

Karya baharu daripada Apple ini akan membawa imaginasi tanpa had kepada keupayaan untuk menambah model besar pada iPhone masa hadapan.
Dalam beberapa tahun kebelakangan ini, model bahasa besar (LLM) seperti GPT-3, OPT dan PaLM telah menunjukkan prestasi yang kukuh dalam pelbagai tugas pemprosesan bahasa semula jadi (NLP). Walau bagaimanapun, untuk mencapai prestasi ini memerlukan inferens pengiraan dan ingatan yang luas, kerana model bahasa yang besar ini mungkin mengandungi ratusan bilion atau bahkan trilion parameter, menjadikannya mencabar untuk memuatkan dan berjalan dengan cekap pada peranti terhad sumber
Pada masa ini Penyelesaian standard adalah untuk memuatkan keseluruhan model ke dalam DRAM untuk inferens, namun ini sangat mengehadkan saiz model maksimum yang boleh dijalankan. Sebagai contoh, model parameter 7 bilion memerlukan lebih daripada 14GB memori untuk memuatkan parameter dalam format titik terapung separuh ketepatan, yang di luar keupayaan kebanyakan peranti tepi.
Untuk menyelesaikan had ini, penyelidik Apple mencadangkan untuk menyimpan parameter model dalam memori kilat, yang sekurang-kurangnya tertib magnitud lebih besar daripada DRAM. Kemudian semasa inferens, mereka secara langsung dan bijak memuatkan parameter yang diperlukan, menghapuskan keperluan untuk memasukkan keseluruhan model ke dalam DRAM.
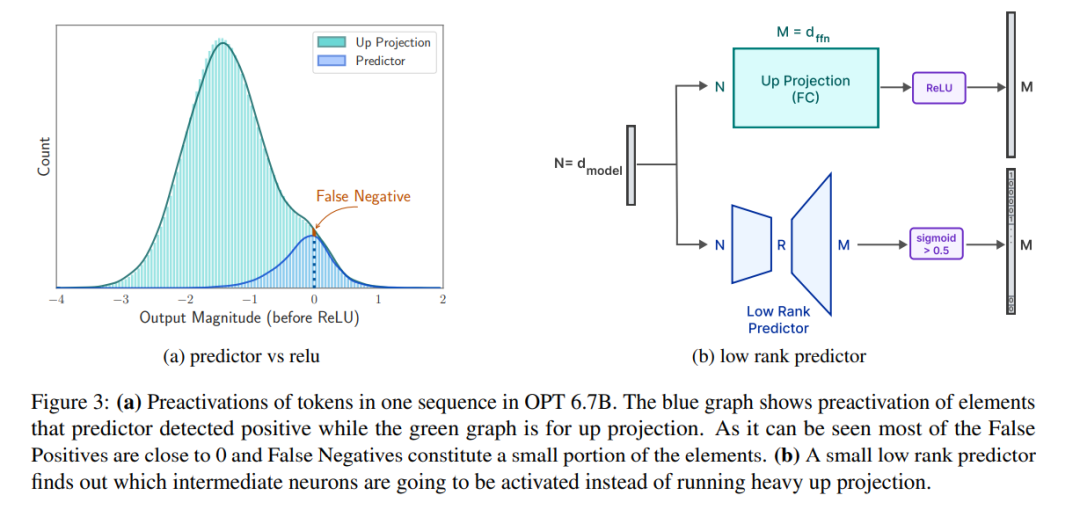
Pendekatan ini dibina berdasarkan kerja baru-baru ini yang menunjukkan bahawa LLM mempamerkan tahap sparsity yang tinggi dalam lapisan rangkaian feedforward (FFN), dengan model seperti OPT dan Falcon mencapai sparsity melebihi 90%. Oleh itu, kami mengeksploitasi keterbatasan ini untuk memuatkan secara terpilih daripada memori kilat hanya parameter yang mempunyai input bukan sifar atau diramalkan mempunyai output bukan sifar.

