GPT-4 telah menunjukkan kebolehannya yang luar biasa untuk menjana penerangan imej yang terperinci dan tepat, menandakan ketibaan era baharu bahasa dan pemprosesan visual. Oleh itu, model bahasa besar multimodal (MLLM) yang serupa dengan GPT-4 baru-baru ini muncul dan menjadi bidang penyelidikan yang sedang hangat muncul . Prestasi MLLM yang tidak dijangka dan cemerlang bukan sahaja mengatasi kaedah tradisional, tetapi juga menjadikannya salah satu cara yang berpotensi untuk mencapai kecerdasan buatan am. Untuk mencipta MLLM yang berguna, data teks imej berpasangan berskala besar dan data penalaan halus visual-linguistik perlu digunakan untuk melatih LLM beku (seperti LLaMA dan Vicuna) dan perwakilan visual (seperti CLIP dan BLIP- 2) Penyambung (seperti MiniGPT-4, LLaVA dan LLaMA-Adapter). Latihan MLLM biasanya dibahagikan kepada dua peringkat: peringkat pra-latihan dan peringkat penalaan halus. Tujuan pra-latihan adalah untuk membolehkan MLLM memperoleh sejumlah besar pengetahuan, manakala penalaan halus adalah untuk mengajar model untuk lebih memahami niat manusia dan menjana respons yang tepat. Untuk meningkatkan keupayaan MLLM memahami bahasa visual dan mengikut arahan, teknologi penalaan halus yang berkuasa dipanggil penalaan arahan telah muncul baru-baru ini. Teknologi ini membantu menjajarkan model dengan pilihan manusia supaya model menghasilkan hasil yang diingini manusia di bawah pelbagai arahan yang berbeza. Dari segi membangunkan teknologi penalaan halus arahan, hala tuju yang agak membina ialah memperkenalkan anotasi imej, jawapan soalan visual (VQA) dan set data penaakulan visual dalam peringkat penalaan halus. Teknik sebelumnya seperti InstructBLIP dan Otter telah menggunakan satu siri set data visual-linguistik untuk memperhalusi arahan visual, dan juga telah mencapai hasil yang menjanjikan. Walau bagaimanapun, telah diperhatikan bahawa set data penalaan halus arahan berbilang mod yang biasa digunakan mengandungi sejumlah besar kejadian berkualiti rendah, iaitu, apabila respons tidak betul atau tidak relevan. Data sedemikian mengelirukan dan boleh menjejaskan prestasi model secara negatif. Soalan ini mendorong penyelidik untuk meneroka kemungkinan: Bolehkah prestasi teguh dicapai menggunakan sejumlah kecil data arahan mengikut kualiti tinggi? Beberapa kajian baru-baru ini telah memperoleh hasil yang memberangsangkan, menunjukkan bahawa hala tuju ini berpotensi. Contohnya, Zhou et al. mencadangkan LIMA, iaitu model bahasa yang diperhalusi menggunakan data berkualiti tinggi yang dipilih dengan teliti oleh pakar manusia. Kajian ini menunjukkan bahawa model bahasa yang besar boleh mencapai hasil yang memuaskan walaupun dengan jumlah data arahan ikut berkualiti tinggi yang terhad. Oleh itu, para penyelidik membuat kesimpulan: Kurang adalah lebih apabila ia berkaitan dengan penjajaran. Walau bagaimanapun, belum ada garis panduan yang jelas tentang cara memilih set data berkualiti tinggi yang sesuai untuk model bahasa berbilang mod penalaan halus. Sebuah pasukan penyelidik dari Institut Penyelidikan Qingyuan Universiti Jiao Tong Shanghai dan Universiti Lehigh telah mengisi jurang ini dan mencadangkan pemilih data yang mantap dan berkesan. Pemilih data ini secara automatik mengenal pasti dan menapis data visual-verbal berkualiti rendah, memastikan bahawa sampel yang paling relevan dan bermaklumat digunakan untuk latihan model. . penalaan data pada penalaan halus berbilang mod Keberkesanan model bahasa besar yang dinamik. Di samping itu, kertas kerja ini memperkenalkan beberapa metrik baharu yang direka khusus untuk menilai kualiti data arahan multimodal. Selepas melakukan pengelompokan spektrum pada imej, pemilih data mengira skor wajaran yang menggabungkan skor CLIP, skor GPT, skor bonus dan panjang jawapan untuk setiap data visual-linguistik. Dengan menggunakan pemilih ini pada 3400 data mentah yang digunakan untuk memperhalusi MiniGPT-4, para penyelidik mendapati bahawa kebanyakan data mempunyai isu kualiti yang rendah. Menggunakan pemilih data ini, penyelidik mendapat subset data yang dipilih susun yang jauh lebih kecil - hanya 200 data, hanya 6% daripada set data asal. Kemudian mereka menggunakan konfigurasi latihan yang sama seperti MiniGPT-4 dan memperhalusinya untuk mendapatkan model baharu: InstructionGPT-4.  