
 Peranti teknologi
AI
RoboFusion untuk pengesanan 3D berbilang modal yang boleh dipercayai menggunakan SAM
Peranti teknologi
AI
RoboFusion untuk pengesanan 3D berbilang modal yang boleh dipercayai menggunakan SAM
RoboFusion untuk pengesanan 3D berbilang modal yang boleh dipercayai menggunakan SAM

Pautan kertas: https://arxiv.org/pdf/2401.03907.pdf
Pengesan 3D berbilang modal direka untuk mengkaji sistem persepsi pemanduan autonomi yang selamat dan boleh dipercayai. Walaupun mereka mencapai prestasi terkini pada set data penanda aras yang bersih, kerumitan dan keadaan persekitaran dunia sebenar yang teruk sering diabaikan. Pada masa yang sama, dengan kemunculan Model Asas Visi (VFM), meningkatkan keteguhan dan keupayaan generalisasi pengesanan 3D berbilang modal menghadapi peluang dan cabaran dalam pemanduan autonomi. Oleh itu, pengarang mencadangkan rangka kerja RoboFusion, yang memanfaatkan VFM seperti SAM untuk menangani senario hingar luar pengedaran (OOD).
Pertama, kami menggunakan SAM asal pada senario pemanduan autonomi yang dipanggil SAM-AD. Untuk menjajarkan SAM atau SAMAD dengan kaedah berbilang modal, kami memperkenalkan AD-FPN untuk menambah sampel ciri imej yang diekstrak oleh SAM. Untuk mengurangkan lagi gangguan hingar dan cuaca, kami menggunakan penguraian wavelet untuk menapis imej berpandukan kedalaman. Akhir sekali, kami menggunakan mekanisme perhatian kendiri untuk menyesuaikan semula ciri yang digabungkan untuk meningkatkan ciri bermaklumat sambil menahan hingar yang berlebihan. RoboFusion meningkatkan daya tahan pengesanan objek 3D berbilang mod dengan memanfaatkan generalisasi dan keteguhan VFM untuk mengurangkan bunyi secara beransur-ansur. Hasilnya, RoboFusion mencapai prestasi terkini dalam adegan bising, menurut hasil daripada penanda aras KITTIC dan nuScenes-C.
Makalah ini mencadangkan rangka kerja teguh yang dipanggil RoboFusion, yang menggunakan VFM seperti SAM untuk menyesuaikan pengesan objek berbilang mod 3D daripada pemandangan bersih kepada adegan bising OOD. Antaranya, strategi penyesuaian SAM adalah kuncinya.
1) Gunakan ciri yang diekstrak daripada SAM dan bukannya membuat kesimpulan hasil segmentasi.
2) SAM-AD dicadangkan, iaitu SAM pra-latihan untuk senario AD.
3) AD-FPN baharu diperkenalkan untuk menyelesaikan masalah pensampelan naik ciri untuk menjajarkan VFM dengan pengesan 3D berbilang modal.
Untuk mengurangkan gangguan hingar dan mengekalkan ciri isyarat, modul Deep Guided Wavelet Attention (DGWA) diperkenalkan untuk mengurangkan bunyi frekuensi tinggi dan rendah dengan berkesan.
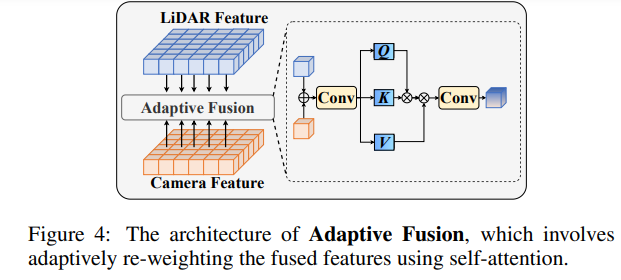
Selepas menggabungkan ciri awan titik dan ciri imej, timbang semula ciri melalui pelakuran suai untuk meningkatkan kekukuhan dan rintangan hingar ciri tersebut.
Struktur rangkaian RoboFusion
Rangka kerja RoboFusion ditunjukkan di bawah, dan cawangan lidarnya mengikut garis dasar [Chen et al., 2022] untuk menjana ciri lidar. Dalam cawangan kamera, algoritma SAM-AD yang sangat dioptimumkan digunakan untuk mengekstrak ciri imej yang mantap, dan digabungkan dengan AD-FPN untuk mendapatkan ciri berbilang skala. Seterusnya, titik asal digunakan untuk menjana peta kedalaman jarang S, yang dimasukkan ke dalam pengekod kedalaman untuk mendapatkan ciri kedalaman, dan digabungkan dengan ciri imej berskala untuk mendapatkan ciri imej berpandukan kedalaman. Kemudian, bunyi mutasi dikeluarkan melalui mekanisme perhatian yang berubah-ubah. Akhirnya, gabungan adaptif dicapai melalui mekanisme perhatian kendiri untuk menggabungkan ciri awan titik dengan ciri imej yang mantap dengan maklumat mendalam.