Alamat kertas: https://arxiv.org/pdf/2312.11514.pdf
Secara khusus, para penyelidik membincangkan model kos yang diilhamkan oleh perkakasan yang merangkumi memori kilat, DRAM dan teras pengkomputeran (CPU atau GPU). Kemudian dua teknik pelengkap diperkenalkan untuk meminimumkan pemindahan data dan memaksimumkan pemprosesan kilat:
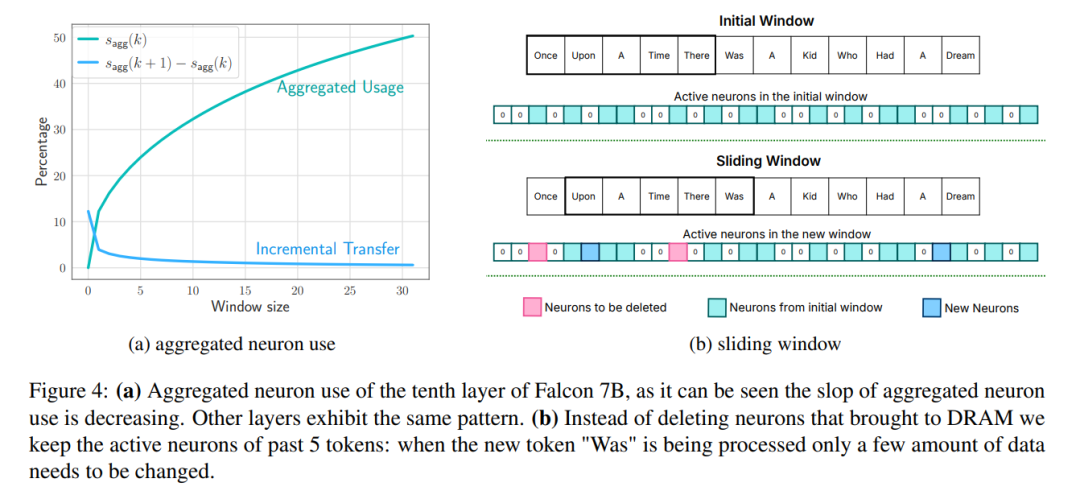
Tetingkap: hanya memuatkan parameter beberapa teg pertama dan menggunakan semula pengaktifan teg yang paling baru dikira. Pendekatan tetingkap gelongsor ini mengurangkan bilangan permintaan IO untuk memuatkan pemberat; Ini akan meningkatkan daya pengeluaran dengan membaca blok yang lebih besar.
Untuk mengurangkan lagi bilangan pemberat yang dipindahkan daripada denyar ke DRAM, para penyelidik cuba meramalkan kesederhanaan FFN dan mengelak daripada memuatkan parameter sifar. Dengan menggunakan gabungan ramalan windowing dan sparsity, hanya 2% daripada lapisan FFN denyar dimuatkan bagi setiap pertanyaan inferens. Mereka juga mencadangkan pra-peruntukan memori statik untuk meminimumkan pemindahan intra-DRAM dan mengurangkan kependaman inferens
Keterbatasan Lebar Jalur dan Tenaga
Walaupun denyar NAND moden menawarkan lebar jalur yang tinggi dan kependaman rendah, ia masih kurang daripada tahap prestasi DRAM, terutamanya dalam sistem kekangan memori. Rajah 2a di bawah menggambarkan perbezaan ini. Pelaksanaan inferens naif yang bergantung pada denyar NAND mungkin memerlukan pemuatan semula keseluruhan model untuk setiap hantaran hadapan, yang merupakan proses yang memakan masa yang walaupun memampatkan model mengambil masa beberapa saat. Selain itu, pemindahan data daripada DRAM ke memori CPU atau GPU memerlukan lebih banyak tenaga.