Para penyelidik berkata ini adalah penemuan yang menarik kerana ia menunjukkan bahawa kualiti data adalah lebih penting daripada kuantiti dalam memperhalusi arahan visual-verbal. Tambahan pula, perubahan ini dengan lebih menekankan kualiti data menyediakan paradigma baharu dan lebih berkesan yang boleh meningkatkan penalaan halus MLLM.Para penyelidik menjalankan eksperimen yang ketat, dan penilaian eksperimen MLLM yang diperhalusi memfokuskan pada tujuh set data berbilang modal domain terbuka yang pelbagai dan kompleks, termasuk Flick-30k, ScienceQA, VSR, dsb. Mereka membandingkan prestasi inferens model yang diperhalusi menggunakan kaedah pemilihan set data yang berbeza (menggunakan pemilih data, persampelan set data secara rawak, menggunakan set data lengkap) pada tugasan pelbagai modal yang berbeza Keputusan menunjukkan prestasi keunggulan ArahanGPT-4 . Selain itu, perlu diambil perhatian: penilai yang digunakan oleh penyelidik untuk penilaian ialah GPT-4. Khususnya, penyelidik menggunakan segera untuk menjadikan GPT-4 sebagai penilai, yang boleh membandingkan keputusan tindak balas ArahanGPT-4 dan MiniGPT-4 asal menggunakan set ujian dalam LLaVA-Bench. Didapati bahawa walaupun data diperhalusi yang digunakan oleh InstructionGPT-4 hanya 6% kurang daripada data pematuhan arahan asal yang digunakan oleh MiniGPT-4, yang terakhir memberikan respons dalam 73% kes Semua sama atau lebih baik. Sumbangan utama kertas ini termasuk:
Para penyelidik berkata ini adalah penemuan yang menarik kerana ia menunjukkan bahawa kualiti data adalah lebih penting daripada kuantiti dalam memperhalusi arahan visual-verbal. Tambahan pula, perubahan ini dengan lebih menekankan kualiti data menyediakan paradigma baharu dan lebih berkesan yang boleh meningkatkan penalaan halus MLLM.Para penyelidik menjalankan eksperimen yang ketat, dan penilaian eksperimen MLLM yang diperhalusi memfokuskan pada tujuh set data berbilang modal domain terbuka yang pelbagai dan kompleks, termasuk Flick-30k, ScienceQA, VSR, dsb. Mereka membandingkan prestasi inferens model yang diperhalusi menggunakan kaedah pemilihan set data yang berbeza (menggunakan pemilih data, persampelan set data secara rawak, menggunakan set data lengkap) pada tugasan pelbagai modal yang berbeza Keputusan menunjukkan prestasi keunggulan ArahanGPT-4 . Selain itu, perlu diambil perhatian: penilai yang digunakan oleh penyelidik untuk penilaian ialah GPT-4. Khususnya, penyelidik menggunakan segera untuk menjadikan GPT-4 sebagai penilai, yang boleh membandingkan keputusan tindak balas ArahanGPT-4 dan MiniGPT-4 asal menggunakan set ujian dalam LLaVA-Bench. Didapati bahawa walaupun data diperhalusi yang digunakan oleh InstructionGPT-4 hanya 6% kurang daripada data pematuhan arahan asal yang digunakan oleh MiniGPT-4, yang terakhir memberikan respons dalam 73% kes Semua sama atau lebih baik. Sumbangan utama kertas ini termasuk:
- Dengan memilih 200 (kira-kira 6%) arahan berkualiti tinggi mengikut data untuk melatih ArahanGPT-4, para penyelidik menunjukkan bahawa ia boleh digunakan untuk pelbagai -Modal model Bahasa berskala besar menggunakan kurang data arahan untuk mencapai penjajaran yang lebih baik.
- Kertas kerja ini mencadangkan pemilih data yang menggunakan prinsip mudah dan boleh ditafsir untuk memilih data pematuhan arahan berbilang mod berkualiti tinggi untuk penalaan halus. Pendekatan ini berusaha untuk mencapai kesahan dan mudah alih dalam penilaian dan pelarasan subset data.
