


Dalam kehidupan seharian, pengekstrakan tangkapan skrin dan soalan carian foto digunakan secara meluas dalam teknologi OCR (Optical Character Recognition), yang merupakan teknologi yang sangat penting dalam bidang pengecaman teks
OCR (Optical Character Recognition) ialah kaedah pengecaman teks komputer yang menggunakan teknologi optik dan komputer untuk menukar imej teks bercetak atau tulisan tangan kepada format teks yang tepat dan boleh dibaca komputer pengiktirafan dan aplikasi. Teknologi pengecaman OCR semakin banyak digunakan dalam pelbagai industri kehidupan moden Ia adalah teknologi utama untuk memasukkan kandungan teks dengan cepat ke dalam komputer
Perkara utama. Teknologi OCR Terdapat dua sekolah OCR tradisional dan OCR pembelajaran mendalam.
Pada zaman awal perkembangan teknologi OCR, juruteknik menggunakan teknologi pemprosesan imej seperti perduaan, analisis domain bersambung dan analisis unjuran, digabungkan dengan pembelajaran mesin statistik (seperti Adaboost dan SVM) untuk mengekstrak kandungan teks imej, yang kami bersatu Ia diklasifikasikan sebagai OCR tradisional Ciri utamanya ialah ia bergantung pada operasi prapemprosesan data yang kompleks untuk membetulkan dan mengurangkan hingar pada imej. Kebolehsuaian ialah keupayaan kritikal dalam persekitaran yang berubah-ubah. Seseorang yang mempunyai kebolehsuaian yang baik boleh menyesuaikan diri dengan situasi dan keperluan baharu, cepat menyesuaikan diri dengan perubahan, dan mencari penyelesaian kepada masalah. Kebolehsuaian juga merupakan salah satu faktor utama kejayaan dalam kehidupan peribadi dan profesional seseorang. Oleh itu, kita harus berusaha untuk memupuk dan meningkatkan kebolehsuaian kita untuk menghadapi dunia yang berubah dengan ketepatan dan kelajuan tindak balas yang lemah.
Terima kasih kepada pembangunan teknologi AI yang berterusan, teknologi OCR berdasarkan pembelajaran mendalam hujung-ke-hujung telah beransur-ansur matang Kelebihan kaedah ini ialah ia tidak perlu memperkenalkan pautan pemotongan teks secara eksplisit dalam imej pra -peringkat pemprosesan, tetapi menukarkan pengecaman teks kepada pembelajaran urutan Masalah, menyepadukan pembahagian teks ke dalam pembelajaran mendalam adalah sangat penting kepada peningkatan teknologi OCR dan hala tuju pembangunan masa hadapan.
Carta aliran pemprosesan teknologi OCR tradisional adalah seperti berikut:

imej teks diimbas oleh peranti , ia memasuki peringkat prapemprosesan Memandangkan terdapat faktor yang mengganggu dalam pelbagai media teks, seperti kelancaran dan kualiti pencetakan kertas, cahaya dan kegelapan skrin, dsb., yang akan menyebabkan herotan teks, adalah perlu untuk melaksanakannya. kaedah pra-pemprosesan seperti pelarasan kecerahan, peningkatan imej, dan penapisan hingar pada imej. Kedudukan kawasan teks
: Untuk penentududukan dan pengekstrakan kawasan teks, kaedah terutamanya termasuk pengesanan domain bersambung dan pengesanan MSER. Pembetulan teks dan imej
: Pembetulan teks senget untuk memastikan mendatar Kaedah pembetulan terutamanya termasuk pembetulan mendatar dan pembetulan perspektif. Pembahagian perkataan tunggal dalam baris dan lajur
: Pengecaman teks tradisional adalah berdasarkan pengecaman aksara tunggal, dan kaedah pembahagian terutamanya menggunakan kontur domain bersambung dan pemotongan unjuran menegak. Pengecaman aksara pengelas
: Gunakan algoritma pengekstrakan ciri seperti HOG dan Ayak untuk mengekstrak maklumat vektor daripada aksara, dan gunakan algoritma SVM, regresi logistik, mesin vektor sokongan, dsb. untuk latihan. Pemprosesan pasca
2.2 Pembelajaran Dalam OCR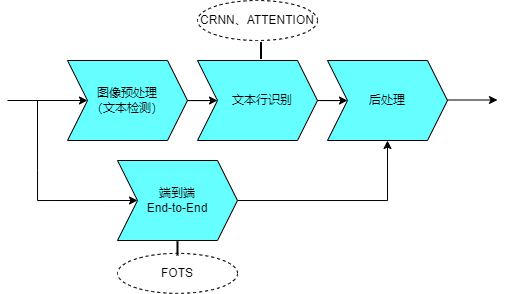
Gambar
Algoritma OCR pembelajaran mendalam arus perdana memodelkan dua peringkat pengesanan teks dan pengecaman teks secara berasingan.