Dalam senario di mana DRAM mencukupi, kos pemuatan data dikurangkan dan model boleh berada dalam DRAM. Walau bagaimanapun, pemuatan awal model masih menggunakan tenaga, terutamanya jika token pertama memerlukan masa tindak balas yang cepat. Kaedah kami mengeksploitasi jarang pengaktifan dalam LLM untuk menangani cabaran ini dengan membaca berat model secara selektif, dengan itu mengurangkan kos masa dan tenaga.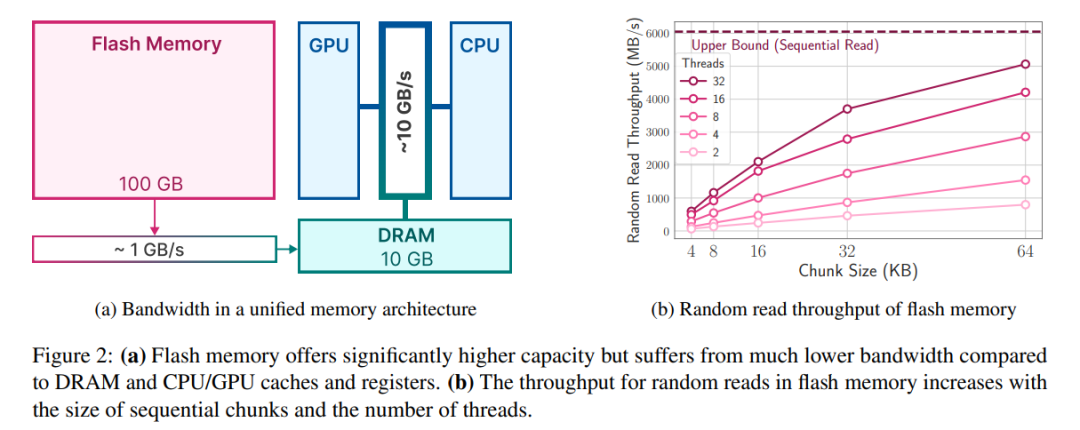
Sistem denyar berprestasi terbaik dengan banyak bacaan berurutan. Sebagai contoh, Apple MacBook Pro M2 dilengkapi dengan 2TB memori denyar, dan dalam ujian penanda aras, kelajuan bacaan linear 1GiB fail tidak dicache melebihi 6GiB/s. Walau bagaimanapun, bacaan rawak yang lebih kecil tidak dapat mencapai lebar jalur yang tinggi kerana sifat berbilang peringkat bacaan ini, termasuk sistem pengendalian, pemacu, pemproses jarak pertengahan dan pengawal denyar. Setiap peringkat memperkenalkan kependaman, yang mempunyai kesan yang lebih besar pada kelajuan bacaan yang lebih kecilUntuk memintas pengehadan ini, penyelidik menyokong dua strategi utama, yang boleh digunakan serentak.
Strategi pertama ialah membaca blok data yang lebih besar. Walaupun peningkatan dalam daya pengeluaran tidak linear (blok data yang lebih besar memerlukan masa pemindahan yang lebih lama), kelewatan dalam bait awal menyumbang bahagian yang lebih kecil daripada jumlah masa permintaan, menjadikan bacaan data lebih cekap. Rajah 2b menggambarkan prinsip ini. Pemerhatian kontra-intuitif tetapi menarik ialah dalam sesetengah kes, lebih cepat untuk membaca lebih banyak data daripada yang diperlukan (tetapi dalam ketulan yang lebih besar) dan kemudian membuangnya, daripada membaca hanya apa yang diperlukan tetapi dalam ketulan yang lebih kecil .
Strategi kedua ialah memanfaatkan keselarian yang wujud pada timbunan storan dan pengawal denyar untuk mencapai bacaan selari. Keputusan menunjukkan bahawa adalah mungkin untuk mencapai daya tampung yang sesuai untuk inferens LLM jarang menggunakan bacaan rawak berbilang benang sebanyak 32KiB atau lebih besar pada perkakasan standard.
Kunci untuk memaksimumkan daya pemprosesan terletak pada cara pemberat disimpan, kerana susun atur yang meningkatkan purata panjang blok boleh meningkatkan lebar jalur dengan ketara. Dalam sesetengah kes, ia mungkin berfaedah untuk membaca dan seterusnya membuang lebihan data, dan bukannya membahagikan data kepada ketulan yang lebih kecil dan kurang cekap.
Flash loading
Diinspirasikan oleh cabaran di atas, para penyelidik mencadangkan kaedah untuk mengoptimumkan volum pemindahan data dan meningkatkan kadar pemindahan data, yang boleh dinyatakan sebagai: Dapatkan kadar pemindahan data untuk meningkatkan kelajuan inferens dengan ketara. Bahagian ini membincangkan cabaran untuk melakukan inferens pada peranti yang memori pengiraan yang tersedia adalah jauh lebih kecil daripada saiz model.
Menganalisis cabaran ini memerlukan penyimpanan berat model lengkap dalam memori kilat. Metrik utama yang digunakan oleh penyelidik untuk menilai pelbagai strategi pemuatan denyar ialah kependaman, yang dibahagikan kepada tiga komponen berbeza: kos I/O untuk melaksanakan beban denyar, overhed memori untuk menguruskan data yang baru dimuatkan dan kos pengiraan bagi operasi inferens.