- Para penyelidik telah menunjukkan melalui eksperimen bahawa teknologi mudah ini boleh mengendalikan tugas yang berbeza dengan baik. Berbanding dengan MiniGPT-4 asal, InstructionGPT-4, yang diperhalusi menggunakan hanya 6% data yang ditapis, mencapai prestasi yang lebih baik pada pelbagai tugas. . Untuk tujuan ini, penyelidik mentakrifkan prinsip pemilihan yang memberi tumpuan kepada kepelbagaian dan kualiti set data multimodal. Pengenalan ringkas akan diberikan di bawah.
Prinsip Pemilihan
Untuk melatih MLLM dengan berkesan, adalah penting untuk memilih data arahan pelbagai mod yang berguna. Untuk memilih data arahan yang optimum, penyelidik mencadangkan dua prinsip utama: kepelbagaian dan kualiti. Untuk kepelbagaian, pendekatan yang diambil oleh penyelidik adalah mengelompokkan benam imej untuk memisahkan data kepada kumpulan yang berbeza. Untuk menilai kualiti, para penyelidik menggunakan beberapa metrik utama untuk penilaian yang cekap bagi data multimodal. Pemilih Data
Memandangkan set data arahan visual-linguistik dan MLLM pra-latihan (seperti MiniGPT-4 dan LLaVA matlamat utama untuk mengenal pasti data). Subset yang digunakan untuk penalaan halus dan membolehkan subset ini membawa penambahbaikan kepada MLLM pra-latihan.
Untuk memilih subset ini dan memastikan kepelbagaiannya, para penyelidik mula-mula menggunakan algoritma pengelompokan untuk membahagikan set data asal kepada berbilang kategori. Untuk memastikan kualiti data arahan pelbagai mod yang dipilih, penyelidik membangunkan satu set penunjuk untuk penilaian, seperti ditunjukkan dalam Jadual 1 di bawah.
Jadual 2 menunjukkan berat setiap markah berbeza semasa mengira markah akhir.
Algoritma 1 menunjukkan keseluruhan aliran kerja pemilih data.  Eksperimen
Eksperimen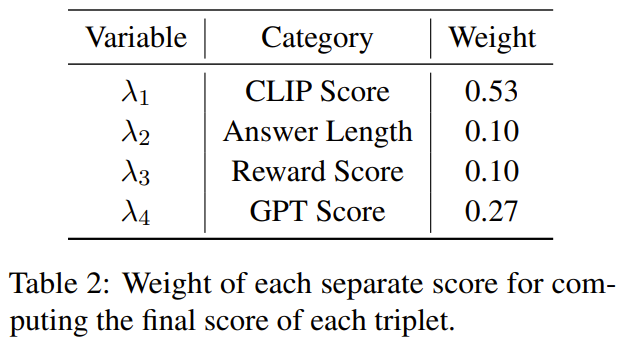 Dataset data yang digunakan dalam penilaian eksperimen ditunjukkan dalam Jadual 3 di bawah.
Dataset data yang digunakan dalam penilaian eksperimen ditunjukkan dalam Jadual 3 di bawah. Markah penanda aras
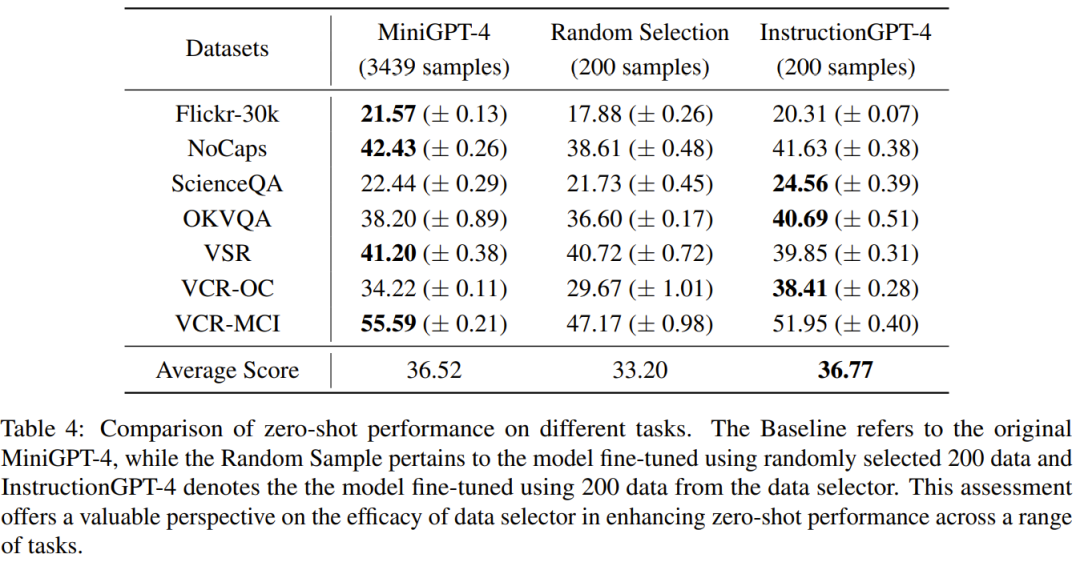
