

Tugas penjanaan imej-ke-video (I2V) adalah cabaran dalam bidang penglihatan komputer yang bertujuan untuk menukar imej statik kepada video dinamik. Kesukaran tugas ini adalah untuk mengekstrak dan menjana maklumat dinamik dalam dimensi temporal daripada imej tunggal sambil mengekalkan keaslian dan keselarasan visual kandungan imej. Kaedah I2V sedia ada selalunya memerlukan seni bina model yang kompleks dan sejumlah besar data latihan untuk mencapai matlamat ini.
Baru-baru ini, hasil penyelidikan baharu "I2V-Adapter: A General Image-to-Video Adapter for Video Diffusion Models" yang diketuai oleh Kuaishou telah dikeluarkan. Penyelidikan ini memperkenalkan kaedah penukaran imej-ke-video yang inovatif dan mencadangkan modul penyesuai ringan, Penyesuai I2V. Modul penyesuai ini mampu menukar imej statik kepada video dinamik tanpa mengubah struktur asal dan parameter pra-latihan bagi model penjanaan teks-ke-video (T2V) sedia ada. Kaedah ini mempunyai prospek aplikasi yang luas dalam bidang penukaran imej kepada video, dan boleh membawa lebih banyak kemungkinan kepada penciptaan video, komunikasi media dan bidang lain. Pengeluaran hasil penyelidikan adalah sangat penting untuk mempromosikan pembangunan teknologi imej dan video, dan menyediakan alat dan kaedah yang berkesan untuk penyelidik dalam bidang berkaitan. . .html