Apple membahagikan penyelesaian untuk mengurangkan kependaman di bawah kekangan memori kepada tiga kawasan strategik, setiap satu menyasarkan aspek kependaman tertentu:
1 Pengurangan beban data: Bertujuan untuk mengurangkan kependaman dengan memuatkan kurang data Kependaman yang dikaitkan dengan operasi I/O kilat.
2. Optimumkan saiz blok data: Tingkatkan daya pemprosesan denyar dengan meningkatkan saiz blok data yang dimuatkan, dengan itu mengurangkan kependaman.
Berikut ialah strategi yang digunakan oleh penyelidik untuk meningkatkan saiz blok data untuk meningkatkan kecekapan membaca denyar:
Menghimpun lajur dan baris
Penggabungan berasaskan pengaktifan bersama
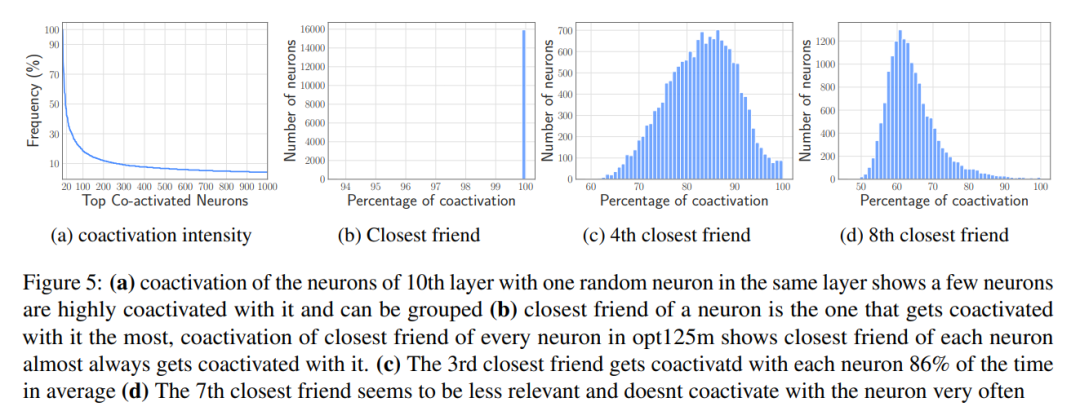
Kesan Kesan data yang dimuatkan: Permudahkan pengurusan data setelah ia dimuatkan ke dalam memori, meminimumkan overhed.
Walaupun memindahkan data dalam DRAM lebih cekap daripada mengakses memori denyar, ia menanggung kos yang tidak boleh diabaikan. Apabila memperkenalkan data untuk neuron baharu, memperuntukkan semula matriks dan menambah matriks baharu boleh menimbulkan overhed yang ketara kerana keperluan untuk menulis semula data neuron sedia ada dalam DRAM. Ini amat mahal apabila sebahagian besar (~25%) rangkaian suapan hadapan (FFN) dalam DRAM perlu ditulis semula.
Untuk menyelesaikan masalah ini, para penyelidik menggunakan strategi pengurusan ingatan yang lain. Strategi ini melibatkan pra-peruntukan semua memori yang diperlukan dan mewujudkan struktur data yang sepadan untuk pengurusan yang cekap. Seperti yang ditunjukkan dalam Rajah 6, struktur data termasuk elemen seperti penunjuk, matriks, offset, nombor terpakai dan last_k_active 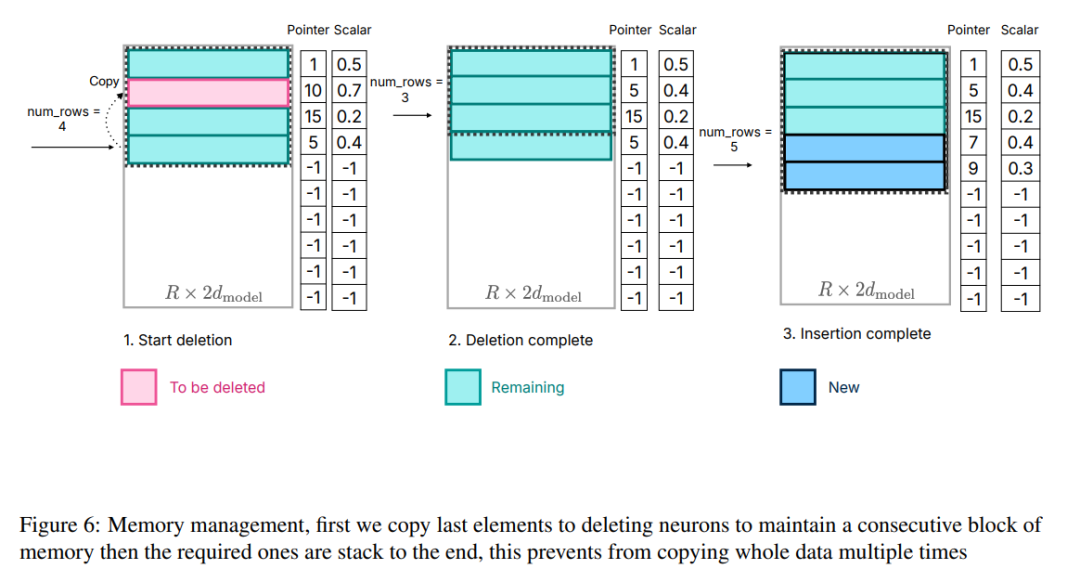
Rajah 6: Pengurusan memori, mula-mula salin elemen terakhir ke neuron padam untuk mengekalkan Kesinambungan blok memori dan kemudian menyusun elemen yang diperlukan hingga akhir, yang mengelakkan penyalinan keseluruhan data beberapa kali.