Pengesanan teks boleh dibahagikan kepada kaedah berasaskan regresi dan berasaskan segmentasi. Kaedah regresi termasuk algoritma seperti CTPN, Textbox dan EAST, yang boleh mengesan teks arah dalam imej, tetapi akan dipengaruhi oleh penyelewengan dalam kawasan teks. Kaedah pembahagian seperti algoritma PSENet boleh mengendalikan teks pelbagai bentuk dan saiz, tetapi teks yang lebih dekat terdedah kepada masalah melekat. Kaedah yang berbeza mempunyai kelebihan dan kelemahan tersendiri
🎜Peringkat pengecaman teks terutamanya menggunakan dua teknologi utama, CRNN dan ATTENTION, untuk mengubah pengecaman teks kepada masalah pembelajaran urutan Kedua-dua teknologi menggunakan rangkaian CNN+RNN dalam peringkat pembelajaran ciri mereka. struktur, perbezaannya terletak pada lapisan keluaran akhir (lapisan terjemahan), iaitu cara menukar maklumat ciri jujukan yang dipelajari oleh rangkaian kepada hasil pengiktirafan akhir. 🎜🎜Selain itu, terdapat algoritma hujung ke hujung terkini yang menyepadukan secara langsung pengesanan teks dan pengecaman teks ke dalam model rangkaian tunggal untuk pembelajaran. Contohnya, algoritma seperti FOTS dan Mask TextSpotter. Berbanding dengan pengesanan teks bebas dan kaedah pengecaman teks, algoritma ini mempunyai kelajuan pengecaman yang lebih pantas tetapi ketepatan relatif yang lebih lemah
Pengiktirafan tradisionaldasar |
algoritma
|
yang mendasari | algoritma
|
terbahagi kepada peringkat pengesanan dan pengecaman proses , gunakan Gabungan algoritma berbeza |
Matlamat model ini adalah untuk menggabungkan proses pengesanan dan pengiktirafan untuk mencapai kestabilan keseluruhan tahap ke tahap-ke-akhir adalah miskin |
Selepas pengoptimuman hujung ke hujung, kestabilan sistem telah dipertingkatkan dengan ketara
|
| Pengiktirafan Ketepatan |
narios dengan sampel kecil mempunyai ketepatan yang rendah Ia mempunyai kelebihan tertentu
|
Ketepatan lebih tinggi, lebih dalam tahap gabungan, ketepatan beransur-ansur berkurangan Pengiktirafan lebih perlahan |
| Pengiktirafan pantas
|
||
|
Senario Kepentingan penyesuaian tidak boleh diabaikan. Kebolehsuaian ialah keupayaan kritikal dalam persekitaran yang berubah-ubah. Seseorang yang mempunyai kebolehsuaian yang baik boleh menyesuaikan diri dengan situasi dan keperluan baharu, cepat menyesuaikan diri dengan perubahan, dan mencari penyelesaian kepada masalah. Kebolehsuaian juga merupakan salah satu faktor utama kejayaan dalam kehidupan peribadi dan profesional seseorang. Oleh itu, kita harus berusaha untuk memupuk dan meningkatkan kebolehsuaian kita untuk menghadapi dunia yang sentiasa berubah |
lemah, sesuai untuk format cetakan standard |
kuat, serasi dengan senario bergantung kepada model yang kompleks |
Anti-gangguan |
Lemah, keperluan yang lebih tinggi untuk imej input |
Kuat, bergantung pada latihan model |
Kadar ketepatan: merujuk kepada nisbah bilangan aksara yang diiktiraf dengan betul oleh sistem OCR kepada jumlah bilangan aksara yang diiktiraf oleh sistem Ia digunakan untuk mengukur berapa banyak hasil pengecaman sistem yang benar-benar betul . Lebih tinggi nilainya, lebih baik hasil pengiktirafannya.
Nilai F1: Penunjuk penilaian yang menggabungkan ingatan semula dan kejituan Nilai F1 adalah antara 0 dan 1. Semakin tinggi nilai, semakin baik keseimbangan antara ketepatan dan penarikan balik yang dicapai oleh sistem.
Purata Jarak Edit (Purata Jarak Edit) ialah penunjuk yang digunakan untuk menilai tahap perbezaan antara hasil pengecaman OCR dan teks sebenar
Bahagian 04,
Atas ialah kandungan terperinci Terokai prinsip dan senario aplikasi pengecaman OCR. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