Alamat kod: https://github.com/I2V-Adapter/I2V-Adapter-repo
Pengenalan imej,dibandingkan dengan penjanaan imej,dibandingkan dengan video bingkai video seks. Kebanyakan kaedah semasa adalah berdasarkan model T2I yang telah dilatih, seperti Stable Diffusion dan SDXL, dengan memperkenalkan modul pemasaan untuk memodelkan maklumat pemasaan dalam video. Diinspirasikan oleh AnimateDiff, model yang pada asalnya direka untuk tugas T2V tersuai, ia memodelkan maklumat pemasaan dengan memperkenalkan modul pemasaan yang dipisahkan daripada model T2I, dan mengekalkan keupayaan model T2I asal untuk menjana video yang lancar . Oleh itu, penyelidik percaya bahawa modul temporal pra-latihan boleh dianggap sebagai perwakilan temporal universal dan boleh digunakan pada senario penjanaan video lain, seperti penjanaan I2V, tanpa sebarang penalaan halus. Oleh itu, para penyelidik secara langsung menggunakan modul pemasaan AnimateDiff yang telah terlatih dan memastikan parameternya tetap.
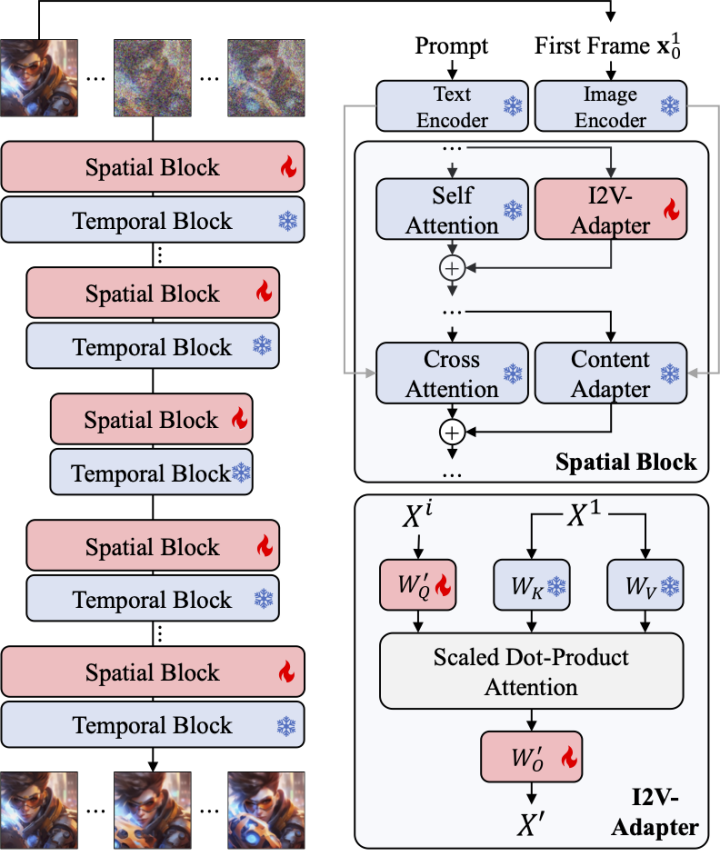
 Penyesuai untuk lapisan perhatian
Penyesuai untuk lapisan perhatian
Untuk menyelesaikan masalah di atas, penyelidik mencadangkan I2V-Adapter. Khususnya, penyelidik memasukkan imej input dan input hingar ke rangkaian secara selari Dalam blok ruang model, semua bingkai juga akan menanyakan maklumat bingkai pertama, iaitu ciri kunci dan nilai datang dari bingkai pertama tanpa bunyi. , dan output Hasilnya ditambah kepada perhatian diri model asal. Matriks pemetaan output dalam modul ini dimulakan dengan sifar dan hanya matriks pemetaan output dan matriks pemetaan pertanyaan dilatih. Untuk meningkatkan lagi pemahaman model tentang maklumat semantik imej input, penyelidik memperkenalkan penyesuai kandungan yang telah terlatih (artikel ini menggunakan Penyesuai IP [8]) untuk menyuntik ciri semantik imej.
Frame Similarity Prior
Untuk meningkatkan lagi kestabilan hasil yang dijana, para penyelidik mencadangkan persamaan antara bingkai sebelum mencapai keseimbangan antara kestabilan dan keamatan gerakan video yang dihasilkan. Andaian utama ialah pada tahap hingar Gaussian yang agak rendah, bingkai pertama yang bising dan bingkai seterusnya yang bising adalah cukup hampir, seperti yang ditunjukkan dalam rajah di bawah:
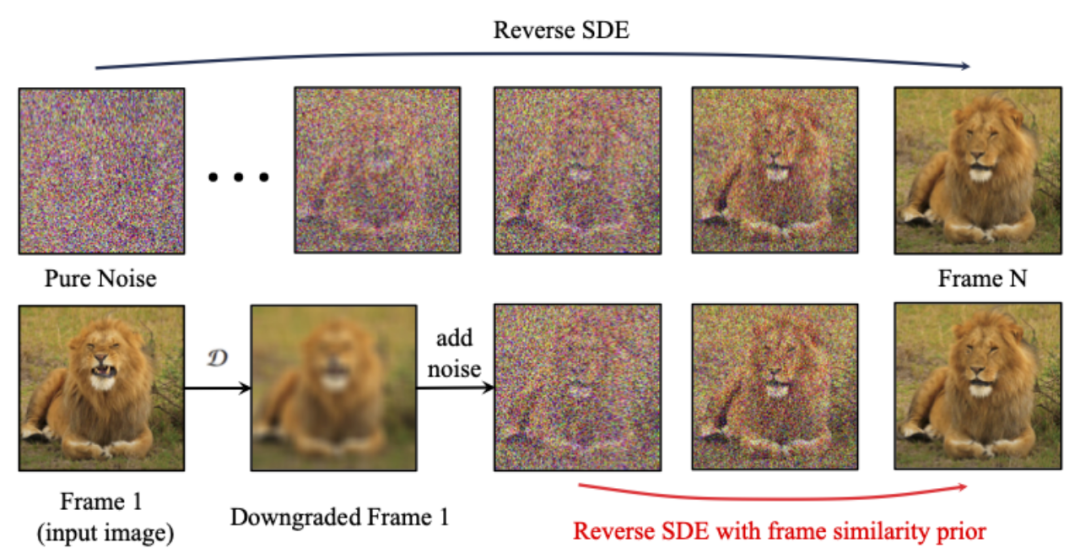
Jadi, penyelidik mengandaikan bahawa semua struktur bingkai Serupa , dan menjadi sukar untuk dibezakan selepas menambah sejumlah hingar Gaussian, jadi imej input hingar boleh digunakan sebagai input priori untuk bingkai berikutnya. Untuk menghapuskan maklumat frekuensi tinggi yang mengelirukan, para penyelidik juga menggunakan pengendali kabur Gaussian dan pencampuran topeng rawak. Khususnya, operasi diberikan oleh formula berikut:

