapat menjalankan kod Java secara langsung, ia dapat dicapai dengan menggunakan alat lain: menggunakan pengkompil baris arahan (Javac) untuk menghasilkan fail bytecode (fileName.class). Gunakan Java Interpreter (Java) untuk mentafsir bytecode, laksanakan kod, dan output hasilnya.
 Seni Bina Linux: Melancarkan 5 Komponen Asas
Apr 20, 2025 am 12:04 AM
Seni Bina Linux: Melancarkan 5 Komponen Asas
Apr 20, 2025 am 12:04 AM
Lima komponen asas sistem Linux adalah: 1. Kernel, 2. Perpustakaan Sistem, 3. Utiliti Sistem, 4. Antara Muka Pengguna Grafik, 5. Aplikasi. Kernel menguruskan sumber perkakasan, Perpustakaan Sistem menyediakan fungsi yang telah dikompilasi, utiliti sistem digunakan untuk pengurusan sistem, GUI menyediakan interaksi visual, dan aplikasi menggunakan komponen ini untuk melaksanakan fungsi.
 VSCode tidak dapat memasang pelanjutan
Apr 15, 2025 pm 07:18 PM
VSCode tidak dapat memasang pelanjutan
Apr 15, 2025 pm 07:18 PM
Sebab -sebab pemasangan sambungan kod VS mungkin: ketidakstabilan rangkaian, kebenaran yang tidak mencukupi, isu keserasian sistem, versi kod VS terlalu lama, perisian antivirus atau gangguan firewall. Dengan menyemak sambungan rangkaian, keizinan, fail log, mengemas kini kod VS, melumpuhkan perisian keselamatan, dan memulakan semula kod VS atau komputer, anda boleh menyelesaikan masalah dan menyelesaikan masalah secara beransur -ansur.
 Cara memeriksa alamat gudang git
Apr 17, 2025 pm 01:54 PM
Cara memeriksa alamat gudang git
Apr 17, 2025 pm 01:54 PM
Untuk melihat alamat repositori Git, lakukan langkah -langkah berikut: 1. Buka baris arahan dan navigasi ke direktori repositori; 2. Jalankan perintah "Git Remote -V"; 3. Lihat nama repositori dalam output dan alamat yang sepadan.
 Boleh vscode digunakan untuk mac
Apr 15, 2025 pm 07:36 PM
Boleh vscode digunakan untuk mac
Apr 15, 2025 pm 07:36 PM
VS Kod boleh didapati di Mac. Ia mempunyai sambungan yang kuat, integrasi git, terminal dan debugger, dan juga menawarkan banyak pilihan persediaan. Walau bagaimanapun, untuk projek yang sangat besar atau pembangunan yang sangat profesional, kod VS mungkin mempunyai prestasi atau batasan fungsi.
 Cara menggunakan vscode
Apr 15, 2025 pm 11:21 PM
Cara menggunakan vscode
Apr 15, 2025 pm 11:21 PM
Visual Studio Code (VSCode) adalah editor cross-platform, sumber terbuka dan editor kod percuma yang dibangunkan oleh Microsoft. Ia terkenal dengan ringan, skalabilitas dan sokongan untuk pelbagai bahasa pengaturcaraan. Untuk memasang VSCode, sila lawati laman web rasmi untuk memuat turun dan jalankan pemasang. Apabila menggunakan VSCode, anda boleh membuat projek baru, edit kod, kod debug, menavigasi projek, mengembangkan VSCode, dan menguruskan tetapan. VSCode tersedia untuk Windows, MacOS, dan Linux, menyokong pelbagai bahasa pengaturcaraan dan menyediakan pelbagai sambungan melalui pasaran. Kelebihannya termasuk ringan, berskala, sokongan bahasa yang luas, ciri dan versi yang kaya
 Tutorial Penggunaan Terminal VSCode
Apr 15, 2025 pm 10:09 PM
Tutorial Penggunaan Terminal VSCode
Apr 15, 2025 pm 10:09 PM
VSCODE Terminal terbina dalam adalah alat pembangunan yang membolehkan arahan dan skrip berjalan dalam editor untuk memudahkan proses pembangunan. Cara Menggunakan VSCode Terminal: Buka terminal dengan kekunci pintasan (Ctrl/Cmd). Masukkan arahan atau jalankan skrip. Gunakan hotkeys (seperti Ctrl L untuk membersihkan terminal). Tukar direktori kerja (seperti perintah CD). Ciri -ciri lanjutan termasuk mod debug, penyelesaian coretan kod automatik, dan sejarah arahan interaktif.