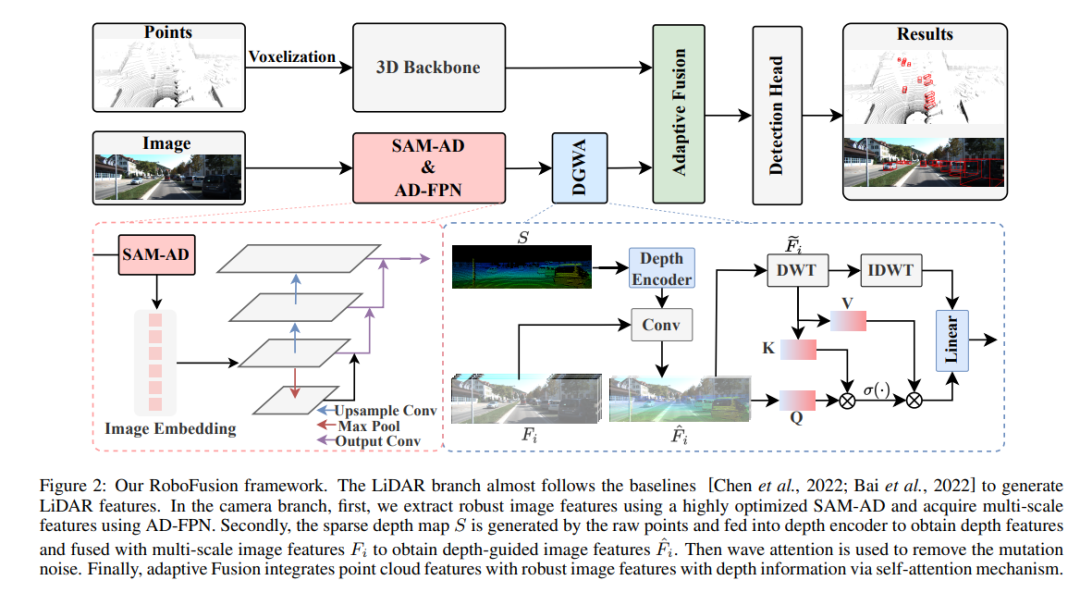
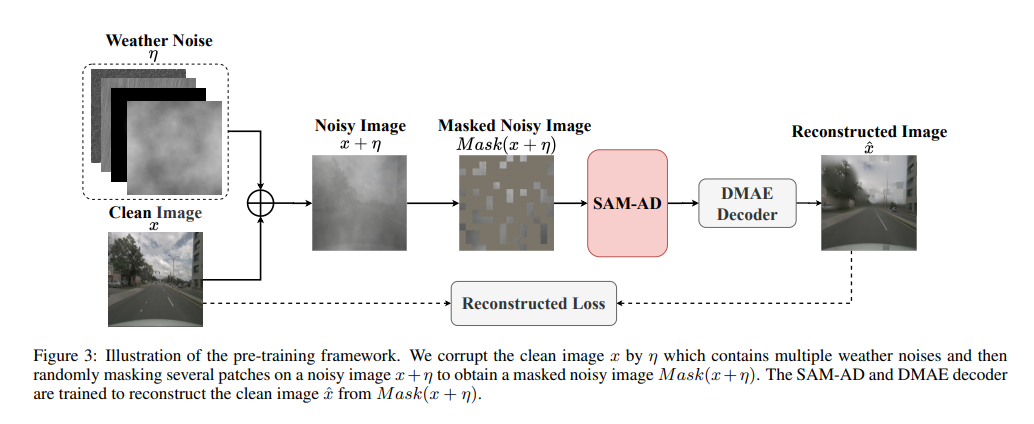
SAM-AD: Untuk menyesuaikan lagi SAM kepada senario AD (pemandu autonomi), SAM telah dilatih terlebih dahulu untuk mendapatkan SAM-AD. Khususnya, kami mengumpul sejumlah besar sampel imej daripada set data matang (iaitu, KITTI dan nuScenes) untuk membentuk set data AD asas. Selepas DMAE, SAM dilatih terlebih dahulu untuk mendapatkan SAM-AD dalam senario AD, seperti yang ditunjukkan dalam Rajah 3. Nyatakan x sebagai imej bersih daripada set data AD (iaitu KITTI dan nuScenes) dan eta sebagai imej bising yang dijana berdasarkan x. Jenis hingar dan keterukan dipilih secara rawak daripada empat keadaan cuaca (iaitu, hujan, salji, kabus dan cahaya matahari) dan lima tahap keterukan masing-masing daripada 1 hingga 5. Menggunakan SAM, pengekod imej MobileSAM sebagai pengekod kami, manakala kehilangan penyahkod dan pembinaan semula adalah sama seperti DMAE.