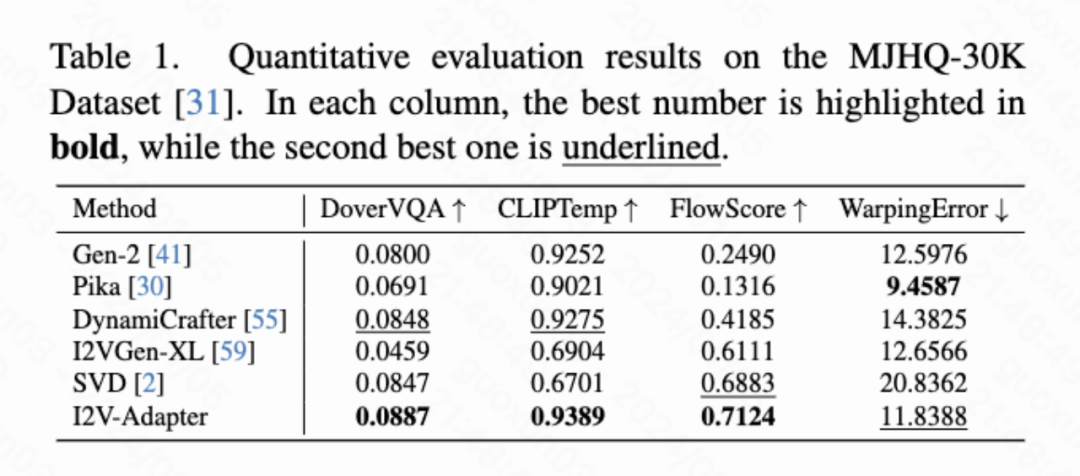
Hasil kuantitatif
Artikel Q.V yang dikira secara kuantitatif ini st Bingkai ketekalan), FlowScore (amplitud gerakan) dan WarppingError (ralat gerakan) digunakan untuk menilai kualiti video yang dihasilkan. Jadual 1 menunjukkan bahawa I2V-Adapter menerima skor estetik tertinggi dan juga melebihi semua skema perbandingan dari segi ketekalan bingkai pertama. Di samping itu, video yang dihasilkan oleh I2V-Adapter mempunyai amplitud gerakan terbesar dan ralat gerakan yang agak rendah, menunjukkan bahawa model ini mampu menjana lebih banyak video dinamik sambil mengekalkan ketepatan gerakan temporal.
Hasil kualitatif
Animasi Imej (kiri ialah input, kanan ialah output):