Jadual 4 membandingkan prestasi model garis dasar MiniGPT-4, MiniGPT-4 diperhalusi menggunakan data sampel yang dipilih secara rawak.-GPT yang dipilih secara halus dan 4 .Boleh diperhatikan bahawa prestasi purata InstructionGPT-4 adalah yang terbaik. Secara khususnya, InstructionGPT-4 mengatasi model garis dasar sebanyak 2.12% pada ScienceQA, dan mengatasi model garis dasar sebanyak 2.49% dan 4.19% pada OKVQA dan VCR-OC masing-masing. Selain itu, InstructionGPT-4 mengatasi model yang dilatih dengan sampel rawak pada semua tugas lain kecuali VSR. Dengan menilai dan membandingkan model ini pada pelbagai tugas, adalah mungkin untuk membezakan keupayaan masing-masing dan menentukan keberkesanan pemilih data yang baru dicadangkan yang mengenal pasti data berkualiti tinggi dengan berkesan. Analisis komprehensif sedemikian menunjukkan bahawa pemilihan data yang bijak boleh meningkatkan prestasi sifar tangkapan model pada pelbagai tugas yang berbeza. . Penyelidikan baharu: Jika konteksnya terlalu panjang, model akan melangkau bahagian tengah dan tidak membacanya》. Oleh itu, pengkaji mengambil langkah untuk menyelesaikan masalah ini Secara khusus, mereka menggunakan dua urutan susunan respons untuk melaksanakan penilaian pada masa yang sama, iaitu meletakkan respons yang dijana oleh InstructionGPT-4 sebelum atau selepas respons yang dihasilkan oleh MiniGPT-4. Untuk membangunkan kriteria penghakiman yang jelas, mereka menggunakan rangka kerja "Win-Tie-Lose":
1) Menang: InstructionGPT-4 Menang dalam kedua-dua situasi atau menang sekali dan seri sekali 2) Seri: InstructionGPT -4 dan MiniGPT-4 seri dua kali atau menang sekali dan kalah sekali;
Rajah 1 menunjukkan keputusan kaedah penilaian ini.
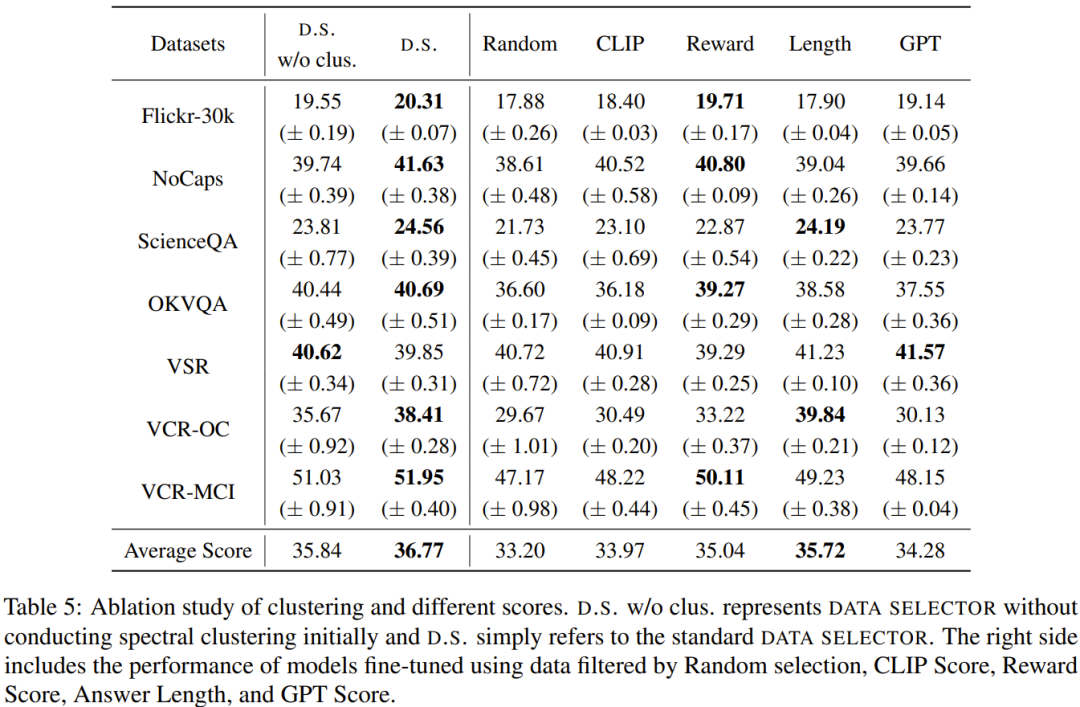
Pada 60 soalan, InstructionGPT-4 memenangi 29 perlawanan, kalah 16 perlawanan dan seri dalam baki 15 perlawanan. Ini sudah cukup untuk membuktikan bahawa InstructionGPT-4 jauh lebih baik daripada MiniGPT-4 dari segi kualiti tindak balas. Jadual 5 memberikan hasil analisis eksperimen ablasi, dari mana kepentingan algoritma pengelompokan dan pelbagai markah penilaian dapat dilihat. 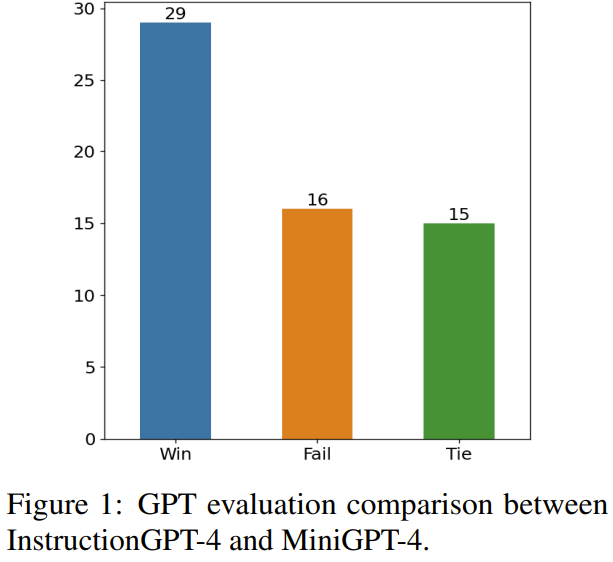