AD-FPN. Sebagai model segmentasi boleh kiu, SAM terdiri daripada tiga bahagian: pengekod imej, pengekod kiu dan penyahkod topeng. Secara umum, pengekod imej perlu digeneralisasikan untuk melatih VFM dan kemudian melatih penyahkod. Dalam erti kata lain, pengekod imej boleh menyediakan pembenaman imej yang berkualiti tinggi dan sangat mantap kepada model hiliran, manakala penyahkod topeng hanya direka untuk menyediakan perkhidmatan penyahkodan bagi pembahagian semantik. Tambahan pula, apa yang kita perlukan ialah ciri imej yang mantap dan bukannya pemprosesan maklumat kiu oleh pengekod kiu. Oleh itu, kami menggunakan pengekod imej SAM untuk mengekstrak ciri imej yang mantap. Walau bagaimanapun, SAM menggunakan siri ViT sebagai pengekod imejnya, yang mengecualikan ciri berbilang skala dan hanya menyediakan ciri resolusi rendah berdimensi tinggi. Untuk menjana ciri berbilang skala yang diperlukan untuk pengesanan sasaran, diilhamkan oleh [Li et al., 2022a], AD-FPN direka bentuk, yang menyediakan ciri berbilang skala berdasarkan ViT!
Walaupun keupayaan SAM-AD atau SAM untuk mengekstrak ciri imej yang mantap, jurang antara domain 2D dan domain 3D masih wujud, dan kamera yang kekurangan maklumat geometri dalam persekitaran yang rosak sering menguatkan bunyi dan menyebabkan masalah pemindahan negatif. Untuk mengurangkan masalah ini, kami mencadangkan modul Deep Guided Wavelet Attention (DGWA), yang boleh dibahagikan kepada dua langkah berikut. 1) Rangkaian panduan mendalam direka bentuk untuk menambah geometri sebelum ciri imej dengan menggabungkan ciri imej dan ciri kedalaman awan titik. 2) Gunakan transformasi wavelet Haar untuk menguraikan ciri imej kepada empat subjalur, dan kemudian mekanisme perhatian membolehkan untuk menafikan ciri maklumat dalam subjalur! Perbandingan eksperimen 8y1 KyipHeUSh5sLQZy-ng
Atas ialah kandungan terperinci RoboFusion untuk pengesanan 3D berbilang modal yang boleh dipercayai menggunakan SAM. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1385
1385
 52
52

 Bagaimana untuk menilai keberkesanan kos sokongan komersial untuk rangka kerja Java
Jun 05, 2024 pm 05:25 PM
Bagaimana untuk menilai keberkesanan kos sokongan komersial untuk rangka kerja Java
Jun 05, 2024 pm 05:25 PM
Menilai kos/prestasi sokongan komersial untuk rangka kerja Java melibatkan langkah-langkah berikut: Tentukan tahap jaminan yang diperlukan dan jaminan perjanjian tahap perkhidmatan (SLA). Pengalaman dan kepakaran pasukan sokongan penyelidikan. Pertimbangkan perkhidmatan tambahan seperti peningkatan, penyelesaian masalah dan pengoptimuman prestasi. Timbang kos sokongan perniagaan terhadap pengurangan risiko dan peningkatan kecekapan.
 Bagaimanakah keluk pembelajaran rangka kerja PHP berbanding rangka kerja bahasa lain?
Jun 06, 2024 pm 12:41 PM
Bagaimanakah keluk pembelajaran rangka kerja PHP berbanding rangka kerja bahasa lain?
Jun 06, 2024 pm 12:41 PM
Keluk pembelajaran rangka kerja PHP bergantung pada kecekapan bahasa, kerumitan rangka kerja, kualiti dokumentasi dan sokongan komuniti. Keluk pembelajaran rangka kerja PHP adalah lebih tinggi jika dibandingkan dengan rangka kerja Python dan lebih rendah jika dibandingkan dengan rangka kerja Ruby. Berbanding dengan rangka kerja Java, rangka kerja PHP mempunyai keluk pembelajaran yang sederhana tetapi masa yang lebih singkat untuk bermula.
 Bagaimanakah pilihan rangka kerja PHP yang ringan mempengaruhi prestasi aplikasi?
Jun 06, 2024 am 10:53 AM
Bagaimanakah pilihan rangka kerja PHP yang ringan mempengaruhi prestasi aplikasi?
Jun 06, 2024 am 10:53 AM
Rangka kerja PHP yang ringan meningkatkan prestasi aplikasi melalui saiz kecil dan penggunaan sumber yang rendah. Ciri-cirinya termasuk: saiz kecil, permulaan pantas, penggunaan memori yang rendah, kelajuan dan daya tindak balas yang dipertingkatkan, dan penggunaan sumber yang dikurangkan: SlimFramework mencipta API REST, hanya 500KB, responsif yang tinggi dan daya pemprosesan yang tinggi.