Perlu diingatkan bahawa tumpuan bukan pada proses pengiraan, kerana ia tidak ada kena mengena dengan kerja teras artikel ini. Pembahagian ini membolehkan penyelidik menumpukan pada mengoptimumkan interaksi denyar dan pengurusan memori untuk mencapai inferens yang cekap pada peranti terhad memori
Penulisan semula keputusan percubaan diperlukanKeputusan model OPT 6.7B
peramal. Seperti yang ditunjukkan dalam Rajah 3a, peramal kami boleh mengenal pasti dengan tepat kebanyakan neuron yang diaktifkan, tetapi kadangkala tersilap mengenal pasti neuron yang tidak diaktifkan dengan nilai yang hampir kepada sifar. Perlu diingat bahawa selepas neuron negatif palsu dengan nilai hampir sifar ini dihapuskan, hasil keluaran akhir tidak akan berubah dengan ketara. Tambahan pula, seperti yang ditunjukkan dalam Jadual 1, tahap ketepatan ramalan ini tidak menjejaskan prestasi model pada tugas pukulan sifar. 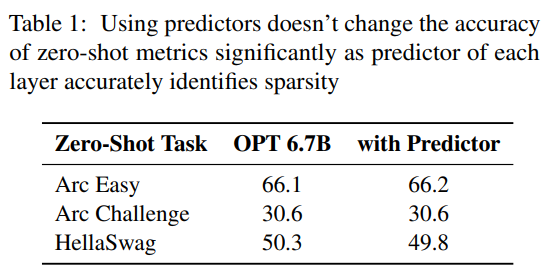
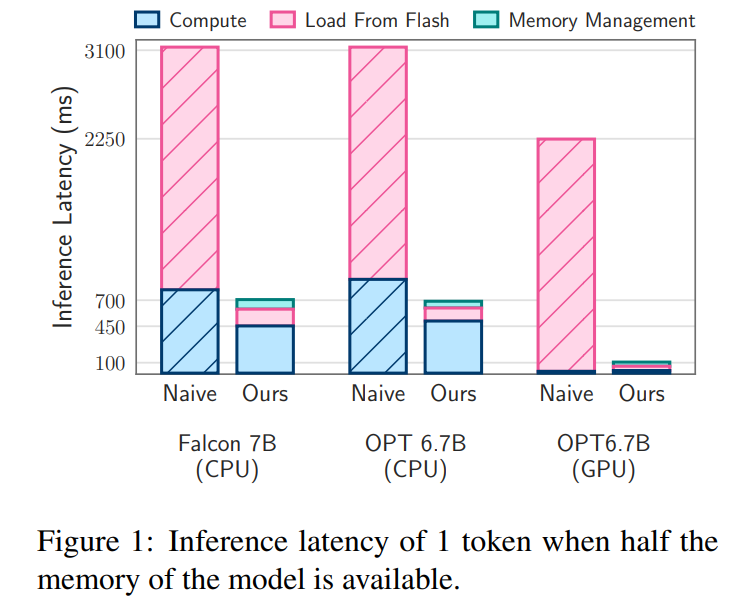
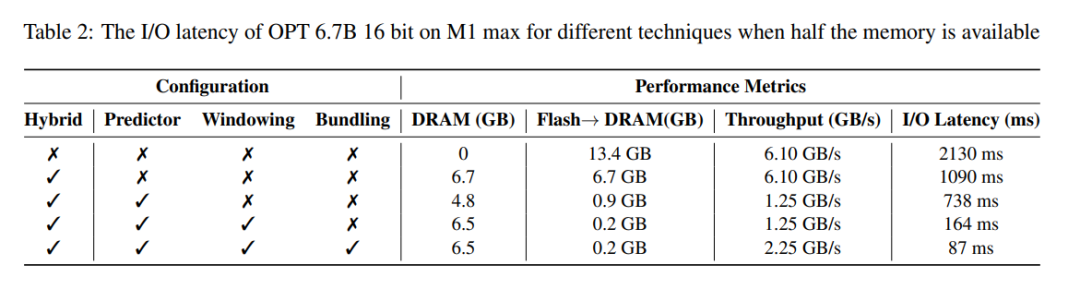
Analisis kependaman. Apabila saiz tetingkap ialah 5, setiap token perlu mengakses 2.4% daripada neuron rangkaian suapan hadapan (FFN). Untuk model 32-bit, saiz blok data setiap bacaan ialah 2dmodel × 4 bait = 32 KiB kerana ia melibatkan penggabungan baris dan lajur. Pada M1 Max, kependaman untuk pemuatan denyar bagi setiap token ialah 125 milisaat dan kependaman untuk pengurusan ingatan (termasuk pemadaman dan penambahan neuron) ialah 65 milisaat. Oleh itu, jumlah kependaman berkaitan memori adalah kurang daripada 190 milisaat bagi setiap token (lihat Rajah 1). Sebagai perbandingan, pendekatan garis dasar memerlukan pemuatan 13.4GB data pada 6.1GB/s, menghasilkan kependaman kira-kira 2330 milisaat setiap token. Oleh itu, kaedah kami bertambah baik berbanding kaedah garis dasar.