Demonstration
dalam perintah untuk mendapatkan pemahaman yang lebih mendalam tentang keupayaan pengajarangpt-4 untuk memahami input visual dan menghasilkan respons yang munasabah, penyelidik juga menjalankan eksperimen pada pengajarangpt-4 dan MiniGPT-4 Pemahaman imej dan kebolehan perbualan dinilai secara perbandingan. Analisis adalah berdasarkan contoh menarik yang melibatkan penerangan dan pemahaman lanjut tentang imej, dan hasilnya ditunjukkan dalam Jadual 6.
ArahanGPT-4 lebih baik dalam menyediakan penerangan imej yang komprehensif dan mengenal pasti aspek menarik dalam imej. Berbanding dengan MiniGPT-4, InstructionGPT-4 lebih berkebolehan untuk mengenali teks yang terdapat dalam imej. Di sini, InstructionGPT-4 dapat menunjukkan dengan betul bahawa terdapat frasa dalam imej: Isnin, hanya Isnin.Lihat kertas asal untuk butiran lanjut.
Atas ialah kandungan terperinci Selepas memilih 200 keping data, MiniGPT-4 telah diatasi dengan memadankan model yang sama.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



 lte
lte
 Pengenalan kepada arahan biasa postgresql
Pengenalan kepada arahan biasa postgresql
 Cara menggunakan perisian pengaturcaraan jsp
Cara menggunakan perisian pengaturcaraan jsp
 Apakah maksud port pautan atas?
Apakah maksud port pautan atas?
 Penggunaan fungsi sprintf dalam php
Penggunaan fungsi sprintf dalam php
 Apakah maksud memformat telefon mudah alih?
Apakah maksud memformat telefon mudah alih?
 Kelas utama tidak ditemui atau tidak dapat dimuatkan
Kelas utama tidak ditemui atau tidak dapat dimuatkan
 Penjelasan terperinci tentang konfigurasi nginx
Penjelasan terperinci tentang konfigurasi nginx


![Bermula dengan Pembangunan Praktikal PHP: Penciptaan PHP Pantas [Forum Perniagaan Kecil]](https://img.php.cn/upload/course/000/000/035/5d27fb58823dc974.jpg)






![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