 RedMagic Tablet 3D Explorer Edition menampilkan paparan 3D tanpa cermin mata
Sep 06, 2024 am 06:45 AM
RedMagic Tablet 3D Explorer Edition menampilkan paparan 3D tanpa cermin mata
Sep 06, 2024 am 06:45 AM
RedMagic Tablet 3D Explorer Edition telah dilancarkan bersama Gaming Tablet Pro. Walau bagaimanapun, sementara yang kedua lebih kepada pemain, yang pertama lebih menjurus kepada hiburan. Tablet Android baharu mempunyai apa yang syarikat panggil sebagai "3D&qu
 Amalan terbaik dokumentasi rangka kerja Golang
Jun 04, 2024 pm 05:00 PM
Amalan terbaik dokumentasi rangka kerja Golang
Jun 04, 2024 pm 05:00 PM
Menulis dokumentasi yang jelas dan komprehensif adalah penting untuk rangka kerja Golang. Amalan terbaik termasuk mengikut gaya dokumentasi yang ditetapkan, seperti Panduan Gaya Pengekodan Google. Gunakan struktur organisasi yang jelas, termasuk tajuk, subtajuk dan senarai, serta sediakan navigasi. Menyediakan maklumat yang komprehensif dan tepat, termasuk panduan permulaan, rujukan API dan konsep. Gunakan contoh kod untuk menggambarkan konsep dan penggunaan. Pastikan dokumentasi dikemas kini, jejak perubahan dan dokumen ciri baharu. Sediakan sokongan dan sumber komuniti seperti isu dan forum GitHub. Buat contoh praktikal, seperti dokumentasi API.
 Bagaimana untuk memilih rangka kerja golang terbaik untuk senario aplikasi yang berbeza
Jun 05, 2024 pm 04:05 PM
Bagaimana untuk memilih rangka kerja golang terbaik untuk senario aplikasi yang berbeza
Jun 05, 2024 pm 04:05 PM
Pilih rangka kerja Go terbaik berdasarkan senario aplikasi: pertimbangkan jenis aplikasi, ciri bahasa, keperluan prestasi dan ekosistem. Rangka kerja Common Go: Gin (aplikasi Web), Echo (Perkhidmatan Web), Fiber (daya pemprosesan tinggi), gorm (ORM), fasthttp (kelajuan). Kes praktikal: membina REST API (Fiber) dan berinteraksi dengan pangkalan data (gorm). Pilih rangka kerja: pilih fasthttp untuk prestasi utama, Gin/Echo untuk aplikasi web yang fleksibel, dan gorm untuk interaksi pangkalan data.
 Penjelasan praktikal terperinci pembangunan rangka kerja golang: Soalan dan Jawapan
Jun 06, 2024 am 10:57 AM
Penjelasan praktikal terperinci pembangunan rangka kerja golang: Soalan dan Jawapan
Jun 06, 2024 am 10:57 AM
Dalam pembangunan rangka kerja Go, cabaran biasa dan penyelesaiannya ialah: Pengendalian ralat: Gunakan pakej ralat untuk pengurusan dan gunakan perisian tengah untuk mengendalikan ralat secara berpusat. Pengesahan dan kebenaran: Sepadukan perpustakaan pihak ketiga dan cipta perisian tengah tersuai untuk menyemak bukti kelayakan. Pemprosesan serentak: Gunakan goroutine, mutex dan saluran untuk mengawal akses sumber. Ujian unit: Gunakan pakej, olok-olok dan stub untuk pengasingan dan alat liputan kod untuk memastikan kecukupan. Penerapan dan pemantauan: Gunakan bekas Docker untuk membungkus penggunaan, menyediakan sandaran data dan menjejak prestasi dan ralat dengan alat pengelogan dan pemantauan.
 Apakah salah faham yang biasa berlaku dalam proses pembelajaran kerangka Golang?
Jun 05, 2024 pm 09:59 PM
Apakah salah faham yang biasa berlaku dalam proses pembelajaran kerangka Golang?
Jun 05, 2024 pm 09:59 PM
Terdapat lima salah faham dalam pembelajaran rangka kerja Go: terlalu bergantung pada rangka kerja dan fleksibiliti terhad. Jika anda tidak mengikut konvensyen rangka kerja, kod tersebut akan menjadi sukar untuk dikekalkan. Menggunakan perpustakaan lapuk boleh menyebabkan isu keselamatan dan keserasian. Penggunaan pakej yang berlebihan mengaburkan struktur kod. Mengabaikan pengendalian ralat membawa kepada tingkah laku yang tidak dijangka dan ranap sistem.