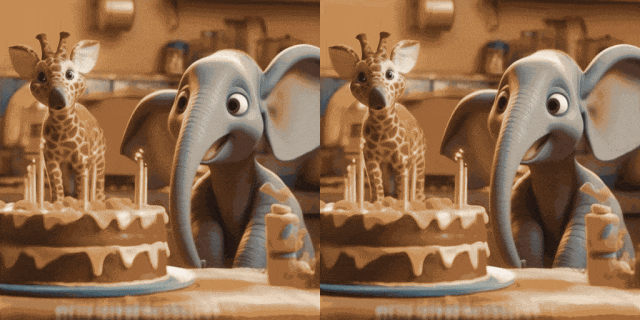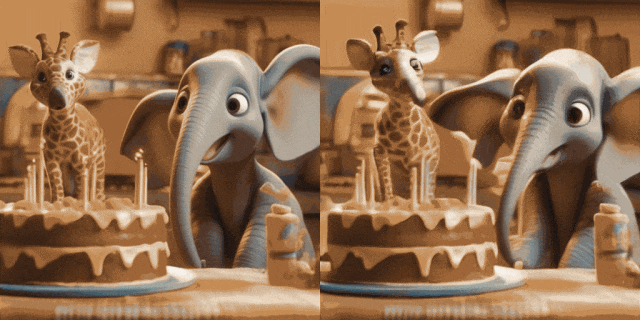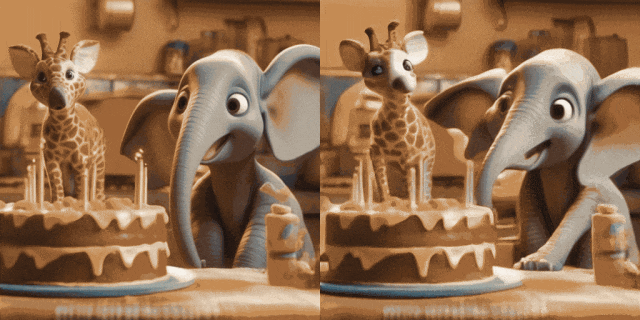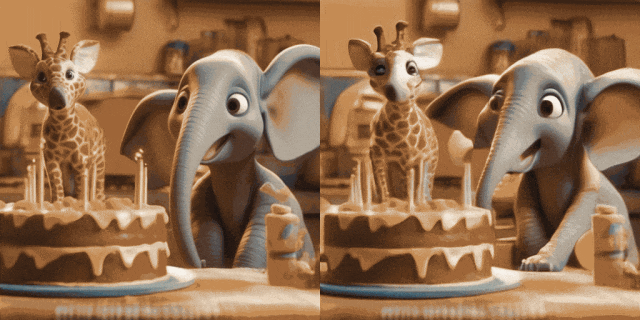
 w/ T2I Diperibadikan (di Input kiri, kanan ialah output):
w/ T2I Diperibadikan (di Input kiri, kanan ialah output):



 w/ ControlNet (kiri ialah input, kanan ialah output):
w/ ControlNet (kiri ialah input, kanan ialah output):


Kertas kerja ini mencadangkan I2V-Adapter, modul ringan pasang dan main untuk tugas penjanaan imej-ke-video. Kaedah ini memastikan struktur blok ruang dan blok gerakan serta parameter model T2V asal tetap, memasukkan bingkai pertama tanpa hingar dan bingkai berikutnya dengan hingar selari, dan membenarkan semua bingkai berinteraksi dengan bingkai pertama tanpa hingar melalui mekanisme perhatian , dengan itu Menghasilkan video yang koheren secara sementara dan konsisten dengan bingkai pertama. Penyelidik telah menunjukkan keberkesanan kaedah ini pada tugasan I2V melalui eksperimen kuantitatif dan kualitatif. Selain itu, reka bentuk decouplednya membolehkan penyelesaian digabungkan secara langsung dengan modul seperti DreamBooth, Lora dan ControlNet, membuktikan keserasian penyelesaian dan mempromosikan penyelidikan mengenai penjanaan imej-ke-video yang disesuaikan dan dikawal.
Atas ialah kandungan terperinci Penyesuai I2V daripada komuniti SD: tiada konfigurasi diperlukan, pasang dan main, serasi sempurna dengan pemalam video Tusheng. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apa yang perlu dilakukan dengan kad video
Apa yang perlu dilakukan dengan kad video
 Bagaimana untuk memuat turun video dari Douyin
Bagaimana untuk memuat turun video dari Douyin
 Perbezaan antara permintaan dapatkan dan permintaan pos
Perbezaan antara permintaan dapatkan dan permintaan pos
 Bagaimana untuk menyelesaikan masalah perisian antivirus win11 tidak boleh dibuka
Bagaimana untuk menyelesaikan masalah perisian antivirus win11 tidak boleh dibuka
 Indeks melebihi penyelesaian sempadan tatasusunan
Indeks melebihi penyelesaian sempadan tatasusunan
 js subrentetan
js subrentetan
 Cara menggunakan debug.exe
Cara menggunakan debug.exe
 Penyelesaian kepada kegagalan kemas kini WIN10
Penyelesaian kepada kegagalan kemas kini WIN10








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