Untuk model 16-bit pada mesin GPU, masa beban denyar dikurangkan kepada 40.5 ms dan masa pengurusan memori ialah 40 ms, dengan sedikit peningkatan disebabkan oleh overhed tambahan untuk memindahkan data daripada CPU ke GPU. Walaupun begitu, masa I/O kaedah garis dasar masih melebihi 2000 ms.
Jadual 2 menyediakan perbandingan terperinci tentang kesan prestasi setiap kaedah.
Hasil model Falcon 7B
Analisis latensi. Menggunakan saiz tetingkap 4 dalam model kami, setiap token perlu mengakses 3.1% daripada neuron rangkaian suapan hadapan (FFN). Dalam model 32-bit, ini bersamaan dengan saiz blok 35.5 KiB setiap bacaan (dikira sebagai 2dmodel × 4 bait). Pada peranti M1 Max, pemuatan denyar data ini mengambil masa kira-kira 161 milisaat dan proses pengurusan memori menambah 90 milisaat lagi, jadi jumlah kependaman setiap token ialah 250 milisaat. Sebagai perbandingan, dengan kependaman garis dasar kira-kira 2330 milisaat, kaedah kami adalah lebih kurang 9 hingga 10 kali lebih pantas.
Atas ialah kandungan terperinci Pecutan inferens model: Prestasi CPU meningkat sebanyak 5 kali Apple menggunakan memori kilat untuk pecutan inferens berskala besar Adakah Siri 2.0 akan muncul?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah maksud perisikan data?
Apakah maksud perisikan data?
 Bagaimana untuk memasang sijil ssl
Bagaimana untuk memasang sijil ssl
 Pengenalan kepada peranti output dalam komputer
Pengenalan kepada peranti output dalam komputer
 Pengenalan kepada kekunci pintasan tangkapan skrin dalam sistem Windows 7
Pengenalan kepada kekunci pintasan tangkapan skrin dalam sistem Windows 7
 Peranan fungsi float() dalam python
Peranan fungsi float() dalam python
 Harga terkini Dogecoin hari ini
Harga terkini Dogecoin hari ini
 Sebab utama mengapa komputer menggunakan binari
Sebab utama mengapa komputer menggunakan binari
 Kekunci pintasan penukaran tetingkap
Kekunci pintasan penukaran tetingkap








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



